本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
分散式資料管理
在傳統應用程式中,所有元件通常共用單一資料庫。相反地,微服務型應用程式的每個元件都會維護自己的資料,進而促進獨立性和分散化。這種方法稱為分散式資料管理,帶來了新的挑戰。
其中一種挑戰來自分散式系統中一致性和效能之間的權衡。相較於堅持即時更新 (立即一致性),接受略有延遲的資料更新 (最終一致性) 通常更實際。
有時候,業務營運需要多個微服務才能一起運作。如果某個部分失敗,您可能需要復原一些已完成的任務。Saga 模式可透過協調一系列補償動作來協助管理此動作。
為了協助微服務保持同步,可以使用集中式資料存放區。此存放區使用 AWS Lambda AWS Step Functions、 和 Amazon 等工具進行管理 EventBridge,可協助清除和刪除重複資料。
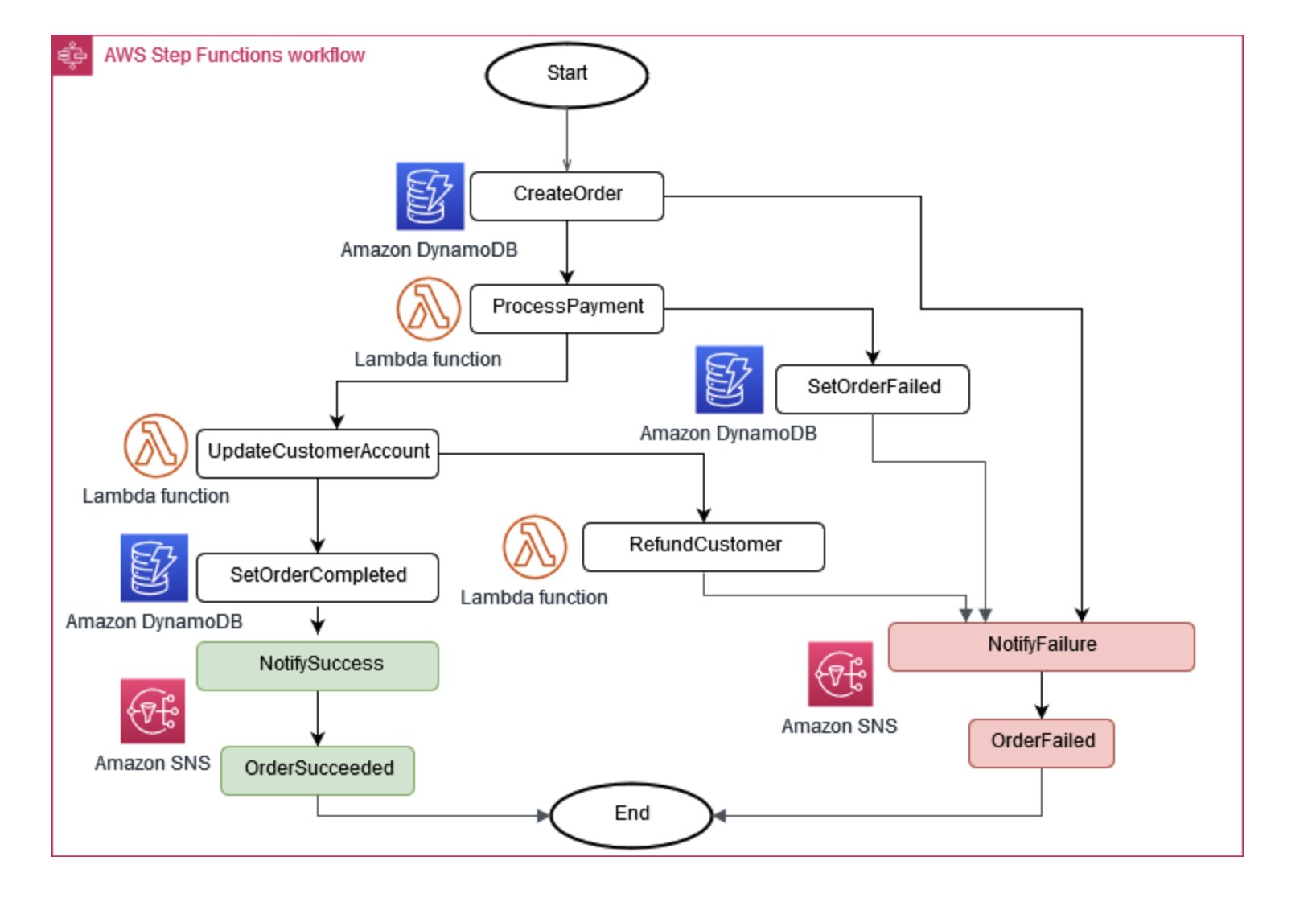
圖 6:Saga 執行協調器
管理跨微服務變更的常見方法是事件來源 。應用程式中的每個變更都會記錄為事件,建立系統狀態的時間軸。這種方法不僅有助於偵錯和稽核,還允許應用程式的不同部分對相同的事件做出反應。
事件來源通常與 Command Query Responsibility Segregation (CQRS) 模式搭配使用 hand-in-hand,該模式會將資料修改和資料查詢分隔成不同的模組,以提高效能和安全性。
在 上 AWS,您可以使用 服務組合實作這些模式。如圖 7 所示,Amazon Kinesis Data Streams 可作為您的中央事件存放區,而 Amazon S3 則為所有事件記錄提供持久的儲存體。 AWS Lambda、Amazon DynamoDB 和 Amazon API Gateway 會一起處理這些事件。
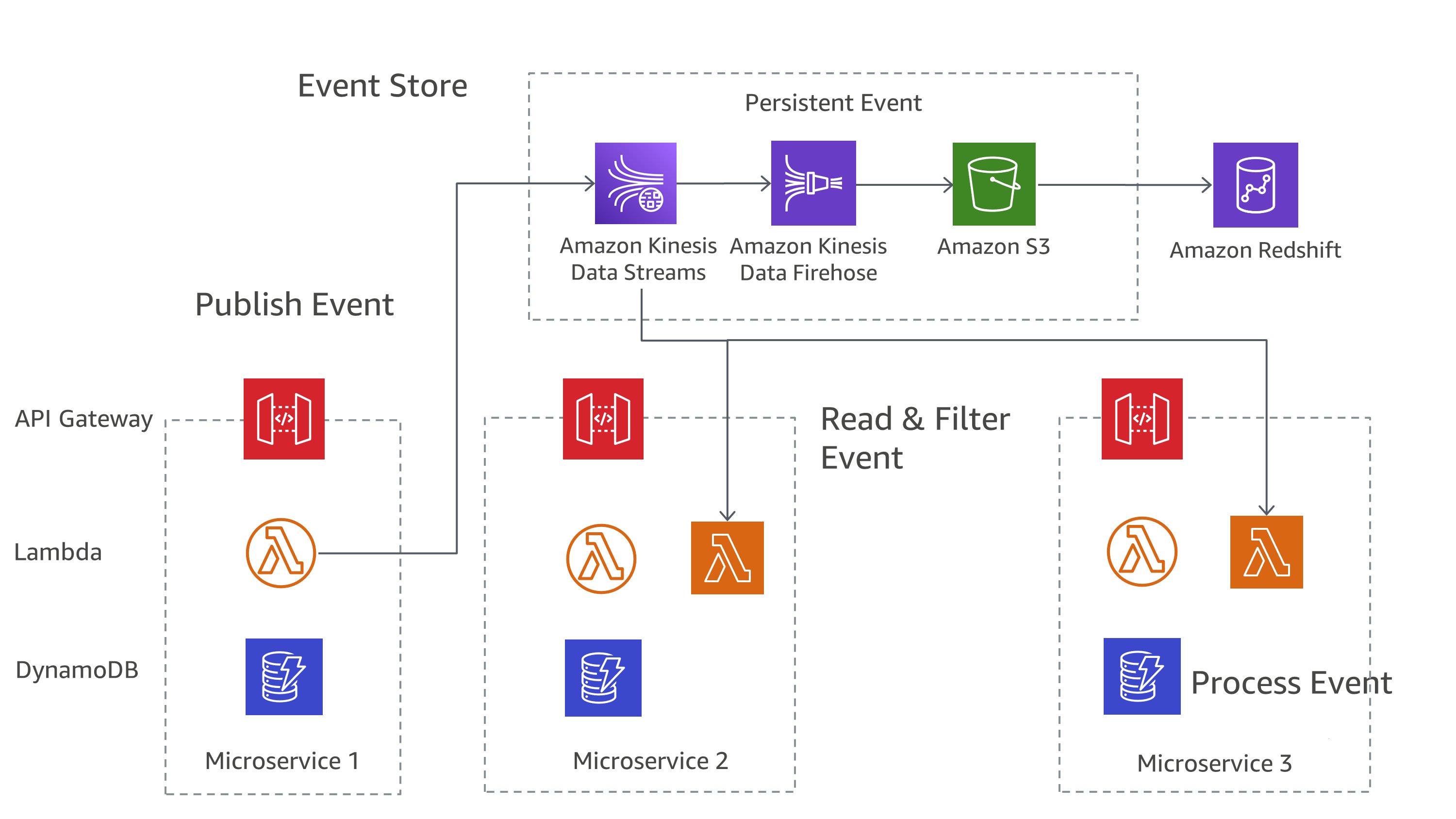
圖 7: 上的事件來源模式 AWS
請記住,在分散式系統中,事件可能會因重試而多次交付,因此設計您的應用程式來處理這一點很重要。
