營運面向:運作狀態和可用性
營運面向側重於確保依與業務利害關係人商定的等級提供雲端服務。自動化和最佳化作業將可讓您有效擴展,同時提高工作負載的可靠性。此面向包含下圖所示的九項能力。共同利害關係人包括基礎設施和營運部門主管、網站可靠性工程師和資訊科技服務經理。
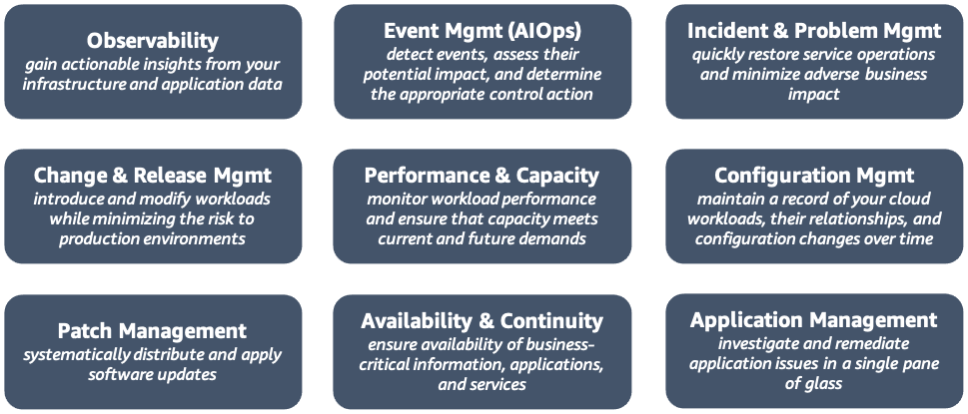
AWS CAF 營運面向功能
-
可觀察性 – 從基礎設施及應用程式資料中取得可行的洞見。當您以雲端速度和規模
作業時,您需要能夠在問題浮現時立即察覺,最好是在干擾客戶體驗之前發現這些問題。開發必要的遙測記錄 (日誌、指標和追蹤),以了解工作負載的內部狀態和運作狀態。監控應用程式端點,評估對最終使用者的影響,並在測量值超過閾值時產生提醒。 使用綜合監控建立 Canary (這是按排程執行的可設定指令碼),以監控您的端點和 API。執行追蹤
,以追蹤這些請求在整個應用程式中的傳輸路線,並找出瓶頸或效能問題。利用指標和記錄深入了解資源、伺服器、資料庫和網路。設定時間序列資料的即時分析,以了解影響效能的原因。將資料集中在單一儀表板 中,為您提供有關工作負載及其效能重要資訊的整合檢視 。 -
事件管理 (AIOps) – 偵測事件、評估其潛在影響並判斷適當的控制動作。能夠過濾雜訊、專注於優先事件、預測資源即將耗盡的情況、自動產生提醒和事件,以及識別可能的原因和補救措施,將有助於您改進事件偵測和回應時間。建立事件儲存模式,利用機器學習
(AIOps ) 自動建立事件關聯、偵測異常及判定因果關係。與雲端服務和第三方工具整合,包括您的事件管理系統和流程。自動回應事件,減少因手動流程造成錯誤,並確保快速一致的回應。 -
事件和問題管理 – 快速還原服務營運,並將對業務的不利影響降至最低。經由雲端採用,服務問題和應用程式運作狀態問題的回應流程得以高度自動化,從而拉長服務正常運行時間。隨著您轉向更為分散的營運模式,簡化相關團隊、工具和流程之間的互動,將有助於加快解決重大及/或複雜事件的速度。在 Runbook 中定義向上呈報路徑,包括觸發向上呈報的條件以及向上呈報的程序。
實行事件反應演習
,並將學到的經驗納入 Runbook。識別事件模式以判斷問題和修正措施。利用 Chatbot 和協作工具連接營運團隊、工具和工作流程。利用不指責的事件後分析,確定導致事件的因素,並制定相應的行動計劃。 -
變更和版本管理 – 引入及修改工作負載,同時將生產環境風險降至最低。傳統的版本管理流程很複雜,部署速度緩慢又難以轉返。雲端採用讓您有機會利用 CI/CD 技術快速管理版本和轉返。建立允許自動核准工作流程的變更流程,使其與雲端敏捷性保持一致。使用部署管理系統來追蹤和實作變更。透過頻繁、細微和可逆的變更來縮小變更範圍。測試變更並在生命週期所有階段
驗證結果,以將失敗部署的風險和影響降至最低。當無法實現結果時,自動還原到先前的良好狀態,以最大限度縮短還原時間,並減少由手動程序引起的錯誤。 -
效能和容量管理 – 監控工作負載效能,並確保容量滿足當下和未來的需求。雖然雲端容量幾乎無限制,但服務配額、容量預留和資源約束會限制實際的工作負載容量。您需要了解
這種容量約束,才能有效加以管理。辨明主要利害關係人並議定中長期目標、範圍和指標。收集及處理效能資料,並定期針對目標檢閱 及報告效能。定期評估新技術以提高效能,並酌情建議變更目標和指標。監控工作負載的利用率,建立未來的比較基準,並視需要確定擴展容量的閾值。分析一段時間的需求,以確保容量能符合季節性趨勢和波動的營運條件。 -
組態管理 – 維護準確且完整的一段時間內所有雲端工作負載、其關係及組態變化記錄。若不以有效方式管理,雲端資源佈建的動態和虛擬性質會造成組態偏移。定義並強制執行可將商業屬性覆蓋到雲端使用方式的標記結構描述
,然後利用標籤按照技術、業務和安全層面安排資源。指定強制標籤並透過政策強制執行合規性。利用 Infrastructure as Code (IaC) 和組態管理工具 進行資源佈建和生命週期管理。建立組態基準並透過版本控制 加以維護。 -
修補程式管理 – 以系統化方式分配及套用軟體更新。軟體更新可解決新出現的安全漏洞、修復錯誤,並引入新功能。管理修補程式的系統化方法會確保您能從最新的更新獲益,同時將生產環境風險降至最低。在指定的維護時段內套用重要更新,並儘快套用重大安全性更新。提前通知使用者即將進行之更新的詳細資訊,並允許使用者在有其他緩解控制措施可用時延遲修補程式。先更新機器映像和測試修補程式,再發佈到生產環境。為確保修補過程中的持續可用性,請考慮為每個可用區域 (AZ) 和環境設定不同的維護時段。定期審查修補程式的合規性,並提醒不符合規範的團隊套用必要的更新。
-
可用性和持續性管理 – 確保商業重大資訊、應用程式和服務的可用性。建置雲端備份
解決方案需要仔細考慮現有的技術投資、恢復目標和可用資源。災難和安全事件後的及時還原 有助於保持系統可用性和業務持續性。根據定義的排程備份資料和文件。 在業務持續性計劃之下,制定災難復原計劃。確定每個工作負載不同災難情境下的威脅、風險、影響和成本,並據以指定復原時間點目標 (RTO) 和復原點目標 (RPO)。利用多可用區域或多區域架構,實作您選擇的災難復原策略。考慮利用混沌工程
,透過對照實驗,改善復原力和效能。定期審查和測試您的計劃,根據習得的經驗調整方法。 -
應用程式管理 – 使用單一虛擬管理平台調查及修復應用程式問題。將應用程式資料彙總到單一管理主控台
,可以簡化營運監督,並透過降低切換不同管理工具環境的需求,加快修復應用程式問題。 與其他營運和管理系統整合 (例如應用程式組合管理和 CMDB),將發現應用程式元件和資源的流程自動化,並將應用程式資料合併到單一管理控制台中。納入軟體元件和基礎設施資源,並說明不同的環境,如開發、預備和生產。為更快、更一致地修復作業問題,請考慮將 Runbook 自動化。
