Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Erstellen eines Aurora-Headless-DB-Clusters in einer sekundären Region
Obwohl eine globale Aurora-Datenbank mindestens einen sekundären Aurora-DB-Cluster in einem anderen AWS-Region als dem primären benötigt, können Sie für den sekundären Cluster eine Headless-Konfiguration verwenden. Ein sekundärer Aurora-Headless-DB-Cluster hat keine DB-Instance. Diese Art der Konfiguration kann die Ausgaben für eine globale Aurora-Datenbank senken. In einem Aurora-DB-Cluster werden die Rechen- und Speicherressourcen entkoppelt. Ohne die DB-Instance wird Ihnen die Rechenleistung nicht in Rechnung gestellt, sondern nur der Speicherplatz. Richtig eingerichtet, wird das sekundäre Headless-Speichervolume mit dem primären Aurora-DB-Cluster synchonisiert.
Sie fügen den sekundären Cluster wie gewohnt beim Erstellen einer globalen Aurora-Datenbank hinzu. Wenn Sie alle Cluster in der globalen Datenbank erstellen, gehen Sie wie unter Erstellen einer globalen Datenbank von Amazon Aurora beschrieben vor. Wenn Sie bereits über einen DB-Cluster verfügen, den Sie als primären Cluster verwenden können, gehen Sie wie unter Hinzufügen eines AWS-Region zu einer globalen Amazon Aurora Aurora-Datenbank beschrieben vor.
Nachdem der primäre Aurora-DB-Cluster mit der Replikation zum sekundären Cluster begonnen hat, löschen Sie die schreibgeschützte Aurora-DB-Instance aus dem sekundären Aurora-DB-Cluster. Dieser sekundäre Cluster gilt jetzt als „Headless“, da er keine DB-Instance mehr hat. Selbst ohne DB-Instance im sekundären Aurora-DB-Cluster synchronisiert Aurora das Speicher-Volume mit dem primären Aurora-DB-Cluster.
Warnung
Um mit Aurora PostgreSQL einen Headless-Cluster in einem sekundären Cluster zu erstellen AWS-Region, verwenden Sie die AWS CLI oder RDS-API, um den sekundären Cluster hinzuzufügen. AWS-RegionÜberspringen Sie den Schritt, um die Reader-DB-Instance für den sekundären Cluster zu erstellen. Derzeit wird das Erstellen eines Headless-Clusters in der RDS-Konsole nicht unterstützt. Informationen zur Verwendung der CLI- und API-Prozeduren finden Sie unter Hinzufügen eines AWS-Region zu einer globalen Amazon Aurora Aurora-Datenbank.
Wenn Ihre globale Datenbank eine niedrigere Engine-Version als 13.4, 12.8 oder 11.13 verwendet, kann das Erstellen einer Reader-DB-Instance in einer sekundären Region und das anschließende Löschen dieser Instance zu einem Aurora-PostgreSQL-Bereinigungsproblem auf der Writer-DB-Instance der primären Region führen. Wenn dieses Problem auftritt, starten Sie die Writer-DB-Instance der primären Region neu, nachdem Sie die Reader-DB-Instance der sekundären Region gelöscht haben.
So fügen Sie Ihrer globalen Aurora-Datenbank einen sekundären Aurora-Headless-DB-Cluster hinzu
Melden Sie sich bei der an AWS Management Console und öffnen Sie die Amazon RDS-Konsole unter https://console.aws.amazon.com/rds/
. -
Wählen Sie im Navigationsbereich AWS Management Console von Datenbanken aus.
-
Wählen Sie die Aurora globale Datenbank aus, die einen sekundären Aurora-DB-Cluster benötigt. Stellen Sie sicher, dass der primäre Aurora-DB-Cluster is
Available. -
Wählen Sie für Aktionen die Option AWS Region hinzufügen aus.
-
Wählen Sie auf der Seite „Region hinzufügen“ die sekundäre Region aus AWS-Region.
Sie können keinen auswählen AWS-Region , der bereits über einen sekundären Aurora-DB-Cluster für dieselbe globale Aurora-Datenbank verfügt. Außerdem kann dies nicht dieselbe Region sein wie die des primären Aurora-DB-Clusters.
-
Füllen Sie die verbleibenden Felder für den sekundären Aurora-Cluster im neuen aus AWS-Region. Dies sind die gleichen Konfigurationsoptionen wie bei jeder Aurora-DB-Cluster-Instance.
Bei einer Aurora MySQL–basierten globalen Aurora-Datenbank ignorieren Sie die Option Read Replica-Schreibweiterleitung aktivieren. Diese Option hat keine Funktion, nachdem Sie die Reader-Instance gelöscht haben.
Wählen Sie AWS Region hinzufügen. Nachdem Sie die Region zu Ihrer globalen Aurora-Datenbank hinzugefügt haben, können Sie sie in der Liste der Datenbanken sehen, AWS Management Console wie im Screenshot gezeigt.
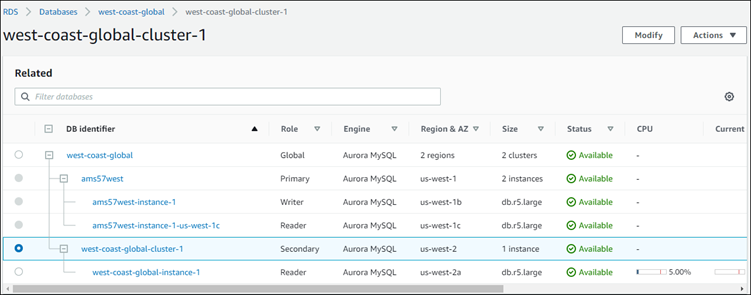
Überprüfen Sie den Status des sekundären Aurora-DB-Clusters und seiner Reader-Instance, bevor Sie fortfahren, indem Sie das AWS Management Console oder das verwenden AWS CLI. Beispiel:
$aws rds describe-db-clusters --db-cluster-identifiersecondary-cluster-id--query '*[].[Status]' --output textEs kann mehrere Minuten dauern, bis der Status eines neu hinzugefügten sekundären Aurora-DB-Clusters von
creatingaufavailablewechselt. Wenn der Aurora-DB-Cluster verfügbar ist, können Sie die Reader-Instance löschen.Wählen Sie die Reader-Instance im sekundären Aurora-DB-Cluster aus und klicken Sie dann auf Löschen.
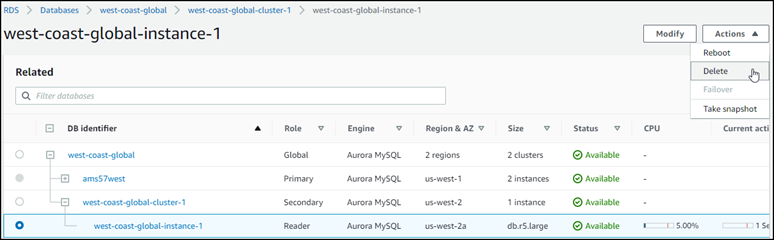
Nach dem Löschen der Reader-Instance bleibt der sekundäre Cluster Teil der globalen Aurora-Datenbank. Ihm ist keine Instance zugeordnet, wie im Folgenden gezeigt.
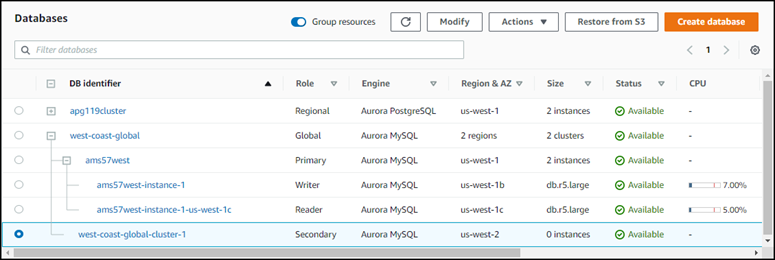
Sie können diesen sekundären Aurora-Headless-DB-Cluster verwenden, um Ihre globale Amazon-Aurora-Datenbank nach einem ungeplanten Ausfall der primären AWS-Region manuell wiederherzustellen, wenn ein solcher Ausfall auftritt.
