Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Erstellen einer globalen Datenbank von Amazon Aurora
Gehen Sie wie folgt vor, um eine globale Aurora-Datenbank und die AWS Management Console zugehörigen Ressourcen mithilfe der AWS CLI, der oder der RDS-API zu erstellen.
Anmerkung
Wenn Sie über einen vorhandenen Aurora-DB-Cluster verfügen, auf dem eine global kompatible Aurora-Datenbank-Engine ausgeführt wird, können Sie das Verfahren abkürzen. In diesem Fall können Sie dem vorhandenen DB-Cluster einen weiteren AWS-Region hinzufügen, um Ihre globale Aurora-Datenbank zu erstellen. Lesen Sie dazu den Abschnitt Hinzufügen eines AWS-Region zu einer globalen Amazon Aurora Aurora-Datenbank.
Die Schritte zum Erstellen einer globalen Aurora-Datenbank beginnen mit der Anmeldung bei einer AWS-Region , die die globale Aurora-Datenbankfunktion unterstützt. Eine vollständige Liste finden Sie hier: Unterstützte Regionen und DB-Engines für globale Aurora-Datenbanken.
Einer der folgenden Schritte ist die Auswahl einer Virtual Private Cloud (VPC), die auf Amazon VPC für Ihren Aurora-DB-Cluster basiert. Um Ihre eigene VPC zu verwenden, empfehlen wir Ihnen, diese im Voraus zu erstellen, damit sie von Ihnen ausgewählt werden kann. Erstellen Sie gleichzeitig alle zugehörigen Subnetze und nach Bedarf eine Subnetz- und Sicherheitsgruppe. Um zu erfahren wie dies geht, vgl. Tutorial: Eine VPC für die Verwendung mit einer DB erstellen Cluster (Nur IPv4).
Allgemeine Informationen zum Erstellen eines Aurora-DB-Clusters finden Sie unter Erstellen eines Amazon Aurora-DB Clusters.
So erstellen Sie eine globale Aurora-Datenbank
Melden Sie sich bei der an AWS Management Console und öffnen Sie die Amazon RDS-Konsole unter https://console.aws.amazon.com/rds/
. Wählen Sie Datenbank erstellen aus. Gehen Sie auf der Seite Datenbank erstellen wie folgt vor:
Wählen Sie als Datenbankerstellungsmethode Standarderstellung aus. Wählen Sie nicht Einfache Erstellung.
Wählen Sie für
Engine typeim Abschnitt Engine-Optionen den entsprechenden Engine-Typ, Aurora (MySQL-kompatibel) oder Aurora (PostgreSQL-kompatibel).
Fahren Sie fort mit dem Erstellen der globalen Datenbank, indem Sie den Schritten aus den folgenden Verfahren folgen:
Erstellen einer globalen Datenbank mit Aurora MySQL
Die folgenden Schritte gelten für alle Versionen von Aurora MySQL.
So erstellen Sie eine globale Aurora-Datenbank mit Aurora MySQL:
Füllen Sie die Seite Datenbank erstellen aus.
Wählen Sie unter Engine-Optionen Folgendes aus:
Wählen Sie für Engine-Version die Version von Aurora MySQL, die Sie für Ihre globale Aurora-Datenbank verwenden möchten.
Wählen Sie für VorlagenProduktion. Oder Sie können wählen, Dev/Test ob es für Ihren Anwendungsfall geeignet ist. Nicht Dev/Test in Produktionsumgebungen verwenden.
Für Settings (Einstellungen) nehmen Sie folgendes vor:
Geben Sie einen aussagekräftigen Namen für die DB-Cluster-ID ein. Wenn Sie mit dem Erstellen der Aurora globalen Datenbank fertig sind, identifiziert dieser Name den primären DB-Cluster.
Geben Sie Ihr eigenes Passwort für das
admin-Benutzerkonto für die DB-Instance ein oder lassen Sie Aurora eines für Sie erstellen. Wenn Sie ein Passwort automatisch generieren, erhalten Sie die Option zum Kopieren des Passworts.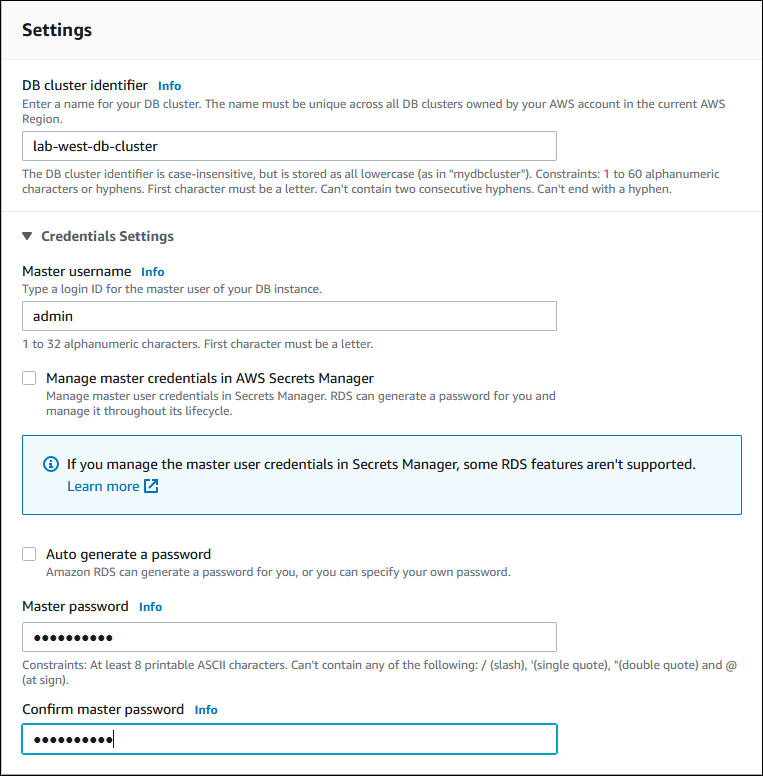
Wählen Sie für DB instance class (DB-Instance-Klasse)
db.r5.largeoder eine andere arbeitsspeicheroptimierte DB-Instance-Klasse aus. Wir empfehlen, db.r5 oder eine höhere Instance-Klasse zu nutzen.Für Verfügbarkeit und Haltbarkeit empfehlen wir Ihnen, Aurora für die Erstellung einer Aurora-Replica in einer anderen Availability Zone (AZ) zu wählen. Wenn Sie jetzt keine Aurora-Replica erstellen, müssen Sie dies später tun.
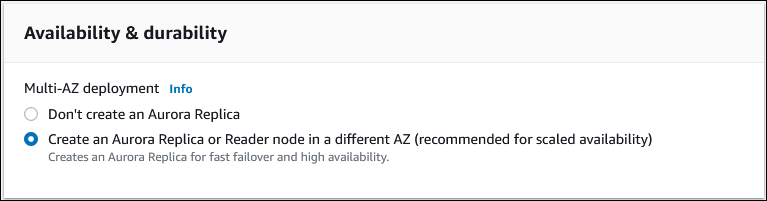
Wählen Sie bei Anbindung die auf Amazon VPC basierende Virtual Private Cloud (VPC) aus, die die virtuelle Netzwerkumgebung für diese DB-Instance definiert. Sie können die Standardwerte auswählen, um diese Aufgabe zu vereinfachen.
Schließen Sie die Einstellungen für die Datenbankauthentifizierung ab. Um den Prozess zu vereinfachen, können Sie jetzt Passwort-Authentifizierung wählen und AWS Identity and Access Management (IAM) später einrichten.
Für Zusätzliche Konfiguration führen Sie die folgenden Schritte aus:
Geben Sie einen Namen für Anfänglicher Datenbankname ein, um die primäre Aurora-DB-Instance für diesen Cluster zu erstellen. Dies ist der Writer-Knoten für den Aurora primären DB-Cluster.
Belassen Sie die für die DB-Clusterparametergruppe und die DB-Parametergruppe ausgewählten Standardwerte, es sei denn, Sie haben Ihre eigenen benutzerdefinierten Parametergruppen, die Sie verwenden möchten.
-
Deaktivieren Sie das Kontrollkästchen Rückverfolgung aktivieren, wenn es aktiviert ist. Globale Datenbanken von Aurora unterstützen keine Rückverfolgung. Sie können andernfalls die anderen Standardeinstellungen für die Zusätzliche Konfiguration akzeptieren.
-
Wählen Sie Create database (Datenbank erstellen) aus.
Es kann einige Minuten dauern, bis Aurora den Prozess zum Erstellen der Aurora-DB-Instance, ihrer Aurora Replica und des Aurora-DB-Clusters abgeschlossen hat. Sie können anhand des Status feststellen, wann der Aurora-DB-Cluster als primärer DB-Cluster in einer globalen Aurora-Datenbank verwendet werden kann. Wenn dies der Fall ist, lautet der Status und der des Writer- und Replikat-Knotens Verfügbar, wie nachstehend gezeigt.
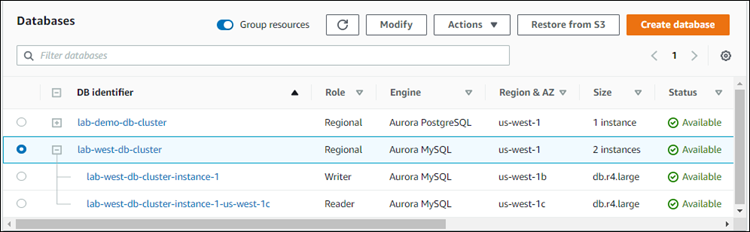
Wenn Ihr primärer DB-Cluster verfügbar ist, erstellen Sie die globale Aurora-Datenbank, indem Sie einen sekundären Cluster hinzufügen. Befolgen Sie dafür die unter Hinzufügen eines AWS-Region zu einer globalen Amazon Aurora Aurora-Datenbank beschriebenen Schritte.
Erstellen einer globalen Datenbank mit Aurora PostgreSQL
So erstellen Sie eine globale Aurora-Datenbank mit Aurora PostgreSQL
Füllen Sie die Seite Datenbank erstellen aus.
Wählen Sie unter Engine-Optionen Folgendes aus:
Wählen Sie für Engine-Version die Version von Aurora PostgreSQL, die Sie für Ihre Aurora globale Datenbank verwenden möchten.
Wählen Sie für VorlagenProduktion. Oder Sie können wählen, Dev/Test ob es angemessen ist. Nicht Dev/Test in Produktionsumgebungen verwenden.
Für Settings (Einstellungen) nehmen Sie folgendes vor:
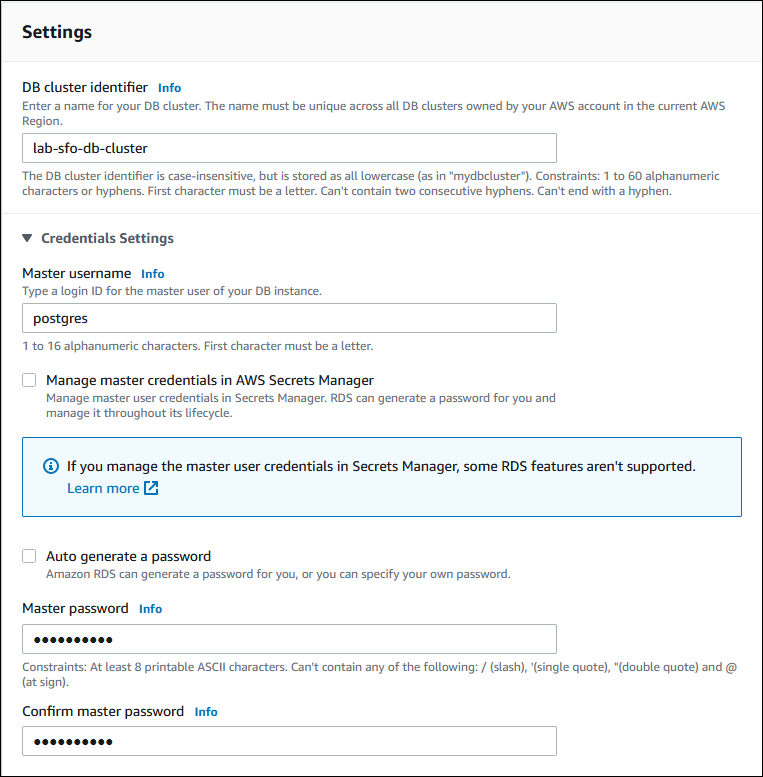
Geben Sie einen aussagekräftigen Namen für die DB-Cluster-ID ein. Wenn Sie mit dem Erstellen der Aurora globalen Datenbank fertig sind, identifiziert dieser Name den primären DB-Cluster.
Geben Sie Ihr eigenes Passwort für das Standard-Admin-Konto für den DB-Cluster ein, oder lassen Sie es Aurora für Sie generieren. Wenn Sie Auto generate a password (Ein Passwort automatisch erstellen) wählen, erhalten Sie die Option zum Kopieren des Passworts.
Wählen Sie für DB instance class (DB-Instance-Klasse)
db.r5.largeoder eine andere arbeitsspeicheroptimierte DB-Instance-Klasse aus. Wir empfehlen, db.r5 oder eine höhere Instance-Klasse zu nutzen.Für Verfügbarkeit und Haltbarkeit empfehlen wir Ihnen, Aurora für die Erstellung einer Aurora-Replica in einer anderen AZ für Sie zu wählen. Wenn Sie jetzt keine Aurora-Replica erstellen, müssen Sie dies später tun.
Wählen Sie bei Anbindung die auf Amazon VPC basierende Virtual Private Cloud (VPC) aus, die die virtuelle Netzwerkumgebung für diese DB-Instance definiert. Sie können die Standardwerte auswählen, um diese Aufgabe zu vereinfachen.
(Optional) Schließen Sie die Einstellungen für die Datenbankauthentifizierung ab. Die Passwortauthentifizierung ist immer aktiviert. Um den Prozess zu vereinfachen, können Sie diesen Abschnitt überspringen und später die IAM- oder Passwort- und Kerberos-Authentifizierung einrichten.
Für Zusätzliche Konfigurationen führen Sie die folgenden Schritte aus:
Geben Sie einen Namen für Anfänglicher Datenbankname ein, um die primäre Aurora-DB-Instance für diesen Cluster zu erstellen. Dies ist der Writer-Knoten für den Aurora primären DB-Cluster.
Belassen Sie die für die DB-Clusterparametergruppe und die DB-Parametergruppe ausgewählten Standardwerte, es sei denn, Sie haben Ihre eigenen benutzerdefinierten Parametergruppen, die Sie verwenden möchten.
Akzeptieren Sie alle anderen Standardeinstellungen für zusätzliche Konfigurationen wie Verschlüsselung, Protokollexporte usw.
-
Wählen Sie Datenbank erstellen aus.
Es kann einige Minuten dauern, bis Aurora den Prozess zum Erstellen der Aurora-DB-Instance, ihrer Aurora Replica und des Aurora-DB-Clusters abgeschlossen hat. Wenn der Cluster einsatzbereit ist, zeigen der Aurora-DB-Cluster und seine Writer- und Replica-Nodes den Status Verfügbar an. Dies wird der primäre DB-Cluster Ihrer Aurora globalen Datenbank, nachdem Sie einen sekundären Cluster hinzugefügt haben.
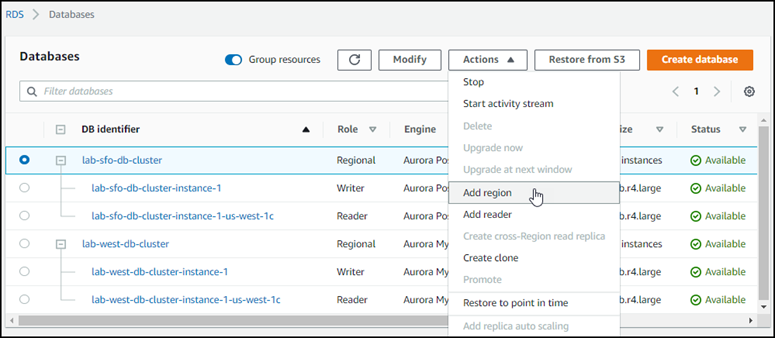
Wenn Ihr primäre DB-Cluster verfügbar ist, erstellen Sie einen oder mehrere sekundäre Cluster, indem Sie die Schritte Hinzufügen eines AWS-Region zu einer globalen Amazon Aurora Aurora-Datenbank.
Die AWS CLI Befehle in den folgenden Verfahren erfüllen die folgenden Aufgaben:
Erstellen einer globalen Aurora-Datenbank, Eingabe eines Namens und Spezifizierung des Typs der Aurora-Datenbank-Engine, den Sie verwenden möchten.
Erstellen Sie einen Aurora-DB-Cluster für die Aurora globale Datenbank.
Erstellen Sie eine Aurora-DB-Instance für den Cluster. Dies ist der primäre Aurora-DB-Cluster der globalen Datenbank.
Erstellen Sie eine zweite DB-Instance für den Aurora-DB-Cluster. Dies ist ein Reader zur Vervollständigung des Aurora-DB-Clusters.
Erstellen Sie einen zweiten Aurora-DB-Cluster in einer anderen Region und fügen Sie ihn dann Ihrer Aurora globalen Datenbank hinzu, indem Sie die unter beschriebenen Schritte ausführe Hinzufügen eines AWS-Region zu einer globalen Amazon Aurora Aurora-Datenbank.
Folgen Sie der Vorgehensweise für Ihre Aurora-Datenbank-Engine.
Erstellen einer globalen Datenbank mit Aurora MySQL
So erstellen Sie eine globale Aurora-Datenbank mit Aurora MySQL:
-
Verwenden Sie den
create-global-clusterCLI-Befehl und übergeben Sie den Namen der AWS-Region Aurora-Datenbank-Engine und die Version.Für Linux, macOS oder Unix:
aws rds create-global-cluster --regionprimary_region\ --global-cluster-identifierglobal_database_id\ --engine aurora-mysql \ --engine-versionversion# optionalFür Windows:
aws rds create-global-cluster ^ --global-cluster-identifierglobal_database_id^ --engine aurora-mysql ^ --engine-versionversion# optionalDadurch wird eine „leere“ Aurora globale Datenbank mit nur einem Namen (Identifier) und einer Aurora-Datenbank-Engine erstellt. Es kann einige Minuten dauern, bis die Aurora globale Datenbank verfügbar ist. Bevor Sie mit dem nächsten Schritt fortfahren, prüfen Sie mit dem
describe-global-clusters-CLI-Befehl, ob sie verfügbar ist.aws rds describe-global-clusters --regionprimary_region--global-cluster-identifierglobal_database_idWenn die Aurora globale Datenbank verfügbar ist, können Sie ihren primären Aurora-DB-Cluster erstellen.
Um einen primären Aurora-DB-Cluster zu erstellen, verwenden Sie den
create-db-cluster-CLI-Befehl. Fügen Sie den Namen Ihrer Aurora globalen Datenbank mit dem Parameter--global-cluster-identifierein.Für Linux, macOS oder Unix:
aws rds create-db-cluster \ --regionprimary_region\ --db-cluster-identifierprimary_db_cluster_id\ --master-usernameuserid\ --master-user-passwordpassword\ --engine aurora-mysql \ --engine-versionversion\ --global-cluster-identifierglobal_database_idFür Windows:
aws rds create-db-cluster ^ --regionprimary_region^ --db-cluster-identifierprimary_db_cluster_id^ --master-usernameuserid^ --master-user-passwordpassword^ --engine aurora-mysql ^ --engine-versionversion^ --global-cluster-identifierglobal_database_idVerwenden Sie den
describe-db-clustersAWS CLI Befehl, um zu bestätigen, dass der Aurora-DB-Cluster bereit ist. Um einen bestimmten Aurora-DB-Cluster herauszugreifen, verwenden Sie den Parameter--db-cluster-identifier. Oder Sie können den Aurora-DB-Cluster-Namen im Befehl weg lassen, um Details zu all Ihren Aurora-DB-Clustern in der angegebenen Region zu erhalten.aws rds describe-db-clusters --regionprimary_region--db-cluster-identifierprimary_db_cluster_idWenn die Antwort
"Status": "available"für den Cluster anzeigt, ist er einsatzbereit.Erstellen Sie die DB-Instance für Ihren primären Aurora-DB-Cluster. Verwenden Sie dazu den
create-db-instance-CLI-Befehl. Geben Sie den Namen Ihres Aurora-DB-Clusters an und geben Sie die Konfigurationsdetails für die Instance an. Sie müssen die Parameter--master-usernameund--master-user-passwordim Befehl nicht übergeben, da diese vom Aurora-DB-Cluster abgerufen werden.Für
--db-instance-classkönnen Sie nur arbeitsspeicheroptimierte Klassen verwenden, z. B.db.r5.large. Wir empfehlen, db.r5 oder eine höhere Instance-Klasse zu nutzen. Informationen zu diesen Klassen finden Sie unter DB-Instance-Klassenarten.Für Linux, macOS oder Unix:
aws rds create-db-instance \ --db-cluster-identifierprimary_db_cluster_id\ --db-instance-classinstance_class\ --db-instance-identifierdb_instance_id\ --engine aurora-mysql \ --engine-versionversion\ --regionprimary_regionFür Windows:
aws rds create-db-instance ^ --db-cluster-identifierprimary_db_cluster_id^ --db-instance-classinstance_class^ --db-instance-identifierdb_instance_id^ --engine aurora-mysql ^ --engine-versionversion^ --regionprimary_regionDie Operation
create-db-instancekann einige Zeit in Anspruch nehmen. Überprüfen Sie den Status, um festzustellen, ob die Aurora-DB-Instance verfügbar ist, bevor Sie fortfahren.aws rds describe-db-clusters --db-cluster-identifierprimary_db_cluster_idWenn der Befehl den Status
availablezurückgibt, können Sie eine weitere Aurora-DB-Instance für Ihren primären DB-Cluster erstellen. Dies ist die Reader-Instance (Aurora-Replica) für den Aurora-DB-Cluster.-
Um eine weitere Aurora-DB-Instance für den Cluster zu erstellen, verwenden Sie den
create-db-instance-CLI-Befehl.Für Linux, macOS oder Unix:
aws rds create-db-instance \ --db-cluster-identifierprimary_db_cluster_id\ --db-instance-classinstance_class\ --db-instance-identifierreplica_db_instance_id\ --engine aurora-mysqlFür Windows:
aws rds create-db-instance ^ --db-cluster-identifierprimary_db_cluster_id^ --db-instance-classinstance_class^ --db-instance-identifierreplica_db_instance_id^ --engine aurora-mysql
Wenn die DB-Instance verfügbar ist, beginnt die Replikation vom Writer-Knoten zum Replica. Bevor Sie fortfahren, überprüfen Sie, ob die DB-Instance mit dem describe-db-instances-CLI-Befehl verfügbar ist.
Zu diesem Zeitpunkt verfügen Sie über eine Aurora globale Datenbank mit ihrem primären Aurora-DB-Cluster, der eine Writer-DB-Instance und eine Aurora-Replica enthält. Sie können jetzt einen schreibgeschützten Aurora-DB-Cluster in einer anderen Region hinzufügen, um Ihre Aurora globale Datenbank zu vervollständigen. Eine Schritt-für-Schritt-Anleitung hierzu finden Sie unter Hinzufügen eines AWS-Region zu einer globalen Amazon Aurora Aurora-Datenbank.
Erstellen einer globalen Datenbank mit Aurora PostgreSQL
Wenn Sie mithilfe der folgenden Befehle Aurora-Objekte für eine globale Aurora-Datenbank erstellen, kann es einige Minuten dauern, bis jedes verfügbar ist. Wir empfehlen, dass Sie nach Abschluss eines bestimmten Befehls den Status des jeweiligen Aurora-Objekts überprüfen, um sicherzustellen, dass der Status „Verfügbar“ lautet.
Verwenden Sie dazu den describe-global-clusters-CLI-Befehl.
aws rds describe-global-clusters --regionprimary_region--global-cluster-identifierglobal_database_id
So erstellen Sie eine globale Aurora-Datenbank mit Aurora PostgreSQL
Verwenden Sie den
create-global-cluster-CLI-Befehl.Für Linux, macOS oder Unix:
aws rds create-global-cluster --regionprimary_region\ --global-cluster-identifierglobal_database_id\ --engine aurora-postgresql \ --engine-versionversion# optionalFür Windows:
aws rds create-global-cluster ^ --global-cluster-identifierglobal_database_id^ --engine aurora-postgresql ^ --engine-versionversion# optionalWenn die Aurora globale Datenbank verfügbar ist, können Sie ihren primären Aurora-DB-Cluster erstellen.
-
Um einen primären Aurora-DB-Cluster zu erstellen, verwenden Sie den
create-db-cluster-CLI-Befehl. Fügen Sie den Namen Ihrer Aurora globalen Datenbank mit dem Parameter--global-cluster-identifierein.Für Linux, macOS oder Unix:
aws rds create-db-cluster \ --regionprimary_region\ --db-cluster-identifierprimary_db_cluster_id\ --master-usernameuserid\ --master-user-passwordpassword\ --engine aurora-postgresql \ --engine-versionversion\ --global-cluster-identifierglobal_database_idFür Windows:
aws rds create-db-cluster ^ --regionprimary_region^ --db-cluster-identifierprimary_db_cluster_id^ --master-usernameuserid^ --master-user-passwordpassword^ --engine aurora-postgresql ^ --engine-versionversion^ --global-cluster-identifierglobal_database_idPrüfen Sie, ob der Aurora-DB-Cluster bereit ist. Wenn die Antwort des folgenden Befehls
"Status": "available"für den Aurora-DB-Cluster angezeigt wird, können Sie fortfahren.aws rds describe-db-clusters --regionprimary_region--db-cluster-identifierprimary_db_cluster_id Erstellen Sie die DB-Instance für Ihren primären Aurora-DB-Cluster. Verwenden Sie dazu den
create-db-instance-CLI-Befehl.Übergeben Sie den Namen Ihres Aurora-DB-Clusters mit dem Parameter
--db-cluster-identifier.Sie müssen die Parameter
--master-usernameund--master-user-passwordim Befehl nicht übergeben, da diese vom Aurora-DB-Cluster abgerufen werden.Für
--db-instance-classkönnen Sie nur arbeitsspeicheroptimierte Klassen verwenden, z. B.db.r5.large. Wir empfehlen, db.r5 oder eine höhere Instance-Klasse zu nutzen. Informationen zu diesen Klassen finden Sie unter DB-Instance-Klassenarten.Für Linux, macOS oder Unix:
aws rds create-db-instance \ --db-cluster-identifierprimary_db_cluster_id\ --db-instance-classinstance_class\ --db-instance-identifierdb_instance_id\ --engine aurora-postgresql \ --engine-versionversion\ --regionprimary_regionFür Windows:
aws rds create-db-instance ^ --db-cluster-identifierprimary_db_cluster_id^ --db-instance-classinstance_class^ --db-instance-identifierdb_instance_id^ --engine aurora-postgresql ^ --engine-versionversion^ --regionprimary_region-
Prüfen Sie den Status der Aurora-DB-Instance, bevor Sie fortfahren.
aws rds describe-db-clusters --db-cluster-identifierprimary_db_cluster_idWenn die Antwort zeigt, dass der Status der Aurora-DB-Instance
availablelautet, können Sie eine weitere Aurora-DB-Instance für Ihren primären DB-Cluster erstellen. -
Um eine Aurora-Replica für Aurora-DB-Cluster zu erstellen, verwenden Sie den
create-db-instanceCLI-Befehl.Für Linux, macOS oder Unix:
aws rds create-db-instance \ --db-cluster-identifierprimary_db_cluster_id\ --db-instance-classinstance_class\ --db-instance-identifierreplica_db_instance_id\ --engine aurora-postgresqlFür Windows:
aws rds create-db-instance ^ --db-cluster-identifierprimary_db_cluster_id^ --db-instance-classinstance_class^ --db-instance-identifierreplica_db_instance_id^ --engine aurora-postgresql
Wenn die DB-Instance verfügbar ist, beginnt die Replikation vom Writer-Knoten zum Replica. Bevor Sie fortfahren, überprüfen Sie, ob die DB-Instance mit dem describe-db-instances-CLI-Befehl verfügbar ist.
Ihre Aurora globale Datenbank existiert nun, verfügt aber nur in ihrer primären Region einen Aurora-DB-Cluster, der aus einer Writer-DB-Instance und einer Aurora-Replica besteht. Sie können jetzt einen schreibgeschützten Aurora-DB-Cluster in einer anderen Region hinzufügen, um Ihre Aurora globale Datenbank zu vervollständigen. Eine Schritt-für-Schritt-Anleitung hierzu finden Sie unter Hinzufügen eines AWS-Region zu einer globalen Amazon Aurora Aurora-Datenbank.
Führen Sie den CreateGlobalClusterVorgang aus, um eine globale Aurora-Datenbank mit der RDS-API zu erstellen.
