Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Funktionsweise von Aurora Serverless v1
Im Folgenden erfahren Sie, wie Aurora Serverless v1 funktioniert.
Themen
- Aurora Serverless v1-Architektur
- Automatische Skalierung für Aurora Serverless v1
- Timeout-Aktion für Kapazitätsänderungen
- Pausieren und Fortsetzen für Aurora Serverless v1
- Bestimmen der maximalen Anzahl von Datenbankverbindungen für Aurora Serverless v1
- Parametergruppen für Aurora Serverless v1
- Protokollierung für Aurora Serverless v1
- Aurora Serverless v1 und Wartung
- Aurora Serverless v1 und Failover
- Aurora Serverless v1 und Snapshots
Aurora Serverless v1-Architektur
Die folgende Abbildung zeigt einen Überblick über die Aurora Serverless v1-Architektur.
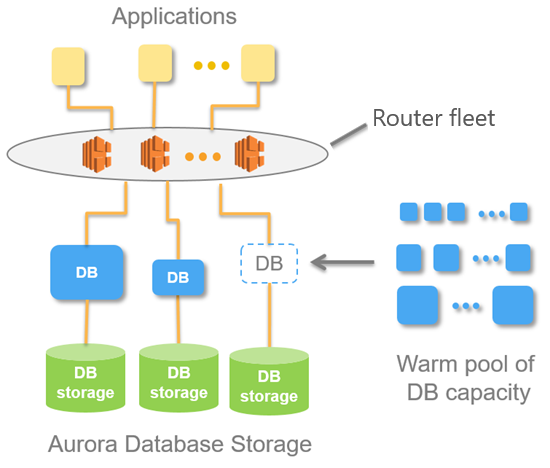
Anstelle der Bereitstellung und Verwaltung von Datenbankservern geben Sie Aurora Capacity Units (ACUs) an. Jede ACU ist eine Kombination aus etwa 2 Gigabyte (GB) Arbeitsspeicher, entsprechender CPU und Netzwerkleistung. Der Datenbankspeicher wird automatisch von 10 Gibibyte (GiB) auf 128 tebibytes (TiB) skaliert, genau wie Speicher in einem standardmäßigen Aurora-DB-Cluster.
Sie können die minimale und maximale ACU angeben. Die Mindestkapazitätseinheit von Aurora ist die kleinste ACU, auf die das DB-Cluster herabskaliert werden kann. Die maximale Kapazitätseinheit von Aurora ist die größte ACU, auf die das DB-Cluster hinaufskaliert werden kann. Basierend auf Ihren Einstellungen erstellt Aurora Serverless v1 automatisch Skalierungsregeln in Bezug auf Schwellenwerte für CPU-Auslastung, Verbindungen und verfügbaren Arbeitsspeicher.
Aurora Serverless v1 verwaltet den warmen Ressourcenpool in einer AWS-Region, um die Skalierungszeit zu minimieren. Wenn Aurora Serverless v1 dem Aurora-DB-Cluster neue Ressourcen hinzufügt, verwendet es die Routerflotte, um aktive Client-Verbindungen auf die neuen Ressourcen umzustellen. Zu jedem Zeitpunkt werden Ihnen nur die ACUs in Rechnung gestellt, die in Ihrem Aurora DB-Cluster aktiv genutzt werden.
Automatische Skalierung für Aurora Serverless v1
Die Ihrem Aurora Serverless v1-DB-Cluster zugewiesene Kapazität wird basierend auf der von Ihrer Client-Anwendung generierten Last nahtlos auf- und abwärts skaliert. Hier ist die Last die CPU-Auslastung und die Anzahl der Verbindungen. Wenn die Kapazität durch eine dieser beiden Faktoren eingeschränkt wird, wird Aurora Serverless v1 skaliert. Aurora Serverless v1 skaliert auch, wenn Leistungsprobleme erkannt werden, die dadurch gelöst werden können.
Sie können Skalierungsereignisse für Ihre Aurora Serverless v1-Cluster in AWS Management Console einsehen. Während der automatischen Skalierung setzt Aurora Serverless v1 die EngineUptime-Metrik zurück. Der Wert des zurückgesetzten Metrikwertes bedeutet weder, dass die nahtlose Skalierung Probleme hatte, noch, dass Aurora Serverless v1 Verbindungen unterbrochen hat. Er ist einfach der Ausgangspunkt für die Betriebszeit bei der neuen Kapazität. Weitere Informationen über Metriken finden Sie unter Überwachung von Metriken in einem Amazon-Aurora-Cluster.
Wenn Ihr Aurora Serverless v1-DB-Cluster keine aktiven Verbindungen hat, kann er auf Kapazität Null skaliert werden (0 ACUs). Weitere Informationen hierzu finden Sie unter Pausieren und Fortsetzen für Aurora Serverless v1.
Wenn er einen Skalierungsvorgang durchführen muss, versucht Aurora Serverless v1 zuerst einen Skalierungspunkt zu identifizieren, ein Moment, in dem keine Anfragen bearbeitet werden. Aurora Serverless v1 kann aus folgenden Gründen möglicherweise keinen Skalierungspunkt finden:
-
Lang laufende Anfragen
-
Transaktionen in Bearbeitung
-
Temporäre Tabellen oder Tabellensperren
Um die Erfolgsrate Ihres Aurora Serverless v1-DB-Clusters bei der Suche nach einem Skalierungspunkt zu erhöhen, empfehlen wir, lang andauernde Abfragen und lang andauernde Transaktionen zu vermeiden. Weitere Informationen zu Operationen zum Blockieren von Skalierungen und wie Sie diese vermeiden können, finden Sie unter Bewährte Methoden für die Arbeit mit Aurora Serverless v1
Standardmäßig versucht Aurora Serverless v1, einen Skalierungspunkt für 5 Minuten (300 Sekunden) zu finden. Sie können bei der Erstellung oder Änderung des Clusters eine andere Zeitspanne festlegen. Die Timeout-Zeit kann zwischen 60 Sekunden und 10 Minuten (600 Sekunden) liegen. Wenn Aurora Serverless v1 innerhalb des angegebenen Zeitraums keinen Skalierungspunkt finden kann, wird der Autoskalierungsvorgang abgebrochen.
Standardmäßig, wenn automatischen Skalierung vor dem Timeout keinen Skalierungspunkt findet, hält Aurora Serverless v1 den Cluster auf der aktuellen Kapazität. Sie können dieses Standardverhalten bei der Erstellung oder Änderung Ihres Aurora Serverless v1 DB-Clusters ändern, indem Sie die Option Kapazitätsänderung erzwingen auswählen. Weitere Informationen finden Sie unter Timeout-Aktion für Kapazitätsänderungen.
Timeout-Aktion für Kapazitätsänderungen
Wenn die automatische Skalierung abbricht, ohne einen Skalierungspunkt zu finden, behält Aurora standardmäßig die aktuelle Kapazität bei. Sie können festlegen, dass Aurora die Änderung erzwingt, indem Sie die Option Force the capacity change (Kapazitätsänderung erzwingen) aktivieren. Diese Option ist im Abschnitt Autoscaling timeout and action (Autoscaling-Timeout und -Aktion) auf der Seite Create database (Datenbank erstellen) verfügbar, wenn Sie den Cluster erstellen.
Standardmäßig ist die Option Force the capacity change (Kapazitätsänderung erzwingen) deaktiviert. Lassen Sie diese Option deaktiviert, damit die Kapazität Ihres Aurora Serverless v1-DB-Clusters unverändert bleibt, wenn der Skalierungsvorgang ausläuft, ohne einen Skalierungspunkt zu finden.
Wenn Sie diese Option aktivieren, erwzingt Ihr Aurora Serverless v1-DB-Cluster die Kapazitätsänderung auch ohne Skalierungspunkt. Bevor Sie diese Option auswählen, sollten Sie sich der Konsequenzen dieser Auswahl bewusst sein:
-
Alle In-Process-Transaktionen werden unterbrochen, und die folgende Fehlermeldung wird angezeigt.
Aurora MySQL Version 2 –
ERROR 1105 (HY000): Die letzte Transaktion wurde aufgrund nahtloser Skalierung abgebrochen. Bitte versuchen Sie es erneut.Sie können die Transaktion erneut übermitteln, sobald Ihr Aurora Serverless v1-DB-Cluster verfügbar ist.
-
Verbindungen zu temporären Tabellen und Sperren werden gelöscht.
Wir empfehlen, dass Sie die Option Force the capacity change (Kapazitätsänderung erzwingen) nur dann auswählen, wenn Ihre Anwendung nach unterbrochenen Verbindungen oder unvollständigen Transaktionen wiederhergestellt werden kann.
Die Entscheidungen, die Sie in der AWS Management Console treffen, wenn Sie einen Aurora Serverless v1-DB-Cluster erstellen, werden im Objekt ScalingConfigurationInfo in den Eigenschaften SecondsBeforeTimeout und TimeoutAction gespeichert. Der Wert der TimeoutAction-Eigenschaft wird bei der Erstellung Ihres Clusters auf einen der folgenden Werte festgelegt:
-
RollbackCapacityChange– Dieser Wert wird festgelegt, wenn Sie die Option Roll back the capacity change (Rückgängig machen der Kapazitätsänderung) auswählen. Dies ist das Standardverhalten. -
ForceApplyCapacityChange– Dieser Wert wird festgelegt, wenn Sie die Option Force the capacity change (Force the capacity change) auswählen.
Sie können den Wert dieser Eigenschaft für einen vorhandenen Aurora Serverless v1 DB-Cluster abrufen, indem Sie den -describe-db-clustersAWS CLIBefehl verwenden, wie im Folgenden gezeigt.
Für Linux, macOSoder Unix:
aws rds describe-db-clusters --regionregion\ --db-cluster-identifieryour-cluster-name\ --query '*[].{ScalingConfigurationInfo:ScalingConfigurationInfo}'
Windows:
aws rds describe-db-clusters --regionregion^ --db-cluster-identifieryour-cluster-name^ --query "*[].{ScalingConfigurationInfo:ScalingConfigurationInfo}"
Das folgende Beispiel zeigt die Abfrage und die Antwort für einen Aurora Serverless v1 DB-Cluster mit der Bezeichnung west-coast-sles in der Region US-West (Nordkalifornien).
$aws rds describe-db-clusters --region us-west-1 --db-cluster-identifier west-coast-sles --query '*[].{ScalingConfigurationInfo:ScalingConfigurationInfo}' [ { "ScalingConfigurationInfo": { "MinCapacity": 1, "MaxCapacity": 64, "AutoPause": false, "SecondsBeforeTimeout": 300, "SecondsUntilAutoPause": 300, "TimeoutAction": "RollbackCapacityChange" } } ]
Wie die Antwort zeigt, verwendet dieser Aurora Serverless v1-DB-Cluster die Standardeinstellung.
Weitere Informationen finden Sie unter Erstellen eines Aurora Serverless v1-DB Clusters. Nach Erstellung Ihres Aurora Serverless v1, können Sie die Timeout-Aktion und andere Kapazitätseinstellungen jederzeit ändern. Um zu erfahren wie, siehe Ändern eines Aurora Serverless v1-DB-Clusters.
Pausieren und Fortsetzen für Aurora Serverless v1
Sie können festlegen, Ihren Aurora Serverless v1-DB-Cluster nach einer bestimmten Zeit ohne Aktivität zu pausieren. Sie geben die Zeitspanne ohne Aktivität an, bevor der DB-Cluster angehalten wird. Wenn Sie diese Option auswählen, beträgt die standardmäßige Inaktivitätszeit fünf Minuten. Sie können diesen Wert jedoch ändern. Dies ist eine optionale Einstellung.
Wenn der DB-Cluster pausiert wird, findet keine Rechen- oder Speicheraktivität statt, und es wird Ihnen nur die Speicherung in Rechnung gestellt. Wenn beim Anhalten eines Aurora Serverless v1 DB-Clusters Datenbankverbindungen angefordert werden, nimmt der DB-Cluster die Verbindungsanforderungen automatisch wieder auf und bedient sie.
Wenn der DB-Cluster die Aktivität fortsetzt, hat er die gleiche Kapazität wie beim Anhalten des Clusters durch Aurora. Die Anzahl der ACUs hängt davon ab, wie stark Aurora den Cluster nach oben oder unten skaliert hat, bevor er angehalten wurde.
Anmerkung
Wenn ein DB-Cluster für mehr als sieben Tage pausiert wird, könnte der DB-Cluster mit einem Snapshot gesichert werden. In diesem Fall stellt Aurora den DB-Cluster aus dem Snapshot wieder her, wenn eine Verbindungsanforderung vorliegt.
Bestimmen der maximalen Anzahl von Datenbankverbindungen für Aurora Serverless v1
Im Folgenden sind einige Beispiele für einen DB-Cluster von Aurora Serverless v1 aufgeführt, der mit MySQL 5.7 kompatibel ist. Sie können einen MySQL-Client oder den Abfrage-Editor verwenden, wenn Sie den Zugriff darauf konfiguriert haben. Weitere Informationen finden Sie unter Ausführen von Abfragen im Abfrage-Editor.
So ermitteln Sie die maximale Anzahl von Datenbankverbindungen
-
Ermitteln Sie den Kapazitätsbereich für Ihren DB-Cluster von Aurora Serverless v1 mithilfe der AWS CLI.
aws rds describe-db-clusters \ --db-cluster-identifier my-serverless-57-cluster \ --query 'DBClusters[*].ScalingConfigurationInfo|[0]'Das Ergebnis zeigt, dass der Kapazitätsbereich 1 bis 4 ACU beträgt.
{ "MinCapacity": 1, "AutoPause": true, "MaxCapacity": 4, "TimeoutAction": "RollbackCapacityChange", "SecondsUntilAutoPause": 3600 } -
Führen Sie die folgende SQL-Abfrage aus, um die maximale Anzahl von Verbindungen zu ermitteln.
select @@max_connections;Das angezeigte Ergebnis gilt für die Mindestkapazität des Clusters, 1 ACU.
@@max_connections 90 -
Skalieren Sie den Cluster auf 8–32 ACU.
Weitere Informationen zur Skalierung finden Sie unter Ändern eines Aurora Serverless v1-DB-Clusters.
-
Bestätigen Sie den Kapazitätsbereich.
{ "MinCapacity": 8, "AutoPause": true, "MaxCapacity": 32, "TimeoutAction": "RollbackCapacityChange", "SecondsUntilAutoPause": 3600 } -
Suchen Sie die maximale Anzahl von Verbindungen.
select @@max_connections;Das angezeigte Ergebnis gilt für die Mindestkapazität des Clusters, 8 ACU.
@@max_connections 1000 -
Skalieren Sie den Cluster auf die maximal mögliche Kapazität, 256–256 ACU.
-
Bestätigen Sie den Kapazitätsbereich.
{ "MinCapacity": 256, "AutoPause": true, "MaxCapacity": 256, "TimeoutAction": "RollbackCapacityChange", "SecondsUntilAutoPause": 3600 } -
Suchen Sie die maximale Anzahl von Verbindungen.
select @@max_connections;Das angezeigte Ergebnis gilt für 256 ACU.
@@max_connections 6000Anmerkung
Der Wert
max_connectionsskaliert nicht linear mit der Anzahl der ACU. -
Skalieren Sie den Cluster wieder herunter auf 1–4 ACU.
{ "MinCapacity": 1, "AutoPause": true, "MaxCapacity": 4, "TimeoutAction": "RollbackCapacityChange", "SecondsUntilAutoPause": 3600 }Dieses Mal gilt der Wert
max_connectionsfür 4 ACU.@@max_connections 270 -
Lassen Sie den Cluster auf 2 ACU herunterskalieren.
@@max_connections 180Wenn Sie den Cluster so konfiguriert haben, dass er nach einer gewissen Zeit im Leerlauf pausiert, skaliert er auf 0 ACU herunter. Allerdings fällt
max_connectionsnicht unter den Wert für 1 ACU.@@max_connections 90
Parametergruppen für Aurora Serverless v1
Wenn Sie Ihren Aurora Serverless v1-DB-Cluster erstellen, wählen Sie eine bestimmte Aurora-DB-Engine und eine zugehörige DB-Cluster-Parametergruppe. Im Gegensatz zu bereitgestellten Aurora-DB-Clustern, hat ein Aurora Serverless v1-DB-Cluster eine einzige DB-Instance mit Lese-/Schreibzugriff, die nur mit einer DB-Cluster-Parametergruppe — konfiguriert ist. Er hat keine separate DB-Parametergruppe. Während der automatischen Skalierung, muss Aurora Serverless v1 in der Lage sein, Parameter zu ändern, damit der Cluster optimal für die erhöhte oder verringerte Kapazität funktioniert. Das heißt, dass bei einem Aurora Serverless v1-DB-Cluster, einige der Änderungen, die Sie an Parametern für einen bestimmten DB-Engine-Typ vornehmen, möglicherweise nicht gelten.
Zum Beispiel kann ein Aurora-PostgreSQL–basierter Aurora Serverless v1-DB-Cluster apg_plan_mgmt.capture_plan_baselines und andere Parameter nicht verwenden, die auf bereitgestellten Aurora PostgreSQL-DB-Clustern für die Verwaltung von Abfrageplänen verwendet werden könnten.
Sie können eine Liste der Standardwerte für die Standardparametergruppen für die verschiedenen Aurora-DB-Engines abrufen, indem Sie den CLI-Befehl describe-engine-default-cluster-parameters verwenden und abfragenAWS-Region. Die folgenden Werte können Sie für die --db-parameter-group-family-Option verwenden.
|
Aurora-MySQL-Version 2 |
|
|
Aurora-PostgreSQL-Version 11 |
|
|
Aurora PostgreSQL Version 13 |
|
Wir empfehlen Ihnen, Ihre AWS CLI mit Ihrer AWS-Zugriffsschlüssel-ID und Ihrem geheimen AWS-Zugriffsschlüssel zu konfigurieren, und Ihre AWS-Region vor der Verwendung der AWS CLI-Befehle einzustellen. Wenn Sie die Region Ihrer CLI-Konfiguration angeben, müssen Sie die --region-Parameter beim Ausführen von Befehlen nicht eingeben. Weitere Informationen über die Konfiguration von AWS CLI finden Sie unter Grundlagen der Konfiguration im AWS Command Line Interface-Benutzerhandbuch.
Im folgenden Beispiel wird eine Liste von Parametern aus der Standard-DB-Cluster-Gruppe für Aurora-MySQL-Version 2 gezeigt.
Für Linux, macOSoder Unix:
aws rds describe-engine-default-cluster-parameters \ --db-parameter-group-family aurora-mysql5.7 --query \ 'EngineDefaults.Parameters[*].{ParameterName:ParameterName,SupportedEngineModes:SupportedEngineModes} | [?contains(SupportedEngineModes, `serverless`) == `true`] | [*].{param:ParameterName}' \ --output text
Windows:
aws rds describe-engine-default-cluster-parameters ^ --db-parameter-group-family aurora-mysql5.7 --query ^ "EngineDefaults.Parameters[*].{ParameterName:ParameterName,SupportedEngineModes:SupportedEngineModes} | [?contains(SupportedEngineModes, 'serverless') == `true`] | [*].{param:ParameterName}" ^ --output text
Änderung von Parameterwerten für Aurora Serverless v1
Wie in Parametergruppen für Amazon Aurora erläutert, können Sie Werte in einer Standardparametergruppe unabhängig von ihrem Typ (DB-Cluster-Parametergruppe, DB-Parametergruppe) nicht direkt ändern. Stattdessen erstellen Sie eine benutzerdefinierte Parametergruppe basierend auf der standardmäßigen DB-Cluster-Parametergruppe für Ihre Aurora-DB-Engine und ändern die Einstellungen nach Bedarf für diese Parametergruppe. Sie können beispielsweise einige der Einstellungen für Ihren Aurora Serverless v1 DB-Cluster ändern, um Abfragen zu protokollieren oder DB-Engine-spezifische Protokolle in Amazon hochzuladen CloudWatch.
So erstellen Sie eine benutzerdefinierte DB-Cluster-Parametergruppe
-
Melden Sie sich bei der AWS Management Console an und öffnen Sie die Amazon-RDS-Konsole unter https://console.aws.amazon.com/rds/
. -
Wählen Sie Parameter groups (Parametergruppen).
-
Wählen Sie Parametergruppe erstellen aus, um den Parametergruppe-Detailbereich zu öffnen.
-
Wählen Sie die entsprechende Standard-DB-Cluster-Gruppe für die DB-Engine aus, die Sie für Ihren Aurora Serverless v1-DB-Cluster verwenden möchten. Wählen Sie dabei unbedingt die folgenden Optionen aus:
-
Wählen Sie unter Parametergruppenfamilie die entsprechende Familie für die von Ihnen gewählte DB-Engine aus. Achten Sie darauf, dass Ihre Auswahl das Präfix
aurora-im Namen enthält. -
Wählen Sie für Typ die Option DB-Cluster-Parametergruppe.
-
Geben Sie für Gruppenname und Beschreibung aussagekräftige Namen für Sie oder andere ein, die möglicherweise mit Ihrem Aurora Serverless v1-DB-Cluster und dessen Parametern arbeiten müssen.
-
Wählen Sie Create aus.
-
Ihre benutzerdefinierte DB-Cluster-Parametergruppe wird der Liste der Parametergruppen hinzugefügt, die in Ihrer AWS-Region verfügbar sind. Sie können Ihre benutzerdefinierte DB-Cluster-Parametergruppe verwenden, wenn Sie neue Aurora Serverless v1-DB-Cluster erstellen. Sie können auch einen vorhandenen Aurora Serverless v1-DB-Cluster anpassen, sodass ser Ihre benutzerdefinierte DB-Cluster-Parametergruppe verwendet. Nachdem Ihr Aurora Serverless v1-DB-Cluster mit der Verwendung Ihrer benutzerdefinierten DB-Cluster-Parametergruppe begonnen hat, können Sie die Werte für dynamische Parameter mithilfe von AWS Management Console oder AWS CLI ändern.
Sie können auch die Konsole verwenden, um einen side-by-side Vergleich der Werte in Ihrer benutzerdefinierten DB-Cluster-Parametergruppe im Vergleich zur Standard-DB-Cluster-Parametergruppe anzuzeigen, wie im folgenden Screenshot gezeigt.
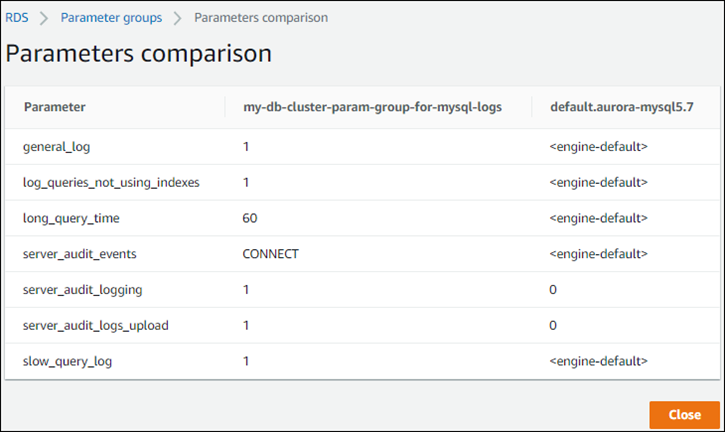
Wenn Sie Parameterwerte in einem aktiven DB-Cluster ändern, startet Aurora Serverless v1 eine nahtlose Skalierung, um die Parameteränderungen anzuwenden. Wenn Ihr Aurora Serverless v1-DB-Cluster sich in einem pausierten Zustand befindet, wird er fortgesetzt und beginnt mit der Skalierung, damit er die Änderung vornehmen kann. Der Skalierungsvorgang für eine Parametergruppe ändert immer Erzwingen einer Kapazitätsänderung. Beachten Sie daher, dass das Ändern von Parametern zu unterbrochenen Verbindungen führen kann, wenn während der Skalierungsperiode kein Skalierungspunkt gefunden werden kann.
Protokollierung für Aurora Serverless v1
Standardmäßig Aurora Serverless v1 werden Fehlerprotokolle für aktiviert und automatisch in Amazon hochgeladen CloudWatch. Sie können Ihren Aurora Serverless v1 DB-Cluster auch Aurora-Datenbank-Engine-spezifische Protokolle in hochladen lassen CloudWatch. Aktivieren Sie dazu die Konfigurationsparameter in Ihrer benutzerdefinierten DB-Cluster-Parametergruppe. Ihr Aurora Serverless v1 DB-Cluster lädt dann alle verfügbaren Protokolle auf Amazon hoch CloudWatch. An diesem Punkt können Sie verwenden, CloudWatch um Protokolldaten zu analysieren, Alarme zu erstellen und Metriken anzuzeigen.
Für Aurora MySQL zeigt die folgende Tabelle die Protokolle, die Sie aktivieren können. Wenn diese Option aktiviert ist, werden sie automatisch von Ihrem Aurora Serverless v1 DB-Cluster zu Amazon hochgeladen CloudWatch.
| Aurora-MySQL-Protokoll | Beschreibung |
|---|---|
|
|
Erstellt das allgemeine Protokoll. Stellen Sie zum Einschalten auf 1. Die Standardeinstellung ist aus (0). |
|
|
Protokolliert alle Abfragen im Slow-Query-Protokoll, das keinen Index verwendet. Die Standardeinstellung ist aus (0). Stellen Sie auf 1 ein, um dieses Protokoll zu aktivieren. |
|
|
Verhindert, dass schnell ablaufende Abfragen im Protokoll für langsame Abfragen protokolliert werden. Kann auf einen Gleitkommawert zwischen 0 und 31.536.000 festgelegt werden. Die Standardeinstellung ist 0 (nicht aktiv). |
|
|
Die Liste der Ereignisse, die in den Protokollen erfasst werden sollen. Unterstützte Werte sind |
|
|
Setzen Sie den Parameter auf 1, um die Serverprüfungsprotokollierung zu aktivieren. Wenn Sie dies aktivieren, können Sie die Audit-Ereignisse angeben, die an gesendet werden sollen, CloudWatch indem Sie sie im |
|
|
Erstellt ein Slow-Query-Protokoll. Auf 1 setzen, um das Slow-Query-Protokoll zu aktivieren. Die Standardeinstellung ist aus (0). |
Weitere Informationen finden Sie unter Verwenden von Advanced Auditing in einem Amazon Aurora MySQL DB-Cluster.
Für Aurora PostgreSQL zeigt die folgende Tabelle die Protokolle, die Sie aktivieren können. Wenn diese Option aktiviert ist, werden sie CloudWatch zusammen mit den regulären Fehlerprotokollen automatisch von Ihrem Aurora Serverless v1 DB-Cluster zu Amazon hochgeladen.
| Aurora-PostgreSQL-Protokoll | Beschreibung |
|---|---|
|
|
Standardmäßig aktiviert und kann nicht geändert werden. Protokolliert Details für alle neuen Client-Verbindungen. |
|
|
Standardmäßig aktiviert und kann nicht geändert werden. Protokolliert alle Client-Verbindungstrennungen. |
|
|
Standardmäßig deaktiviert und kann nicht geändert werden. Hostnamen werden nicht protokolliert. |
|
|
Der Standardwert ist 0 (aus). Stellen Sie auf 1 ein, um die Wartezeiten für die Sperrung zu protokollieren. |
|
|
Die Mindestdauer (in Millisekunden), die eine Anweisung vor der Protokollierung ausgeführt wird. |
|
|
Legt die Nachrichtenebenen fest, die protokolliert werden. Unterstützte Werte sind , , , , , , , , , , und Zum Protokollieren von Leistungsdaten im |
|
|
Protokolliert die Verwendung von temporären Dateien, die über den angegebenen Kilobyte (kB) liegen. |
|
|
Steuert die spezifischen SQL-Anweisungen, die protokolliert werden. Unterstützte Werte sind |
Nachdem Sie die Protokolle für Aurora MySQL oder Aurora PostgreSQL für Ihren Aurora Serverless v1 DB-Cluster aktiviert haben, können Sie die Protokolle in anzeigen CloudWatch.
Anzeigen von Aurora Serverless v1 Protokollen mit Amazon CloudWatch
Aurora Serverless v1 lädt automatisch alle CloudWatch Protokolle, die in Ihrer benutzerdefinierten DB-Cluster-Parametergruppe aktiviert sind, in Amazon hoch („veröffentlicht“). Sie müssen die Protokolltypen nicht auswählen oder angeben. Das Hochladen von Protokollen beginnt, sobald Sie den Protokollkonfigurationsparameter aktivieren. Wenn Sie den Protokoll-Parameter später deaktivieren, werden weitere Uploads angehalten. Alle Protokolle, die bereits veröffentlicht wurden, CloudWatch verbleiben jedoch, bis Sie sie löschen.
Weitere Informationen zur Verwendung von CloudWatch mit Aurora MySQL-Protokollen finden Sie unter Überwachen von Protokollereignissen in Amazon CloudWatch.
Weitere Informationen zu CloudWatch und Aurora PostgreSQL finden Sie unter Veröffentlichen von Aurora-PostgreSQL-Protokollen in Amazon CloudWatch Logs.
So zeigen Sie Protokolle für Ihren Aurora Serverless v1-DB-Cluster an:
Öffnen Sie die - CloudWatch Konsole unter https://console.aws.amazon.com/cloudwatch/
. -
Wählen Sie Ihre AWS-Region.
-
Wählen Sie Protokollgruppen.
-
Wählen Sie Ihr DB-Cluster-Protokoll für Aurora Serverless v1 in der Liste aus. Bei Fehlerprotokollen ist das Benennungsmuster wie folgt:
/aws/rds/cluster/cluster-name/error
Im folgenden Screenshot finden Sie beispielsweise Verzeichnisse für Protokolle, die für einen Aurora PostgreSQL Aurora Serverless v1-DB-Cluster namens western-sles veröffentlicht wurden. Sie können auch mehrere Verzeichnisse für Aurora MySQL Aurora Serverless v1-DB-Cluster west-coast-sles finden. Wählen Sie das gewünschte Protokoll aus, um sich den Inhalt anzusehen.
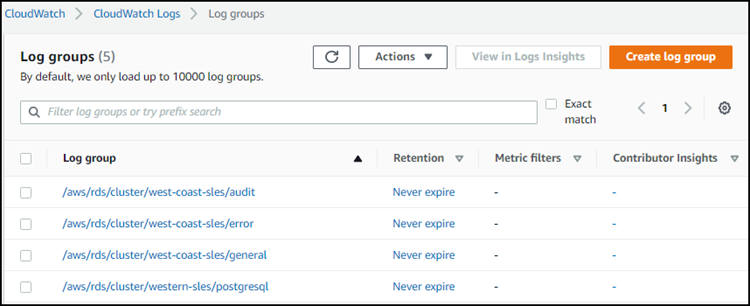
Aurora Serverless v1 und Wartung
Die Wartung für Aurora Serverless v1-DB-Cluster, wie die Anwendung der neuesten Funktionen, Fehlerbehebungen und Sicherheitsupdates, wird automatisch für Sie durchgeführt. Aurora Serverless v1verfügt über ein Wartungsfenster, das Sie in der AWS Management Console unter Wartung und Sicherungen) für Ihren Aurora Serverless v1-DB-Cluster anzeigen können. Sie finden das Datum und die Uhrzeit, zu der die Wartung möglicherweise durchgeführt wird, und ob Wartungsarbeiten für Ihren Aurora Serverless v1 DB-Cluster ausstehen, wie in der folgenden Abbildung dargestellt.
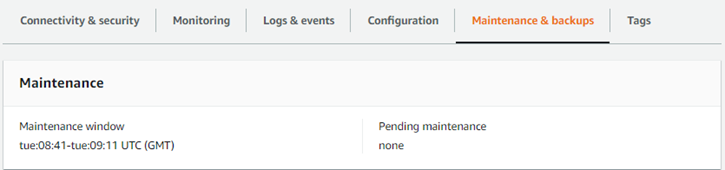
Sie können das Wartungsfenster festlegen, wenn Sie den Aurora Serverless v1-DB-Cluster erstellen, und Sie können das Fenster später ändern. Weitere Informationen finden Sie unter Anpassen des bevorzugten DB-Cluster-Wartungsfensters.
Wartungsfenster werden für geplante Hauptversions-Upgrades verwendet. Nebenversions-Upgrades und Patches werden sofort während der Skalierung angewendet. Die Skalierung erfolgt entsprechend Ihrer Einstellung für TimeoutAction:
-
ForceApplyCapacityChange– Die Änderung wird sofort angewendet. -
RollbackCapacityChange– Aurora aktualisiert den Cluster erzwingend nach 3 Tagen ab dem ersten Patch-Versuch.
Wie bei jeder Änderung, die ohne einen geeigneten Skalierungspunkt erzwungen wird, kann Ihr Workload dadurch unterbrochen werden.
Wann immer möglich, führt Aurora Serverless v1 die Wartung unterbrechungsfrei durch. Wenn eine Wartung erforderlich ist, skaliert Ihr Aurora Serverless v1-DB-Cluster seine Kapazität, damit die erforderlichen Vorgänge durchgeführt werden können. Vor dem Skalieren sucht Aurora Serverless v1 nach einem Skalierungspunkt. Dies geschieht bei Bedarf bis zu drei Tage lang.
Am Ende jedes Tages, an dem Aurora Serverless v1 keinen Skalierungspunkt finden kann, erstellt es ein Cluster-Ereignis. Dieses Ereignis informiert Sie über die ausstehende Wartung und die Notwendigkeit einer Skalierung für die Durchführung der Wartung. Die Benachrichtigung enthält auch das Datum, an dem Aurora Serverless v1 die Skalierung des DB-Clusters erzwingen kann.
Weitere Informationen finden Sie unter Timeout-Aktion für Kapazitätsänderungen.
Aurora Serverless v1 und Failover
Wenn die DB-Instance für einen Aurora Serverless v1-DB-Cluster nicht mehr verfügbar ist oder die Availability Zone (AZ), in der sie sich befindet, ausfällt, erstellt Aurora die DB-Instance in einer anderen AZ neu. Allerdings ist der Aurora Serverless v1-Cluster kein Multi-AZ-Cluster. Das liegt daran, dass er aus einer einzigen DB-Instance in einer einzigen AZ besteht. Dieser Failover-Mechanismus benötigt mehr Zeit als bei einem Aurora-Cluster mit bereitgestellten oder Aurora Serverless v2-Instances. Die Failover-Zeit für Aurora Serverless v1 ist nicht definiert, da sie von der Nachfrage sowie der Kapazität abhängt, die in anderen AZs innerhalb der angegebenen AWS-Region verfügbar ist.
Da Aurora die Datenverarbeitungskapazität und den Speicher voneinander trennt, ist das Speichervolumen für den Cluster auf mehrere AZs verteilt. Ihre Daten bleiben auch bei Ausfällen der DB-Instance oder der zugehörigen AZ verfügbar.
Aurora Serverless v1 und Snapshots
Das Cluster-Volume für einen Aurora Serverless v1-Cluster ist immer verschlüsselt. Sie können den Verschlüsselungsschlüssel auswählen, aber Sie können die Verschlüsselung nicht deaktivieren. Zum Kopieren oder Freigeben eines Snapshots eines Aurora Serverless v1-Clusters verschlüsseln Sie den Snapshot mit Ihrem eigenen AWS KMS key. Weitere Informationen finden Sie unter Kopieren eines DB-Cluster-Snapshots. Weitere Informationen zur Verschlüsselung und zu Amazon Aurora finden Sie unter Verschlüsseln eines Amazon-Aurora-DB-Clusters.
