Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Tutorial: Erste Schritte mit S3 Express One Zone
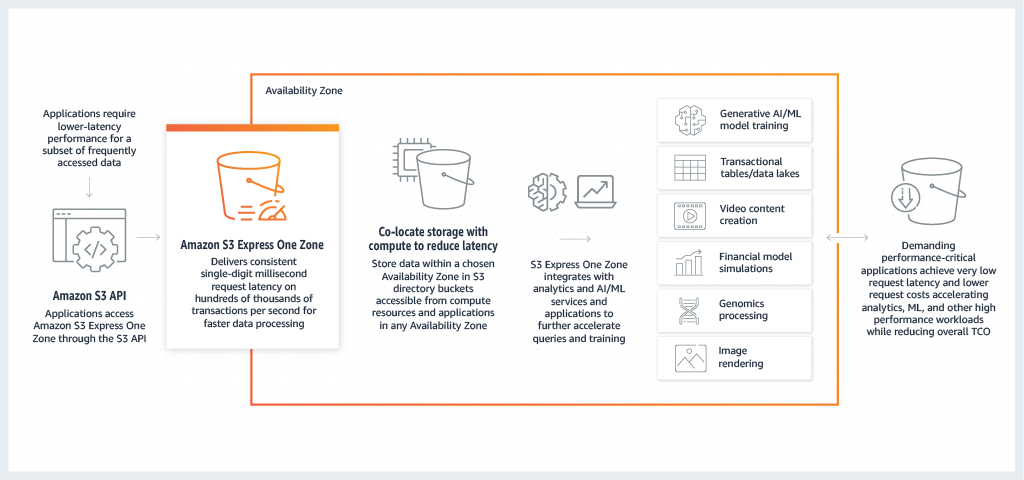
Amazon S3 Express One Zone ist die erste S3-Speicherklasse, bei der Sie eine einzelne Availability Zone mit der Option auswählen können, Ihren Objektspeicher zusammen mit Ihren Rechenressourcen zu platzieren, was die höchstmögliche Zugriffsgeschwindigkeit bietet. Daten in S3 Express One Zone werden in Verzeichnis-Buckets gespeichert, die sich in Availability Zones befinden. Weitere Informationen zu Verzeichnis-Buckets finden Sie unter Verzeichnis-Buckets.
S3 Express One Zone ist ideal für jede Anwendung, bei der es entscheidend ist, die Anforderungslatenz zu minimieren. Bei solchen Anwendungen kann es sich um Workflows handeln, mit denen Menschen interagieren, z. B. bei der Videobearbeitung, wo kreative Mitarbeiter über ihre Benutzeroberflächen schnell auf Inhalte zugreifen müssen. S3 Express One Zone bietet auch Vorteile für Analysen und Machine Learning, die ähnliche Anforderungen an die Reaktionsfähigkeit ihrer Daten stellen, insbesondere Workloads mit vielen kleineren Zugriffen oder einer großen Anzahl zufälliger Zugriffe. S3 Express One Zone kann mit anderen AWS Diensten wie Amazon EMR, Amazon Athena, AWS Glue Data Catalog und Amazon SageMaker Model Training verwendet werden, um Workloads für Analysen, künstliche Intelligenz und maschinelles Lernen (AI/ML) zu unterstützen. Sie können mit der Speicherklasse und den Verzeichnis-Buckets von S3 Express One Zone arbeiten, indem Sie die Amazon S3 S3-Konsole, AWS SDKs, die AWS Befehlszeilenschnittstelle (AWS CLI) und die Amazon S3 S3-REST-API verwenden. Weitere Informationen finden Sie unter Was ist S3 Express One Zone? und Wodurch zeichnet sich S3 Express One Zone aus?.
Ziel
In diesem Tutorial erfahren Sie, wie Sie einen Gateway-Endpunkt erstellen, eine IAM-Richtlinie erstellen und anhängen, einen Verzeichnis-Bucket erstellen und dann die Import-Aktion verwenden, um Ihren Verzeichnis-Bucket mit Objekten zu füllen, die derzeit in Ihrem Allzweck-Bucket gespeichert sind. Alternativ können Sie Objekte manuell in Ihre Verzeichnis-Bucket hochladen.
Themen
Schritt 2: Erstellen eines S3 Express One Zone-Verzeichnis-Buckets
Schritt 3: Importieren von Daten in einen S3 Express One Zone-Verzeichnis-Bucket
Schritt 4: Manuelles Hochladen von Objekten in Ihr S3 Express One Zone-Verzeichnis-Bucket
Schritt 5: Leeren Sie Ihren S3 Express One Zone-Verzeichnis-Bucket
Schritt 6: Löschen Sie Ihren S3 Express One Zone-Verzeichnis-Bucket
Voraussetzungen
Bevor Sie mit diesem Tutorial beginnen, benötigen Sie einen AWS-Konto , bei dem Sie sich als AWS Identity and Access Management (IAM-) Benutzer mit den richtigen Berechtigungen anmelden können.
Teilschritte
Erstellen Sie ein AWS-Konto
Um dieses Tutorial abzuschließen, benötigen Sie eine AWS-Konto. Wenn Sie sich für registrieren AWS, AWS-Konto ist Ihr automatisch für alle Services angemeldet AWS, einschließlich Amazon S3. Berechnet werden Ihnen aber nur die Services, die Sie nutzen. Weitere Informationen zu Preisen finden Sie unter S3 – Preise
Erstellen Sie einen IAM-Benutzer in Ihrem AWS-Konto (Konsole)
AWS Identity and Access Management (IAM) hilft Administratoren dabei AWS-Service , den Zugriff auf AWS Ressourcen sicher zu kontrollieren. IAM-Administratoren steuern, wer authentifiziert (angemeldet) und autorisiert (Berechtigungen erhalten) werden kann, um auf Objekte zuzugreifen und Verzeichnis-Buckets in S3 Express One Zone zu nutzen. Sie können IAM ohne zusätzliche Kosten nutzen.
Standardmäßig haben Benutzer keine Berechtigungen, um auf Verzeichnis-Buckets zuzugreifen und Operationen in S3 Express One Zone auszuführen. Um Zugriffsberechtigungen für Verzeichnis-Buckets und S3-Express-One-Zone-Vorgänge zu gewähren, können Sie IAM verwenden, um Benutzer oder Rollen zu erstellen und diesen Identitäten Berechtigungen zuzuweisen. Weitere Informationen zum Erstellen eines IAM-Benutzers finden Sie unter Erstellen von IAM-Benutzern (Konsole) im IAM-Benutzerhandbuch. Weitere Informationen zum Erstellen einer IAM-Rolle finden Sie unter Erstellen einer Rolle zum Delegieren von Berechtigungen an einen IAM-Benutzer im IAM-Benutzerhandbuch.
Der Einfachheit halber wird in diesem Tutorial einen IAM-Benutzer erstellt und verwendet. Denken Sie nach Abschluss dieses Tutorials an Löschen des IAM-Benutzers. Für den Einsatz in der Produktion empfehlen wir, dass Sie die bewährten Sicherheitsmethoden in IAM im IAM-Benutzerhandbuch befolgen. Eine bewährte Methode ist, dass menschliche Benutzer den Verbund mit einem Identitätsanbieter verwenden, um mit temporären Anmeldeinformationen auf AWS zuzugreifen. Eine weitere bewährte Methode besteht darin, dass Workloads temporäre Anmeldeinformationen mit IAM-Rollen verwenden müssen, um auf AWS zuzugreifen. Weitere Informationen AWS IAM Identity Center zur Erstellung von Benutzern mit temporären Anmeldeinformationen finden Sie unter Erste Schritte im AWS IAM Identity Center Benutzerhandbuch.
Warnung
IAM-Benutzer verfügen über langfristige Anmeldeinformationen, was ein Sicherheitsrisiko darstellt. Um dieses Risiko zu minimieren, empfehlen wir, diesen Benutzern nur die Berechtigungen zu gewähren, die sie für die Ausführung der Aufgabe benötigen, und diese Benutzer zu entfernen, wenn sie nicht mehr benötigt werden.
Erstellen Sie eine IAM-Richtlinie und fügen Sie diese an einen IAM-Benutzer oder eine -Rolle (Konsole) an.
Standardmäßig haben Benutzer keine Berechtigungen für Verzeichnis-Buckets und S3-Express-One-Zone-Vorgänge. Um Zugriffsberechtigungen für Verzeichnis-Buckets zu gewähren, können Sie IAM verwenden, um Benutzer, Gruppen oder Rollen zu erstellen und diesen Identitäten Berechtigungen zuzuweisen. Verzeichnis-Buckets sind die einzige Ressource, die Sie in Bucket-Richtlinien oder IAM-Identitätsrichtlinien für den Zugriff auf S3 Express One Zone aufnehmen können.
Um regionale Endpunkt-API-Operationen (Operationen auf Bucket-Ebene oder Steuerebene) mit S3 Express One Zone zu verwenden, verwenden Sie das IAM-Autorisierungsmodell, das kein Sitzungsmanagement beinhaltet. Berechtigungen werden für Aktionen einzeln erteilt. Um API-Vorgänge für zonale Endpunkte (Vorgänge auf Objektebene oder Datenebene) zu verwenden, verwenden Sie CreateSession, um Sitzungen zu erstellen und zu verwalten, die für die Autorisierung von Datenanforderungen mit geringer Latenz optimiert sind. Um ein Sitzungstoken abzurufen und zu verwenden, müssen Sie die s3express:CreateSession-Aktion für Ihren Verzeichnis-Bucket in einer identitätsbasierten Richtlinie oder einer Bucket-Richtlinie zulassen. Wenn Sie in der Amazon S3-Konsole, über die AWS Befehlszeilenschnittstelle (AWS CLI) oder mithilfe der AWS SDKs auf S3 Express One Zone zugreifen, erstellt S3 Express One Zone in Ihrem Namen eine Sitzung. Weitere Informationen finden Sie unter CreateSession-Autorisierung und AWS Identity and Access Management (IAM) für S3 Express One Zone.
So erstellen Sie eine benutzerdefinierte IAM-Richtlinie und fügen diese an einen IAM-Benutzer (oder eine Rolle) an
Melden Sie sich bei der AWS Management Console an und öffnen Sie die IAM Management Console.
Wählen Sie im Navigationsbereich Richtlinien.
Wählen Sie Richtlinie erstellen aus.
Wählen Sie JSON aus.
Kopieren Sie die nachstehende Richtlinie in das Fenster Richtlinien-Editor. Bevor Sie Verzeichnis-Buckets erstellen oder S3 Express One Zone verwenden können, müssen Sie Ihrer AWS Identity and Access Management (IAM-) Rolle oder Ihren Benutzern die erforderlichen Berechtigungen erteilen. Diese Beispielrichtlinie erlaubt den Zugriff auf die
CreateSession-API-Operation (zur Verwendung mit anderen zonalen oder objektbezogenen API-Operationen) sowie auf alle API-Operationen des regionalen Endpunkts (Bucket-Ebene). Diese Richtlinie ermöglicht die Verwendung desCreateSession-API-Vorgangs mit allen Verzeichnis-Buckets, aber die API-Operationen für regionale Endpunkte sind nur für die Verwendung mit dem angegebenen Verzeichnis-Bucket zulässig. Wenn Sie diese Beispielrichtlinie verwenden möchten, ersetzen Sieuser input placeholdersWählen Sie Weiter aus.
Benennen Sie die Richtlinie.
Anmerkung
Bucket-Tags werden für S3 Express One Zone nicht unterstützt.
-
Wählen Sie Richtlinie erstellen.
-
Nachdem Sie eine IAM-Richtlinie erstellt haben, können Sie sie einem IAM-Benutzer anfügen. Wählen Sie im Navigationsbereich Richtlinien.
Geben Sie im Suchfeld den Namen der Richtlinie ein.
Wählen Sie im Menü Aktionen die Option Anhängen aus.
Wählen Sie unter Nach Entitätstyp filtern die Option IAM-Benutzer oder Rollen aus.
GebenSie im Suchfeld den Namen des Benutzers oder der Rolle ein, den/die Sie verwenden möchten.
Wählen Sie Richtlinie anfügen aus.
Themen
Nächste Schritte
In diesem Tutorial haben Sie gelernt, wie man einen Verzeichnis-Bucket erstellt und die Speicherklasse S3 Express One Zone verwendet. Nach Abschluss dieses Tutorials können Sie verwandte AWS -Services für die Verwendung mit der Speicherklasse S3 Express One Zone erkunden.
Sie können Folgendes AWS-Services mit der S3 Express One Zone-Speicherklasse verwenden, um Ihren speziellen Anwendungsfall mit niedriger Latenz zu unterstützen.
-
Amazon Elastic Compute Cloud (Amazon EC2) – Amazon EC2 bietet sichere und skalierbare Rechenkapazität in der AWS Cloud. Amazon EC2 reduziert die Notwendigkeit, im Voraus in Hardware investieren zu müssen. Daher können Sie Anwendungen schneller entwickeln und bereitstellen. Mit Amazon EC2 können Sie so viele oder so wenige virtuelle Server starten, wie Sie benötigen, die Sicherheit und das Netzwerk konfigurieren und den Speicher verwalten.
-
AWS Lambda – Lambda ist ein Computingservice, mit dem Sie Code ausführen können, ohne Server bereitstellen oder verwalten zu müssen. Sie konfigurieren Benachrichtigungseinstellungen für einen Bucket und erteilen die Amazon-S3-Berechtigung zum Aufrufen einer Funktion in der ressourcenbasierten Berechtigungsrichtlinie der Funktion.
-
Amazon Elastic Kubernetes Service (Amazon EKS) — Amazon EKS ist ein verwalteter Service, der die Installation, den Betrieb und die Wartung Ihrer eigenen Kubernetes Steuerungsebene überflüssig macht. AWSKubernetes
ist ein Open-Source-System, das die Verwaltung, Skalierung und Bereitstellung von containerisierten Anwendungen automatisiert. -
Amazon Elastic Container Service (Amazon ECS) – Amazon ECS ist ein vollständig verwalteter Container-Orchestrierungsservice, mit dem Sie containerisierte Anwendungen einfach bereitstellen, verwalten und skalieren können.
-
Amazon EMR — Amazon EMR ist eine verwaltete Cluster-Plattform, die den Betrieb von Big-Data-Frameworks vereinfacht, z. Apache Hadoop B. Apache Spark AWS zur Verarbeitung und Analyse riesiger Datenmengen.
-
Amazon Athena – Athena ist ein interaktiver Abfrageservice, der die Analyse von Daten in Amazon S3 mit Standard-SQL erleichtert. Athena vereinfacht auch die interaktive Ausführung von Datenanalysen mit Apache Spark, ohne Ressourcen planen, konfigurieren oder verwalten zu müssen. Wenn Sie Apache Spark-Anwendungen auf Athena ausführen, übermitteln Sie Spark-Code zur Verarbeitung und erhalten die Ergebnisse direkt.
-
AWS Glue Data Catalog — AWS Glue ist ein serverloser Datenintegrationsdienst, der es Analytics-Benutzern erleichtert, Daten aus mehreren Quellen zu entdecken, aufzubereiten, zu verschieben und zu integrieren. Sie können ihn AWS Glue für Analysen, maschinelles Lernen und Anwendungsentwicklung verwenden. AWS Glue Data Catalog ist ein zentrales Repository, das Metadaten zu den Datensätzen Ihres Unternehmens speichert. Es ein Index für die Speicherort-, Schema- und Laufzeitmetriken Ihrer Datenquellen.
-
Amazon SageMaker Runtime Model Training — Amazon SageMaker Runtime ist ein vollständig verwalteter Service für maschinelles Lernen. Mit SageMaker Runtime können Datenwissenschaftler und Entwickler schnell und einfach Modelle für maschinelles Lernen erstellen und trainieren und sie dann direkt in einer produktionsbereiten gehosteten Umgebung bereitstellen.
Weitere Informationen zu S3 Express One Zone finden Sie unter Was ist S3 Express One Zone? und Wodurch zeichnet sich S3 Express One Zone aus?.
