Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Arbeiten mit Amazon S3 S3-Dateien
Was sind S3-Dateien?
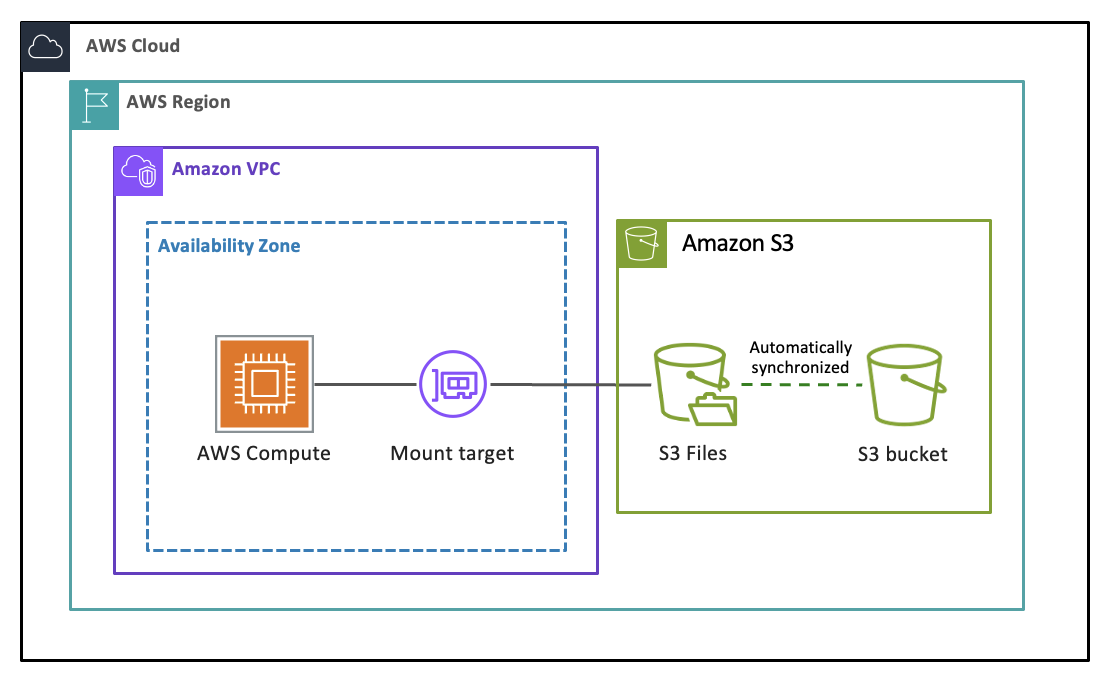
S3 Files ist ein gemeinsam genutztes Dateisystem, das jede AWS Rechenressource direkt mit Ihren Daten in Amazon S3 verbindet. Es bietet schnellen, direkten Zugriff auf all Ihre S3-Daten als Dateien mit vollständiger Dateisystemsemantik und geringer Latenz, ohne dass Ihre Daten S3 jemals verlassen. Jede dateibasierte Anwendung, jeder Agent und jedes Team können mithilfe der Tools, von denen sie bereits abhängig sind, auf Ihre S3-Daten als Dateisystem zugreifen und mit ihnen arbeiten. S3 Files wurde mit Amazon EFS entwickelt und bietet Ihnen die Leistung und Einfachheit eines Dateisystems mit der Skalierbarkeit, Haltbarkeit und Kosteneffektivität von S3. Sie können Daten mithilfe von Datei- und Verzeichnisoperationen lesen, schreiben und organisieren, während S3 Files die Synchronisation von Änderungen zwischen Ihrem Bucket und dem Dateisystem verwaltet.
Wie funktioniert S3 Files?
Wenn Sie ein S3-Dateisystem erstellen, das mit Ihrem S3-Bucket oder einem darin enthaltenen Präfix verknüpft ist, und es auf einer Rechenressource wie einer EC2-Instance oder einer Lambda-Funktion mounten, bietet S3 Files zunächst eine durchsuchbare Ansicht der Objekte Ihres Buckets als Dateien. Wenn Sie durch Verzeichnisse navigieren und Dateien öffnen, werden die zugehörigen Metadaten und Inhalte auf dem Hochleistungsspeicher des Dateisystems abgelegt. Wenn Sie Dateien lesen, lädt S3 Files bei Bedarf Dateiinhalte in den Hochleistungsspeicher, ohne dass Ihr gesamter Datensatz dupliziert wird. Wenn Sie Daten schreiben, werden Ihre Schreibvorgänge in den Hochleistungsspeicher verschoben und wieder mit Ihrem S3-Bucket synchronisiert. S3 Files übersetzt Ihre Dateisystemoperationen auf intelligente Weise in effiziente S3-Anfragen in Ihrem Namen. Bei vielen Lesevorgängen wird das Dateisystem vollständig umgangen, da die Daten direkt von S3 aus bereitgestellt werden.
Sie können den Schwellenwert für die Dateigröße für das konfigurieren, was auf den Hochleistungsspeicher geladen wird (Standard <128 KiB), da Latenzen bei kleinen Dateien am wichtigsten sind. S3 Files streamt Dateilesevorgänge in zwei Fällen direkt aus Ihrem S3-Bucket: wenn die Daten der Datei nicht im Hochleistungsspeicher des Dateisystems gespeichert sind, und bei großen Lesevorgängen >= 1 MiB, auch wenn sich die Daten auch auf dem Hochleistungsspeicher des Dateisystems befinden. Der S3-Bucket ist für einen hohen Durchsatz optimiert, während die Hochleistungsspeicherschicht des Dateisystems für den Zugriff mit niedriger Latenz optimiert ist. S3 Files importiert asynchron Daten für kleine Dateien (standardmäßig < 128 KiB) in den Hochleistungsspeicher des Dateisystems für den Zugriff mit geringer Latenz bei nachfolgenden Lesevorgängen. Kürzlich geänderte Daten, die noch nicht mit S3 synchronisiert wurden, werden immer vom Dateisystem aus bereitgestellt. Weitere Informationen finden Sie unter Synchronisation für S3-Dateien anpassen.
Daten, die nicht innerhalb eines konfigurierbaren Fensters (1 bis 365 Tage, Standard 30) gelesen wurden, laufen automatisch aus dem Hochleistungsspeicher ab. Ihre verlässlichen Daten verbleiben immer in S3, und die Hintergrundsynchronisierung sorgt dafür, dass das Dateisystem und der Bucket in beide Richtungen konsistent sind. Weitere Informationen finden Sie unter Verstehen, wie die Synchronisation funktioniert.
Unterstützte Rechendienste zum Mounten Ihrer S3-Dateisysteme sind Amazon EC2 AWS Lambda, Amazon EKS und Amazon ECS. Weitere Informationen finden Sie unter Mounten Ihrer S3-Buckets auf Rechenressourcen.
Verwenden Sie S3 Files zum ersten Mal?
Wenn Sie S3 Files zum ersten Mal verwenden, erstellen Sie Ihr erstes S3-Dateisystem mithilfe der S3-Konsole oder der AWS CLI, indem Sie dem Tutorial: Erste Schritte mit S3-Dateien folgen.
Die wichtigsten Konzepte
Die folgenden Begriffe werden in der gesamten Dokumentation zu S3 Files verwendet:
- Dateisystem
Ein gemeinsam genutztes Dateisystem, das mit Ihrem S3-Bucket verknüpft ist.
- High-performance Speicher
Die Speicherebene mit niedriger Latenz in Ihrem Dateisystem, auf der sich aktiv genutzte Dateidaten und Metadaten befinden. S3 Files verwaltet diesen Speicher automatisch, kopiert Daten darauf, wenn Sie auf Dateien zugreifen, und entfernt Daten, die nicht innerhalb eines konfigurierbaren Ablauffensters gelesen wurden. Sie zahlen eine Speichergebühr für Daten, die sich auf dem Hochleistungsspeicher befinden.
- Synchronisation
Der Prozess, mit dem S3 Files Ihren aktiven Arbeitsdatensatz und Ihre Änderungen zwischen Ihrem Dateisystem und dem S3-Bucket konsistent hält. Beim Import werden Daten aus Ihrem S3-Bucket in das Dateisystem kopiert. Beim Exportieren werden Änderungen, die Sie über das Dateisystem vornehmen, zurück in Ihren S3-Bucket kopiert. S3 Files führt die Synchronisation automatisch in beide Richtungen durch.
- Ziel mounten
Ein Mount-Ziel bietet Netzwerkzugriff auf Ihr Dateisystem innerhalb einer einzigen Availability Zone in Ihrer VPC. Sie benötigen mindestens ein Mount-Ziel, um von Rechenressourcen aus auf Ihr Dateisystem zuzugreifen, und Sie können maximal ein Mount-Ziel pro Availability Zone erstellen.
- Zugriffspunkt
Access Points sind anwendungsspezifische Einstiegspunkte in ein Dateisystem, die die Verwaltung des Datenzugriffs für gemeinsam genutzte Datensätze in großem Umfang vereinfachen. Sie können Access Points verwenden, um Benutzeridentitäten und Berechtigungen für alle Dateisystemanfragen durchzusetzen, die über den Access Point gestellt werden. Wenn Sie mit der AWS Management Console ein Dateisystem erstellen, erstellt S3 Files automatisch einen Zugriffspunkt für das Dateisystem.
Features
- Hohe Leistung ohne vollständige Datenreplikation
S3 Files bietet Dateizugriff mit niedriger Latenz, indem nur Ihr aktiver Arbeitssatz in den Hochleistungsspeicher des Dateisystems kopiert wird, nicht Ihr gesamter Datensatz. Kleine Dateien, auf die häufig zugegriffen wird, werden vom Hochleistungsspeicher mit Latenzen im Submillisekunden- bis einstelligen Millisekundenbereich bereitgestellt. Große Lesevorgänge werden mit einem Gesamtdurchsatz von bis zu Terabyte pro Sekunde direkt von S3 gestreamt. Das bedeutet, dass Sie Dateisystemleistung für interaktive Workloads und S3-Durchsatz für Streaming-Workloads erhalten, ohne für das Speichern oder Importieren von Daten bezahlen zu müssen, die Sie nicht verwenden oder die nicht von der niedrigen Latenz profitieren. Weitere Informationen finden Sie unter Leistungsspezifikationen.
- Intelligentes Lese-Routing
S3 Files leitet Leseanfragen automatisch an die Speicherebene (S3-Dateisystem oder S3-Bucket) weiter, die für sie am besten geeignet ist, wobei die vollständige Dateisystemsemantik einschließlich Konsistenz, Sperren und POSIX-Berechtigungen beibehalten wird. Kleine, zufällige Lesevorgänge von aktiv verwendeten Dateien werden aus dem Hochleistungsspeicher bereitgestellt, um eine geringe Latenz zu gewährleisten. Große sequentielle Lese- und Lesevorgänge von Daten, die sich nicht im Dateisystem befinden, werden direkt von Ihrem S3-Bucket aus ausgeführt, um einen hohen Durchsatz zu gewährleisten, ohne dass für das Dateisystem Gebühren anfallen.
- Automatische Synchronisation
S3 Files sorgt automatisch dafür, dass Ihr Dateisystem und Ihr S3-Bucket in beide Richtungen konsistent sind. Änderungen, die Sie über das Dateisystem vornehmen, werden zurück in Ihren S3-Bucket kopiert, und Änderungen, die Sie direkt an Ihrem S3-Bucket vornehmen, werden in der Ansicht Ihres Dateisystems wiedergegeben. Sie können das Synchronisierungsverhalten anpassen, z. B. welche Daten importiert werden und wie lange sie im Dateisystem verbleiben. Weitere Informationen finden Sie unter Verstehen, wie die Synchronisation funktioniert.
- Skalierbare Leistung
S3 Files skaliert den Durchsatz und die IOPS automatisch entsprechend Ihrer Workload-Aktivität. Sie müssen keine Leistungskapazität bereitstellen oder verwalten und zahlen nur für das, was Sie tatsächlich nutzen.
- Regionale Dauerhaftigkeit
Daten, die auf die Hochleistungsspeicherschicht geschrieben werden, haben dieselbe Haltbarkeit wie Amazon S3. Es speichert Daten redundant in mehreren geografisch getrennten Availability Zones innerhalb derselben AWS Region und bietet so eine hohe Beständigkeit und Verfügbarkeit Ihrer Daten.
- Verschlüsselung
S3 Files verschlüsselt alle Daten während der Übertragung mit TLS und alle Daten im Ruhezustand mit AWS KMS-Schlüsseln. Sie können AWS eigene Schlüssel (Standard) oder Ihre eigenen, vom Kunden verwalteten Schlüssel verwenden. Weitere Informationen finden Sie unter Verschlüsselung.
- Semantik des Dateisystems
S3 Files unterstützt die NFS-Protokolle der Versionen 4.2 und 4.1. Es bietet Semantik für den Dateisystemzugriff, z. B. Datenkonsistenz beim Lesen nach dem Schreiben, Dateisperren und POSIX-Berechtigungen.
Wie werden Ihnen S3-Dateien in Rechnung gestellt?
Sie zahlen eine Speichergebühr für den Teil der aktiven Daten, die sich auf dem Hochleistungsspeicher befinden, und Sie zahlen Gebühren für den Dateisystemzugriff für das Lesen und Schreiben in den Hochleistungsspeicher Ihres Dateisystems. S3 Files streamt Dateilesevorgänge in zwei Fällen direkt aus Ihrem S3-Bucket: wenn die Daten der Datei nicht im Hochleistungsspeicher des Dateisystems gespeichert sind, und bei großen Lesevorgängen >= 1 MiB, auch wenn sich die Daten auch auf dem Hochleistungsspeicher des Dateisystems befinden. Der S3-Bucket ist für einen hohen Durchsatz optimiert, während die Hochleistungsspeicherschicht des Dateisystems für den Zugriff mit niedriger Latenz optimiert ist. S3 Files importiert asynchron Daten für kleine Dateien (standardmäßig < 128 KiB) in den Hochleistungsspeicher des Dateisystems für den Zugriff mit geringer Latenz bei nachfolgenden Lesevorgängen. Für diese Lesevorgänge fallen nur die Standardkosten für S3 GET-Anfragen an, es fallen keine Gebühren für den Zugriff auf das Dateisystem an. Die Gebühren für den Dateisystemzugriff fallen für Synchronisationsvorgänge an: Für den Import von Daten in das Dateisystem fallen Schreibgebühren an, und für den Export von Änderungen zurück nach S3 fallen Lesekosten an. Weitere Informationen finden Sie unter So wird S3 Files gemessen. Aktuelle Preise finden Sie auf der Preisseite für S3 Files
