Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Beispiel für die Modellierung relationaler Daten in DynamoDB
In diesem Beispiel wird die Modellierung relationaler Daten in Amazon DynamoDB beschrieben. Ein DynamoDB-Tabellendesign entspricht dem relationalen Bestelleingabeschema, das in Relationale Modellierung gezeigt wird. Es folgt dem Adjazenzlisten-Designmuster, das häufig zur Darstellung relationaler Datenstrukturen in DynamoDB verwendet wird.
Das Designmuster erfordert die Definition eines Satzes von Entity-Typen, die sich in der Regel auf die verschiedenen Tabellen im relationalen Schema beziehen. Anschließend werden der Tabelle mittels eines zusammengesetzten primären Schlüssels (Partitions- und Sortierschlüssel) Entity-Elemente hinzugefügt. Der Partitionsschlüssel dieser Entity-Elemente ist das Attribut, das das Element eindeutig identifiziert und allgemein für alle Elemente als PK bezeichnet wird. Das Sortierschlüsselattribut enthält einen Attributwert, den Sie für einen umgekehrten Index oder einen globalen sekundären Index verwenden können. Es wird allgemein als SK bezeichnet.
Sie definieren die folgenden Entitys, die das relationale Bestelleingabeschema unterstützen.
-
HR-Employee – PK: EmployeeID, SK: Name des Mitarbeiters
-
HR-Region – PK: RegionID, SK: Name der Region
-
HR-Land - PK: CountryId, SK: Name des Landes
-
HR-Location – PK: LocationID, SK: Name des Landes
-
HR-Job – PK: JobID, SK: Positionsbezeichnung
-
Personalabteilung - PK: DepartmentID, SK: DepartmentName
-
OE-Kunde - PK: CustomerID, SK: ID AccountRep
-
OE-Order – PK OrderID, SK: CustomerID
-
OE-Product – PK: ProductID, SK: Name des Produkts
-
OE-Warehouse – PK: WarehouseID, SK: Name der Region
Nach der Hinzufügung dieser Entity-Elemente zur Tabelle können Sie die Beziehungen zwischen ihnen definieren, indem Sie den Entity-Elementpartitionen Edge-Elemente hinzufügen. Dieser Schritt wird in der folgenden Tabelle veranschaulicht.
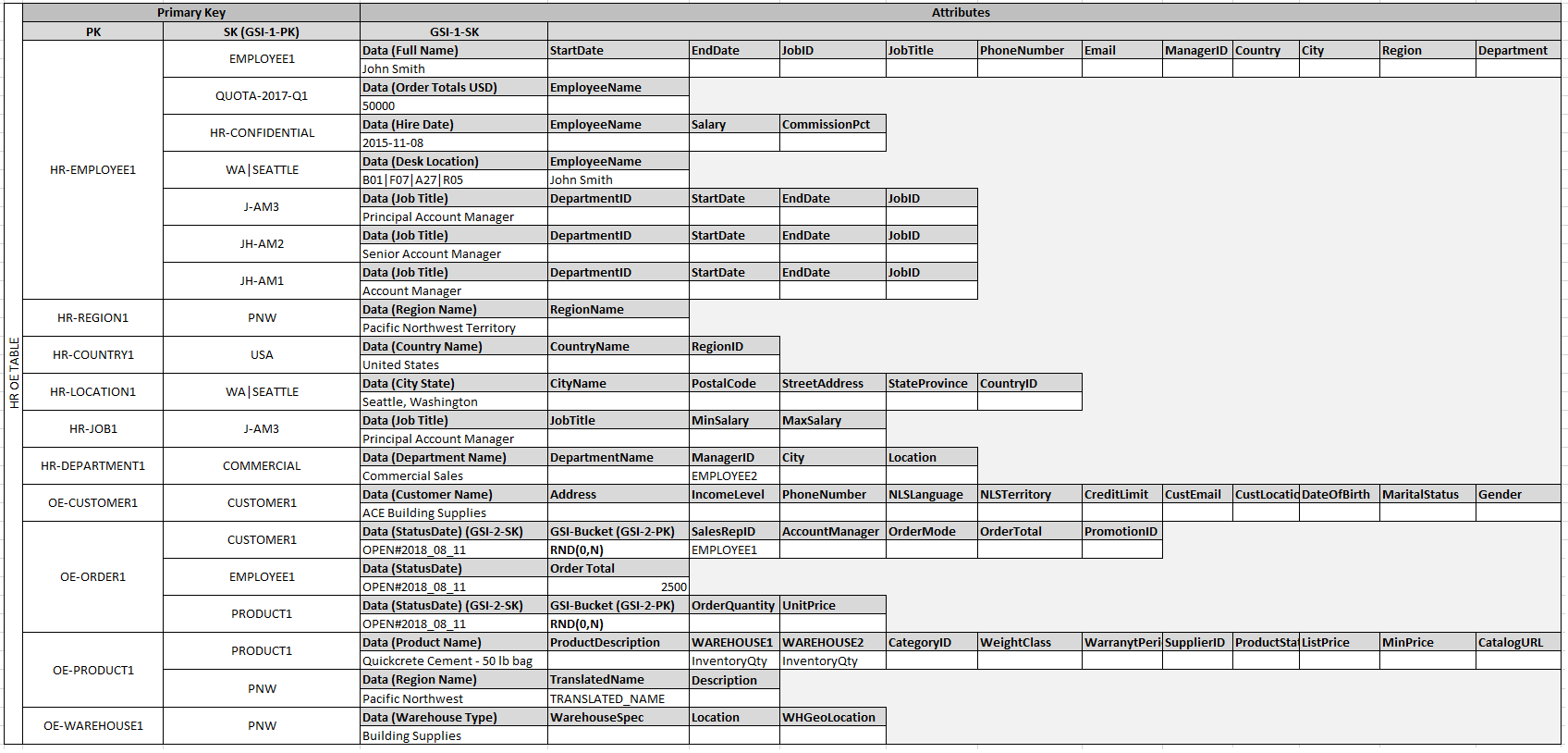
In diesem Beispiel besitzen die Partitionen Employee, Order und Product
Entity in der Tabelle zusätzliche Edge-Elemente, die Zeiger auf andere Entity-Elemente in der Tabelle besitzen. Definieren Sie als Nächstes einige globale Sekundärindizes (GSIs), um alle zuvor definierten Zugriffsmuster zu unterstützen. Die Entity-Elemente verwenden nicht alle denselben Typ von Wert für den primären Schlüssel oder das Sortierschlüsselattribut. Es müssen lediglich der primäre Schlüssel und die Sortierschlüsselattribute vorhanden sein, um diese in die Tabelle einzufügen.
Die Tatsache, dass einige dieser Entitäten Eigennamen und andere Entitäten IDs als Sortierschlüsselwerte verwenden, ermöglicht es demselben globalen sekundären Index, mehrere Arten von Abfragen zu unterstützen. Diese Technik wird als GSIÜberladen bezeichnet. Sie beseitigt das Standardlimit von 20 globalen sekundären Indexen für Tabellen, die mehrere Elementtypen enthalten. Dies wird im folgenden Diagramm als GSI1 dargestellt.
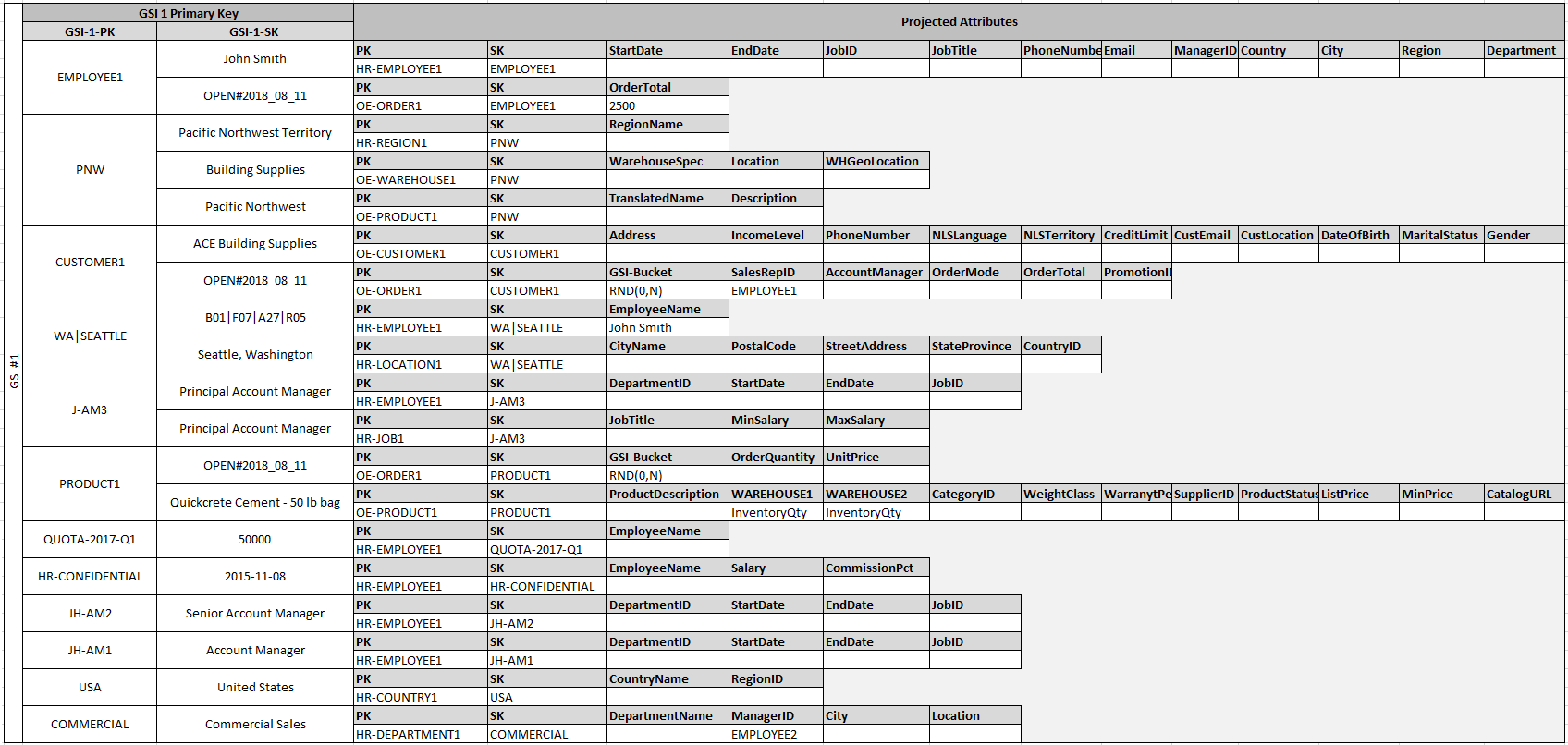
GSI2 ist so konzipiert, dass es ein recht verbreitetes Anwendungszugriffsmuster unterstützt, bei dem alle Elemente in der Tabelle abgerufen werden, die einen bestimmten Status haben. Im Fall einer großen Tabelle mit einer ungleichmäßigen Verteilung von Elementen über die verfügbaren Zustände hinweg, kann dieses Zugriffsmuster zu einem Hot-Schlüssel führen, wenn die Elemente nicht über mehrere logische Partitionen verteilt sind, die parallel abgefragt werden können. Dieses Designmuster wird als write sharding bezeichnet.
Um dies für GSI 2 zu erreichen, fügt die Anwendung jedem Bestellartikel das Primärschlüsselattribut GSI 2 hinzu. Sie füllt es mit einer zufällig ausgewählten Zahl von 0-N aus, wobei N allgemein mit der folgenden Formel berechnet werden kann, es sei denn, es gibt spezifische Gründe, anders zu verfahren.
ItemsPerRCU = 4KB / AvgItemSize PartitionMaxReadRate = 3K * ItemsPerRCU N = MaxRequiredIO / PartitionMaxReadRate
Angenommen, Sie erwarten Folgendes:
-
Das System wird bis zu 2 Millionen Bestellungen enthalten. Diese Zahl wird in 5 Jahren auf 3 Millionen anwachsen.
-
Bis zu 20 Prozent dieser Bestellungen werden sich zu einem bestimmten Zeitpunkt in einem OPEN Bundesstaat befinden.
-
Der durchschnittliche Auftragsdatensatz umfasst etwa 100 Byte, wobei drei
OrderItemDatensätze in der Auftragspartition jeweils etwa 50 Byte groß sind, sodass Sie eine durchschnittliche Größe der Bestelleinheit von 250 Byte erhalten.
Für diese Tabelle würde die Berechnung des N-Faktors wie folgt aussehen.
ItemsPerRCU = 4KB / 250B = 16 PartitionMaxReadRate = 3K * 16 = 48K N = (0.2 * 3M) / 48K = 13
In diesem Fall müssen Sie alle Bestellungen auf mindestens 13 logische Partitionen auf GSI 2 verteilen, um sicherzustellen, dass das Lesen aller Order Elemente mit einem OPEN Status nicht zu einer heißen Partition auf der physischen Speicherebene führt. Es stellt eine bewährte Methode dar, diese Zahl zu erhöhen, um Anomalien im Datensatz zu unterstützen. Ein Modell, das N = 15 verwendet, ist wahrscheinlich gut geeignet. Wie bereits erwähnt, fügen Sie dazu den zufälligen Wert 0—N zum GSI 2-PK-Attribut jedes einzelnen Order OrderItem Datensatzes hinzu, der in die Tabelle eingefügt wird.
Diese Beschreibung geht davon aus, dass das Zugriffsmuster, das die Sammlung aller Rechnungen mit dem Zustand OPEN erfordert, vergleichsweise selten ausgeführt wird, sodass Sie für diese Anforderung Burst-Kapazitäten verwenden können. Sie können den folgenden globalen sekundären Index mittels einer State- und Date Range-Sortierschlüsselbedingung abfragen, um einen Teilsatz der Bestellungen oder alle Orders in einem bestimmten Zustand zu erhalten wie erforderlich.

In diesem Beispiel sind die Elemente zufällig über die 15 logischen Partitionen verteilt. Diese Struktur funktioniert, da das Zugriffsmuster den Abruf einer großen Zahl von Elementen erfordert. Daher ist es unwahrscheinlich, dass einer der 15 Threads leere Ergebnissätze zurückgibt, die potenziell verschwendete Kapazitäten darstellen würden. Eine Abfrage verwendet immer 1 Lesekapazitätseinheit (RCU) oder 1 Schreibkapazitätseinheit (WCU), auch wenn nichts zurückgegeben oder keine Daten geschrieben werden.
Wenn das Zugriffsmuster eine Abfrage für diesen globalen sekundären Index erfordert, die sehr schnell ausgeführt werden muss und einen Sparse-Ergebnissatz zurückgibt, ist es wahrscheinlich besser, anstelle eines Zufallsmusters einen Hash-Algorithmus zu verwenden, um die Elemente zu verteilen. In diesem Fall können Sie ein Attribut auswählen, das bekannt ist, wenn die Abfrage zur Laufzeit ausgeführt wird, und dieses Attribut beim Einfügen der Elemente in einen Schlüsselbereich von 0 bis 14 hashen. Anschließend können die Werte effizient aus dem globalen sekundären Index gelesen werden.
Schließlich können Sie die Zugriffsmuster erneut aufrufen, die zuvor definiert wurden. Im Folgenden finden Sie die Liste der Zugriffsmuster und Abfragebedingungen, die Sie mit der neuen DynamoDB-Version der Anwendung verwenden werden.
| S. Nein. | Zugriffsmuster | Abfragebedingungen |
|---|---|---|
|
1 |
Suchen von Mitarbeiterdetails nach Mitarbeiter-ID |
Primärschlüssel in der Tabelle, ID="HR-“ EMPLOYEE |
|
2 |
Mitarbeiterdetails nach Mitarbeiternamen abfragen |
Verwenden Sie GSI -1, pk="Name des Mitarbeiters“ |
|
3 |
Nur die aktuellen beruflichen Details eines Mitarbeiters abrufen |
Primärschlüssel in der Tabelle, PK=HR- EMPLOYEE -1, SK beginnt mit „JH“ |
|
4 |
Bestellungen für einen Kunden für einen Datumsbereich abrufen |
Verwenden Sie GSI -1, PK=CUSTOMER1, SK=“ STATUS - DATE „, für jeden StatusCode |
|
5 |
Zeigt alle Bestellungen mit OPEN Status für einen Zeitraum für alle Kunden an |
Verwenden Sie GSI -2, pk=Query parallel für den Bereich [0.. N], SK zwischen OPEN -Date1 und -Date2 OPEN |
|
6 |
Alle Mitarbeiter, die kürzlich eingestellt wurden |
Verwenden Sie GSI -1, PK="HR- ', SK > Datum1 CONFIDENTIAL |
|
7 |
Alle Mitarbeiter in einem bestimmten Lager finden |
Verwenden Sie -1, PK= GSI WAREHOUSE1 |
|
8 |
Alle Bestellartikel für ein Produkt einschließlich Lagerstandortbestände abrufen |
Verwenden Sie GSI -1, PK= PRODUCT1 |
|
9 |
Kunden nach Kundenbetreuer abrufen |
Verwenden Sie GSI -1, ACCOUNT PK= - REP |
|
10 |
Bestellungen nach Kundenbetreuer und Datum abrufen |
Verwenden Sie GSI -1, PK= ACCOUNT -REP, SK=“ STATUS - DATE „, für jeden StatusCode |
|
11 |
Alle Mitarbeiter mit einer bestimmten Berufsbezeichnung abrufen |
Verwenden Sie GSI -1, PK= JOBTITLE |
|
12 |
Bestand nach Produkt und Lager abrufen |
Primärschlüssel in der Tabelle, PK=OE-, SK= PRODUCT1 PRODUCT1 |
|
13 |
Gesamten Produktbestand abrufen |
Primärschlüssel in der Tabelle, PK=OE-, SK= PRODUCT1 PRODUCT1 |
|
14 |
Kundenbetreuer nach Bestellsumme und Verkaufszeitraum auflisten |
Verwenden Sie GSI -1, PK= -Q1, =False YYYY scanIndexForward |
