Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Bewährte Methoden für die Modellierung relationaler Daten in DynamoDB
Dieser Abschnitt erläutert bewährte Methoden für die Modellierung relationaler Daten in Amazon DynamoDB. Zunächst stellen wir traditionelle Konzepte der Datenmodellierung vor. Anschließend beschreiben wir die Vorteile der Verwendung von DynamoDB gegenüber herkömmlichen relationalen Datenbankmanagementsystemen – wie JOIN-Operationen überflüssig werden und der Overhead reduziert wird.
Anschließend erläutern wir, wie Sie eine DynamoDB-Tabelle entwerfen, die effizient skaliert werden kann. Schließlich geben wir ein Beispiel für die Modellierung relationaler Daten in DynamoDB.
Themen
Traditionelle relationale Datenbankmodelle
Herkömmliche relationale Datenbankmanagementsysteme (RDBMS) speichern Daten in einer normalisierten relationalen Struktur. Das Ziel des relationalen Datenmodells besteht darin, die Duplizierung von Daten (durch Normalisierung) zu reduzieren, um die referentielle Integrität zu unterstützen und Datenanomalien zu verringern.
Das folgende Schema ist ein Beispiel für ein relationales Datenmodell für eine generische Auftragserfassungsanwendung. Die Anwendung unterstützt ein Personalschema, das die betrieblichen und geschäftlichen Unterstützungssysteme eines imaginären Fertigungsunternehmens unterstützt.
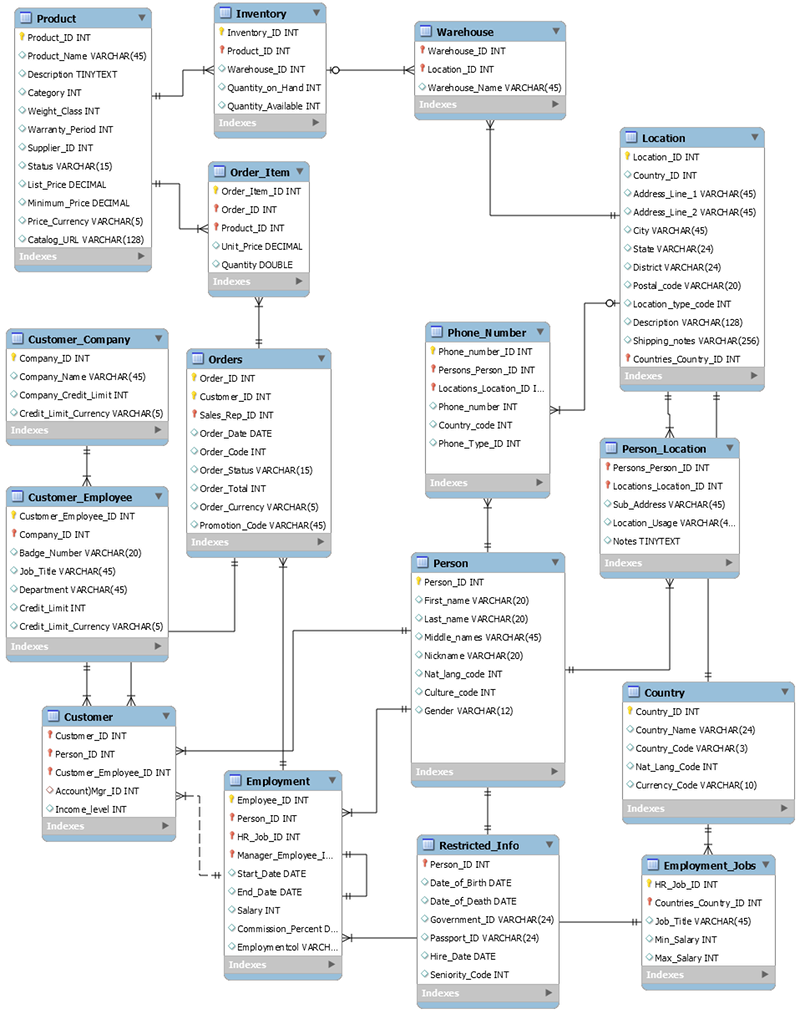
Als nicht-relationaler Datenbankservice bietet DynamoDB viele Vorteile gegenüber herkömmlichen relationalen Datenbankmanagementsystemen.
So macht DynamoDB JOIN-Operationen überflüssig
Ein RDBMS verwendet eine strukturierte Abfragesprache (SQL), um Daten an die Anwendung zurückzugeben. Aufgrund der Normalisierung des Datenmodells erfordern solche Abfragen in der Regel die Verwendung des JOIN-Operators, um Daten aus einer oder mehreren Tabellen zu kombinieren.
Um beispielsweise eine Liste von Bestellpositionen zu generieren, die nach der Menge der Artikel in allen Lagern sortiert ist, die alle Bestellpositionen liefern können, könnten Sie die folgende SQL-Abfrage für das vorangehende Schema ausgeben.
SELECT * FROM Orders
INNER JOIN Order_Items ON Orders.Order_ID = Order_Items.Order_ID
INNER JOIN Products ON Products.Product_ID = Order_Items.Product_ID
INNER JOIN Inventories ON Products.Product_ID = Inventories.Product_ID
ORDER BY Quantity_on_Hand DESCSQL-Abfragen dieser Art können eine flexible API für den Zugriff auf Daten bereitstellen. Sie erfordern jedoch einen erheblichen Verarbeitungsaufwand. Jeder Join in der Abfrage erhöht die Laufzeitkomplexität der Abfrage, da die Daten für jede Tabelle zwischengespeichert und dann zusammengestellt werden müssen, um die Ergebnismenge zurückzugeben.
Weitere Faktoren, die sich auf die Dauer der Ausführung der Abfragen auswirken können, sind die Größe der Tabellen und die Frage, ob die zu verknüpfenden Spalten Indizes haben. Die vorangehende Abfrage initiiert komplexe Abfragen für mehrere Tabellen und sortiert anschließend die Ergebnismenge.
Bei der NoSQL-Datenmodellierung geht es im Wesentlichen darum, keine JOINs mehr zu benötigen. Aus diesem Grund haben wir DynamoDB zur Unterstützung entwickelt Amazon.com, und aus diesem Grund kann DynamoDB in jeder Größenordnung gleichbleibende Leistung bieten. Angesichts der Laufzeitkomplexität von SQL-Abfragen und JOINs der RDBMS-Leistung ist die Leistung im großen Maßstab nicht konstant. Dies führt zu Leistungsproblemen, wenn Kundenanwendungen wachsen.
Durch die Normalisierung von Daten verringert sich zwar die Menge der auf der Festplatte gespeicherten Daten, die am stärksten eingeschränkten Ressourcen mit Auswirkungen auf die Leistung sind jedoch die CPU-Zeit und die Netzwerklatenz.
DynamoDB wurde entwickelt, um beide Einschränkungen zu minimieren, indem JOINs wegfallen (und die Denormalisierung von Daten gefördert wird) und die Datenbankarchitektur optimiert wird, um eine Anwendungsabfrage mit einer einzigen Anforderung an ein Element vollständig zu beantworten. Diese Eigenschaften ermöglichen es DynamoDB, in jeder Größenordnung eine Leistung im einstelligen Millisekundenbereich zu bieten. Dies liegt daran, dass die Laufzeitkomplexität für DynamoDB-Operationen unabhängig von der Datengröße bei häufigen Zugriffsmustern konstant ist.
So verringern DynamoDB-Transaktionen den Aufwand für den Schreibprozess
Auch die Verwendung von Transaktionen zum Schreiben in ein normalisiertes Schema kann ein RDBMS verlangsamen. Wie in dem Beispiel dargestellt, müssen die relationalen Datenstrukturen, die von der Mehrzahl der OLTP-Anwendungen (Online Transaction Processing, Online-Transaktionsverarbeitung) verwendet werden, unterteilt und auf mehrere logische Tabellen verteilt werden, wenn sie in einem RDBMS gespeichert werden.
Daher ist ein ACID-compliant Transaktions-Framework erforderlich, um Race Conditions und Datenintegritätsprobleme zu vermeiden, die auftreten könnten, wenn eine Anwendung versucht, ein Objekt zu lesen, das gerade geschrieben wird. Ein solches Transaktions-Framework kann in Verbindung mit einem relationalen Schema den Schreibprozess deutlich aufwendiger machen.
Die Implementierung von Transaktionen in DynamoDB verhindert Skalierungsprobleme, die bei einem RDBMS typischerweise auftreten. DynamoDB tut dies, indem es eine Transaktion als einen einzigen API-Aufruf ausgibt und die Anzahl der Elemente begrenzt, auf die in dieser einzelnen Transaktion zugegriffen werden kann. Long-running Transaktionen können zu Betriebsproblemen führen, da die Daten entweder für eine lange Zeit oder dauerhaft gesperrt werden, da die Transaktion nie abgeschlossen wird.
Um solche Probleme in DynamoDB zu vermeiden, wurden Transaktionen mit zwei verschiedenen API-Operationen implementiert: TransactWriteItems und TransactGetItems. Diese API-Operationen haben keine Anfangs- und Endsemantik, wie in einem RDBMS üblich. Darüber hinaus gilt in DynamoDB ein Zugriffslimit von 100 Elementen innerhalb einer Transaktion, ebenfalls um lang andauernde Transaktionen zu verhindern. Weitere Informationen zu DynamoDB-Transaktionen finden Sie unter Arbeiten mit Transaktionen.
Aus diesen Gründen ist die Nutzung eines NoSQL-Systems in der Regel technisch und wirtschaftlich sinnvoll, wenn Ihr Unternehmen eine Reaktion mit geringer Latenz auf Abfragen mit hohem Datenverkehr benötigt. Amazon DynamoDB hilft bei der Lösung von Problemen, die die Skalierbarkeit des relationalen Systems einschränken, indem sie diese vermeiden.
Die Leistung eines RDBMS ist in der Regel aus den folgenden Gründen nicht gut skalierbar:
-
Es verwendet kostspielige Joins, um die gewünschten Ansichten von Abfrageergebnissen neu zusammenzustellen.
-
Es standardisiert Daten und speichert sie in mehreren Tabellen, die mehrere Abfragen erfordern, bei denen Daten auf den Datenträger geschrieben werden.
-
Dies verursacht im Allgemeinen die Leistungskosten eines ACID-compliant Transaktionssystems.
DynamoDB kann aus den folgenden Gründen gut skaliert werden:
-
Die Flexibilität des Schemas ermöglicht DynamoDB die Speicherung komplexer hierarchischer Daten innerhalb eines einzelnen Elements.
-
Das Design mit zusammengesetzten Schlüsseln ermöglicht das Speichern verwandter Elemente nahe beieinander in derselben Tabelle.
-
Transaktionen werden in einem einzigen Vorgang ausgeführt. Die Anzahl der Elemente, auf die zugegriffen werden kann, ist auf 100 begrenzt, um lange laufende Operationen zu vermeiden.
Abfragen des Datenspeichers werden sehr viel einfacher und können häufig im folgenden Format erfolgen:
SELECT * FROM Table_X WHERE Attribute_Y = "somevalue"
DynamoDB erfordert im Vergleich zum RDBMS aus dem vorhergehenden Beispiel deutlich weniger Aufwand, um die angeforderten Daten zu erhalten.
