Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwenden des DynamoDB-Streams-Kinesis-Adapters zum Verarbeiten von Stream-Datensätzen
Die Verwendung des Amazon-Kinesis-Adapters ist die empfohlene Methode zum Verwenden von Streams aus Amazon DynamoDB. Die DynamoDB-Streams-API ist absichtlich ähnlich gestaltet wie die von Kinesis Data Streams. In beiden Services bestehen die Daten-Streams aus Shards. Dieses sind Container für Stream-Datensätze. Die APIs beider Services enthalten ListStreams, DescribeStream, GetShards, und GetShardIterator-Operationen. (Diese DynamoDB-Streams-Aktionen ähneln ihren Gegenstücken in Kinesis Data Streams, sind jedoch nicht vollkommen identisch.)
Als DynamoDB-Streams-Benutzer können Sie das Entwurfsmuster in der KCL zum Verarbeiten von DynamoDB-Streams-Shards und Stream-Datensätzen verwenden. Verwenden Sie dazu den DynamoDB-Streams-Kinesis-Adapter. Der Kinesis-Adapter implementiert die Kinesis-Data-Streams-Schnittstelle so, dass die KCL zum Verwenden und Verarbeiten von Datensätzen aus DynamoDB Streams eingesetzt werden kann. Anweisungen zur Einrichtung und Installation des DynamoDB Streams Kinesis Adapters finden Sie im Repository. GitHub
Sie können Anwendungen für Kinesis Data Streams mit der Kinesis Client Library (KCL) schreiben. Die KCL vereinfacht die Codierung durch Bereitstellen nützlicher Abstraktionen oberhalb der Low-Level-Kinesis-Data-Streams-API. Weitere Informationen zur KCL finden Sie im Entwickeln von Konsumenten mit der Kinesis-Client-Library im Entwicklerhandbuch zu Amazon Kinesis Data Streams.
DynamoDB empfiehlt die Verwendung von KCL Version 3.x mit AWS SDK for Java v2.x. Die aktuelle Version 1.x des DynamoDB Streams Kinesis Adapters mit AWS SDK für AWS SDK für Java v1.x wird während des gesamten Lebenszyklus weiterhin vollständig unterstützt, wie während der Übergangsphase vorgesehen, und zwar in Übereinstimmung mit den Wartungsrichtlinien für AWS SDKs und Tools.
Anmerkung
Die Versionen 1.x und 2.x der Amazon Kinesis Client Library (KCL) sind veraltet. Die Unterstützung für KCL 1.x endet am 30. Januar 2026. Wir empfehlen dringend, KCL-Anwendungen, die Version 1.x verwenden, vor dem 30. Januar 2026 zur neuesten KCL-Version zu migrieren. Die neueste KCL-Version finden Sie auf der Seite Amazon Kinesis Client Library
Das folgende Diagramm zeigt, wie diese Bibliotheken miteinander interagieren.
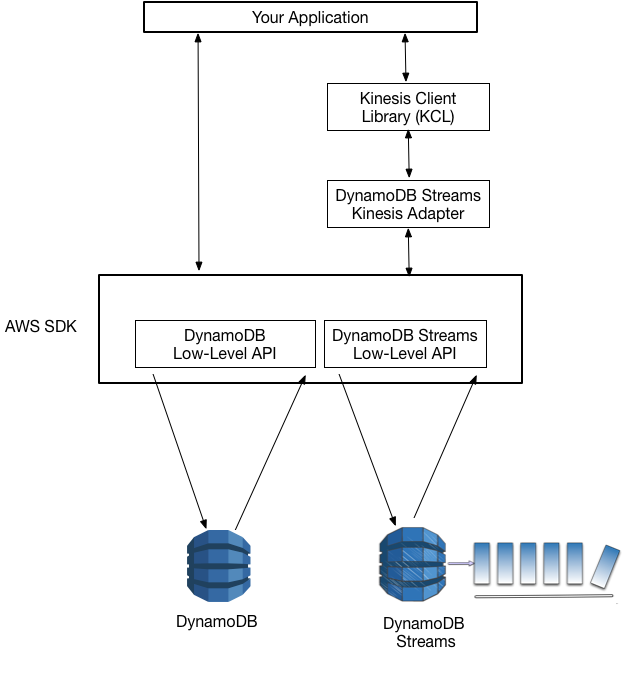
Wenn Sie den DynamoDB-Streams-Kinesis-Adapter eingerichtet haben, können Sie die Entwicklung mit der KCL-Schnittstelle starten, wobei die API-Aufrufe nahtlos an den DynamoDB-Streams-Endpunkt gerichtet werden.
Beim Start der Anwendung wird die KCL aufgerufen, einen Worker zu instanziieren. Sie müssen dem Worker Konfigurationsinformationen für die Anwendung, wie z. B. den Stream-Deskriptor und die AWS Anmeldeinformationen, sowie den Namen einer von Ihnen angegebenen Datensatzprozessorklasse zur Verfügung stellen. Da der Code im Datensatzprozessor ausgeführt wird, erledigt der Worker die folgenden Aufgaben:
-
Stellt eine Verbindung mit dem Stream her
-
Listet die Shards innerhalb des Streams auf
-
Überprüft und listet untergeordnete Shards eines geschlossenen übergeordneten Shards innerhalb des Streams auf
-
Koordiniert Shard-Zuordnungen mit anderen Auftragnehmern (wenn vorhanden)
-
Instanziiert einen Datensatzverarbeiter für jeden Shard, der verwaltet wird
-
Ruft Datensätze aus dem Stream per Pull ab
-
Skaliert die GetRecords API-Aufrufrate bei hohem Durchsatz (wenn der Nachholmodus konfiguriert ist)
-
Überträgt per Push Datensätze an den entsprechenden Datensatzverarbeiter
-
Verwendet Checkpoints für verarbeitete Datensätze
-
Gleicht Shard-Auftragnehmer-Zuordnungen aus, wenn die Auftragnehmer-Instance Änderungen zählt
-
Gleicht Shard-Worker-Zuordnungen aus, wenn Shards aufgeteilt werden
Der KCL-Adapter unterstützt den Catch-up-Modus, eine Funktion zur automatischen Anpassung der Anrufrate zur Bewältigung vorübergehender Durchsatzerhöhungen. Wenn die Verzögerung bei der Stream-Verarbeitung einen konfigurierbaren Schwellenwert (standardmäßig eine Minute) überschreitet, skaliert der Aufholmodus die GetRecords API-Aufruffrequenz um einen konfigurierbaren Wert (Standard 3x), um Datensätze schneller abzurufen, und kehrt dann zum Normalzustand zurück, sobald die Verzögerung nachlässt. Dies ist in Zeiten mit hohem Durchsatz nützlich, in denen DynamoDB-Schreibaktivitäten die Verbraucher bei Verwendung der Standardabfrageraten überfordern können. Catch-up Der Modus kann über den catchupEnabled Konfigurationsparameter aktiviert werden (Standardeinstellung falsch).
Anmerkung
Eine Beschreibung der hier aufgeführten KCL-Konzepte finden Sie unter Entwickeln von Konsumenten mithilfe der Kinesis-Clientbibliothek im Amazon-Kinesis-Data-Streams-Entwicklerhandbuch.
Weitere Informationen zur Verwendung von Streams mit AWS Lambda finden Sie unter DynamoDB Streams und AWS Lambda triggers
