Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Schemadesign für Gaming-Profile in DynamoDB
Geschäftlicher Anwendungsfall für Gaming-Profile
In diesem Anwendungsfall geht es um die Verwendung von DynamoDB zum Speichern von Spielerprofilen für ein Gaming-System. Bevor Benutzer (in diesem Fall Spieler) mit vielen modernen Spielen, insbesondere Online-Spielen, interagieren können, müssen sie Profile erstellen. Gaming-Profile beinhalten in der Regel Folgendes:
-
Grundlegende Informationen wie beispielsweise den Benutzernamen
-
Spieledaten wie beispielsweise Gegenstände und Ausrüstung
-
Spieledatensätze wie beispielsweise Aufgaben und Aktivitäten
-
Soziale Informationen wie beispielsweise Freundeslisten
Um die differenzierten Anforderungen für den Zugriff auf Datenabfragen für diese Anwendung zu erfüllen, verwenden die Primärschlüssel (Partitionsschlüssel und Sortierschlüssel) generische Namen (PK und SK), sodass sie mit verschiedenen Arten von Werten überlastet werden können, wie wir weiter unten sehen werden.
Die Zugriffsmuster für dieses Schemadesign sind folgende:
-
Abrufen der Freundesliste eines Benutzers
-
Abrufen aller Informationen eines Spielers
-
Abrufen der Gegenstandsliste eines Benutzers
-
Abrufen eines spezifischen Gegenstands aus der Gegenstandsliste des Benutzers
-
Aktualisieren des Charakters eines Benutzers
-
Aktualisieren der Anzahl an Gegenständen für einen Benutzer
Die Größe des Gaming-Profils variiert je nach Spiel. Wenn Sie große Attributwerte komprimieren, liegen sie möglicherweise innerhalb der Elementeinschränkungen in DynamoDB, sodass Ihre Kosten reduziert werden. Die Strategie für die Durchsatzverwaltung würde von verschiedenen Faktoren abhängen, z. B. der Anzahl der Spieler, der Anzahl der pro Sekunde gespielten Spiele und der Saisonalität des Workloads. In der Regel sind bei einem neu gestarteten Spiel die Anzahl der Spieler und der Beliebtheitsgrad nicht bekannt, daher beginnen wir mit dem On-Demand-Durchsatzmodus.
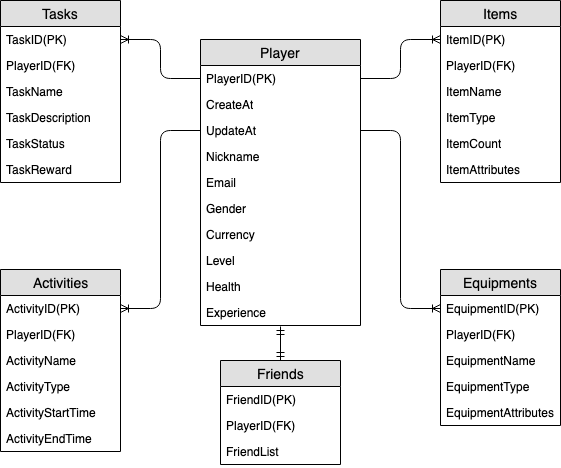
Diagramm der Entitätsbeziehungen in Gaming-Profilen
Dies ist das Diagramm der Entitätsbeziehungen (Entity Relationship Diagram, ERD), das wir für das Schemadesign für Gaming-Profile verwenden werden.
Zugriffsmuster für Gaming-Profile
Dies sind die Zugriffsmuster, die wir für das Schemadesign für soziale Netzwerke berücksichtigen werden.
-
getPlayerFriends -
getPlayerAllProfile -
getPlayerAllItems -
getPlayerSpecificItem -
updateCharacterAttributes -
updateItemCount
Entwicklung des Schemas für Gaming-Profile
Im obigen ERD lässt sich erkennen, dass es sich bei der Art der Datenmodellierung um eine 1:n-Beziehung handelt. In DynamoDB können 1:n-Datenmodelle in Elementauflistungen organisiert werden. Dies unterscheidet sich von herkömmlichen relationalen Datenbanken, in denen mehrere Tabellen erstellt und über Fremdschlüssel verknüpft werden. Eine Elementauflistung ist eine Gruppe von Elementen, die den gleichen Partitionsschlüsselwert, aber unterschiedliche Sortierschlüsselwerte aufweisen. Innerhalb einer Elementauflistung hat jedes Element einen eindeutigen Sortierschlüsselwert, der es von anderen Elementen unterscheidet. Vor diesem Hintergrund verwenden wir das folgende Muster für HASH- und RANGE-Werte für jeden Entitätstyp.
Zu Beginn verwenden wir generische Namen wie PK und SK, um verschiedene Arten von Entitäten in derselben Tabelle zu speichern und das Modell zukunftssicher zu machen. Zur besseren Lesbarkeit können wir Präfixe zur Angabe des Datentyps oder ein beliebiges Attribut mit der Bezeichnung Entity_type oder Type hinzufügen. Im aktuellen Beispiel verwenden wir eine Zeichenfolge, die mit player beginnt, um player_ID als PK zu speichern. Wir verwenden entity name# als Präfix von SK und fügen das Attribut Type hinzu, um anzugeben, um welchen Entitätstyp es sich bei diesen Daten handelt. Dadurch können wir in Zukunft die Speicherung weiterer Entitätstypen unterstützen und fortschrittliche Technologien wie GSI-Überladung und Sparse GSI verwenden, um mehr Zugriffsmuster zu erfüllen.
Beginnen wir mit der Implementierung der Zugriffsmuster. Zugriffsmuster wie das Hinzufügen von Spielern und das Hinzufügen von Ausrüstung können über die Operation PutItem realisiert werden, sodass wir sie ignorieren können. In diesem Dokument konzentrieren wir uns auf die oben aufgeführten typischen Zugriffsmuster.
Schritt 1: Zugriffsmuster 1 (getPlayerFriends) angehen
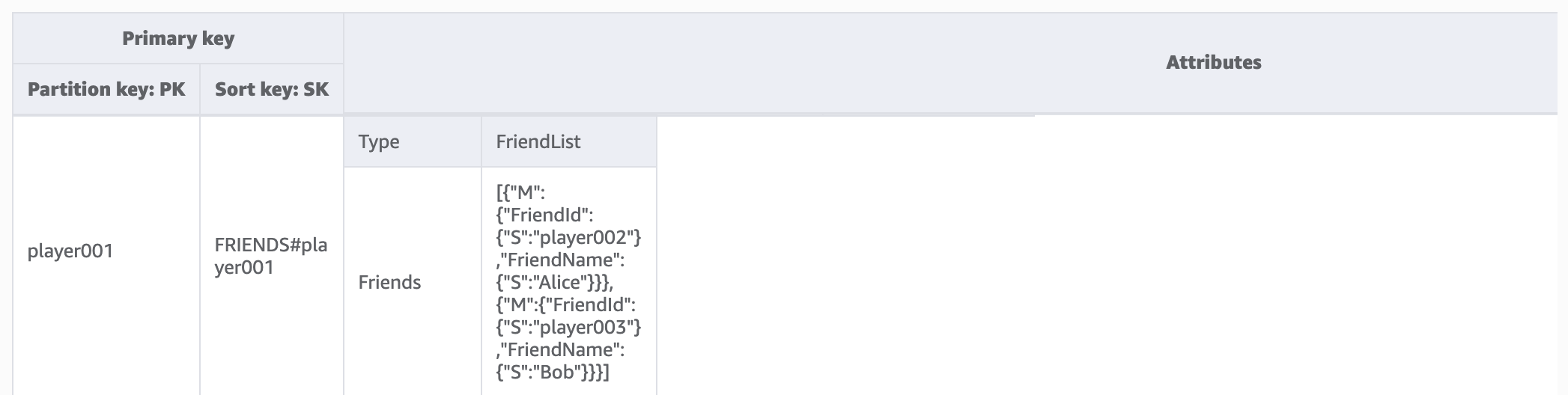
In diesem Schritt gehen wir das Zugriffsmuster 1 (getPlayerFriends) an. In unserem aktuellen Design ist die Freundschaft einfach und die Anzahl der Freunde im Spiel ist gering. Der Einfachheit halber verwenden wir einen Listendatentyp, um Freundeslisten zu speichern (1:1-Modellierung). In diesem Design verwenden wir GetItem, um dieses Zugriffsmuster zu erfüllen. In der Operation GetItem geben wir explizit den Partitions- und den Sortierschlüsselwert an, um ein spezifisches Element abzurufen.
Wenn es in einem Spiel jedoch eine große Anzahl von Freunden gibt und die Beziehungen zwischen ihnen komplex sind (z. B. bidirektionale Freundschaften, die sowohl eine Einladungs- als auch eine Annahmekomponente enthalten), ist es erforderlich, eine n:m-Beziehung zu verwenden, um jeden Freund einzeln zu speichern und auf eine unbegrenzte Größe der Freundesliste zu skalieren. Wenn der Freundschaftswechsel die gleichzeitige Bearbeitung mehrerer Elemente beinhaltet, können DynamoDB-Transaktionen verwendet werden, um mehrere Aktionen zu gruppieren und sie als eine einzige atomare TransactWriteItems- oder TransactGetItems-Operation zu übermitteln.
Schritt 2: Zugriffsmuster 2 (getPlayerAllProfile), 3 (getPlayerAllItems) und 4 (getPlayerSpecificItem) angehen
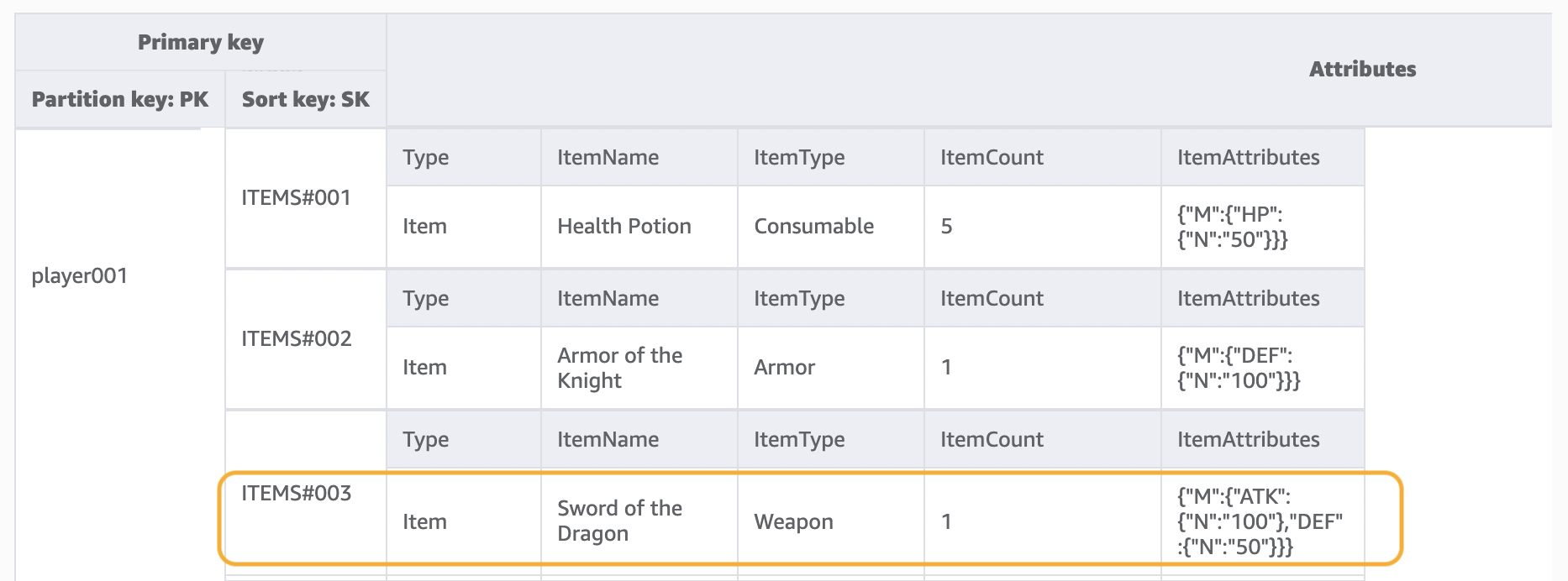
In diesem Schritt gehen wir die Zugriffsmuster 2 (getPlayerAllProfile), 3 (getPlayerAllItems) und 4 (getPlayerSpecificItem) an. Was diese drei Zugriffsmuster gemeinsam haben, ist eine Bereichsabfrage, die die Operation Query verwendet. Je nach Umfang der Abfrage werden Schlüsselbedingung und Filterausdrücke verwendet, die in der praktischen Entwicklung häufig verwendet werden.
In der Abfrage-Operation geben wir einen einzelnen Wert für den Partitionsschlüssel an und rufen alle Elemente mit diesem Partitionsschlüsselwert ab. Das Zugriffsmuster 2 (getPlayerAllProfile) wird auf diese Weise implementiert. Optional können wir einen Bedingungsausdruck für den Sortierschlüssel hinzufügen – eine Zeichenfolge, die bestimmt, welche Elemente aus der Tabelle gelesen werden sollen. Das Zugriffsmuster 3 (getPlayerAllItems) wird implementiert, indem die Schlüsselbedingung sort key begins_with ITEMS# hinzugefügt wird. Zum Vereinfachen der Entwicklung der Anwendungsseite können wir außerdem Filterausdrücke verwenden, um das Zugriffsmuster 4 (getPlayerSpecificItem) zu implementieren.
Dies ist ein Pseudocode-Beispiel, das einen Filterausdruck verwendet, der Elemente der Kategorie Weapon filtert:
filterExpression: "ItemType = :itemType" expressionAttributeValues: {":itemType": "Weapon"}
Anmerkung
Ein Filterausdruck wird angewendet, nachdem eine Abfrage abgeschlossen ist und bevor die Ergebnisse zurückgegeben werden. Folglich verbraucht eine Abfrage unabhängig davon, ob ein Filterausdruck vorhanden ist oder nicht, gleich viel Lesekapazität.
Wenn das Zugriffsmuster darin besteht, einen großen Datensatz abzufragen und eine große Datenmenge herauszufiltern, um nur eine kleine Teilmenge der Daten zu behalten, sollten der DynamoDB-Partitionsschlüssel und -Sortierschlüssel effektiver gestaltet werden. Wenn es im obigen Beispiel zum Abrufen eines bestimmten ItemType beispielsweise viele Gegenstände für jeden Spieler gibt und die Abfrage eines bestimmten ItemType ein typisches Zugriffsmuster ist, wäre es effizienter, ItemType als zusammengesetzten Schlüssel in den SK aufzunehmen. Das Datenmodell würde dann wie folgt aussehen: ITEMS#ItemType#ItemId.
Schritt 3: Zugriffsmuster 5 (updateCharacterAttributes) und 6 (updateItemCount) angehen
In diesem Schritt gehen wir die Zugriffsmuster 5 (updateCharacterAttributes) und 6 (updateItemCount) an. Wenn der Spieler den Charakter modifizieren – z. B. die Währung reduzieren oder die Menge einer bestimmten Waffe in seinen Gegenständen ändern – muss, verwenden Sie UpdateItem, um diese Zugriffsmuster zu implementieren. Wenn wir die Währung eines Spielers aktualisieren und gleichzeitig sicherstellen möchten, dass sie einen Mindestbetrag niemals unterschreitet, können wir CLI-Beispiel für DynamoDB-Bedingungsausdrücke hinzufügen, um das Guthaben nur dann zu reduzieren, wenn es größer oder gleich dem Mindestbetrag ist. Dies ist ein Pseudocode-Beispiel:
UpdateExpression: "SET currency = currency - :amount" ConditionExpression: "currency >= :minAmount"

Wenn wir bei der Entwicklung mit DynamoDB unteilbare Zähler zum Verringern des Inventars verwenden, können wir die Idempotenz sicherstellen, indem wir die optimistische Sperre verwenden. Dies ist ein Pseudocode-Beispiel für unteilbare Zähler:
UpdateExpression: "SET ItemCount = ItemCount - :incr" expression-attribute-values: '{":incr":{"N":"1"}}'

Darüber hinaus muss in einem Szenario, in dem der Spieler einen Gegenstand mit einer Währung kauft, der gesamte Vorgang die Währung abziehen und gleichzeitig einen Gegenstand hinzufügen. Wir können DynamoDB-Transaktionen verwenden, um mehrere Aktionen zu gruppieren und sie als eine einzige atomare TransactWriteItems- oder TransactGetItems-Operation zu übermitteln. TransactWriteItems ist eine synchrone und idempotente Schreiboperation, die bis zu 100 Schreibaktionen in einer einzigen atomaren Operation gruppiert. Die Aktionen werden atomarisch ausgeführt, d. h. entweder sind alle von ihnen oder keine von ihnen erfolgreich. Mit Transaktionen lässt sich das Risiko beseitigen, dass eine Währung dupliziert wird oder verschwindet. Weitere Informationen zu Transaktionen finden Sie unter DynamoDB-Transaktionen-Beispiel.
Alle Zugriffsmuster und wie das Schemadesign sie behandelt, sind in der folgenden Tabelle zusammengefasst:
| Zugriffsmuster | Basis /LSI table/GSI | Operation | Partitionsschlüsselwert | Sortierschlüsselwert | Andere conditions/filters |
|---|---|---|---|---|---|
| bekommen PlayerFriends | Basistabelle | GetItem | PK=PlayerID | SK=“FRIENDS#playerID” | |
| bekommen PlayerAllProfile | Basistabelle | Query | PK=PlayerID | ||
| bekommen PlayerAllItems | Basistabelle | Query | PK=PlayerID | SK begins_with “ITEMS#” | |
| bekommen PlayerSpecificItem | Basistabelle | Query | PK=PlayerID | SK begins_with “ITEMS#” | filterExpression: "ItemType =:itemType“ -AusdruckAttributeValues: {„:itemType“: „Waffe“} |
| aktualisieren CharacterAttributes | Basistabelle | UpdateItem | PK=PlayerID | SK=“#METADATA#playerID” | UpdateExpression: „SET-Währung = Währung -:Betrag“ ConditionExpression: „Währung >=:MinAmount“ |
| aktualisieren ItemCount | Basistabelle | UpdateItem | PK=PlayerID | SK =“ITEMS#ItemID” | Ausdruck aktualisieren: „SET ItemCount = ItemCount -:incr“ Ausdrucksattributwerte: '{“ :incr“: {"N“ :"1"}}' |
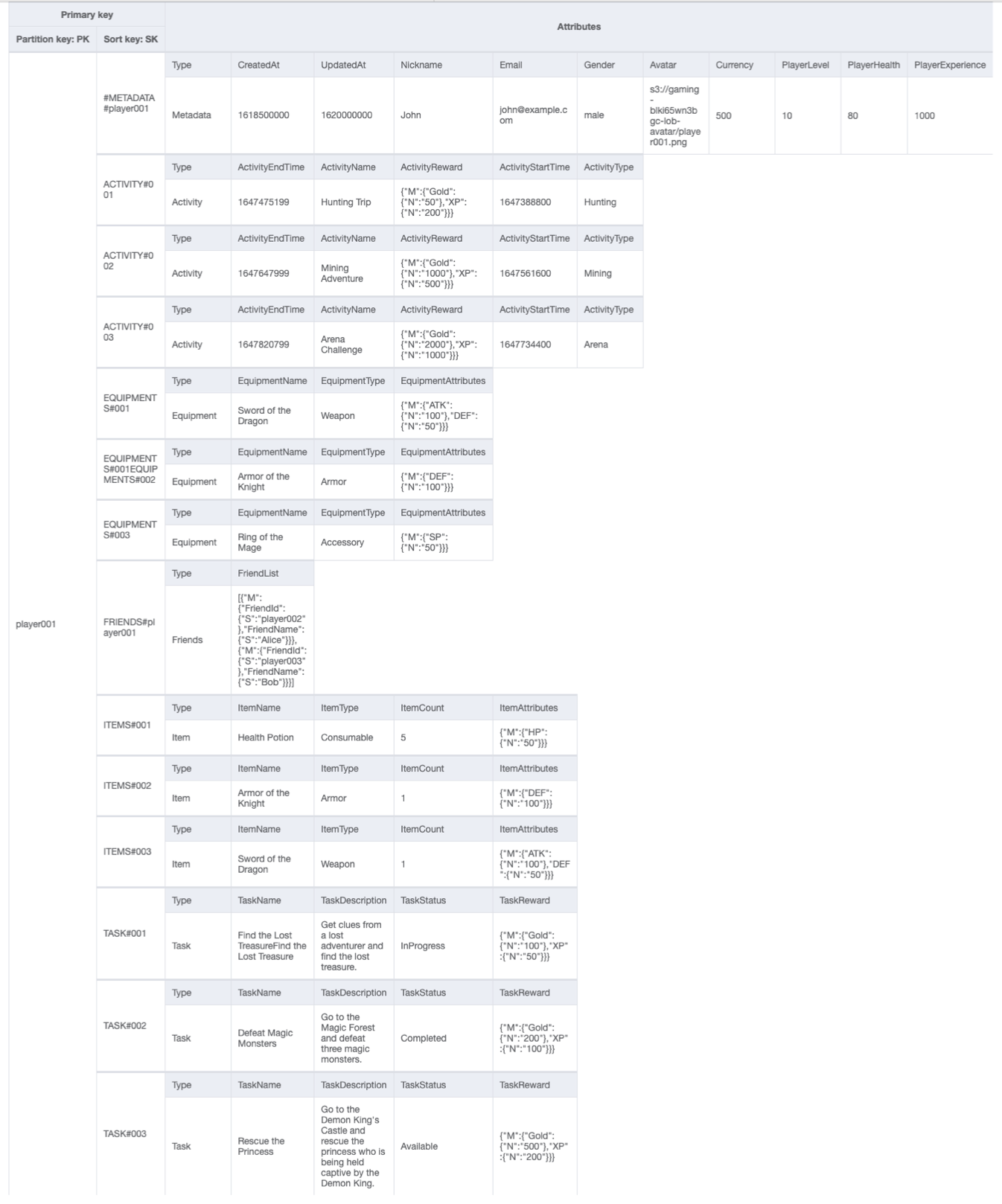
Endgültiges Schema des Gaming-Profils
Dies ist das endgültige Schemadesign. Informationen zum Herunterladen dieses Schemadesign als JSON-Datei finden Sie unter DynamoDB-Beispiele
Basistabelle:
Verwendung von NoSQL Workbench mit diesem Schemadesign
Sie können dieses endgültige Schema in NoSQL Workbench importieren, um Ihr neues Projekt weiter zu untersuchen und zu bearbeiten. NoSQL Workbench ist ein visuelles Tool, das Features zur Datenmodellierung, Datenvisualisierung und Abfrageentwicklung für DynamoDB bereitstellt. Gehen Sie folgendermaßen vor, um zu beginnen:
-
Laden Sie NoSQL Workbench herunter. Weitere Informationen finden Sie unter Herunterladen von NoSQL Workbench for DynamoDB.
-
Laden Sie die oben aufgeführte JSON-Schemadatei herunter, die bereits das NoSQL-Workbench-Modellformat aufweist.
-
Importieren Sie die JSON-Schemadatei in NoSQL Workbench. Weitere Informationen finden Sie unter Importieren eines vorhandenen Datenmodells.
-
Nach dem Import in NOSQL Workbench können Sie das Datenmodell bearbeiten. Weitere Informationen finden Sie unter Bearbeiten eines vorhandenen Datenmodells.
