Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Grundlagen der Datenmodellierung in DynamoDB
In diesem Abschnitt werden zunächst die beiden Arten des Tabellendesigns behandelt: das Design mit einer einzelnen und das Design mit mehreren Tabellen.
Fundament für das Design mit einer einzelnen Tabelle
Eine Option für das Fundament unseres DynamoDB-Schemas ist das Design mit einer einzelnen Tabelle. Das Design mit einer einzelnen Tabelle ist ein Muster, mit dem Sie mehrere Datentypen (Entitäten) in einer einzigen DynamoDB-Tabelle speichern können. Ziel ist es, die Datenzugriffsmuster zu optimieren, die Leistung zu verbessern und die Kosten zu senken, indem die Notwendigkeit entfällt, mehrere Tabellen und komplexe Beziehungen zwischen diesen zu verwalten. Dies ist möglich, weil DynamoDB Elemente mit dem gleichen Partitionsschlüssel (als Elementauflistung bezeichnet) auf der-/denselben Partition(en) speichert. In diesem Design werden verschiedene Datentypen als Elemente in derselben Tabelle gespeichert und jedes Element wird durch einen eindeutigen Sortierschlüssel identifiziert.
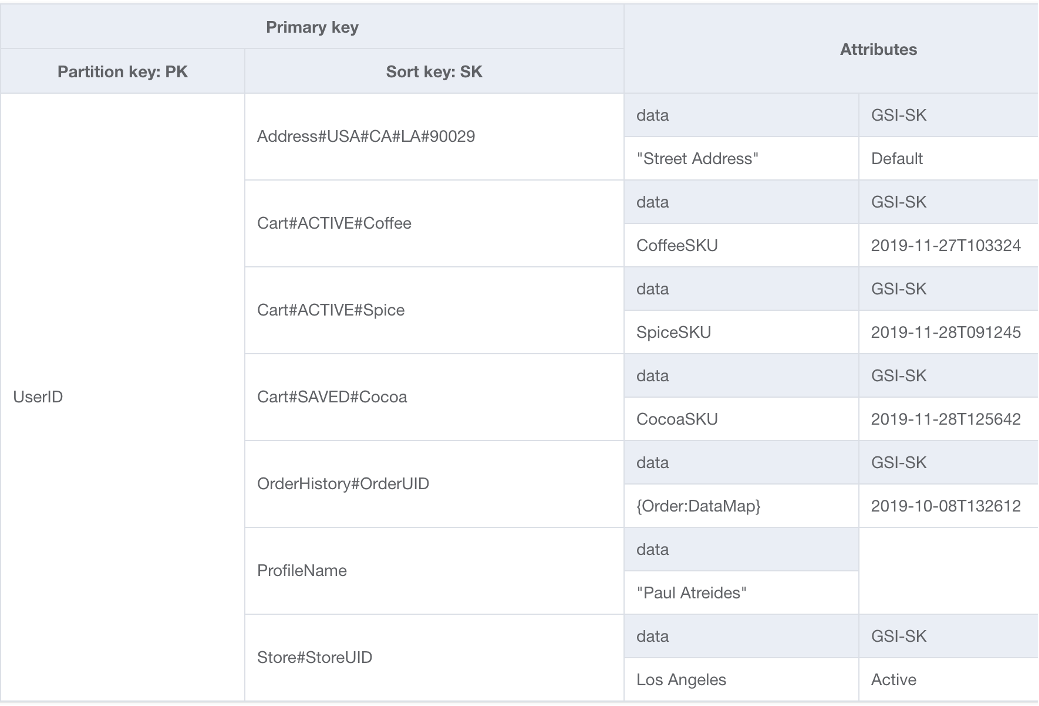
Vorteile
-
Datenlokalität zur Unterstützung von Abfragen für mehrere Entitätstypen in einem einzigen Datenbankaufruf
-
Reduzierung der finanziellen Gesamtkosten und der Latenzkosten für Lesevorgänge:
-
Eine einzelne Abfrage für zwei Elemente mit einer Gesamtgröße von weniger als 4 KB entspricht einem letztendlich konsistenten Lesevorgang mit 0,5 RCU.
-
Zwei Abfragen für zwei Elemente mit einer Gesamtgröße von weniger als 4 KB entsprechen einem letztendlich konsistenten Lesevorgang mit 1 RCU (jeweils 0,5 RCU).
-
Die Zeit für die Rückgabe von zwei separaten Datenbankaufrufen ist im Durchschnitt höher als bei einem einzelnen Aufruf.
-
-
Reduzierung der Anzahl an zu verwaltenden Tabellen:
-
Berechtigungen müssen nicht für mehrere IAM-Rollen oder -Richtlinien verwaltet werden.
-
Die Kapazitätsverwaltung für die Tabelle wird über alle Einheiten hinweg gemittelt, was in der Regel ein besser vorhersehbares Nutzungsmuster zur Folge hat.
-
Für die Überwachung sind weniger Alarme erforderlich.
-
Vom Kunden verwaltete Verschlüsselungsschlüssel müssen nur für eine Tabelle rotiert werden.
-
-
Reibungsloser Datenverkehr zur Tabelle:
-
Durch die Zusammenfassung mehrerer Nutzungsmuster in derselben Tabelle ist die Gesamtnutzung in der Regel reibungsloser (so wie die Leistung eines Aktienindex tendenziell reibungsloser ist als bei einer einzelnen Aktie). Dies eignet sich besser, um mit Tabellen im Modus bereitgestellter Kapazität eine höhere Auslastung zu erzielen.
-
Nachteile
-
Die Lernkurve kann aufgrund des paradoxen Designs im Vergleich zu relationalen Datenbanken steil sein.
-
Die Datenanforderungen müssen für alle Entitätstypen konsistent sein.
-
Für Backups gilt das „alles oder nichts“-Prinzip. Wenn einige Daten nicht geschäftskritisch sind, sollten Sie erwägen, diese in einer separaten Tabelle zu speichern.
-
Die Tabellenverschlüsselung ist für alle Elemente gleich. Im Fall von Anwendungen für mehrere Mandanten mit individuellen Mandanten-Verschlüsselungsanforderungen wäre eine clientseitige Verschlüsselung erforderlich.
-
Im Fall von Tabellen mit einer Mischung aus historischen Daten und Betriebsdaten wird die Aktivierung der Speicherklasse Infrequent Access nicht so vorteilhaft sein. Weitere Informationen finden Sie unter DynamoDB-Tabellenklassen.
-
-
Alle geänderten Daten werden an DynamoDB Streams weitergegeben, auch wenn nur eine Teilmenge von Entitäten verarbeitet werden muss.
-
Dank der Lambda-Ereignisfilter hat dies keine Auswirkungen auf Ihre Abrechnung, wenn Sie Lambda verwenden. Es ist jedoch mit zusätzlichen Kosten verbunden, wenn Sie die Kinesis Consumer Library verwenden.
-
-
Bei Verwendung von GraphQL wird es schwieriger sein, das Design mit einer einzelnen Tabelle zu implementieren.
-
Wenn Sie übergeordnete SDK-Clients wie DynamoDBMapper oder Enhanced Client von Java verwenden, kann es schwieriger sein, Ergebnisse zu verarbeiten, da Elemente in derselben Antwort möglicherweise verschiedenen Klassen zugeordnet sind.
Wann sollte dies verwendet werden?
Das Design mit einer einzigen Tabelle eignet sich gut für Anwendungen, die häufig mehrere Entitätstypen zusammen abfragen oder Beziehungen zwischen verschiedenen Datentypen aufrechterhalten müssen. Es ist besonders effektiv, wenn Ihre Zugriffsmuster von der Datenlokalität profitieren und wenn Sie den Aufwand für die Verwaltung mehrerer Tabellen minimieren möchten.
Fundament für das Design mit mehreren Tabellen
Die zweite Option für das Fundament unseres DynamoDB-Schemas ist das Design mit mehreren Tabellen. Das Design mit mehreren Tabellen ist ein Muster, das eher einem herkömmlichen Datenbankdesign ähnelt, bei dem Sie in jeder DynamoDB-Tabelle einen einzigen Datentyp (Entität) speichern. Die Daten in jeder Tabelle werden weiterhin nach Partitionsschlüsseln organisiert, sodass die Leistung innerhalb eines einzelnen Entitätstyps im Hinblick auf Skalierbarkeit und Leistung optimiert wird. Abfragen über mehrere Tabellen müssen jedoch unabhängig voneinander durchgeführt werden.
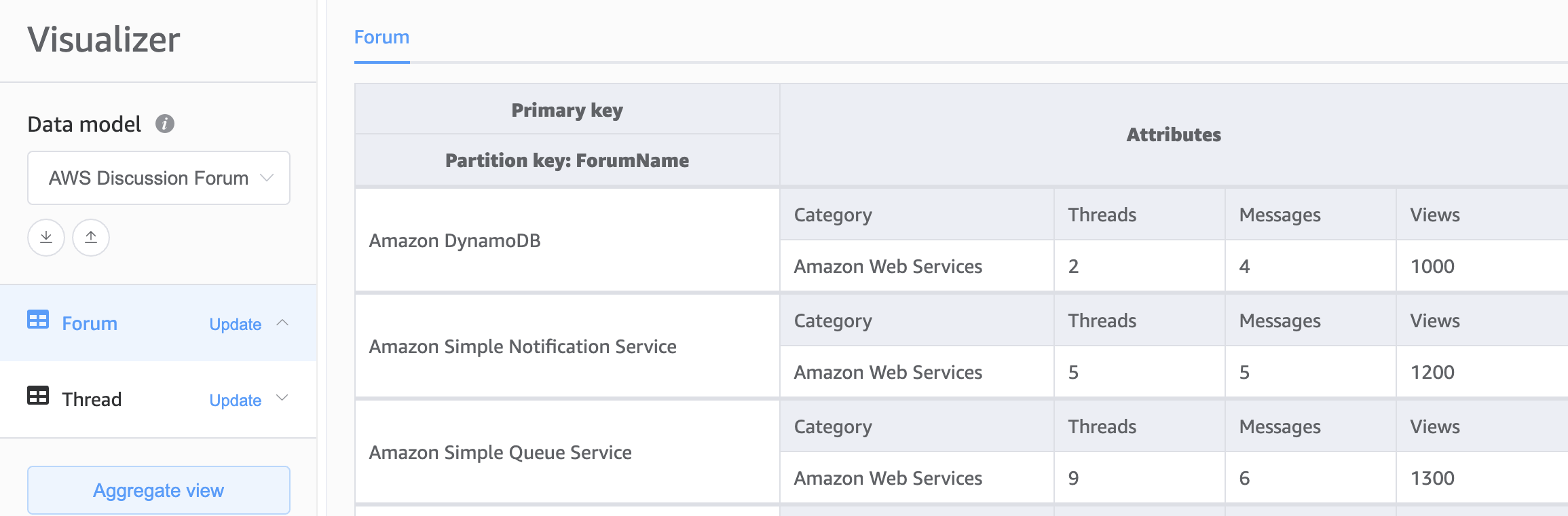
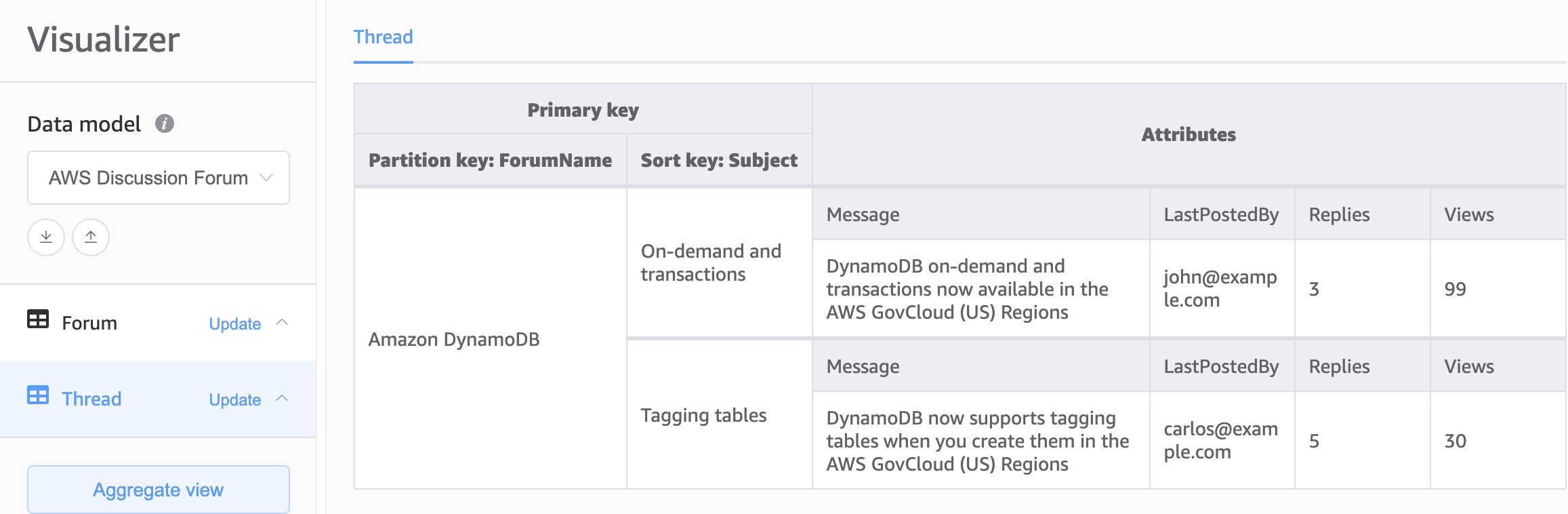
Vorteile
-
Einfacheres Design, wenn Sie die Arbeit mit dem Design mit einer einzelnen Tabelle nicht gewohnt sind
-
Einfachere Implementierung von GraphQL-Resolvern, da jeder Resolver einer einzelnen Entität (Tabelle) zugeordnet wird
-
Ermöglicht eindeutige Datenanforderungen für verschiedene Entitätstypen:
-
Für die einzelnen Tabellen, die geschäftskritisch sind, können Backups erstellt werden.
-
Die Tabellenverschlüsselung kann für jede Tabelle verwaltet werden. Im Fall von Anwendungen für mehrere Mandanten mit individuellen Mandanten-Verschlüsselungsanforderungen ermöglichen separate Mandantentabellen, dass jeder Kunde seinen eigenen Verschlüsselungsschlüssel hat.
-
Die Speicherklasse Infrequent Access kann nur für Tabellen mit historischen Daten aktiviert werden, um vollumfänglich vom Vorteil der Kosteneinsparungen zu profitieren. Weitere Informationen finden Sie unter DynamoDB-Tabellenklassen.
-
-
Jede Tabelle hat ihren eigenen Änderungsdatenstrom, sodass für jeden Elementtyp eine eigene Lambda-Funktion entworfen werden kann, anstatt einen einzelnen monolithischen Prozessor verwenden zu müssen.
Nachteile
-
Für Zugriffsmuster, die Daten aus mehreren Tabellen erfordern, sind mehrere Lesevorgänge aus DynamoDB erforderlich, und Daten müssen sich möglicherweise processed/joined im Client-Code befinden.
-
Für den Betrieb und die Überwachung mehrerer Tabellen sind mehr CloudWatch Alarme erforderlich, und jede Tabelle muss unabhängig skaliert werden
-
Die Berechtigungen jeder Tabelle müssen separat verwaltet werden. Wenn in Zukunft Tabellen hinzugefügt werden, müssen alle erforderlichen IAM-Rollen oder -Richtlinien geändert werden.
Wann sollte dies verwendet werden?
Wenn die Zugriffsmuster Ihrer Anwendung nicht mehrere Entitäten oder Tabellen zusammen abfragen müssen, ist der Entwurf mehrerer Tabellen ein guter und ausreichender Ansatz.
