Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Bausteine der Datenmodellierung in DynamoDB
In diesem Abschnitt werden die Bausteine behandelt, damit Sie Designmuster erhalten, die Sie für Ihre Anwendung verwenden können.
Themen
Baustein für zusammengesetzte Sortierschlüssel
Bei NoSQL denken viele vielleicht an eine nicht relationale Datenbank. Letztendlich spricht jedoch nichts dagegen, Beziehungen in ein DynamoDB-Schema einzubringen, diese sehen nur anders aus als relationale Datenbanken und ihre Fremdschlüssel. Eines der wichtigsten Muster, die wir verwenden können, um eine logische Hierarchie unserer Daten in DynamoDB zu entwickeln, ist ein zusammengesetzter Sortierschlüssel. Die gebräuchlichste Gestaltungsmethode besteht darin, jede Hierarchieebene (übergeordnete Ebene > untergeordnete Ebene > zweite untergeordnete Ebene) durch einen Hashtag zu trennen. Beispiel, PARENT#CHILD#GRANDCHILD#ETC.
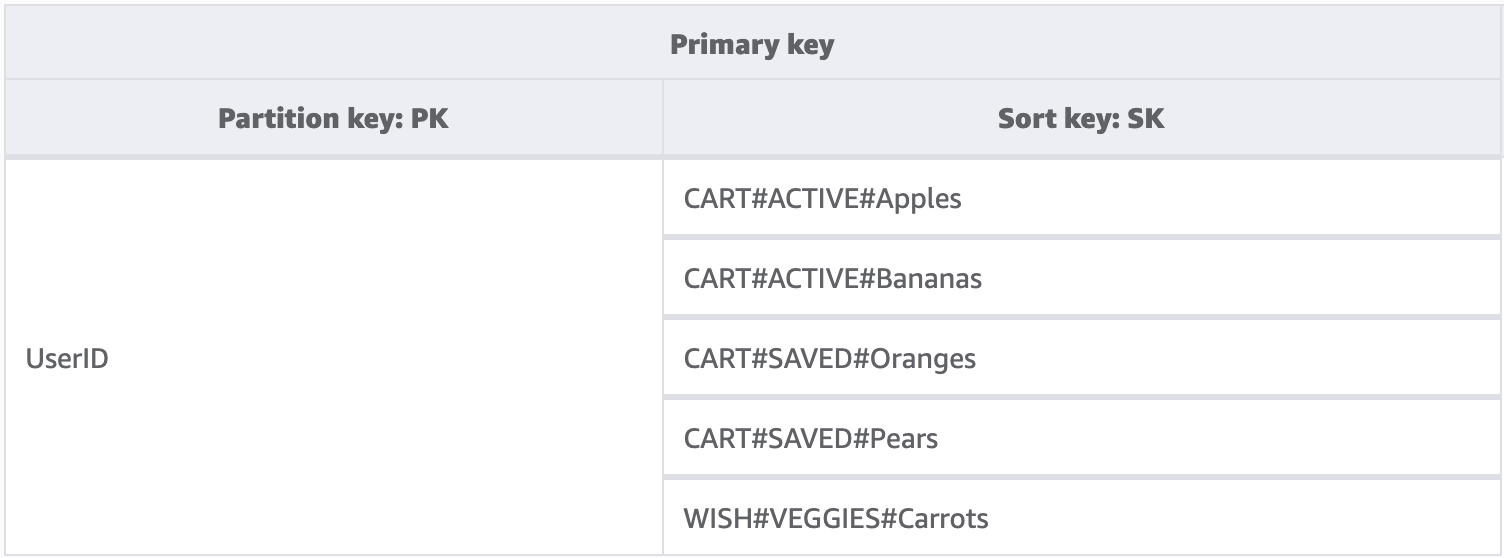
Während ein Partitionsschlüssel in DynamoDB für die Datenabfrage immer den genauen Wert benötigt, können wir eine Teilbedingung von links nach rechts auf den Sortierschlüssel anwenden, ähnlich wie beim Durchlaufen einer Binärstruktur.
Im obigen Beispiel haben wir einen E-Commerce-Shop mit einem Warenkorb, der über alle Benutzersitzungen hinweg verwaltet werden muss. Bei der Anmeldung möchte der Benutzer möglicherweise den gesamten Warenkorb einschließlich der für später gespeicherten Elemente sehen. An der Kasse sollten jedoch nur Elemente im aktiven Warenkorb zum Kauf geladen werden. Da beide KeyConditions explizit nach CART-Sortierschlüsseln fragen, werden die zusätzlichen Wunschlistendaten beim Lesen von DynamoDB einfach ignoriert. Zwar sind gespeicherte und aktive Elemente Teil desselben Warenkorbs, in verschiedenen Teilen der Anwendung müssen sie jedoch unterschiedlich behandelt werden. Die Anwendung einer KeyCondition auf das Präfix des Sortierschlüssels ist daher die beste Methode, um nur die Daten abzurufen, die für den jeweiligen Anwendungsteil benötigt werden.
Hauptmerkmale dieses Bausteins
-
Zusammengehörige Elemente werden lokal zueinander gespeichert, um einen effektiven Datenzugriff zu ermöglichen.
-
Mithilfe von
KeyConditionAusdrücken können Teilmengen der Hierarchie selektiv abgerufen werden, sodass sie nicht verschwendet werden RCUs -
Verschiedene Teile der Anwendung können ihre Elemente unter einem bestimmten Präfix speichern, um das Überschreiben von Elementen oder widersprüchliche Schreibvorgänge zu verhindern.
Baustein für Mehrmandantenfähigkeit
Viele Kunden verwenden DynamoDB für das Hosting von Daten für ihre mandantenfähigen Anwendungen. Für solche Szenarien möchten wir das Schema so gestalten, dass alle Daten eines einzelnen Mandanten in einer eigenen logischen Partition der Tabelle gespeichert werden. Dabei wird das Konzept der Elementauflistung genutzt, einem Begriff, der alle Elemente in einer DynamoDB-Tabelle mit demselben Partitionsschlüssel bezeichnet. Weitere Informationen über den Umgang von DynamoDB mit Mehrmandantenfähigkeit finden Sie unter Mehrmandantenfähigkeit in DynamoDB.
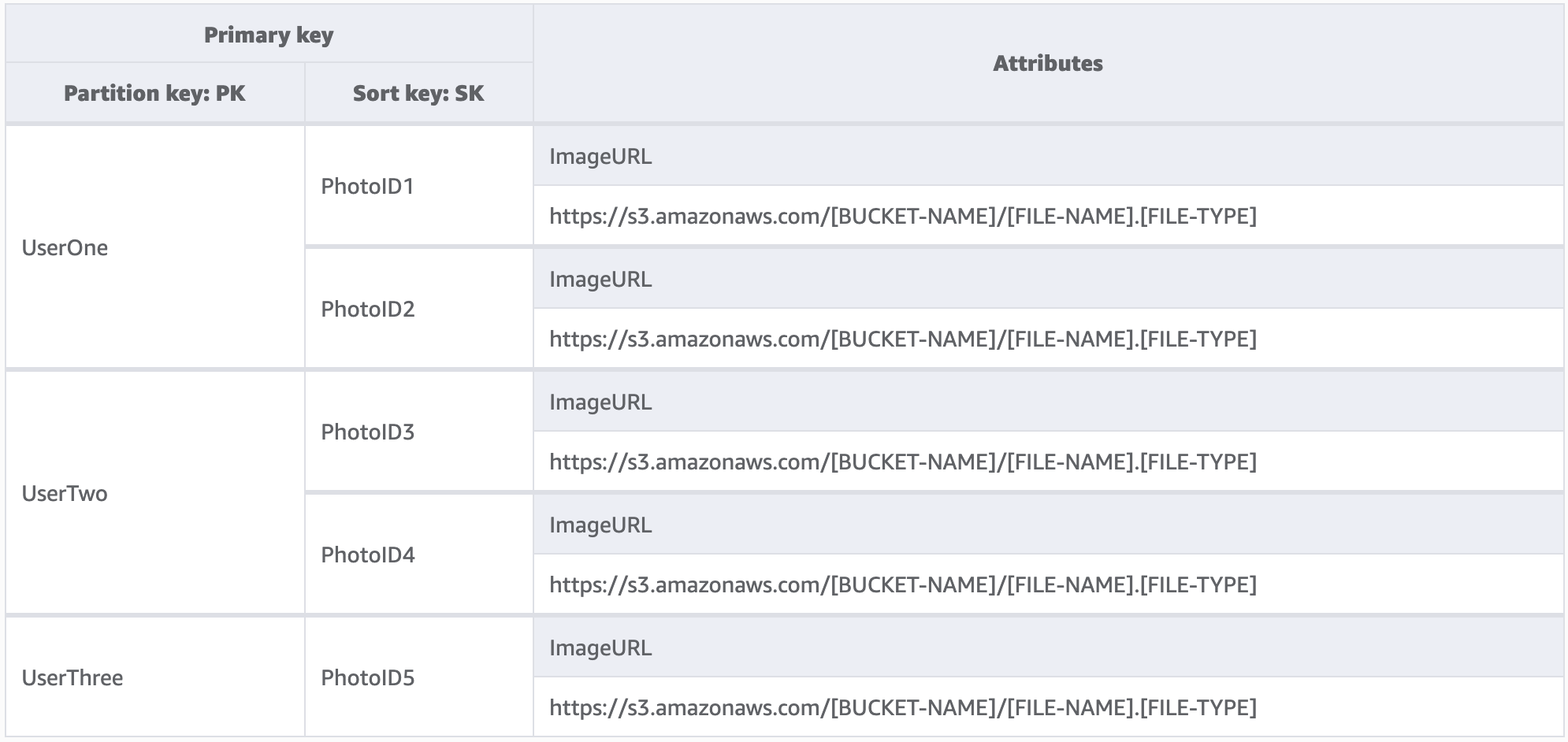
In diesem Beispiel betreiben wir eine Website für das Hosting von Fotos mit potenziell Tausenden von Benutzern. Jeder Benutzer lädt zunächst nur Fotos in sein eigenes Profil hoch, standardmäßig ist es den Benutzern jedoch nicht gestattet, die Fotos anderer Benutzer zu sehen. Idealerweise würde der Autorisierung jedes Benutzeraufrufs an Ihre API eine zusätzliche Isolationsstufe hinzugefügt, um sicherzustellen, dass die Benutzer nur Daten von ihrer eigenen Partition anfordern. Auf Schemaebene sind eindeutige Partitionsschlüssel jedoch angemessen.
Hauptmerkmale dieses Bausteins
-
Die Datenmenge, die ein Benutzer oder Mandant lesen kann, kann nur so groß wie die Gesamtmenge der Elemente in seiner Partition sein.
-
Die Entfernung der Daten eines Mandanten aufgrund einer Kontoschließung oder einer Aufforderung zur Einhaltung der Vorschriften kann diskret und kostengünstig erfolgen. Hierfür muss nur eine Abfrage ausgeführt werden, bei der der Partitionsschlüssel der betreffenden Mandanten-ID entspricht, und dann muss für jeden zurückgegebenen Primärschlüssel eine
DeleteItem-Operation durchgeführt werden.
Anmerkung
Bei der Entwicklung wurde die Mehrmandantenfähigkeit berücksichtigt. Sie können verschiedene Anbieter von Verschlüsselungsschlüsseln in einer einzigen Tabelle verwenden, um Daten sicher zu isolieren. Mit dem AWS Datenbankverschlüsselungs-SDK für Amazon DynamoDB können Sie eine clientseitige Verschlüsselung in Ihre DynamoDB-Workloads einbeziehen. Sie können eine Verschlüsselung auf Attributebene durchführen, sodass Sie bestimmte Attributwerte verschlüsseln können, bevor Sie sie in Ihrer DynamoDB-Tabelle speichern, und nach verschlüsselten Attributen suchen können, ohne zuvor die gesamte Datenbank zu entschlüsseln.
Baustein für Sparse Index
Manchmal erfordert ein Zugriffsmuster die Suche nach Elementen, die mit einem seltenen Element übereinstimmen, oder nach einem Element, das einen Status erhält (der eine eskalierte Antwort erfordert). Anstatt regelmäßig den gesamten Datensatz nach diesen Elementen abzufragen, können wir die Tatsache nutzen, dass globale sekundäre Indizes (GSI) nur spärlich mit Daten gefüllt sind. Dies bedeutet, dass nur die Elemente in der Basistabelle, die die im Index definierten Attribute aufweisen, in den Index repliziert werden.
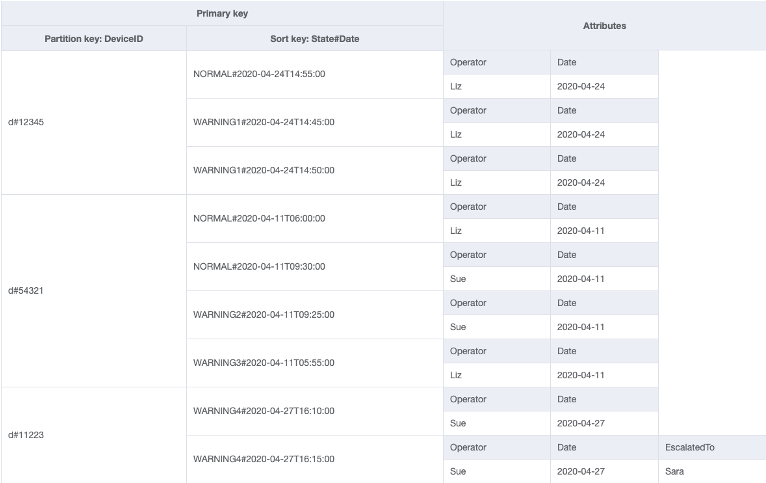

In diesem Beispiel sehen wir einen IoT-Anwendungsfall, bei dem jedes Gerät regelmäßig einen Status zurückmeldet. In den meisten Fällen erwarten wir die Meldung, dass alles in Ordnung ist. Gelegentlich kann es jedoch zu einem Fehler kommen, der an einen Reparaturtechniker weitergeleitet werden muss. Bei Berichten mit einer Eskalation wird dem Element das Attribut EscalatedTo hinzugefügt, dieses ist ansonsten aber nicht vorhanden. Der GSI in diesem Beispiel ist nach EscalatedTo partitioniert. Da der GSI Schlüssel aus der Basistabelle übernimmt, können wir immer noch sehen, welche DeviceID den Fehler zu welcher Uhrzeit gemeldet hat.
Lesevorgänge sind in DynamoDB zwar günstiger als Schreibvorgänge, Sparse Indexes stellen jedoch ein sehr leistungsfähiges Tool für Anwendungsfälle dar, in denen Instances eines bestimmten Elementtyps selten vorkommen, Lesevorgänge, um diese zu finden, jedoch häufig stattfinden.
Hauptmerkmale dieses Bausteins
-
Die Schreib- und Speicherkosten für den globalen Index mit geringer Dichte fallen nur für Elemente an, die dem Schlüsselmuster entsprechen, sodass die Kosten für den globalen Index erheblich niedriger sein können als bei anderen GSIs, auf die alle Elemente repliziert werden
-
Es kann immer noch ein zusammengesetzter Sortierschlüssel verwendet werden, um die Elemente, die der gewünschten Abfrage entsprechen, weiter einzugrenzen. So könnte beispielsweise ein Zeitstempel für den Sortierschlüssel verwendet werden, um nur die in den letzten X Minuten gemeldeten Fehler anzuzeigen (
SK > 5 minutes ago, ScanIndexForward: False).
Baustein für Time to Live
Bei den meisten Daten ist es für eine gewisse Zeitspanne sinnvoll, sie in einem primären Datenspeicher aufzubewahren. Um den Ablauf von Daten in DynamoDB zu erleichtern, gibt es eine Funktion namens Time to Live (TTL). Mit der TTL-Funktion können Sie auf Tabellenebene ein bestimmtes Attribut definieren, das auf Elemente mit einem Epochenzeitstempel (der in der Vergangenheit liegt) überwacht werden muss. Auf diese Weise können Sie abgelaufene Datensätze kostenlos aus der Tabelle löschen.
Anmerkung
Wenn Sie Version 2019.11.21 der globalen Tabellen (aktuell) und außerdem die Time-to-Live-Funktion verwenden, repliziert DynamoDB TTL-Löschungen in alle Replikattabellen. Die anfängliche TTL-Löschung verbraucht keine Schreibkapazität in der Region, in der die TTL abläuft. Die in die Replikattabelle(n) replizierte TTL-Löschung verbraucht jedoch in jeder Region mit einem Replikat replizierte Schreibkapazität. Dafür werden die entsprechenden Gebühren berechnet.
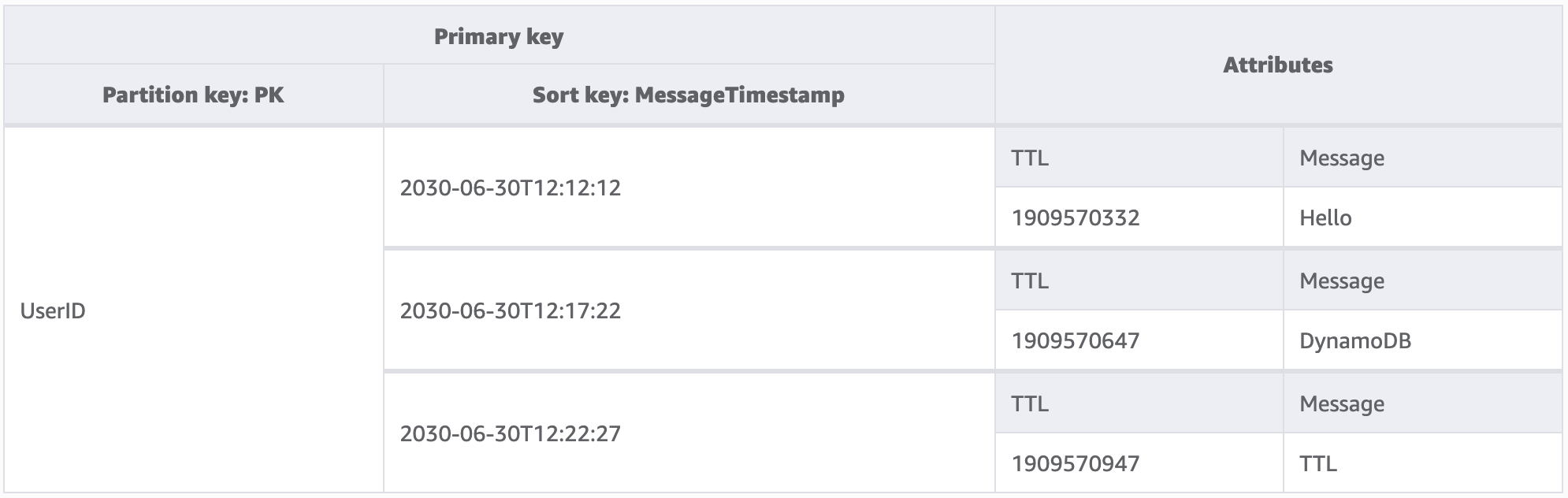
Mit der Anwendung in diesem Beispiel kann ein Benutzer kurzlebige Nachrichten erstellen. Wenn eine Nachricht in DynamoDB erstellt wird, wird das TTL-Attribut vom Anwendungscode auf ein Datum gesetzt, das sieben Tage in der Zukunft liegt. In etwa sieben Tagen wird DynamoDB feststellen, dass der Epochenzeitstempel dieser Elemente in der Vergangenheit liegt, und die Elemente löschen.
Da die von TTL durchgeführten Löschungen kostenlos sind, ist die Verwendung dieser Funktion zum Entfernen von historischen Daten aus der Tabelle dringend zu empfehlen. Dadurch reduzieren sich die monatlichen Speicherkosten insgesamt und wahrscheinlich auch die Kosten für Lesevorgänge der Benutzer, da bei den Abfragen weniger Daten abgerufen werden müssen. TTL ist zwar auf Tabellenebene aktiviert, es ist jedoch Ihre Entscheidung, für welche Elemente oder Entitäten Sie ein TTL-Attribut erstellen möchten und wie weit in der Zukunft Sie den Epochenzeitstempel festlegen möchten.
Hauptmerkmale dieses Bausteins
-
TTL-Löschungen werden im Hintergrund ohne Auswirkungen auf die Tabellenleistung ausgeführt.
-
TTL ist ein asynchroner Prozess, der ungefähr alle sechs Stunden ausgeführt wird. Es kann jedoch mehr als 48 Stunden dauern, bis ein abgelaufener Datensatz gelöscht wird.
-
Verlassen Sie sich nicht auf TTL-Löschungen für Anwendungsfälle wie Sperrdatensätze oder die Statusverwaltung, wenn veraltete Daten in weniger als 48 Stunden bereinigt werden müssen.
-
-
Sie können dem TTL-Attribut einen gültigen Attributnamen geben, der Wert muss jedoch ein numerischer Wert sein.
Baustein für Time to Live für die Archivierung
TTL ist zwar ein effektives Tool zum Löschen älterer Daten aus DynamoDB, in vielen Anwendungsfällen müssen die Daten jedoch über ihre Zeit im primären Datenspeicher hinausgehend archiviert werden. In diesem Fall können wir die zeitgesteuerte Löschung von Datensätzen durch TTL nutzen, um abgelaufene Datensätze in einen langfristigen Datenspeicher zu verschieben.
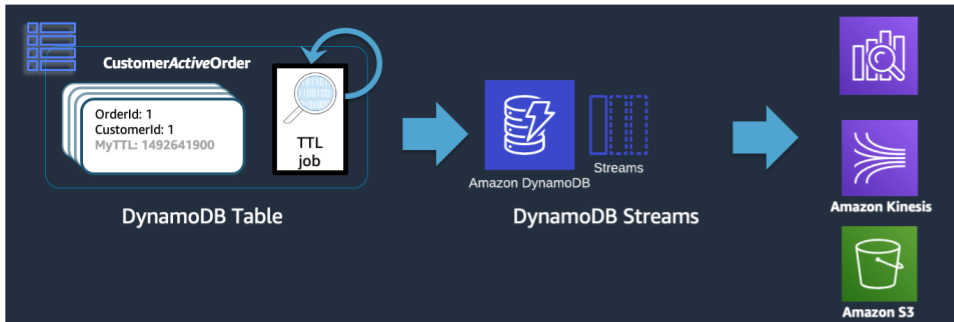
Wenn DynamoDB eine TTL-Löschung durchführt, wird dies weiterhin als Delete-Ereignis in den DynamoDB-Stream übertragen. Wenn DynamoDB TTL jedoch den Löschvorgang durchführt, enthält der Stream-Datensatz das Attribut principal:dynamodb. Wenn wir einen Lambda-Abonnenten für den DynamoDB-Stream verwenden, können wir einen Event-Filter nur für das DynamoDB-Prinzipalattribut anwenden und wissen, dass alle Datensätze, die diesem Filter entsprechen, in einen Archivspeicher wie Amazon Glacier übertragen werden müssen.
Hauptmerkmale dieses Bausteins
-
Sobald die Lesevorgänge von DynamoDB mit niedriger Latenz für die historischen Elemente nicht mehr benötigt werden, kann die Migration zu einem kälteren Speicherservice wie Amazon Glacier die Speicherkosten erheblich senken und gleichzeitig die Datenkonformitätsanforderungen Ihres Anwendungsfalls erfüllen.
-
Wenn die Daten in Amazon S3 gespeichert werden, können kostengünstige Analysetools wie Amazon Athena oder Redshift Spectrum für historische Datenanalysen verwendet werden.
Baustein für vertikale Partitionierung
Benutzer, die mit einer Dokumentmodelldatenbank vertraut sind, werden es gewohnt sein, alle zusammengehörigen Daten in einem einzigen JSON-Dokument zu speichern. DynamoDB unterstützt zwar JSON-Datentypen, nicht jedoch die Ausführung von KeyConditions für verschachteltes JSON. Da KeyConditions sie bestimmen, wie viele Daten von der Festplatte gelesen werden und wie viele Daten RCUs eine Abfrage tatsächlich verbraucht, kann dies zu großen Ineffizienzen führen. Zur Optimierung der Schreib- und Lesevorgänge von DynamoDB empfehlen wir, die einzelnen Entitäten des Dokuments in DynamoDB-Elemente aufzuteilen, was auch als vertikale Partitionierung bezeichnet wird.

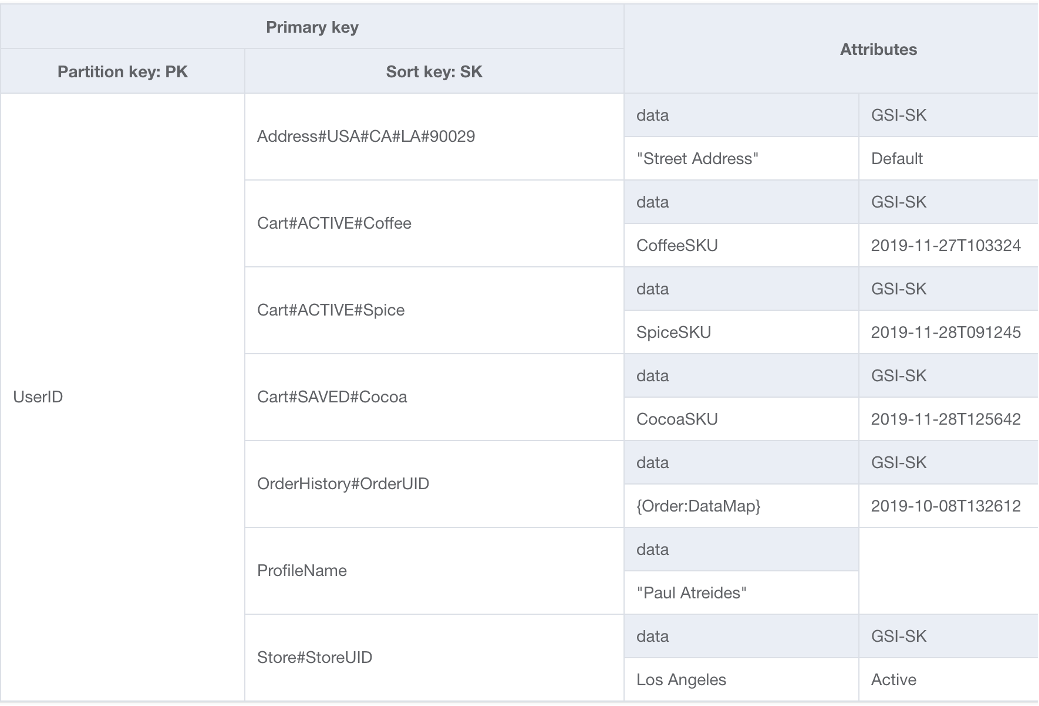
Die vertikale Partitionierung, wie oben dargestellt, ist ein wichtiges Beispiel für das Design einer einzelnen Tabelle in Aktion, kann aber bei Bedarf auch für mehrere Tabellen implementiert werden. Da DynamoDB Schreibvorgänge in 1-KB-Schritten abrechnet, sollten Sie das Dokument idealerweise so partitionieren, dass Elemente mit weniger als 1 KB entstehen.
Hauptmerkmale dieses Bausteins
-
Eine Hierarchie von Datenbeziehungen wird über Sortierschlüsselpräfixe aufrechterhalten, sodass die einzelne Dokumentstruktur bei Bedarf clientseitig neu aufgebaut werden kann.
-
Einzelne Komponenten der Datenstruktur können unabhängig voneinander aktualisiert werden, sodass kleine Elementaktualisierungen nur 1 WCU umfassen.
-
Bei Verwendung des Sortierschlüssels
BeginsWithkann die Anwendung ähnliche Daten in einer einzigen Abfrage abrufen. So können die Lesekosten aggregiert werden, um die Gesamtkosten/Latenz zu verringern. -
Große Dokumente können leicht die maximale Größe von 400 KB für einzelne Elemente in DynamoDB überschreiten. Mithilfe der vertikalen Partitionierung lässt sich dieser Höchstwert umgehen.
Baustein für Schreib-Sharding
Eine der wenigen festen Beschränkungen in DynamoDB bezieht sich auf den Durchsatz, den eine einzelne physische Partition (nicht unbedingt ein einzelner Partitionsschlüssel) pro Sekunde aufrechterhalten kann. Die aktuellen Höchstwerte lauten wie folgt:
-
1 000 WCU (oder 1 000 <= 1 KB geschriebene Elemente pro Sekunde) und 3 000 RCU (oder 3 000 <= 4 KB Lesevorgänge pro Sekunde) Strikt konsistent oder
-
6 000 <= 4 KB Lesevorgänge pro Sekunde Letztendlich konsistent
Falls Anfragen an die Tabelle einen dieser Grenzwerte überschreiten, wird ein Fehler ThroughputExceededException an das Client-SDK zurückgesendet. Dies wird allgemein als Drosselung bezeichnet. Für Anwendungsfälle, die über diesen Grenzwert hinausgehende Lesevorgänge erfordern, ist es meistens am besten, einen Lese-Cache vor DynamoDB zu platzieren. Schreibvorgänge erfordern jedoch ein Design auf Schemaebene, das als Schreib-Sharding bekannt ist.
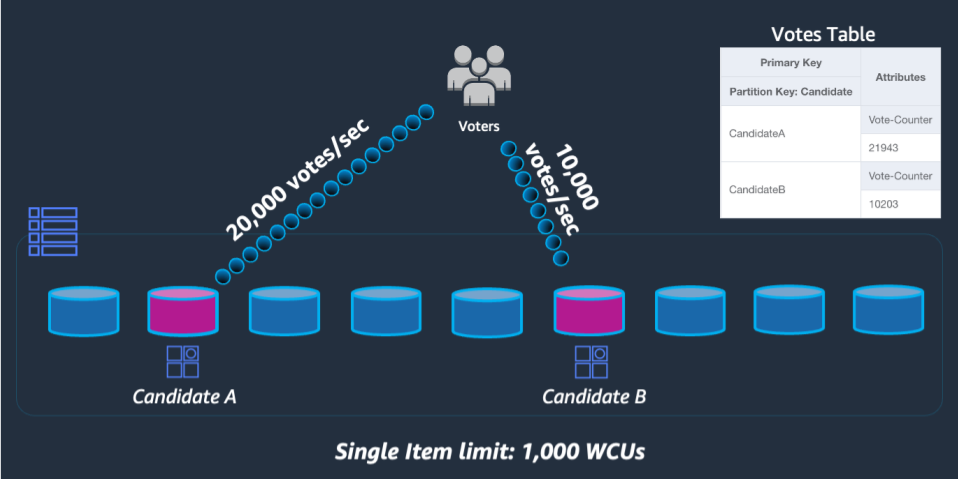
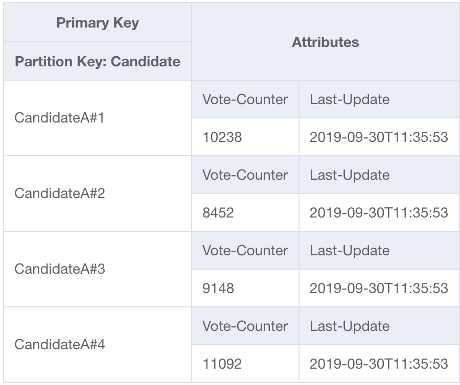
Um dieses Problem zu lösen, fügen wir für jeden Teilnehmer im UpdateItem-Code der Anwendung eine zufällige Ganzzahl an das Ende des Partitionsschlüssels an. Der Bereich des Zufallszahlengenerators muss eine Obergrenze haben, die der erwarteten Anzahl von Schreibvorgängen pro Sekunde für einen bestimmten Teilnehmer geteilt durch 1 000 entspricht oder diese übersteigt. Um 20 000 Stimmen pro Sekunde zu unterstützen, würde die Angabe beispielsweise „rand(0,19)“ lauten. Da die Daten nun auf separaten logischen Partitionen gespeichert sind, müssen sie beim Lesen wieder zusammengeführt werden. Da die Gesamtzahl der Stimmen nicht in Echtzeit vorliegen muss, könnte eine Lambda-Funktion, die alle X Minuten alle Abstimmungspartitionen liest, eine gelegentliche Aggregation für jeden Teilnehmer durchführen und für Live-Lesevorgänge in einen einzigen Datensatz für die Gesamtzahl der Stimmen zurückschreiben.
Hauptmerkmale dieses Bausteins
-
Für Anwendungsfälle mit nicht vermeidbarem extrem hohem Schreibdurchsatz für einen bestimmten Partitionsschlüssel können Schreibvorgänge künstlich auf mehrere DynamoDB-Partitionen verteilt werden.
-
GSIs Bei einem Partitionsschlüssel mit niedriger Kardinalität sollte dieses Muster ebenfalls verwendet werden, da die Drosselung auf einer globalen Datenschnittstelle zu Gegendruck bei Schreibvorgängen in der Basistabelle führt
