Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Entwerfen Ihres GraphQL-SchemasDas GraphQL-Schema ist die Grundlage jeder GraphQL-Serverimplementierung. Jede GraphQL-API wird durch ein einzelnes Schema definiert, das Typen und Felder enthält, die beschreiben, wie die Daten aus Anfragen gefüllt werden. Die Daten, die durch Ihre API fließen, und die ausgeführten Operationen müssen anhand des Schemas validiert werden.
Im Allgemeinen beschreibt das GraphQL-Typsystem die Funktionen eines GraphQL-Servers und wird verwendet, um festzustellen, ob eine Abfrage gültig ist. Das Typsystem eines Servers wird oft als das Schema dieses Servers bezeichnet und kann aus verschiedenen Objekttypen, Skalartypen, Eingabetypen und mehr bestehen. GraphQL ist sowohl deklarativ als auch stark typisiert, was bedeutet, dass die Typen zur Laufzeit gut definiert sind und nur das zurückgeben, was angegeben wurde.
AWS AppSync ermöglicht es Ihnen, GraphQL-Schemas zu definieren und zu konfigurieren. Der folgende Abschnitt beschreibt, wie Sie GraphQL-Schemas mithilfe AWS AppSync der Dienste von Grund auf neu erstellen.
Strukturierung eines GraphQL-Schemas
Wir empfehlen, den Abschnitt Schemas zu lesen, bevor Sie fortfahren.
GraphQL ist ein leistungsstarkes Tool zur Implementierung von API-Diensten. Laut der Website von GraphQL ist GraphQL wie folgt:
„GraphQL ist eine Abfragesprache APIs und eine Laufzeit für die Ausführung dieser Abfragen mit Ihren vorhandenen Daten. GraphQL bietet eine vollständige und verständliche Beschreibung der Daten in Ihrer API, gibt Kunden die Möglichkeit, genau nach dem zu fragen, was sie benötigen, und nicht mehr, erleichtert die Weiterentwicklung APIs im Laufe der Zeit und ermöglicht leistungsstarke Entwicklertools. “
Dieser Abschnitt behandelt den allerersten Teil Ihrer GraphQL-Implementierung, das Schema. Unter Verwendung des obigen Zitats spielt ein Schema die Rolle, „eine vollständige und verständliche Beschreibung der Daten in Ihrer API bereitzustellen“. Mit anderen Worten, ein GraphQL-Schema ist eine textuelle Darstellung der Daten, Operationen und der Beziehungen zwischen ihnen Ihres Dienstes. Das Schema gilt als Haupteinstiegspunkt für Ihre GraphQL-Serviceimplementierung. Es überrascht nicht, dass es oft eines der ersten Dinge ist, die Sie in Ihrem Projekt machen. Wir empfehlen, den Abschnitt Schemas zu lesen, bevor Sie fortfahren.
Um den Abschnitt Schemas zu zitieren: GraphQL-Schemas sind in der Schema Definition Language (SDL) geschrieben. SDL besteht aus Typen und Feldern mit einer festgelegten Struktur:
-
Typen: Mit Typen definiert GraphQL die Form und das Verhalten der Daten. GraphQL unterstützt eine Vielzahl von Typen, die später in diesem Abschnitt erklärt werden. Jeder Typ, der in Ihrem Schema definiert ist, enthält seinen eigenen Bereich. Innerhalb des Bereichs befinden sich ein oder mehrere Felder, die einen Wert oder eine Logik enthalten können, die in Ihrem GraphQL-Dienst verwendet werden. Typen erfüllen viele verschiedene Rollen, am häufigsten sind Objekte oder Skalare (primitive Werttypen).
-
Felder: Felder existieren innerhalb des Gültigkeitsbereichs eines Typs und enthalten den Wert, der vom GraphQL-Dienst angefordert wird. Diese sind Variablen in anderen Programmiersprachen sehr ähnlich. Die Form der Daten, die Sie in Ihren Feldern definieren, bestimmt, wie die Daten in einer request/response Operation strukturiert werden. Auf diese Weise können Entwickler vorhersagen, was zurückgegeben wird, ohne zu wissen, wie das Backend des Dienstes implementiert ist.
Die einfachsten Schemas werden drei verschiedene Datenkategorien enthalten:
-
Schemastämme: Stammverzeichnisse definieren die Einstiegspunkte Ihres Schemas. Es verweist auf die Felder, die bestimmte Operationen an den Daten ausführen, z. B. etwas hinzufügen, löschen oder ändern.
-
Typen: Dies sind Basistypen, die verwendet werden, um die Form der Daten darzustellen. Man kann sich diese fast als Objekte oder abstrakte Repräsentationen von etwas mit definierten Eigenschaften vorstellen. Sie könnten beispielsweise ein Person Objekt erstellen, das eine Person in einer Datenbank darstellt. Die Eigenschaften jeder Person werden in den Person AS-Feldern definiert. Sie können alles sein wie Name, Alter, Beruf, Adresse usw. der Person.
-
Spezielle Objekttypen: Dies sind die Typen, die das Verhalten der Operationen in Ihrem Schema definieren. Jeder spezielle Objekttyp wird einmal pro Schema definiert. Sie werden zuerst im Schemastamm platziert und dann im Hauptteil des Schemas definiert. Jedes Feld in einem speziellen Objekttyp definiert eine einzelne Operation, die von Ihrem Resolver implementiert werden soll.
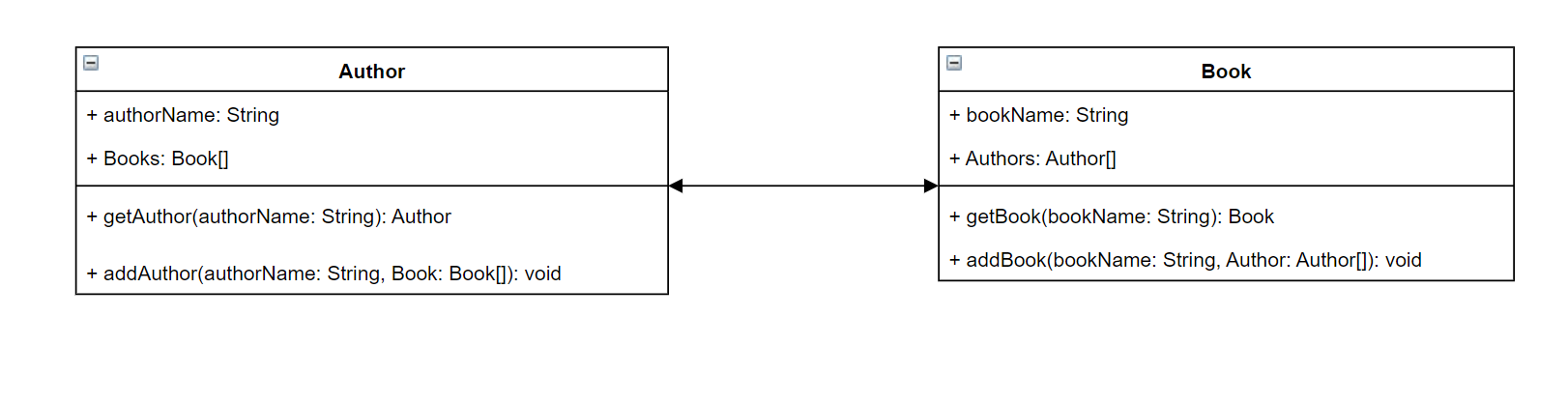
Um das ins rechte Licht zu rücken, stellen Sie sich vor, Sie erstellen einen Dienst, der Autoren und die von ihnen geschriebenen Bücher speichert. Jeder Autor hat einen Namen und eine Reihe von Büchern, die er verfasst hat. Jedes Buch hat einen Namen und eine Liste der assoziierten Autoren. Wir möchten auch die Möglichkeit haben, Bücher und Autoren hinzuzufügen oder abzurufen. Eine einfache UML-Darstellung dieser Beziehung könnte wie folgt aussehen:
In GraphQL stellen die Entitäten Author und zwei verschiedene Objekttypen in Ihrem Schema Book dar:
type Author {
}
type Book {
}
Authorenthält authorName undBooks, während es bookName und Book Authors enthält. Diese können als Felder im Rahmen Ihrer Typen dargestellt werden:
type Author {
authorName: String
Books: [Book]
}
type Book {
bookName: String
Authors: [Author]
}
Wie Sie sehen können, sind die Typdarstellungen dem Diagramm sehr ähnlich. Bei den Methoden wird es jedoch etwas schwieriger. Diese werden als Feld in einem von wenigen speziellen Objekttypen platziert. Ihre spezielle Objektkategorisierung hängt von ihrem Verhalten ab. GraphQL enthält drei grundlegende spezielle Objekttypen: Abfragen, Mutationen und Abonnements. Weitere Informationen finden Sie unter Spezielle Objekte.
Da getAuthor beide Daten anfordern, werden sie einem Query speziellen Objekttyp zugeordnet: getBook
type Author {
authorName: String
Books: [Book]
}
type Book {
bookName: String
Authors: [Author]
}
type Query {
getAuthor(authorName: String): Author
getBook(bookName: String): Book
}
Die Operationen sind mit der Abfrage verknüpft, die wiederum mit dem Schema verknüpft ist. Wenn Sie einen Schemastamm hinzufügen, wird der spezielle Objekttyp (Queryin diesem Fall) als einer Ihrer Einstiegspunkte definiert. Dies kann mit dem schema Schlüsselwort geschehen:
schema {
query: Query
}
type Author {
authorName: String
Books: [Book]
}
type Book {
bookName: String
Authors: [Author]
}
type Query {
getAuthor(authorName: String): Author
getBook(bookName: String): Book
}
Schauen Sie sich die letzten beiden Methoden an addAuthor und addBook fügen Ihrer Datenbank Daten hinzu, sodass sie in einem Mutation speziellen Objekttyp definiert werden. Aus der Seite „Typen“ wissen wir jedoch auch, dass Eingaben, die direkt auf Objekte verweisen, nicht zulässig sind, da es sich ausschließlich um Ausgabetypen handelt. In diesem Fall können wir Author oder nicht verwendenBook, also müssen wir einen Eingabetyp mit denselben Feldern erstellen. In diesem Beispiel haben wir AuthorInput und hinzugefügtBookInput, die beide dieselben Felder ihres jeweiligen Typs akzeptieren. Dann erstellen wir unsere Mutation mit den Eingaben als Parameter:
schema {
query: Query
mutation: Mutation
}
type Author {
authorName: String
Books: [Book]
}
input AuthorInput {
authorName: String
Books: [BookInput]
}
type Book {
bookName: String
Authors: [Author]
}
input BookInput {
bookName: String
Authors: [AuthorInput]
}
type Query {
getAuthor(authorName: String): Author
getBook(bookName: String): Book
}
type Mutation {
addAuthor(input: [BookInput]): Author
addBook(input: [AuthorInput]): Book
}
Lassen Sie uns überprüfen, was wir gerade getan haben:
-
Wir haben ein Schema mit den Author Typen Book und zur Darstellung unserer Entitäten erstellt.
-
Wir haben die Felder hinzugefügt, die die Eigenschaften unserer Entitäten enthalten.
-
Wir haben eine Abfrage hinzugefügt, um diese Informationen aus der Datenbank abzurufen.
-
Wir haben eine Mutation hinzugefügt, um Daten in der Datenbank zu manipulieren.
-
Wir haben Eingabetypen hinzugefügt, um unsere Objektparameter in der Mutation zu ersetzen und den Regeln von GraphQL zu entsprechen.
-
Wir haben die Abfrage und die Mutation zu unserem Stammschema hinzugefügt, damit die GraphQL-Implementierung die Position des Root-Typs versteht.
Wie Sie sehen können, stützt sich der Prozess der Erstellung eines Schemas auf viele Konzepte aus der Datenmodellierung (insbesondere der Datenbankmodellierung) im Allgemeinen. Sie können sich das Schema so vorstellen, dass es der Form der Daten aus der Quelle entspricht. Es dient auch als Modell, das der Resolver implementieren wird. In den folgenden Abschnitten erfahren Sie, wie Sie mithilfe verschiedener AWS unterstützter Tools und Dienste ein Schema erstellen.
Die Beispiele in den folgenden Abschnitten sind nicht für die Ausführung in einer echten Anwendung vorgesehen. Sie dienen nur dazu, die Befehle zu veranschaulichen, damit Sie Ihre eigenen Anwendungen erstellen können.
Erstellen von Schemata
Ihr Schema wird sich in einer Datei mit dem Namen befindenschema.graphql. AWS AppSync ermöglicht es Benutzern, mit verschiedenen Methoden neue Schemas für ihr GraphQL APIs zu erstellen. In diesem Beispiel erstellen wir eine leere API zusammen mit einem leeren Schema.
- Console
-
-
Melden Sie sich bei der an AWS Management Console und öffnen Sie die AppSyncKonsole.
-
Wählen Sie im Dashboard Create API (API erstellen) aus.
-
Wählen Sie unter API-Optionen GraphQL APIs, Von Grund auf neu entwerfen und dann Weiter aus.
-
Ändern Sie für den API-Namen den vorausgefüllten Namen in den Namen, den Ihre Anwendung benötigt.
-
Für Kontaktinformationen können Sie eine Kontaktperson angeben, um einen Manager für die API zu identifizieren. Dies ist ein optionales Feld.
-
Unter Private API-Konfiguration können Sie private API-Funktionen aktivieren. Auf eine private API kann nur von einem konfigurierten VPC-Endpunkt (VPCE) aus zugegriffen werden. Weitere Informationen finden Sie unter Privat. APIs
Wir empfehlen, diese Funktion für dieses Beispiel nicht zu aktivieren. Wählen Sie „Weiter“, nachdem Sie Ihre Eingaben überprüft haben.
-
Unter GraphQL-Typ erstellen können Sie wählen, ob Sie eine DynamoDB-Tabelle erstellen möchten, die Sie als Datenquelle verwenden möchten, oder dies überspringen und später tun möchten.
Wählen Sie für dieses Beispiel Create GraphQL resources later aus. Wir werden eine Ressource in einem separaten Abschnitt erstellen.
-
Überprüfe deine Eingaben und wähle dann Create API.
-
Sie befinden sich im Dashboard Ihrer spezifischen API. Sie können es daran erkennen, dass der Name der API oben im Dashboard angezeigt wird. Wenn dies nicht der Fall ist, können Sie APIsin der Seitenleiste auswählen und dann Ihre API im APIs Dashboard auswählen.
-
Wählen Sie in der Seitenleiste unter dem Namen Ihrer API Schema aus.
-
Im Schema-Editor können Sie Ihre schema.graphql Datei konfigurieren. Sie kann leer sein oder mit Typen gefüllt sein, die aus einem Modell generiert wurden. Auf der rechten Seite befindet sich der Abschnitt Resolver, in dem Sie Resolver an Ihre Schemafelder anhängen können. In diesem Abschnitt werden wir uns nicht mit Resolvern befassen.
- CLI
-
Stellen Sie bei der Verwendung der CLI sicher, dass Sie über die richtigen Berechtigungen für den Zugriff und die Erstellung von Ressourcen im Service verfügen. Möglicherweise möchten Sie Richtlinien mit den geringsten Rechten für Benutzer ohne Administratorrechte festlegen, die auf den Service zugreifen müssen. Weitere Informationen zu AWS AppSync Richtlinien finden Sie unter Identitäts- und Zugriffsverwaltung für. AWS AppSync
Darüber hinaus empfehlen wir, zuerst die Konsolenversion zu lesen, falls Sie dies noch nicht getan haben.
-
Falls Sie dies noch nicht getan haben, installieren Sie die AWS
CLI und fügen Sie dann Ihre Konfiguration hinzu.
-
Erstellen Sie ein GraphQL-API-Objekt, indem Sie den create-graphql-apiBefehl ausführen.
Sie müssen zwei Parameter für diesen speziellen Befehl eingeben:
-
Die name Ihrer API.
-
Die oder die Art der Anmeldeinformationenauthentication-type, die für den Zugriff auf die API verwendet werden (IAM, OIDC usw.).
Andere Parameter wie Region müssen konfiguriert werden, verwenden aber normalerweise standardmäßig Ihre CLI-Konfigurationswerte.
Ein Beispielbefehl könnte wie folgt aussehen:
aws appsync create-graphql-api --name testAPI123 --authentication-type API_KEY
Eine Ausgabe wird in der CLI zurückgegeben. Hier ein Beispiel:
{
"graphqlApi": {
"xrayEnabled": false,
"name": "testAPI123",
"authenticationType": "API_KEY",
"tags": {},
"apiId": "abcdefghijklmnopqrstuvwxyz",
"uris": {
"GRAPHQL": "https://zyxwvutsrqponmlkjihgfedcba.appsync-api.us-west-2.amazonaws.com/graphql",
"REALTIME": "wss://zyxwvutsrqponmlkjihgfedcba.appsync-realtime-api.us-west-2.amazonaws.com/graphql"
},
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz"
}
}
-
Dies ist ein optionaler Befehl, der ein vorhandenes Schema verwendet und es mithilfe eines Base-64-Blobs in den AWS AppSync Dienst hochlädt. Wir werden diesen Befehl nicht für dieses Beispiel verwenden.
Führen Sie den Befehl start-schema-creation aus.
Für diesen speziellen Befehl müssen Sie zwei Parameter eingeben:
-
Ihr api-id aus dem vorherigen Schritt.
-
Das Schema definition ist ein Base-64-codierter binärer Blob.
Ein Beispielbefehl könnte wie folgt aussehen:
aws appsync start-schema-creation --api-id abcdefghijklmnopqrstuvwxyz --definition "aa1111aa-123b-2bb2-c321-12hgg76cc33v"
Es wird eine Ausgabe zurückgegeben:
{
"status": "PROCESSING"
}
Dieser Befehl gibt nach der Verarbeitung nicht die endgültige Ausgabe zurück. Sie müssen einen separaten Befehl verwenden get-schema-creation-status, um das Ergebnis zu sehen. Beachten Sie, dass diese beiden Befehle asynchron sind, sodass Sie den Ausgabestatus überprüfen können, auch wenn das Schema noch erstellt wird.
- CDK
-
Bevor Sie das CDK verwenden, empfehlen wir, die offizielle Dokumentation des CDK zusammen mit AWS AppSync der CDK-Referenz zu lesen.
Die unten aufgeführten Schritte zeigen nur ein allgemeines Beispiel für das Snippet, das zum Hinzufügen einer bestimmten Ressource verwendet wurde. Dies soll keine funktionierende Lösung in Ihrem Produktionscode sein. Wir gehen auch davon aus, dass Sie bereits eine funktionierende App haben.
-
Der Ausgangspunkt für das CDK ist etwas anders. Idealerweise sollte Ihre schema.graphql Datei bereits erstellt sein. Sie müssen nur eine neue Datei mit der .graphql Dateierweiterung erstellen. Dies kann eine leere Datei sein.
-
Im Allgemeinen müssen Sie möglicherweise die Import-Direktive zu dem Dienst hinzufügen, den Sie verwenden. Zum Beispiel kann es den folgenden Formen folgen:
import * as x from 'x'; # import wildcard as the 'x' keyword from 'x-service'
import {a, b, ...} from 'c'; # import {specific constructs} from 'c-service'
Um eine GraphQL-API hinzuzufügen, muss Ihre Stack-Datei den AWS AppSync Dienst importieren:
import * as appsync from 'aws-cdk-lib/aws-appsync';
Das bedeutet, dass wir den gesamten Service unter dem appsync Schlüsselwort importieren. Um dies in Ihrer App zu verwenden, verwenden Ihre AWS AppSync Konstrukte das Formatappsync.construct_name. Wenn wir zum Beispiel eine GraphQL-API erstellen wollten, würden wir sagennew appsync.GraphqlApi(args_go_here). Der folgende Schritt zeigt dies.
-
Die grundlegendste GraphQL-API wird eine name für die API und den schema Pfad enthalten.
const add_api = new appsync.GraphqlApi(this, 'API_ID', {
name: 'name_of_API_in_console',
schema: appsync.SchemaFile.fromAsset(path.join(__dirname, 'schema_name.graphql')),
});
Sehen wir uns an, was dieser Ausschnitt bewirkt. Im Rahmen von api erstellen wir eine neue GraphQL-API, indem wir aufrufenappsync.GraphqlApi(scope: Construct, id:
string, props: GraphqlApiProps). Der Gültigkeitsbereich istthis, was sich auf das aktuelle Objekt bezieht. Die ID lautetAPI_ID, was der Ressourcenname Ihrer GraphQL-API sein wird, CloudFormation wenn sie erstellt wird. Das GraphqlApiProps enthält die name Ihrer GraphQL-API und dieschema. Das schema generiert ein Schema (SchemaFile.fromAsset), indem es den absoluten Pfad (__dirname) nach der .graphql Datei (schema_name.graphql) durchsucht. In einem realen Szenario befindet sich Ihre Schemadatei wahrscheinlich in der CDK-App.
Um die an Ihrer GraphQL-API vorgenommenen Änderungen verwenden zu können, müssen Sie die App erneut bereitstellen.
Hinzufügen von Typen zu Schemas
Nachdem Sie Ihr Schema hinzugefügt haben, können Sie damit beginnen, sowohl Ihre Eingabe- als auch Ihre Ausgabetypen hinzuzufügen. Beachten Sie, dass die hier aufgeführten Typen nicht in echtem Code verwendet werden sollten. Sie sind lediglich Beispiele, die Ihnen helfen sollen, den Prozess zu verstehen.
Zuerst erstellen wir einen Objekttyp. In echtem Code müssen Sie nicht mit diesen Typen beginnen. Sie können jederzeit jeden beliebigen Typ erstellen, solange Sie die Regeln und die Syntax von GraphQL befolgen.
In den nächsten Abschnitten wird der Schema-Editor verwendet, lassen Sie ihn also offen.
- Console
-
-
Sie können einen Objekttyp erstellen, indem Sie das type Schlüsselwort zusammen mit dem Namen des Typs verwenden:
type Type_Name_Goes_Here {}
Innerhalb des Gültigkeitsbereichs des Typs können Sie Felder hinzufügen, die die Eigenschaften des Objekts repräsentieren:
type Type_Name_Goes_Here {
# Add fields here
}
Hier ein Beispiel:
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
In diesem Schritt haben wir einen generischen Objekttyp hinzugefügt, bei dem ein erforderliches id Feld gespeichert alsID, ein title Feld gespeichert als und ein date FeldString, das als gespeichert istAWSDateTime. Eine Liste der Typen und Felder und ihrer Funktionsweise finden Sie unter Schemas. Eine Liste der Skalare und ihrer Funktionsweise finden Sie in der Typenreferenz.
- CLI
-
Wir empfehlen, zuerst die Konsolenversion zu lesen, falls Sie dies noch nicht getan haben.
-
Sie können einen Objekttyp erstellen, indem Sie den create-typeBefehl ausführen.
Für diesen speziellen Befehl müssen Sie einige Parameter eingeben:
-
Die api-id Ihrer API.
-
Der definition oder der Inhalt Ihres Typs. Im Konsolenbeispiel war das:
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
-
Die format deiner Eingabe. In diesem Beispiel verwenden wirSDL.
Ein Beispielbefehl könnte so aussehen:
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "type Obj_Type_1{id: ID! title: String date: AWSDateTime}" --format SDL
Eine Ausgabe wird in der CLI zurückgegeben. Hier ein Beispiel:
{
"type": {
"definition": "type Obj_Type_1{id: ID! title: String date: AWSDateTime}",
"name": "Obj_Type_1",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/Obj_Type_1",
"format": "SDL"
}
}
In diesem Schritt haben wir einen generischen Objekttyp mit einem erforderlichen id Feld hinzugefügt, das als gespeichert istID, einem title Feld, das als gespeichert istString, und einem date Feld, das als gespeichert istAWSDateTime. Eine Liste der Typen und Felder und ihrer Funktionsweise finden Sie unter Schemas. Eine Liste der Skalare und ihrer Funktionsweise finden Sie unter Typenreferenz.
Außerdem haben Sie vielleicht bemerkt, dass die direkte Eingabe der Definition für kleinere Typen funktioniert, für das Hinzufügen größerer oder mehrerer Typen jedoch nicht möglich ist. Sie können sich dafür entscheiden, alles in einer .graphql Datei hinzuzufügen und es dann als Eingabe zu übergeben.
- CDK
-
Bevor Sie das CDK verwenden, empfehlen wir Ihnen, die offizielle Dokumentation des CDK zusammen mit der CDK-Referenz zu AWS AppSync lesen.
Die unten aufgeführten Schritte zeigen nur ein allgemeines Beispiel für das Snippet, das zum Hinzufügen einer bestimmten Ressource verwendet wurde. Dies soll keine funktionierende Lösung in Ihrem Produktionscode sein. Wir gehen auch davon aus, dass Sie bereits eine funktionierende App haben.
Um einen Typ hinzuzufügen, müssen Sie ihn zu Ihrer .graphql Datei hinzufügen. Das Konsolenbeispiel lautete zum Beispiel:
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
Sie können Ihre Typen wie jede andere Datei direkt zum Schema hinzufügen.
Um die an Ihrer GraphQL-API vorgenommenen Änderungen verwenden zu können, müssen Sie die App erneut bereitstellen.
Der Objekttyp hat Felder, bei denen es sich um skalare Typen wie Zeichenketten und Ganzzahlen handelt. AWS AppSync ermöglicht es Ihnen auch, erweiterte Skalartypen wie AWSDateTime zusätzlich zu den Basis-GraphQL-Skalaren zu verwenden. Außerdem ist jedes Feld, das mit einem Ausrufezeichen endet, erforderlich.
Insbesondere der ID skalare Typ ist ein eindeutiger Bezeichner, der entweder oder sein kann. String Int Sie können diese in Ihrem Resolver-Code für die automatische Zuweisung steuern.
Es gibt Ähnlichkeiten zwischen speziellen Objekttypen wie Query und „normalen“ Objekttypen wie dem obigen Beispiel, da sie beide das type Schlüsselwort verwenden und als Objekte betrachtet werden. Bei den speziellen Objekttypen (QueryMutation, undSubscription) unterscheidet sich ihr Verhalten jedoch erheblich, da sie als Einstiegspunkte für Ihre API bereitgestellt werden. Außerdem geht es bei ihnen eher um die Gestaltung von Vorgängen als um Daten. Weitere Informationen finden Sie unter Die Abfrage- und Mutationstypen.
Was spezielle Objekttypen angeht, könnte der nächste Schritt darin bestehen, einen oder mehrere von ihnen hinzuzufügen, um Operationen an den geformten Daten durchzuführen. In einem realen Szenario muss jedes GraphQL-Schema mindestens einen Root-Abfragetyp zum Anfordern von Daten haben. Sie können sich die Abfrage als einen der Einstiegspunkte (oder Endpunkte) für Ihren GraphQL-Server vorstellen. Fügen wir als Beispiel eine Abfrage hinzu.
- Console
-
-
Um eine Abfrage zu erstellen, können Sie sie einfach wie jeden anderen Typ zur Schemadatei hinzufügen. Eine Abfrage würde einen Query Typ und einen Eintrag im Stammverzeichnis wie folgt erfordern:
schema {
query: Name_of_Query
}
type Name_of_Query {
# Add field operation here
}
Beachten Sie, dass Name_of_Query in einer Produktionsumgebung Query in den meisten Fällen einfach aufgerufen wird. Wir empfehlen, diesen Wert beizubehalten. Innerhalb des Abfragetyps können Sie Felder hinzufügen. Jedes Feld führt eine Operation in der Anfrage aus. Infolgedessen werden die meisten, wenn nicht alle dieser Felder an einen Resolver angehängt. In diesem Abschnitt befassen wir uns jedoch nicht damit. In Bezug auf das Format der Feldoperation könnte es so aussehen:
Name_of_Query(params): Return_Type # version with params
Name_of_Query: Return_Type # version without params
Hier ein Beispiel:
schema {
query: Query
}
type Query {
getObj: [Obj_Type_1]
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
In diesem Schritt haben wir einen Query Typ hinzugefügt und ihn in unserem schema Stammverzeichnis definiert. Unser Query Typ hat ein getObj Feld definiert, das eine Liste von Obj_Type_1 Objekten zurückgibt. Beachten Sie, Obj_Type_1 dass dies das Objekt des vorherigen Schritts ist. Im Produktionscode arbeiten Ihre Außendienstmitarbeiter normalerweise mit Daten, die von Objekten wie geformt sindObj_Type_1. Darüber hinaus verfügen Felder wie getObj normalerweise über einen Resolver, der die Geschäftslogik ausführt. Das wird in einem anderen Abschnitt behandelt.
Als zusätzlicher Hinweis wird bei Exporten AWS AppSync automatisch ein Schema-Root hinzugefügt, sodass Sie es technisch gesehen nicht direkt zum Schema hinzufügen müssen. Unser Service verarbeitet automatisch doppelte Schemas. Wir fügen es hier als bewährte Methode hinzu.
- CLI
-
Wir empfehlen, zuerst die Konsolenversion zu lesen, falls Sie dies noch nicht getan haben.
-
Erstellen Sie ein schema Stammverzeichnis mit einer query Definition, indem create-typeSie den Befehl ausführen.
Für diesen speziellen Befehl müssen Sie einige Parameter eingeben:
-
Die api-id Ihrer API.
-
Der definition oder der Inhalt Ihres Typs. Im Konsolenbeispiel war das:
schema {
query: Query
}
-
Die format deiner Eingabe. In diesem Beispiel verwenden wirSDL.
Ein Beispielbefehl könnte so aussehen:
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "schema {query: Query}" --format SDL
Eine Ausgabe wird in der CLI zurückgegeben. Hier ein Beispiel:
{
"type": {
"definition": "schema {query: Query}",
"name": "schema",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/schema",
"format": "SDL"
}
}
Beachten Sie, dass Sie Ihren Schemastamm (oder einen beliebigen Typ im Schema) aktualisieren können, indem Sie den create-type Befehl ausführen, wenn Sie etwas nicht korrekt in den update-typeBefehl eingegeben haben. In diesem Beispiel ändern wir vorübergehend den Schemastamm, sodass er eine subscription Definition enthält.
Für diesen speziellen Befehl müssen Sie einige Parameter eingeben:
-
Die api-id Ihrer API.
-
Die type-name deines Typs. Im Konsolenbeispiel war dasschema.
-
Derdefinition, oder der Inhalt Ihres Typs. Im Konsolenbeispiel war das:
schema {
query: Query
}
Das Schema nach dem Hinzufügen von subscription sieht so aus:
schema {
query: Query
subscription: Subscription
}
-
Die format deiner Eingabe. In diesem Beispiel verwenden wirSDL.
Ein Beispielbefehl könnte so aussehen:
aws appsync update-type --api-id abcdefghijklmnopqrstuvwxyz --type-name schema --definition "schema {query: Query subscription: Subscription}" --format SDL
Eine Ausgabe wird in der CLI zurückgegeben. Hier ein Beispiel:
{
"type": {
"definition": "schema {query: Query subscription: Subscription}",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/schema",
"format": "SDL"
}
}
Das Hinzufügen vorformatierter Dateien funktioniert in diesem Beispiel weiterhin.
-
Erstellen Sie einen Query Typ, indem Sie den create-typeBefehl ausführen.
Für diesen speziellen Befehl müssen Sie einige Parameter eingeben:
-
Die api-id Ihrer API.
-
Der definition oder der Inhalt Ihres Typs. Im Konsolenbeispiel war das:
type Query {
getObj: [Obj_Type_1]
}
-
Die format deiner Eingabe. In diesem Beispiel verwenden wirSDL.
Ein Beispielbefehl könnte so aussehen:
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "type Query {getObj: [Obj_Type_1]}" --format SDL
Eine Ausgabe wird in der CLI zurückgegeben. Hier ein Beispiel:
{
"type": {
"definition": "Query {getObj: [Obj_Type_1]}",
"name": "Query",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/Query",
"format": "SDL"
}
}
In diesem Schritt haben wir einen Query Typ hinzugefügt und ihn in Ihrem schema Stammverzeichnis definiert. Unser Query Typ hat ein getObj Feld definiert, das eine Liste von Obj_Type_1 Objekten zurückgab.
Im schema Stammcode gibt der query: Teil anquery: Query, dass eine Abfrage in Ihrem Schema definiert wurde, während der Query Teil den tatsächlichen Namen des speziellen Objekts angibt.
- CDK
-
Bevor Sie das CDK verwenden, empfehlen wir, die offizielle Dokumentation des CDK zusammen mit der CDK-Referenz zu AWS AppSync lesen.
Die unten aufgeführten Schritte zeigen nur ein allgemeines Beispiel für das Snippet, das zum Hinzufügen einer bestimmten Ressource verwendet wurde. Dies soll keine funktionierende Lösung in Ihrem Produktionscode sein. Wir gehen auch davon aus, dass Sie bereits eine funktionierende App haben.
Sie müssen Ihre Abfrage und den Schemastamm zur .graphql Datei hinzufügen. Unser Beispiel sah wie das folgende Beispiel aus, aber Sie sollten es durch Ihren tatsächlichen Schemacode ersetzen:
schema {
query: Query
}
type Query {
getObj: [Obj_Type_1]
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
Sie können Ihre Typen wie jede andere Datei direkt zum Schema hinzufügen.
Die Aktualisierung des Schemastammes ist optional. Wir haben es als bewährte Methode zu diesem Beispiel hinzugefügt.
Um die an Ihrer GraphQL-API vorgenommenen Änderungen verwenden zu können, müssen Sie die App erneut bereitstellen.
Sie haben jetzt ein Beispiel für die Erstellung von Objekten und speziellen Objekten (Abfragen) gesehen. Sie haben auch gesehen, wie diese miteinander verbunden werden können, um Daten und Operationen zu beschreiben. Sie können Schemas verwenden, die nur die Datenbeschreibung und eine oder mehrere Abfragen enthalten. Wir möchten jedoch eine weitere Operation hinzufügen, um der Datenquelle Daten hinzuzufügen. Wir werden einen weiteren speziellen Objekttyp hinzufügenMutation, der Daten modifiziert.
- Console
-
-
Eine Mutation wird aufgerufenMutation. Die darin Mutation enthaltenen Feldoperationen beschreiben zum Beispiel Query eine Operation und werden an einen Resolver angehängt. Beachten Sie auch, dass wir es im schema Stammverzeichnis definieren müssen, da es sich um einen speziellen Objekttyp handelt. Hier ist ein Beispiel für eine Mutation:
schema {
mutation: Name_of_Mutation
}
type Name_of_Mutation {
# Add field operation here
}
Eine typische Mutation wird wie eine Abfrage im Stammverzeichnis aufgeführt. Die Mutation wird mit dem type Schlüsselwort zusammen mit dem Namen definiert. Name_of_Mutationwird normalerweise aufgerufenMutation, daher empfehlen wir, es so zu belassen. Jedes Feld führt auch eine Operation aus. In Bezug auf das Format der Feldoperation könnte es so aussehen:
Name_of_Mutation(params): Return_Type # version with params
Name_of_Mutation: Return_Type # version without params
Hier ein Beispiel:
schema {
query: Query
mutation: Mutation
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
type Query {
getObj: [Obj_Type_1]
}
type Mutation {
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
}
In diesem Schritt haben wir einen Mutation Typ mit einem addObj Feld hinzugefügt. Lassen Sie uns zusammenfassen, was dieses Feld tut:
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
addObjverwendet das Obj_Type_1 Objekt, um eine Operation auszuführen. Das liegt an den Feldern, aber die Syntax beweist dies im : Obj_Type_1 Rückgabetyp. addObjIm Inneren akzeptiert es die date Felder idtitle, und aus dem Obj_Type_1 Objekt als Parameter. Wie Sie vielleicht sehen, sieht es einer Methodendeklaration sehr ähnlich. Wir haben das Verhalten unserer Methode jedoch noch nicht beschrieben. Wie bereits erwähnt, dient das Schema nur dazu, zu definieren, wie die Daten und Operationen aussehen werden, und nicht, wie sie funktionieren. Die Implementierung der eigentlichen Geschäftslogik erfolgt später, wenn wir unsere ersten Resolver erstellen.
Sobald Sie mit Ihrem Schema fertig sind, besteht die Möglichkeit, es als schema.graphql Datei zu exportieren. Im Schema-Editor können Sie Schema exportieren wählen, um die Datei in einem unterstützten Format herunterzuladen.
Ein zusätzlicher Hinweis: Fügt bei Exporten AWS AppSync automatisch ein Schema-Root hinzu, sodass Sie es technisch gesehen nicht direkt zum Schema hinzufügen müssen. Unser Service verarbeitet automatisch doppelte Schemas. Wir fügen es hier als bewährte Methode hinzu.
- CLI
-
Wir empfehlen, zuerst die Konsolenversion zu lesen, falls Sie dies noch nicht getan haben.
-
Aktualisieren Sie Ihr Stammschema, indem Sie den update-typeBefehl ausführen.
Für diesen speziellen Befehl müssen Sie einige Parameter eingeben:
-
Die api-id Ihrer API.
-
Die type-name deines Typs. Im Konsolenbeispiel war dasschema.
-
Derdefinition, oder der Inhalt Ihres Typs. Im Konsolenbeispiel war das:
schema {
query: Query
mutation: Mutation
}
-
Die format deiner Eingabe. In diesem Beispiel verwenden wirSDL.
Ein Beispielbefehl könnte so aussehen:
aws appsync update-type --api-id abcdefghijklmnopqrstuvwxyz --type-name schema --definition "schema {query: Query mutation: Mutation}" --format SDL
Eine Ausgabe wird in der CLI zurückgegeben. Hier ein Beispiel:
{
"type": {
"definition": "schema {query: Query mutation: Mutation}",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/schema",
"format": "SDL"
}
}
-
Erstellen Sie einen Mutation Typ, indem Sie den create-typeBefehl ausführen.
Für diesen speziellen Befehl müssen Sie einige Parameter eingeben:
-
Die api-id Ihrer API.
-
Der definition oder der Inhalt Ihres Typs. Im Konsolenbeispiel war das
type Mutation {
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
}
-
Die format deiner Eingabe. In diesem Beispiel verwenden wirSDL.
Ein Beispielbefehl könnte so aussehen:
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "type Mutation {addObj(id: ID! title: String date: AWSDateTime): Obj_Type_1}" --format SDL
Eine Ausgabe wird in der CLI zurückgegeben. Hier ein Beispiel:
{
"type": {
"definition": "type Mutation {addObj(id: ID! title: String date: AWSDateTime): Obj_Type_1}",
"name": "Mutation",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/Mutation",
"format": "SDL"
}
}
- CDK
-
Bevor Sie das CDK verwenden, empfehlen wir, die offizielle Dokumentation des CDK zusammen mit der CDK-Referenz zu AWS AppSync lesen.
Die unten aufgeführten Schritte zeigen nur ein allgemeines Beispiel für das Snippet, das zum Hinzufügen einer bestimmten Ressource verwendet wurde. Dies soll keine funktionierende Lösung in Ihrem Produktionscode sein. Wir gehen auch davon aus, dass Sie bereits eine funktionierende App haben.
Sie müssen Ihre Abfrage und den Schemastamm zur .graphql Datei hinzufügen. Unser Beispiel sah wie das folgende Beispiel aus, aber Sie sollten es durch Ihren tatsächlichen Schemacode ersetzen:
schema {
query: Query
mutation: Mutation
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
type Query {
getObj: [Obj_Type_1]
}
type Mutation {
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
}
Das Aktualisieren des Schema-Stammverzeichnisses ist optional. Wir haben es als bewährte Methode zu diesem Beispiel hinzugefügt.
Um die an Ihrer GraphQL-API vorgenommenen Änderungen verwenden zu können, müssen Sie die App erneut bereitstellen.
Optionale Überlegungen — Verwendung von Enums als Status
Zu diesem Zeitpunkt wissen Sie, wie man ein grundlegendes Schema erstellt. Es gibt jedoch viele Dinge, die Sie hinzufügen könnten, um die Funktionalität des Schemas zu erhöhen. Eine häufig vorkommende Sache in Anwendungen ist die Verwendung von Enums als Status. Sie können eine Aufzählung verwenden, um zu erzwingen, dass beim Aufruf ein bestimmter Wert aus einer Menge von Werten ausgewählt wird. Das ist gut für Dinge, von denen Sie wissen, dass sie sich über lange Zeiträume nicht drastisch ändern werden. Hypothetisch gesehen könnten wir eine Aufzählung hinzufügen, die den Statuscode oder die Zeichenfolge in der Antwort zurückgibt.
Nehmen wir als Beispiel an, wir erstellen eine Social-Media-App, die die Beitragsdaten eines Benutzers im Backend speichert. Unser Schema enthält einen Post Typ, der die Daten eines einzelnen Beitrags darstellt:
type Post {
id: ID!
title: String
date: AWSDateTime
poststatus: PostStatus
}
Unser Post wird einen eindeutigen id Beitrag und eine title date Aufzählung mit dem Namen enthalten, PostStatus die den Status des Beitrags angibt, während er von der App verarbeitet wird. Für unseren Betrieb werden wir eine Abfrage haben, die alle Beitragsdaten zurückgibt:
type Query {
getPosts: [Post]
}
Wir werden auch eine Mutation haben, die Beiträge zur Datenquelle hinzufügt:
type Mutation {
addPost(id: ID!, title: String, date: AWSDateTime, poststatus: PostStatus): Post
}
Wenn wir uns unser Schema ansehen, könnte die PostStatus Aufzählung mehrere Status haben. Möglicherweise möchten wir, dass die drei grundlegenden Status success (Post erfolgreich verarbeitet), pending (Post wird verarbeitet) und error (Beitrag kann nicht verarbeitet werden) heißen. Um die Aufzählung hinzuzufügen, könnten wir Folgendes tun:
enum PostStatus {
success
pending
error
}
Das vollständige Schema könnte so aussehen:
schema {
query: Query
mutation: Mutation
}
type Post {
id: ID!
title: String
date: AWSDateTime
poststatus: PostStatus
}
type Mutation {
addPost(id: ID!, title: String, date: AWSDateTime, poststatus: PostStatus): Post
}
type Query {
getPosts: [Post]
}
enum PostStatus {
success
pending
error
}
Wenn ein Benutzer der Anwendung eine Post hinzufügt, wird die addPost Operation aufgerufen, um diese Daten zu verarbeiten. Während der damit verbundene Resolver die Daten addPost verarbeitet, aktualisiert er sie kontinuierlich poststatus mit dem Status des Vorgangs. Wenn sie abgefragt Post werden, enthält sie den endgültigen Status der Daten. Denken Sie daran, dass wir nur beschreiben, wie die Daten im Schema funktionieren sollen. Wir gehen von der Implementierung unserer Resolver (s) aus, die die eigentliche Geschäftslogik für die Verarbeitung der Daten zur Erfüllung der Anfrage implementieren.
Optionale Überlegungen — Abonnements
Abonnements in AWS AppSync werden als Reaktion auf eine Mutation aufgerufen. Diese werden mit einem Subscription-Typ und einer @aws_subscribe()-Anweisung im Schema konfiguriert, um anzugeben, welche Mutationen ein oder mehrere Abonnements aufrufen. Weitere Informationen zur Konfiguration von Abonnements finden Sie unter Echtzeitdaten.
Optionale Überlegungen — Beziehungen und Seitennummerierung
Angenommen, Sie haben eine Million in einer DynamoDB-Tabelle Posts gespeichert und möchten einige dieser Daten zurückgeben. Die oben angegebene Beispielabfrage gibt jedoch nur alle Beiträge zurück. Sie möchten nicht jedes Mal, wenn Sie eine Anfrage stellen, alle abrufen. Stattdessen würden Sie sie paginieren wollen. Nehmen Sie dazu die folgenden Änderungen an Ihrem Schema vor:
-
Fügen Sie im getPosts Feld zwei Eingabeargumente hinzu: nextToken (Iterator) und limit (Iterationslimit).
-
Fügen Sie einen neuen PostIterator Typ hinzu, der Posts Felder (ruft die Post Objektliste ab) und nextToken (Iterator) enthält.
-
Ändern Sie es getPosts so, dass es zurückgegeben wird PostIterator und keine Liste von Post Objekten.
schema {
query: Query
mutation: Mutation
}
type Post {
id: ID!
title: String
date: AWSDateTime
poststatus: PostStatus
}
type Mutation {
addPost(id: ID!, title: String, date: AWSDateTime, poststatus: PostStatus): Post
}
type Query {
getPosts(limit: Int, nextToken: String): PostIterator
}
enum PostStatus {
success
pending
error
}
type PostIterator {
posts: [Post]
nextToken: String
}
Der PostIterator Typ ermöglicht es Ihnen, einen Teil der Post Objektliste zurückzugeben und einen, nextToken um den nächsten Teil abzurufen. Darin befindet PostIterator sich eine Liste von Post Elementen ([Post]), die mit einem Paginierungstoken (nextToken) zurückgegeben wird. AWS AppSyncIn würde dies über einen Resolver mit Amazon DynamoDB verbunden und automatisch als verschlüsseltes Token generiert. Dadurch wird der Wert des Arguments limit in den Parameter maxResults und des Arguments nextToken in den Parameter exclusiveStartKey konvertiert. Beispiele und die integrierten Vorlagenbeispiele in der AWS AppSync Konsole finden Sie unter Resolver-Referenz (). JavaScript