Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
So funktionieren Amazon Bedrock-Wissensdatenbanken
Amazon Bedrock Knowledge Bases helfen Ihnen dabei, die Vorteile von Retrieval Augmented Generation (RAG) zu nutzen, einer beliebten Technik, bei der Informationen aus einem Datenspeicher abgerufen werden, um die von Large Language Models () generierten Antworten zu erweitern. LLMs Wenn Sie mit Ihrer Datenquelle eine Wissensdatenbank einrichten, kann Ihre Anwendung die Wissensdatenbank abfragen, um Informationen zur Beantwortung der Anfrage zurückzugeben, entweder mit direkten Zitaten aus Quellen oder mit natürlichen Antworten, die aus den Abfrageergebnissen generiert werden.
Mit Amazon Bedrock Knowledge Bases können Sie Anwendungen erstellen, die durch den Kontext bereichert werden, der bei der Abfrage einer Wissensdatenbank entsteht. Es ermöglicht eine schnellere Markteinführung, da es von der aufwändigen Erstellung von Pipelines absieht und Ihnen eine out-of-the-box RAG-Lösung zur Verfügung stellt, mit der Sie die Erstellungszeit für Ihre Anwendung reduzieren können. Durch Hinzufügen einer Wissensdatenbank steigt auch die Kosteneffizienz, da Ihr Modell nicht kontinuierlich trainiert werden muss, um Ihre privaten Daten nutzen zu können.
Die folgenden Diagramme sind eine schematische Darstellung von RAG. Die Wissensdatenbank vereinfacht die Einrichtung und Implementierung von RAG, indem mehrere Schritte dieses Prozesses automatisiert werden.
Vorverarbeitung unstrukturierter Daten
Um einen effektiven Abruf aus unstrukturierten privaten Daten (Daten, die nicht in einem strukturierten Datenspeicher vorhanden sind) zu ermöglichen, besteht eine gängige Praxis darin, die Daten in Text umzuwandeln und in verwaltbare Teile aufzuteilen. Die Teile oder Blöcke werden dann in Einbettungen umgewandelt und in einen Vektorindex geschrieben, wobei die Zuordnung zum Originaldokument beibehalten wird. Diese Einbettungen werden verwendet, um die semantische Ähnlichkeit zwischen Abfragen und Text aus den Datenquellen zu ermitteln. Die folgende Abbildung veranschaulicht die Vorverarbeitung von Daten für die Vektordatenbank.
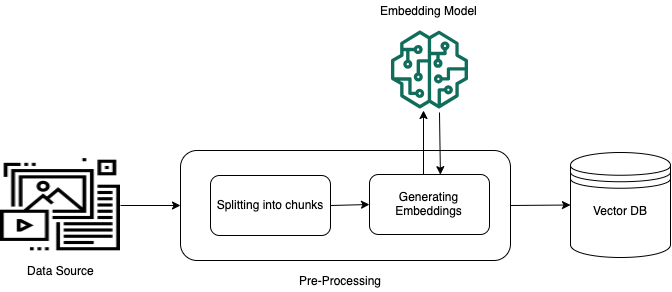
Bei Vektoreinbettungen handelt es sich um eine Reihe von Zahlen, die für jeden Textabschnitt stehen. Ein Modell wandelt jeden Textblock in eine Reihe von Zahlen um, die als Vektoren bezeichnet werden, sodass die Texte mathematisch verglichen werden können. Bei diesen Vektoren kann es sich entweder um Gleitkommazahlen (Float32) oder um Binärzahlen handeln. Die meisten von Amazon Bedrock unterstützten Einbettungsmodelle verwenden standardmäßig Gleitkomma-Vektoren. Einige Modelle unterstützen jedoch binäre Vektoren. Wenn Sie ein binäres Einbettungsmodell wählen, müssen Sie auch ein Modell und einen Vektorspeicher wählen, die binäre Vektoren unterstützen.
Binäre Vektoren, die nur 1 Bit pro Dimension verwenden, sind nicht so speicherintensiv wie Gleitkomma-Vektoren (float32), die 32 Bit pro Dimension verwenden. Binäre Vektoren sind jedoch in ihrer Darstellung des Textes nicht so präzise wie Fließkommavektoren.
Das folgende Beispiel zeigt einen Text in drei Darstellungen:
| Darstellung | Wert |
|---|---|
| Text | „Amazon Bedrock verwendet leistungsstarke Basismodelle von führenden KI-Unternehmen und Amazon.“ |
| Gleitkomma-Vektor | [0.041..., 0.056..., -0.018..., -0.012..., -0.020...,
...] |
| Binärer Vektor | [1,1,0,0,0, ...] |
Ausführung zur Laufzeit
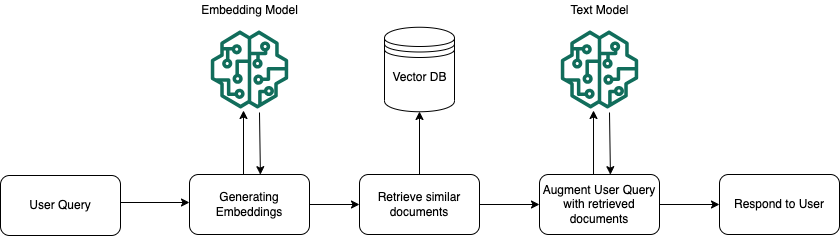
Zur Laufzeit wird ein Einbettungsmodell verwendet, um die Benutzerabfrage in einen Vektor zu konvertieren. Anschließend wird der Vektorindex abgefragt, um Blöcke zu finden, die der Benutzerabfrage ähneln, indem Dokumentvektoren mit dem Benutzerabfragevektor verglichen werden. Im letzten Schritt wird die Benutzereingabe mit zusätzlichem Kontext aus den Blöcken erweitert, die aus dem Vektorindex abgerufen werden. Die Eingabeaufforderung wird dann mit dem zusätzlichen Kontext an das Modell gesendet, um eine Antwort für den/die Benutzer:in zu generieren. Die folgende Abbildung zeigt, wie RAG zur Laufzeit arbeitet, um die Antworten auf Benutzerabfragen zu verbessern.
Weitere Informationen darüber, wie Sie Ihre Daten in eine Wissensdatenbank umwandeln, wie Sie Ihre Wissensdatenbank abfragen, nachdem Sie sie eingerichtet haben, und Anpassungen, die Sie während der Aufnahme auf die Datenquelle anwenden können, finden Sie in den folgenden Themen:
Themen
