Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
So konfigurieren Sie Abfragen und die Antwortgenerierung und passen diese an
Sie können den Abruf und die Generierung von Antworten konfigurieren und anpassen und so die Relevanz der Antworten weiter verbessern. Sie können beispielsweise Filter auf Dokumentmetadaten anwenden, fields/attributes um die zuletzt aktualisierten Dokumente oder Dokumente mit den letzten Änderungszeiten zu verwenden.
Anmerkung
Alle folgenden Konfigurationen, mit Ausnahme von Orchestrierung und Generierung sind nur auf unstrukturierte Datenquellen anwendbar.
Wählen Sie eines der folgenden Themen aus, um mehr über diese Konfigurationen in der Konsole oder API zu erfahren:
Wenn Sie eine Wissensdatenbank abfragen, gibt Amazon Bedrock standardmäßig bis zu fünf Ergebnisse in der Antwort zurück. Jedes Ergebnis entspricht einem Quellblock.
Anmerkung
Die tatsächliche Anzahl der Ergebnisse in der Antwort kann unter dem angegebenen numberOfResults-Wert liegen, da dieser Parameter die maximale Anzahl der zurückzugebenden Ergebnisse festlegt. Wenn Sie hierarchisches Chunking für Ihre Chunking-Strategie konfiguriert haben, entspricht der Parameter numberOfResults der Anzahl der untergeordneten Blöcke, die die Wissensdatenbank abrufen wird. Da untergeordnete Blöcke, die denselben übergeordneten Block teilen, in der endgültigen Antwort durch den übergeordneten Block ersetzt werden, kann die Anzahl der zurückgegebenen Ergebnisse geringer sein als die angeforderte Menge.
Wählen Sie die Registerkarte mit Ihrer bevorzugten Methode aus und gehen Sie dann wie folgt vor, um die maximale Anzahl zurückzugebender Ergebnisse zu modifizieren:
Der Suchtyp definiert, wie Datenquellen in der Wissensdatenbank abgefragt werden. Mögliche Suchtypen:
Anmerkung
Die Hybridsuche wird nur für Amazon RDS-, Amazon OpenSearch Serverless- und MongoDB-Vektorspeicher unterstützt, die ein filterbares Textfeld enthalten. Wenn Sie einen anderen Vektorspeicher verwenden oder Ihr Vektorspeicher kein filterbares Textfeld enthält, verwendet die Abfrage eine semantische Suche.
-
Standard – Amazon Bedrock wählt die Suchstrategie für Sie aus.
-
Hybrid – Hier werden Vektoreinbettungen (semantische Suche) in Kombination mit Rohtext durchsucht.
-
Semantisch – Durchsucht ausschließlich Vektoreinbettungen.
Wählen Sie die Registerkarte mit Ihrer bevorzugten Methode aus und führen Sie dann die Schritte aus, um zu erfahren, wie Sie den Suchtyp definieren:
Sie können Filter auf Dokumente anwenden fields/attributes , um die Relevanz der Antworten weiter zu verbessern. Ihre Datenquellen können Dokumentmetadaten enthalten attributes/fields , nach denen gefiltert werden kann, und Sie können angeben, welche Felder in die Einbettungen aufgenommen werden sollen.
Überlegungen zur verwalteten Wissensdatenbank
Wenn Sie die Metadatenfilterung mit einer verwalteten Wissensdatenbank verwenden:
-
Die Filter
startsWithundstringContainsMetadaten werden nicht unterstützt. Verwenden SieequalsstattdessengreaterThandienotInOperatorenlessThanin,,, oder. -
Für benutzerdefinierte Wissensdatenbanken
x-amz-bedrocksind Metadatenfelder mit einem Präfix vom Dienst reserviert. Bei vollständig verwalteten Wissensdatenbanken verwenden reservierte Metadatenfelder ein Unterstrich-Präfix (z. B._source_uri,_data_source_id). Sie können reservierte Metadatenfelder in keinem der beiden Wissensdatenbanktypen überschreiben.
Beispielsweise steht „epoch_modification_time“ für die Zeit in Sekunden seit dem 1. Januar 1970 (UTC), als das Dokument zuletzt aktualisiert wurde. Sie können nach den neuesten Daten filtern, wobei „epoch_modification_time“ größer als eine bestimmte Zahl ist. Diese neuesten Dokumente können für die Abfrage verwendet werden.
Überprüfen Sie, ob Ihre Wissensdatenbank die folgenden Anforderungen erfüllt, um bei der Abfrage einer Wissensdatenbank Filter zu verwenden:
-
Bei der Konfiguration Ihres Datenquellen-Connectors crawlen die meisten Connectors durch die wichtigsten Metadatenfelder Ihrer Dokumente. Wenn Sie einen Amazon-S3-Bucket als Datenquelle verwenden, muss der Bucket mindestens einen
fileName.extension.metadata.jsonenthalten, der der jeweiligen Datei oder dem Dokument zugeordnet ist. Weitere Informationen zur Konfiguration der Metadatendatei finden Sie in Konfiguration der Verbindung unter Dokumentmetadatenfelder. -
Wenn sich der Vektorindex Ihrer Wissensdatenbank in einem Amazon OpenSearch Serverless Vector Store befindet, überprüfen Sie, ob der Vektorindex mit der
faissEngine konfiguriert ist. Wenn der Vektorindex mit dernmslib-Engine konfiguriert ist, müssen Sie einen der folgenden Prozesse ausführen:-
Erstellen Sie eine neue Wissensdatenbank in der Konsole und lassen Sie Amazon Bedrock automatisch einen Vektorindex in Amazon OpenSearch Serverless für Sie erstellen.
-
Erstellen Sie einen weiteren Vektorindex im Vektorspeicher und wählen Sie
faissals Engine aus. Anschließend erstellen Sie eine neue Wissensdatenbank und geben den neuen Vektorindex an.
-
-
Wenn Ihre Wissensdatenbank einen Vektorindex in einem S3-Vektor-Bucket verwendet, können Sie die Filter
stringContainsundstartsWithnicht verwenden. -
Wenn Sie Metadaten zu einem bestehenden Vektorindex in einem Datenbank-Cluster unter Amazon Aurora hinzufügen, empfehlen wir, den Feldnamen der benutzerdefinierten Metadatenspalte anzugeben, um alle Ihre Metadaten in einer einzigen Spalte zu speichern. Diese Spalte wird während der Datenerfassung mit allen in den Metadatendateien enthaltenen Informationen aus Ihren Datenquellen gefüllt. Wenn Sie entscheiden, dieses Feld anzugeben, müssen Sie einen Index für diese Spalte erstellen.
-
Wenn Sie in der Konsole eine neue Wissensdatenbank erstellen und Amazon Bedrock Ihre Amazon-Aurora-Datenbank konfigurieren lassen, wird automatisch eine einzelne Spalte erstellt und mit den Informationen aus Ihren Metadatendateien befüllt.
-
Wenn Sie entscheiden, einen weiteren Vektorindex im Vektorspeicher zu erstellen, müssen Sie den Namen des benutzerdefinierten Metadatenfeldes angeben, um Informationen aus Ihren Metadatendateien zu speichern. Wenn Sie diesen Feldnamen nicht angeben, müssen Sie für jedes Metadatenattribut in Ihren Dateien eine Spalte erstellen und den Datentyp (Text, Zahl oder boolescher Wert) angeben. Wenn das Attribut
genrebeispielsweise in Ihrer Datenquelle vorhanden ist, würden Sie eine Spalte mit dem Namengenreund der Angabetextals Datentyp hinzufügen. Während der Aufnahme werden diese separaten Spalten mit den entsprechenden Attributwerten gefüllt.
-
Wenn Sie PDF-Dokumente in Ihrer Datenquelle haben und Amazon OpenSearch Serverless oder Amazon Aurora für Ihren Vector Store verwenden: Amazon Bedrock-Wissensdatenbanken generieren Seitenzahlen von Dokumenten und speichern sie in Metadaten field/attribute namens x-amz-bedrock-kb-document-page-number. Beachten Sie, dass Seitenzahlen, die in einem Metadatenfeld gespeichert sind, nicht unterstützt werden, wenn Sie für Ihre Dokumente kein Chunking auswählen.
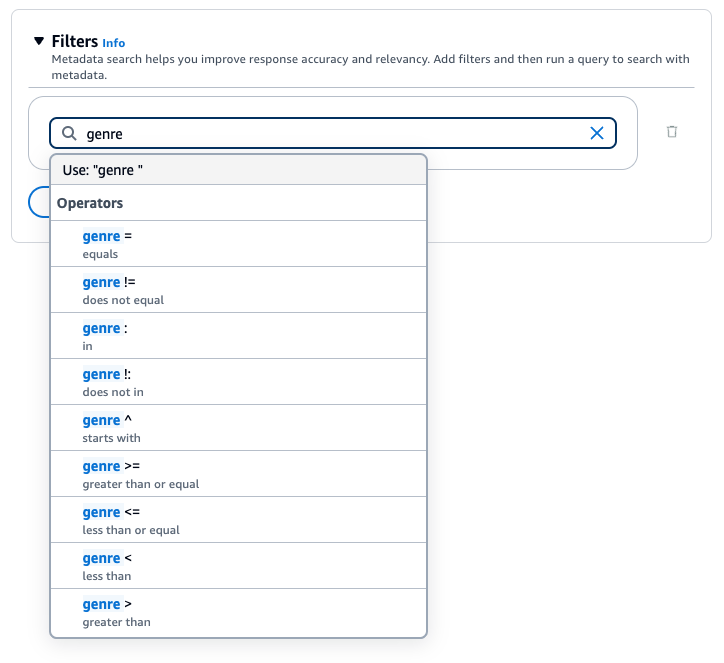
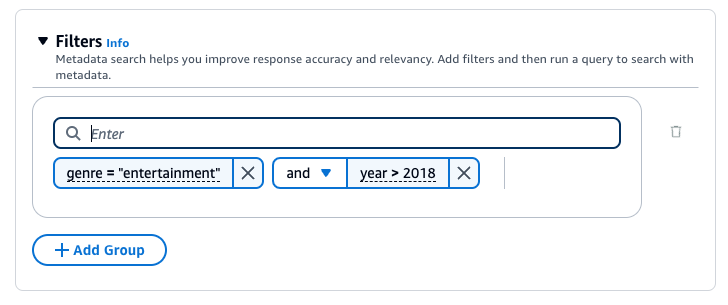
Sie können die folgenden Filteroperatoren verwenden, um bei der Abfrage die Ergebnisse zu filtern:
| Operator | Konsole | API-Filtername | Unterstützte Attributdatentypen | Gefilterte Ergebnisse |
|---|---|---|---|---|
| Gleich | = | equals | Zeichenfolge, Zahl, boolescher Wert | Das Attribut entspricht dem von Ihnen angegebenen Wert |
| Ungleich | != | notEquals | Zeichenfolge, Zahl, boolescher Wert | Das Attribut entspricht nicht dem von Ihnen angegebenen Wert |
| Größer als | > | Größer als | number | Das Attribut ist größer als der von Ihnen angegebene Wert |
| Größer als oder gleich | >= | größer ThanOrEquals | number | Das Attribut ist größer als oder gleich dem von Ihnen angegebenen Wert |
| Kleiner als | < | weniger als | number | Das Attribut ist kleiner als der von Ihnen angegebene Wert |
| Kleiner als oder gleich | <= | weniger ThanOrEquals | number | Das Attribut ist kleiner als der oder gleich dem von Ihnen angegebenen Wert |
| In | : | in | Zeichenfolgenliste | Das Attribut befindet sich in der von Ihnen bereitgestellten Liste (wird derzeit am besten von Amazon OpenSearch Serverless und Neptune Analytics GraphRag Vector Stores unterstützt) |
| NOT IN | !: | Nicht eingeschrieben | Zeichenfolgenliste | Das Attribut ist nicht in der von Ihnen angegebenen Liste enthalten (wird derzeit am besten von Amazon OpenSearch Serverless und Neptune Analytics GraphRag Vector Stores unterstützt) |
| Zeichenfolge enthält | Nicht verfügbar | stringContains | Zeichenfolge | Das Attribut muss eine Zeichenfolge sein. Der Attributname entspricht dem Schlüssel und dessen Wert ist eine Zeichenfolge, die den Wert enthält, den Sie als Teilzeichenfolge angegeben haben, oder eine Liste mit einem Mitglied, das den Wert enthält, den Sie als Teilzeichenfolge angegeben haben (derzeit am besten unterstützt mit Amazon OpenSearch Serverless Vector Store). Der GraphRag-Vektorspeicher von Neptune Analytics unterstützt die String-Variante, aber nicht die Listenvariante dieses Filters). |
| Liste enthält | Nicht verfügbar | listContains | Zeichenfolge | Das Attribut muss eine Zeichenfolgenliste sein. Der Attributname entspricht dem Schlüssel und dessen Wert ist eine Liste, die den Wert enthält, den Sie als eines seiner Mitglieder angegeben haben (derzeit am besten mit Amazon OpenSearch Serverless Vector Stores unterstützt). |
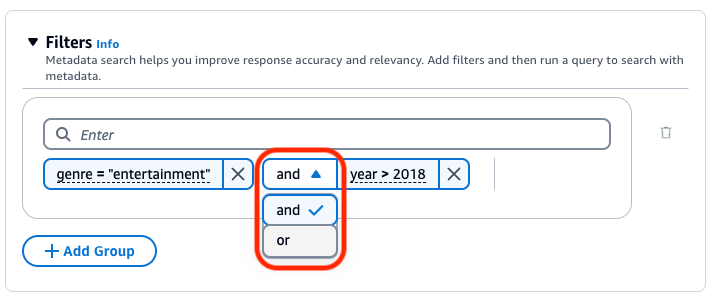
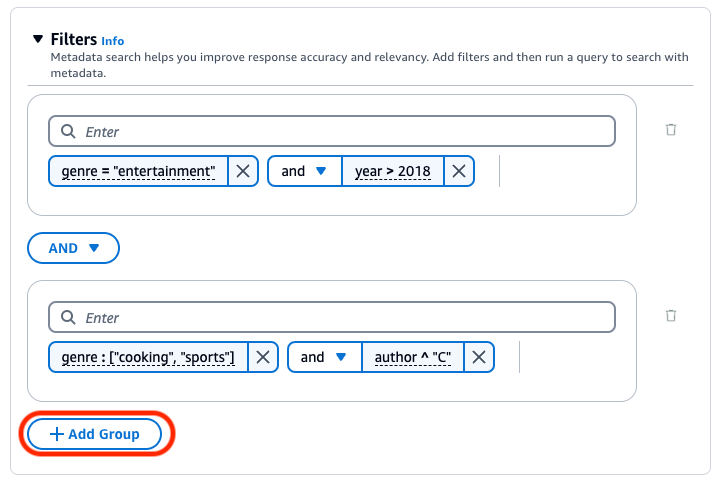
Sie können die folgenden logischen Operatoren verwenden, um Filteroperatoren zu kombinieren:
Wählen Sie den Tab für Ihre bevorzugte Methode aus und führen Sie dann die Schritte aus, um zu erfahren, wie Sie Ergebnisse mithilfe von Metadaten filtern:
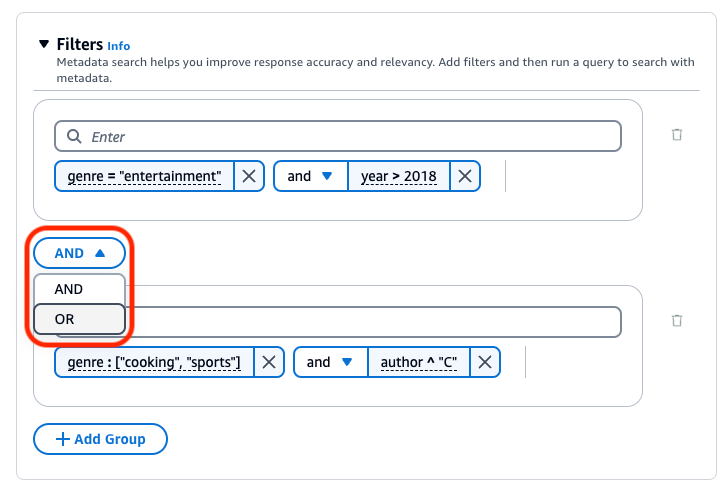
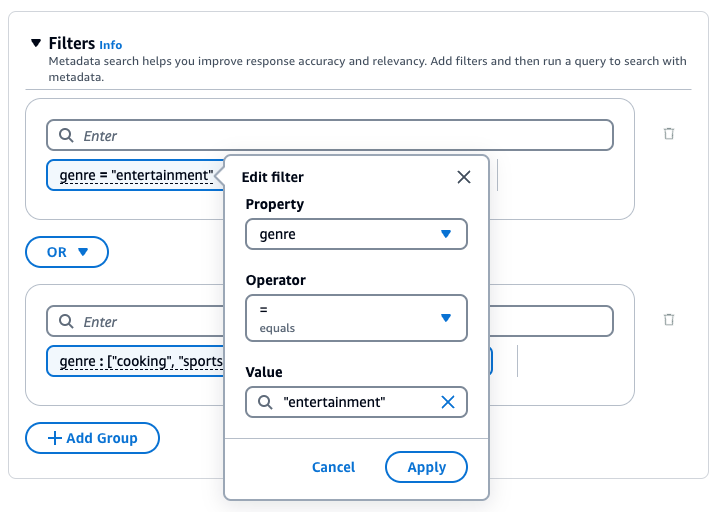
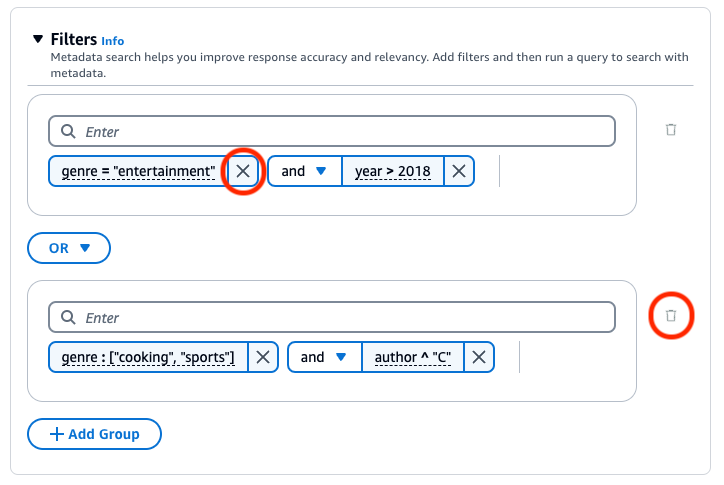
Amazon Bedrock Knowledge Base generiert einen Abruffilter und wendet diesen anhand der Benutzerabfrage und eines Metadatenschemas an.
Anmerkung
Die implizite Metadatenfilterung wird von Anthropic Claude Modellen unterstützt. Weitere Informationen zu unterstützten Modellen finden Sie unter Modelle auf einen Blick.
Die implicitFilterConfiguration ist im Hauptteil der vectorSearchConfiguration in der Retrieve-Anfrage angegeben. Schließen Sie die folgenden Felder mit ein:
-
metadataAttributes– Geben Sie in diesem Array Schemas an, die Metadatenattribute beschreiben, für die das Modell einen Filter generiert. -
modelArn– Der ARN des zu verwendenden Modells.
Im Folgenden wird ein Beispiel für Metadatenschemas gezeigt, die Sie dem Array unter metadataAttributes hinzufügen können.
[ { "key": "company", "type": "STRING", "description": "The full name of the company. E.g. `Amazon.com, Inc.`, `Alphabet Inc.`, etc" }, { "key": "ticker", "type": "STRING", "description": "The ticker name of a company in the stock market, e.g. AMZN, AAPL" }, { "key": "pe_ratio", "type": "NUMBER", "description": "The price to earning ratio of the company. This is a measure of valuation of a company. The lower the pe ratio, the company stock is considered chearper." }, { "key": "is_us_company", "type": "BOOLEAN", "description": "Indicates whether the company is a US company." }, { "key": "tags", "type": "STRING_LIST", "description": "Tags of the company, indicating its main business. E.g. `E-commerce`, `Search engine`, `Artificial intelligence`, `Cloud computing`, etc" } ]
Sie können für Ihre Wissensdatenbank Schutzmaßnahmen für Ihre Anwendungsfälle und verantwortungsvolle KI-Richtlinien implementieren. Sie können mehrere Integritätsschutzmaßnahmen treffen, die auf verschiedene Anwendungsfälle zugeschnitten sind, und sie auf mehrere Anfrage- und Antwortbedingungen anwenden, um eine konsistente Benutzerumgebung zu gewährleisten und die Sicherheitskontrollen in Ihrer gesamten Wissensdatenbank zu standardisieren. Sie können abgelehnte Themen so konfigurieren, dass unerwünschte Themen und Inhaltsfilter schädliche Inhalte in Modelleingaben und -antworten blockieren. Weitere Informationen finden Sie unter So erkennen und filtern Sie schädliche Inhalte mithilfe vom Integritätsschutz für Amazon Bedrock.
Anmerkung
Die Verwendung eines Integritätsschutzes mit kontextueller Begründungsprüfung für Wissensdatenbanken wird aktuell in Claude 3 Sonnet und Haiku nicht unterstützt.
Allgemeine Leitfäden zum Prompt-Engineering finden Sie unter Prompt-Engineering-Konzepte.
Wählen Sie die Registerkarte für Ihre bevorzugte Methode aus und befolgen Sie die angegebenen Schritte:
Sie können ein Reranker-Modell verwenden, um Ergebnisse aus einer Wissensdatenbankabfrage neu einzustufen. Folgen Sie den Konsolenschritten unter Abrufen einer Wissensdatenbank und Datenabruf oder So fragen Sie eine Wissensdatenbank ab und generieren Antworten auf Grundlage der abgerufenen Daten. Wenn Sie den Bereich Konfigurationen öffnen, erweitern Sie den Abschnitt Neueinstufung. Wählen Sie ein Reranker-Modell aus, aktualisieren Sie die Berechtigungen falls erforderlich und modifizieren Sie bei Bedarf weitere Optionen. Geben Sie einen Prompt ein und klicken Sie auf Ausführen, um die Ergebnisse nach der Neueinstufung zu testen.
Die Abfragezerlegung wird verwendet, um komplexe Abfragen in kleinere, einfacher zu handhabende Unterabfragen aufzuteilen. Dieser Ansatz kann dabei helfen, genauere und relevantere Informationen abzurufen – insbesondere dann, wenn die ursprüngliche Abfrage vielschichtig oder zu allgemein formuliert ist. Die Aktivierung dieser Option kann dazu führen, dass mehrere Abfragen in Ihrer Wissensdatenbank ausgeführt werden, was zu einer genaueren endgültigen Antwort beitragen kann.
Zum Beispiel für eine Frage wie „Wer hat bei der FIFA-Weltmeisterschaft 2022 besser abgeschnitten, Argentinien oder Frankreich?“ , Amazon Bedrock Knowledge Bases können zunächst die folgenden Unterabfragen generieren, bevor eine endgültige Antwort generiert wird:
-
Wie viele Tore hat Argentinien im Finale der FIFA-Weltmeisterschaft 2022 geschossen?
-
Wie viele Tore hat Frankreich im Finale der FIFA-Weltmeisterschaft 2022 geschossen?
Beim Generieren von Antworten auf Grundlage abgerufener Informationen können Sie Inferenzparameter verwenden, um mehr Kontrolle über das Verhalten des Modells während der Inferenz zu erhalten und dessen Ausgaben gezielt zu beeinflussen.
Wählen Sie den Tab für Ihre bevorzugte Methode aus und führen Sie dann die Schritte aus, um zu erfahren, wie Sie die Inferenzparameter modifizieren können:
Wenn Sie eine Wissensdatenbank abfragen und die Generierung einer Antwort anfordern, verwendet Amazon Bedrock eine Prompt-Vorlage, die Anweisungen und Kontext mit der Benutzerabfrage kombiniert, um den Prompt zur Generierung zu erstellen, der an das Modell zur Antworterstellung gesendet wird. Sie können auch den Orchestrierungs-Prompt anpassen, der den Benutzer-Prompt in eine Suchabfrage umwandelt. Sie können die Prompt-Vorlagen mit den folgenden Tools gestalten:
-
Platzhalter für Eingabeaufforderungen — Pre-defined Variablen in Amazon Bedrock Knowledge Bases, die während der Wissensdatenbank-Abfrage zur Laufzeit dynamisch ausgefüllt werden. Im System-Prompt sehen Sie diese Platzhalter, die von dem Symbol
$umgeben sind. In der folgenden Liste werden die Platzhalter beschrieben, die Sie verwenden können:Anmerkung
Der Platzhalter
$output_format_instructions$ist ein Pflichtfeld, damit Zitate in der Antwort angezeigt werden können.Variable Prompt-Vorlage Ersetzt durch Modell Erforderlich? $query$ Orchestrierung, Generierung Die an die Wissensdatenbank gesendete Benutzerabfrage. Anthropic Claude Instant, Anthropic Claude v2.x Ja Anthropic Claude 3 Sonnet Nein (automatisch in der Modelleingabe enthalten) $search_results$ Generation Die für die Benutzerabfrage abgerufenen Ergebnisse. Alle Ja $output_format_instructions$ Orchestrierung Zugrunde liegende Anweisungen zur Formatierung der Antwortgenerierung und der Zitate. Unterscheidet sich je nach Modell. Wenn Sie Ihre eigenen Formatierungsanweisungen definieren, empfehlen wir Ihnen, diesen Platzhalter zu entfernen. Ohne diesen Platzhalter enthält die Antwort keine Zitate. Alle Ja $current_time$ Orchestrierung, Generierung Die aktuelle Uhrzeit. Alle Nein -
XML-Tags – Anthropic-Modelle unterstützen die Verwendung von XML-Tags zur Strukturierung und Abgrenzung Ihrer Prompts. Verwenden Sie aussagekräftige Tag-Namen, um optimale Ergebnisse zu erzielen. Beispielsweise sehen Sie im Standardsystem-Prompt das
<database>-Tag, das verwendet wird, um eine Datenbank zuvor gestellter Fragen abzugrenzen. Weitere Informationen finden Sie im Anthropic-Benutzerhandbuchunter Verwenden von XML-Tags .
Allgemeine Leitfäden zum Prompt-Engineering finden Sie unter Prompt-Engineering-Konzepte.
Anmerkung
Wenn Sie keine Vorlage für benutzerdefinierte Eingabeaufforderungen bereitstellen, verwendet Amazon Bedrock eine Standard-Systemaufforderung, die allgemeine Beispielinhalte (wie Beispielfragen und Antworten zu nicht verwandten Themen) enthält, um die Formatierung der Antworten des Modells zu steuern. Diese Standardaufforderung ist in den Aufrufprotokollen des Modells sichtbar. Der Beispielinhalt in der Standard-Eingabeaufforderung stammt nicht aus den Daten anderer Kunden — es handelt sich um eine statische Vorlage, die von Amazon Bedrock bereitgestellt wird. Sie können die Standard-Eingabeaufforderung überschreiben, indem Sie Ihre eigene textPromptTemplate angeben.
Wählen Sie die Registerkarte für Ihre bevorzugte Methode aus und befolgen Sie dann die Schritte:
