Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
AWS-Reinräume ML
Mit AWS Clean Rooms ML können zwei oder mehr Parteien Modelle für maschinelles Lernen auf ihren Daten ausführen, ohne ihre Daten miteinander teilen zu müssen. Der Service bietet Kontrollen zur Verbesserung des Datenschutzes, mit denen Dateneigentümer ihre Daten und ihre Modell-IP schützen können. Sie können von Hand AWS erstellte Modelle verwenden oder Ihr eigenes benutzerdefiniertes Modell mitbringen.
Eine detailliertere Erklärung, wie das funktioniert, finden Sie unter. Cross-account Jobs
Weitere Informationen zu den Funktionen von Clean Rooms ML-Modellen finden Sie in den folgenden Themen.
Topics
ML-Terminologie von AWS Clean Rooms
Bei der Verwendung von Clean Rooms ML ist es wichtig, die folgende Terminologie zu verstehen:
-
Anbieter von Trainingsdaten — Die Partei, die die Trainingsdaten bereitstellt, ein Lookalike-Modell erstellt und konfiguriert und dieses Lookalike-Modell dann einer Zusammenarbeit zuordnet.
-
Seed-Datenanbieter — Die Partei, die die Ausgangsdaten bereitstellt, generiert ein Lookalike-Segment und exportiert ihr Lookalike-Segment.
-
Trainingsdaten — Die Daten des Trainingsdatenanbieters, die zur Generierung eines Lookalike-Modells verwendet werden. Die Trainingsdaten werden verwendet, um die Ähnlichkeit des Benutzerverhaltens zu messen.
Die Trainingsdaten müssen eine Benutzer-ID, eine Element-ID und eine Zeitstempelspalte enthalten. Optional können die Trainingsdaten auch andere Interaktionen als numerische oder kategoriale Merkmale enthalten. Beispiele für Interaktionen sind eine Liste von angesehenen Videos, gekauften Artikeln oder gelesenen Artikeln.
-
Seed-Daten — Die Daten des Seed-Datenanbieters, die zur Erstellung eines Lookalike-Segments verwendet werden. Die Ausgangsdaten können direkt bereitgestellt werden oder aus den Ergebnissen einer AWS Clean Rooms Abfrage stammen. Bei der Ausgabe des Lookalike-Segments handelt es sich um eine Gruppe von Benutzern aus den Trainingsdaten, die den Ausgangsbenutzern am ähnlichsten sind.
-
Lookalike-Modell — Ein maschinelles Lernmodell der Trainingsdaten, das verwendet wird, um ähnliche Benutzer in anderen Datensätzen zu finden.
Bei der Verwendung der API wird der Begriff Zielgruppenmodell gleichwertig mit dem Lookalike-Modell verwendet. Beispielsweise verwenden Sie die CreateAudienceModelAPI, um ein Lookalike-Modell zu erstellen.
-
Lookalike-Segment — Eine Teilmenge der Trainingsdaten, die den Ausgangsdaten am ähnlichsten ist.
Wenn Sie die API verwenden, erstellen Sie mit der API ein Lookalike-Segment. StartAudienceGenerationJob
Die Daten des Trainingsdatenanbieters werden niemals mit dem Startdatenanbieter geteilt, und die Daten des Ausgangsdatenanbieters werden niemals mit dem Trainingsdatenanbieter geteilt. Die Ausgabe des Lookalike-Segments wird mit dem Trainingsdatenanbieter geteilt, aber niemals mit dem Seed-Datenanbieter.
So funktioniert AWS Clean Rooms ML mit AWS Modellen
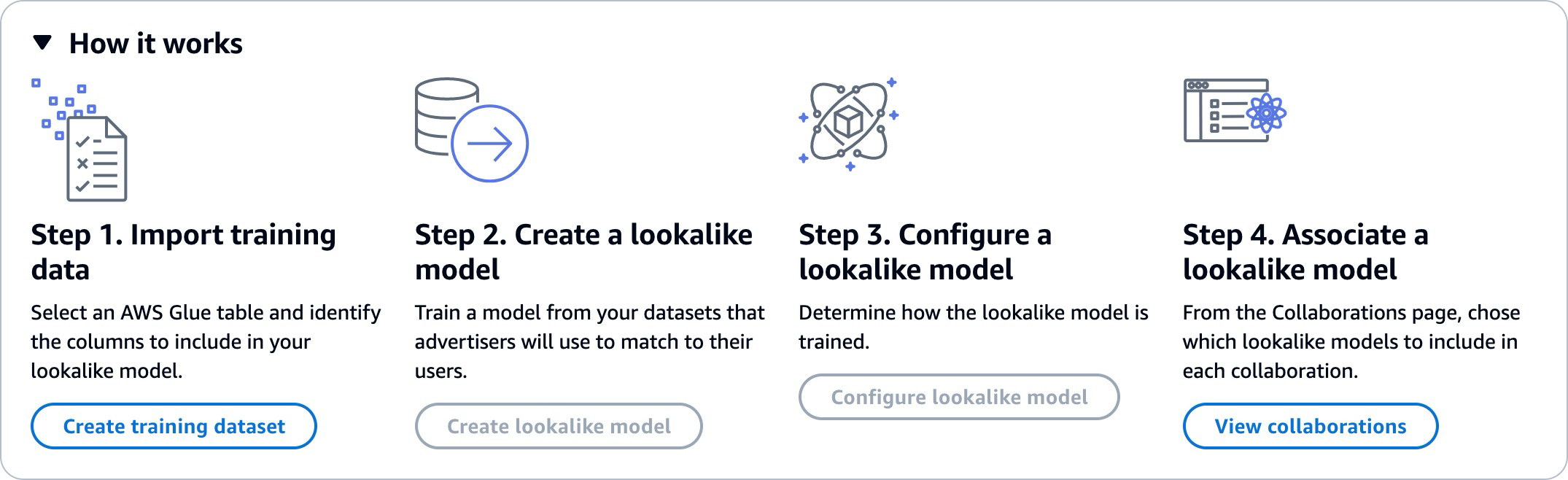
Die Arbeit mit Lookalike-Modellen erfordert, dass zwei Parteien, ein Anbieter von Trainingsdaten und ein Anbieter von Startdaten, nacheinander zusammenarbeiten, AWS Clean Rooms um ihre Daten in eine Zusammenarbeit einzubringen. Dies ist der Workflow, den der Trainingsdatenanbieter zuerst abschließen muss:
-
Die Daten des Trainingsdatenanbieters müssen in einer AWS Glue Datenkatalogtabelle mit Interaktionen zwischen Benutzern und Elementen gespeichert werden. Die Trainingsdaten müssen mindestens eine Benutzer-ID-Spalte, eine Interaktions-ID-Spalte und eine Zeitstempelspalte enthalten.
-
Der Trainingsdatenanbieter registriert die Trainingsdaten bei AWS Clean Rooms.
-
Der Trainingsdatenanbieter erstellt ein Lookalike-Modell, das mit mehreren Startdatenanbietern gemeinsam genutzt werden kann. Das Lookalike-Modell ist ein tiefes neuronales Netzwerk, dessen Training bis zu 24 Stunden dauern kann. Es wird nicht automatisch neu trainiert und wir empfehlen, dass Sie das Modell wöchentlich neu trainieren.
-
Der Anbieter von Trainingsdaten konfiguriert das Lookalike-Modell, einschließlich der Frage, ob Relevanzkennzahlen und der Amazon S3 S3-Speicherort der Ausgabesegmente geteilt werden sollen. Der Anbieter von Trainingsdaten kann mehrere konfigurierte Lookalike-Modelle aus einem einzigen Lookalike-Modell erstellen.
-
Der Anbieter von Trainingsdaten ordnet das konfigurierte Zielgruppenmodell einer Zusammenarbeit zu, die mit einem Startdatenanbieter geteilt wird.
Dies ist der Workflow, den der Seed-Datenanbieter als Nächstes abschließen muss:
-
Die Daten des Seed-Datenanbieters können in einem Amazon S3 S3-Bucket gespeichert werden oder aus den Ergebnissen einer Abfrage stammen.
-
Der Seed-Datenanbieter eröffnet die Zusammenarbeit, die er mit dem Trainingsdatenanbieter teilt.
-
Der Seed-Datenanbieter erstellt auf der Registerkarte Clean Rooms ML der Kollaborationsseite ein ähnliches Segment.
-
Der Seed-Datenanbieter kann die Relevanzkennzahlen auswerten, sofern sie geteilt wurden, und das Lookalike-Segment zur externen Verwendung exportieren. AWS Clean Rooms
So funktioniert AWS Clean Rooms ML mit benutzerdefinierten Modellen
Mit Clean Rooms ML können Mitglieder einer Kollaboration einen angedockten benutzerdefinierten Modellalgorithmus verwenden, der in Amazon ECR gespeichert ist, um ihre Daten gemeinsam zu analysieren. Dazu muss der Modellanbieter ein Bild erstellen und es in Amazon ECR speichern. Folgen Sie den Schritten im Amazon Elastic Container Registry User Guide, um ein privates Repository zu erstellen, das das benutzerdefinierte ML-Modell enthalten wird.
Jedes Mitglied einer Kollaboration kann der Modellanbieter sein, vorausgesetzt, es verfügt über die richtigen Berechtigungen. Alle Mitglieder einer Kollaboration können Trainingsdaten, Inferenzdaten oder beides zum Modell beitragen. Für die Zwecke dieses Leitfadens werden Mitglieder, die Daten beisteuern, als Datenanbieter bezeichnet. Das Mitglied, das die Kollaboration erstellt, ist der Ersteller der Kollaboration, und dieses Mitglied kann entweder der Modellanbieter, einer der Datenanbieter oder beides sein.
Auf der höchsten Ebene sind die folgenden Schritte aufgeführt, die ausgeführt werden müssen, um eine benutzerdefinierte ML-Modellierung durchzuführen:
-
Der Kollaborationsersteller erstellt eine Kollaboration und weist jedem Mitglied die richtigen Mitgliederfähigkeiten und Zahlungskonfigurationen zu. Der Kollaborationsersteller muss in diesem Schritt dem jeweiligen Mitglied die Fähigkeit zuweisen, entweder Modellausgaben zu empfangen oder Inferenzergebnisse zu empfangen, da diese Fähigkeit nach der Erstellung der Kollaboration nicht mehr aktualisiert werden kann. Weitere Informationen finden Sie unter Aufbau und Beitritt zur Zusammenarbeit in AWS Clean Rooms ML.
-
Der Modellanbieter konfiguriert und ordnet sein containerisiertes ML-Modell der Kollaboration zu und stellt sicher, dass Datenschutzbeschränkungen für exportierte Daten festgelegt werden. Weitere Informationen finden Sie unter Konfiguration eines Modellalgorithmus in AWS Clean Rooms ML.
-
Die Datenanbieter tragen ihre Daten zur Zusammenarbeit bei und stellen sicher, dass ihre Datenschutzanforderungen spezifiziert werden. Datenanbieter müssen dem Modell den Zugriff auf ihre Daten ermöglichen. Weitere Informationen erhalten Sie unter Bereitstellung von Trainingsdaten in AWS Clean Rooms ML und Zuordnen des konfigurierten Modellalgorithmus in AWS Clean Rooms ML.
-
Ein Mitglied der Kollaboration erstellt die ML-Konfiguration, die definiert, wohin die Modellartefakte oder Inferenzergebnisse exportiert werden.
-
Ein Kollaborationsmitglied erstellt einen ML-Eingabekanal, der Eingaben für den Trainings- oder Inferenzcontainer bereitstellt. Der ML-Eingabekanal ist eine Abfrage, die die Daten definiert, die im Kontext des Modellalgorithmus verwendet werden sollen.
-
Ein Kollaborationsmitglied ruft das Modelltraining mithilfe des ML-Eingabekanals und des konfigurierten Modellalgorithmus auf. Weitere Informationen finden Sie unter Erstellen eines trainierten Modells in AWS Clean Rooms ML.
-
(Optional) Der Modeltrainer ruft den Modellexportjob auf und die Modellartefakte werden an den Empfänger der Modellergebnisse gesendet. Nur Mitglieder mit einer gültigen ML-Konfiguration und der Fähigkeit, Modellausgaben zu empfangen, können Modellartefakte empfangen. Weitere Informationen finden Sie unter Exportieren von Modellartefakten aus AWS Clean Rooms ML.
-
(Optional) Ein Kollaborationsmitglied ruft die Modellinferenz mithilfe des ML-Eingangskanals, des trainierten Modell-ARN und des mit Inferenz konfigurierten Modellalgorithmus auf. Die Inferenzergebnisse werden an den Empfänger für die Inferenzausgabe gesendet. Nur Mitglieder mit einer gültigen ML-Konfiguration und der Fähigkeit eines Mitglieds, Inferenzausgaben zu empfangen, können Inferenzergebnisse empfangen.
Hier sind die Schritte, die vom Modellanbieter ausgeführt werden müssen:
-
Erstellen Sie ein SageMaker KI-kompatibles Amazon ECR-Docker-Image. Clean Rooms ML unterstützt nur SageMaker KI-kompatible Docker-Images.
-
Nachdem Sie ein SageMaker KI-kompatibles Docker-Image erstellt haben, übertragen Sie das Image an Amazon ECR. Folgen Sie den Anweisungen im Amazon Elastic Container Registry User Guide, um ein Container-Training-Image zu erstellen.
-
Konfigurieren Sie den Modellalgorithmus für die Verwendung in Clean Rooms ML.
-
Geben Sie den Amazon ECR-Repository-Link und alle Argumente an, die für die Konfiguration des Modellalgorithmus erforderlich sind.
-
Stellen Sie eine Servicezugriffsrolle bereit, die Clean Rooms ML den Zugriff auf das Amazon ECR-Repository ermöglicht.
-
Ordnen Sie den konfigurierten Modellalgorithmus der Kollaboration zu. Dazu gehört die Bereitstellung einer Datenschutzrichtlinie, die Kontrollen für Container-Logs, Fehlerprotokolle und CloudWatch Metriken sowie Beschränkungen dafür definiert, wie viele Daten aus den Container-Ergebnissen exportiert werden können.
-
Die folgenden Schritte müssen vom Datenanbieter ausgeführt werden, um mit einem benutzerdefinierten ML-Modell zusammenzuarbeiten:
-
Konfigurieren Sie eine vorhandene AWS Glue Tabelle mit einer benutzerdefinierten Analyseregel. Auf diese Weise können bestimmte vorab genehmigte Abfragen oder vorab genehmigte Konten Ihre Daten verwenden.
-
Ordnen Sie Ihre konfigurierte Tabelle einer Kollaboration zu und stellen Sie eine Dienstzugriffsrolle bereit, die auf Ihre AWS Glue Tabellen zugreifen kann.
-
Fügen Sie der Tabelle eine Regel zur Kollaborationsanalyse hinzu, die es der konfigurierten Modellalgorithmus-Assoziation ermöglicht, auf die konfigurierte Tabelle zuzugreifen.
-
Nachdem das Modell und die Daten in Clean Rooms ML verknüpft und konfiguriert wurden, stellt das Mitglied, das Abfragen ausführen kann, eine SQL-Abfrage bereit und wählt den zu verwendenden Modellalgorithmus aus.
Nach Abschluss des Modelltrainings initiiert dieses Mitglied den Export von Modelltrainingsartefakten oder Inferenzergebnissen. Diese Artefakte oder Ergebnisse werden an das Mitglied gesendet, das die Ausgabe des trainierten Modells empfangen kann. Der Empfänger der Ergebnisse muss sie konfigurieren, MachineLearningConfiguration bevor er die Modellausgabe empfangen kann.
