Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Rufen Sie eine AWS Lambda Funktion in einer Pipeline auf in CodePipeline
AWS Lambda ist ein Datenverarbeitungsservice, mit dem Sie Code ausführen können, ohne Server bereitstellen oder verwalten zu müssen. Sie können Lambda-Funktionen erstellen und sie als Aktionen zu Ihren Pipelines hinzufügen. Da Sie mit Lambda Funktionen für fast jede Aufgabe schreiben können, können Sie die Funktionsweise Ihrer Pipeline anpassen.
Wichtig
Protokollieren Sie nicht das JSON-Ereignis, das CodePipeline an Lambda gesendet wird, da dies dazu führen kann, dass Benutzeranmeldeinformationen in CloudWatch Logs protokolliert werden. Die CodePipeline Rolle verwendet ein JSON-Ereignis, um temporäre Anmeldeinformationen im artifactCredentials Feld an Lambda zu übergeben. Ein Beispiel für ein Ereignis finden Sie unter JSON-Beispielereignis.
Hier sind einige Möglichkeiten, wie Lambda-Funktionen in Pipelines verwendet werden können:
-
Um Ressourcen nach Bedarf in einer Phase einer Pipeline zu erstellen CloudFormation und sie in einer anderen Phase zu löschen.
-
Um Anwendungsversionen ohne Ausfallzeiten AWS Elastic Beanstalk mit einer Lambda-Funktion bereitzustellen, die CNAME-Werte tauscht.
-
Zur Bereitstellung auf Amazon ECS-Docker-Instances.
-
Sichern von Ressourcen mithilfe eines AMI-Snapshots vor dem Erstellen oder Bereitstellen
-
Integrieren von Drittanbieterprodukten in Ihre Pipeline, wie beispielsweise das Versenden von Nachrichten an einen IRC-Client
Anmerkung
Das Erstellen und Ausführen von Lambda-Funktionen kann zu Gebühren für Ihr AWS Konto führen. Weitere Informationen finden Sie unter – Preise
In diesem Thema wird vorausgesetzt, dass Sie mit Pipelines AWS CodePipeline AWS Lambda und Funktionen sowie den IAM-Richtlinien und -Rollen, von denen sie abhängen, vertraut sind und wissen, wie diese erstellt werden. In diesem Thema wird Folgendes veranschaulicht:
-
Erstellen Sie eine Lambda-Funktion, die testet, ob eine Webseite erfolgreich bereitgestellt wurde.
-
Konfigurieren Sie die Ausführungsrollen CodePipeline und die Lambda-Ausführungsrollen sowie die Berechtigungen, die für die Ausführung der Funktion als Teil der Pipeline erforderlich sind.
-
Bearbeiten Sie eine Pipeline, um die Lambda-Funktion als Aktion hinzuzufügen.
-
Testen der Aktion durch manuelles Veröffentlichen einer Änderung
Anmerkung
Wenn Sie die regionsübergreifende Lambda-Aufrufaktion in verwenden CodePipeline, PutJobFailureResultsollte der Status der Lambda-Ausführung mithilfe von PutJobSuccessResultund an die Region gesendet werden, in der die Lambda-Funktion vorhanden ist, und nicht an die AWS Region, in der sie existiert. CodePipeline
Dieses Thema enthält Beispielfunktionen, um die Flexibilität der Arbeit mit Lambda-Funktionen in CodePipeline folgenden Bereichen zu demonstrieren:
-
-
Erstellen einer grundlegenden Lambda-Funktion zur Verwendung mit CodePipeline.
-
Die Rückgabe von Erfolgs- oder Fehlschlagsergebnissen CodePipeline erfolgt über den Link „Details“ für die Aktion.
-
-
Beispiel für eine Python-Funktion, die eine AWS CloudFormation Vorlage verwendet
-
Verwenden von JSON-verschlüsselten Benutzerparametern für die Weiterleitung mehrerer Konfigurationswerte an die Funktion (
get_user_params) -
Interaktion mit ZIP-Artefakten in einem Artefakt-Bucket (
get_template) -
Verwenden eines Fortsetzungstokens, um einen lange andauernden asynchronen Prozess zu überwachen (
continue_job_later). Dadurch kann die Aktion fortgesetzt und die Funktion erfolgreich ausgeführt werden, auch wenn sie eine Laufzeit von fünfzehn Minuten überschreitet (ein Limit in Lambda).
-
Jede Beispielfunktion beinhaltet Informationen zu den Berechtigungen, die Sie der Rolle hinzufügen müssen. Informationen zu Grenzwerten in finden Sie unter Grenzwerte im AWS Lambda Entwicklerhandbuch.AWS Lambda
Wichtig
Beispiel-Code, Rollen und Richtlinien, die in diesem Thema enthalten sind, dienen lediglich als Beispiele und werden unverändert bereitgestellt.
Schritt 1: Erstellen einer Pipeline
In diesem Schritt erstellen Sie eine Pipeline, zu der Sie später die Lambda-Funktion hinzufügen. Das ist dieselbe Pipeline, die Sie unter CodePipeline Tutorials erstellt haben. Wenn diese Pipeline noch für Ihr Konto konfiguriert ist und sich in derselben Region befindet, in der Sie die Lambda-Funktion erstellen möchten, können Sie diesen Schritt überspringen.
So erstellen Sie die Pipeline
-
Folgen Sie den ersten drei Schritten unterTutorial: Erstellen einer einfachen Pipeline (S3-Bucket), um einen Amazon S3 S3-Bucket, CodeDeploy Ressourcen und eine zweistufige Pipeline zu erstellen. Wählen Sie die Amazon Linux-Option für Ihre Instance-Typen. Sie können einen beliebigen Namen für die Pipeline verwenden. Die Schritte in diesem Thema verwenden den Namen MyLambdaTestPipeline.
-
Wählen Sie auf der Statusseite für Ihre Pipeline in der CodeDeploy Aktion die Option Details aus. Wählen Sie auf der Seite zu den Details der Bereitstellungsgruppe eine Instance-ID aus der Liste aus.
-
Kopieren Sie in der Amazon EC2 EC2-Konsole auf der Registerkarte Details für die Instance die IP-Adresse in das Feld Öffentliche IPv4 Adresse (z. B.
192.0.2.4). Sie verwenden diese Adresse als Ziel der Funktion in AWS Lambda.
Anmerkung
Die standardmäßige Servicerollenrichtlinie für CodePipeline beinhaltet die Lambda-Berechtigungen, die zum Aufrufen der Funktion erforderlich sind. Sollten Sie jedoch die standardmäßige Servicerolle geändert oder eine andere Rolle ausgewählt haben, stellen Sie sicher, dass die Richtlinie für die Rolle die Berechtigungen für lambda:InvokeFunction und lambda:ListFunctions zulässt. Andernfalls schlagen Pipelines fehl, die Lambda-Aktionen enthalten.
Schritt 2: Erstellen Sie die Lambda-Funktion
In diesem Schritt erstellen Sie eine Lambda-Funktion, die eine HTTP-Anfrage stellt und nach einer Textzeile auf einer Webseite sucht. Im Rahmen dieses Schritts müssen Sie auch eine IAM-Richtlinie und eine Lambda-Ausführungsrolle erstellen. Weitere Informationen finden Sie im Berechtigungsmodell im AWS Lambda -Entwicklerhandbuch.
So erstellen Sie eine Ausführungsrolle
Melden Sie sich bei der an AWS-Managementkonsole und öffnen Sie die IAM-Konsole unter. https://console.aws.amazon.com/iam/
-
Wählen Sie Policies aus und wählen Sie dann Create Policy aus. Wählen Sie die Registerkarte JSON aus und kopieren Sie dann die folgende JSON-Richtlinie in das Feld.
-
Wählen Sie Richtlinie prüfen.
-
Geben Sie auf der Seite Review policy (Richtlinie prüfen) unter Name einen Namen für die Richtlinie ein (z. B.
CodePipelineLambdaExecPolicy). Geben Sie unter Description (Beschreibung) Folgendes ein:Enables Lambda to execute code.Wählen Sie Richtlinie erstellen aus.
Anmerkung
Dies sind die Mindestberechtigungen, die für die Zusammenarbeit einer Lambda-Funktion mit CodePipeline Amazon erforderlich sind. CloudWatch Wenn Sie diese Richtlinie erweitern möchten, um Funktionen zuzulassen, die mit anderen AWS Ressourcen interagieren, sollten Sie diese Richtlinie ändern, um die für diese Lambda-Funktionen erforderlichen Aktionen zuzulassen.
-
Wählen Sie auf der Seite mit dem Richtlinien-Dashboard Roles (Rollen) aus und wählen Sie dann Create role (Rolle erstellen) aus.
-
Wählen Sie auf der Seite Rolle erstellen die Option AWS-Service. Wählen Sie Lambda und klicken Sie dann auf Next: Permissions (Weiter: Berechtigungen).
-
Aktivieren Sie auf der Seite Attach permissions policies (Berechtigungsrichtlinien anfügen) das Kontrollkästchen neben CodePipelineLambdaExecPolicy und wählen Sie dann Next: Tags (Weiter: Tags) aus. Wählen Sie Weiter: Prüfen aus.
-
Geben Sie auf der Seite Review (Überprüfen) unter Role name (Rollenname) den Namen ein. Klicken Sie dann auf Create role (Rolle erstellen).
Um die Lambda-Beispielfunktion zu erstellen, die mit verwendet werden soll CodePipeline
Melden Sie sich bei der an AWS-Managementkonsole und öffnen Sie die AWS Lambda Konsole unter https://console.aws.amazon.com/lambda/
. -
Klicken Sie auf der Seite Functions (Funktionen) auf Create function (Funktion erstellen).
Anmerkung
Wenn Sie statt der Lambda-Seite eine Willkommensseite sehen, wählen Sie Jetzt loslegen.
-
Wählen Sie auf der Seite Create function die Option Author from scratch. Geben Sie im Feld Funktionsname einen Namen für Ihre Lambda-Funktion ein (z. B.
MyLambdaFunctionForAWSCodePipeline). Wählen Sie in Runtime Node.js 20.x aus. -
Wählen Sie für Role (Rolle) die Option Choose an existing role (Eine vorhandene Rolle wählen) aus. Wählen Sie Ihre Rolle unter Existing role (Vorhandene Rolle) aus und klicken Sie dann auf Create function (Funktion erstellen).
Die Detailseite für Ihre erstellte Funktion wird geöffnet.
-
Fügen Sie den folgenden Code in das Feld Function code (Funktionscode) ein:
Anmerkung
Das Ereignisobjekt unter dem Schlüssel CodePipeline .job enthält die Auftragsdetails. Ein vollständiges Beispiel für die CodePipeline Rückkehr des JSON-Ereignisses zu Lambda finden Sie unterJSON-Beispielereignis.
import { CodePipelineClient, PutJobSuccessResultCommand, PutJobFailureResultCommand } from "@aws-sdk/client-codepipeline"; import http from 'http'; import assert from 'assert'; export const handler = (event, context) => { const codepipeline = new CodePipelineClient(); // Retrieve the Job ID from the Lambda action const jobId = event["CodePipeline.job"].id; // Retrieve the value of UserParameters from the Lambda action configuration in CodePipeline, in this case a URL which will be // health checked by this function. const url = event["CodePipeline.job"].data.actionConfiguration.configuration.UserParameters; // Notify CodePipeline of a successful job const putJobSuccess = async function(message) { const command = new PutJobSuccessResultCommand({ jobId: jobId }); try { await codepipeline.send(command); context.succeed(message); } catch (err) { context.fail(err); } }; // Notify CodePipeline of a failed job const putJobFailure = async function(message) { const command = new PutJobFailureResultCommand({ jobId: jobId, failureDetails: { message: JSON.stringify(message), type: 'JobFailed', externalExecutionId: context.awsRequestId } }); await codepipeline.send(command); context.fail(message); }; // Validate the URL passed in UserParameters if(!url || url.indexOf('http://') === -1) { putJobFailure('The UserParameters field must contain a valid URL address to test, including http:// or https://'); return; } // Helper function to make a HTTP GET request to the page. // The helper will test the response and succeed or fail the job accordingly const getPage = function(url, callback) { var pageObject = { body: '', statusCode: 0, contains: function(search) { return this.body.indexOf(search) > -1; } }; http.get(url, function(response) { pageObject.body = ''; pageObject.statusCode = response.statusCode; response.on('data', function (chunk) { pageObject.body += chunk; }); response.on('end', function () { callback(pageObject); }); response.resume(); }).on('error', function(error) { // Fail the job if our request failed putJobFailure(error); }); }; getPage(url, function(returnedPage) { try { // Check if the HTTP response has a 200 status assert(returnedPage.statusCode === 200); // Check if the page contains the text "Congratulations" // You can change this to check for different text, or add other tests as required assert(returnedPage.contains('Congratulations')); // Succeed the job putJobSuccess("Tests passed."); } catch (ex) { // If any of the assertions failed then fail the job putJobFailure(ex); } }); }; -
Behalten Sie für Handler den Standardwert und für Role (Rolle) die Standardrolle
CodePipelineLambdaExecRolebei. -
Geben Sie unter Basic settings (Grundlegende Einstellungen) für Timeout den Wert
20Sekunden ein. -
Wählen Sie Speichern.
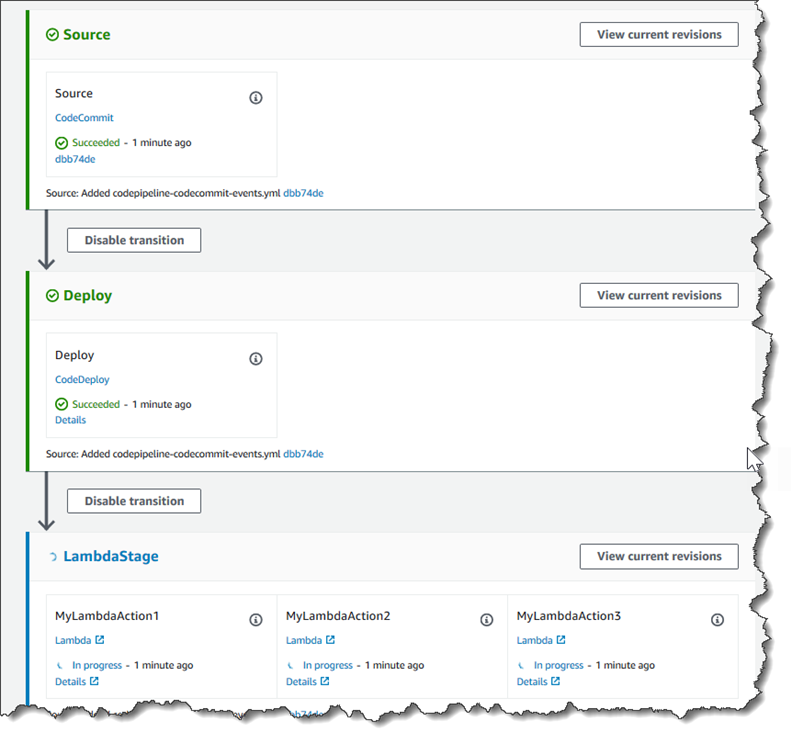
Schritt 3: Fügen Sie die Lambda-Funktion zu einer Pipeline in der CodePipeline Konsole hinzu
In diesem Schritt fügen Sie Ihrer Pipeline eine neue Phase hinzu und fügen dann eine Lambda-Aktion hinzu, die Ihre Funktion zu dieser Phase aufruft.
So fügen Sie eine Stufe hinzu
Melden Sie sich bei der an AWS-Managementkonsole und öffnen Sie die CodePipeline Konsole unter http://console.aws.amazon. com/codesuite/codepipeline/home
. -
Wählen Sie auf der Seite Welcome (Willkommen) die von Ihnen erstellte Pipeline aus.
-
Wählen Sie auf der Pipeline-Seite Edit aus.
-
Wählen Sie auf der Seite Bearbeiten die Option + Phase hinzufügen aus, um nach der Bereitstellungsphase eine Phase mit der CodeDeploy Aktion hinzuzufügen. Geben Sie einen Namen für die Stufe ein (z. B.
LambdaStage) und wählen Sie Add stage (Stufe hinzufügen).Anmerkung
Sie können sich auch dafür entscheiden, Ihre Lambda-Aktion zu einer vorhandenen Phase hinzuzufügen. Zu Demonstrationszwecken fügen wir die Lambda-Funktion als einzige Aktion in einer Phase hinzu, damit Sie ihren Fortschritt leicht verfolgen können, während Artefakte eine Pipeline durchlaufen.
-
Wählen Sie + Add action group (Aktionsgruppe hinzufügen). Geben Sie unter Aktion bearbeiten unter Aktionsname einen Namen für Ihre Lambda-Aktion ein (z. B.
MyLambdaAction). Wählen Sie in Provider (Anbieter) AWS Lambda aus. Wählen Sie unter Funktionsname den Namen Ihrer Lambda-Funktion aus, oder geben Sie ihn ein (z. B.MyLambdaFunctionForAWSCodePipeline). Geben Sie unter Benutzerparameter die IP-Adresse für die Amazon EC2 EC2-Instance an, die Sie zuvor kopiert haben (z. B.http://), und wählen Sie dann Fertig.192.0.2.4Anmerkung
Dieses Thema verwendet eine IP-Adresse. In echten Szenarien sollten Sie jedoch Ihren registrierten Website-Namen verwenden (z. B.
http://). Weitere Informationen zu Ereignisdaten und Handlern finden Sie unter Programmiermodell im AWS Lambda Entwicklerhandbuch. AWS Lambdawww.example.com -
Wählen Sie auf der Seite Edit action (Aktion bearbeiten) die Option Save (Speichern).
Schritt 4: Testen Sie die Pipeline mit der Lambda-Funktion
Um die Funktion zu testen, führen Sie die aktuelleste Änderung über die Pipeline aus.
So verwenden Sie die Konsole zum Ausführen der letzten Version eines Artefaktes in einer Pipeline
-
Wählen Sie auf der Seite mit den Pipeline-Details die Option Änderung veröffentlichen aus. Dadurch wird die letzte Revision gestartet, die in jedem in einer Quellaktion der Pipeline angegebenen Quellspeicherort vorhanden ist.
-
Wenn die Lambda-Aktion abgeschlossen ist, wählen Sie den Link Details, um den Protokollstream für die Funktion in Amazon anzuzeigen CloudWatch, einschließlich der abgerechneten Dauer des Ereignisses. Wenn die Funktion fehlgeschlagen ist, enthält das CloudWatch Protokoll Informationen über die Ursache.
Schritt 5: Nächste Schritte
Nachdem Sie erfolgreich eine Lambda-Funktion erstellt und als Aktion in einer Pipeline hinzugefügt haben, können Sie Folgendes versuchen:
-
Fügen Sie Ihrer Phase weitere Lambda-Aktionen hinzu, um andere Webseiten zu überprüfen.
-
Ändern Sie die Lambda-Funktion, um nach einer anderen Textzeichenfolge zu suchen.
-
Erkunden Sie Lambda-Funktionen und erstellen Sie Ihre eigenen Lambda-Funktionen und fügen Sie sie zu Pipelines hinzu.
Nachdem Sie mit dem Experimentieren mit der Lambda-Funktion fertig sind, sollten Sie erwägen, sie aus Ihrer Pipeline zu entfernen, sie aus IAM zu löschen und die Rolle aus IAM zu löschen AWS Lambda, um mögliche Gebühren zu vermeiden. Weitere Informationen finden Sie unter Eine Pipeline bearbeiten in CodePipeline, Löschen Sie eine Pipeline in CodePipeline und Löschen von Rollen oder Instance-Profilen.
JSON-Beispielereignis
Das folgende Beispiel zeigt ein JSON-Beispielereignis, das von CodePipeline an Lambda gesendet wurde. Die Struktur dieses Ereignisses ähnelt der Antwort unter GetJobDetails API, aber ohne den actionTypeId- und pipelineContext-Datentyp. Zwei Aktionskonfigurationsdetails, FunctionName und UserParameters, sind sowohl im JSON-Ereignis als auch in der Antwort auf die GetJobDetails-API enthalten. Die Werte in red italic text sind Beispiele oder Erklärungen, keine echten Werte.
{ "CodePipeline.job": { "id": "11111111-abcd-1111-abcd-111111abcdef", "accountId": "111111111111", "data": { "actionConfiguration": { "configuration": { "FunctionName": "MyLambdaFunctionForAWSCodePipeline", "UserParameters": "some-input-such-as-a-URL" } }, "inputArtifacts": [ { "location": { "s3Location": { "bucketName": "the name of the bucket configured as the pipeline artifact store in Amazon S3, for example codepipeline-us-east-2-1234567890", "objectKey": "the name of the application, for example CodePipelineDemoApplication.zip" }, "type": "S3" }, "revision": null, "name": "ArtifactName" } ], "outputArtifacts": [], "artifactCredentials": { "secretAccessKey": "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY", "sessionToken": "MIICiTCCAfICCQD6m7oRw0uXOjANBgkqhkiG9w 0BAQUFADCBiDELMAkGA1UEBhMCVVMxCzAJBgNVBAgTAldBMRAwDgYDVQQHEwdTZ WF0dGxlMQ8wDQYDVQQKEwZBbWF6b24xFDASBgNVBAsTC0lBTSBDb25zb2xlMRIw EAYDVQQDEwlUZXN0Q2lsYWMxHzAdBgkqhkiG9w0BCQEWEG5vb25lQGFtYXpvbi5 jb20wHhcNMTEwNDI1MjA0NTIxWhcNMTIwNDI0MjA0NTIxWjCBiDELMAkGA1UEBh MCVVMxCzAJBgNVBAgTAldBMRAwDgYDVQQHEwdTZWF0dGxlMQ8wDQYDVQQKEwZBb WF6b24xFDASBgNVBAsTC0lBTSBDb25zb2xlMRIwEAYDVQQDEwlUZXN0Q2lsYWMx HzAdBgkqhkiG9w0BCQEWEG5vb25lQGFtYXpvbi5jb20wgZ8wDQYJKoZIhvcNAQE BBQADgY0AMIGJAoGBAMaK0dn+a4GmWIWJ21uUSfwfEvySWtC2XADZ4nB+BLYgVI k60CpiwsZ3G93vUEIO3IyNoH/f0wYK8m9TrDHudUZg3qX4waLG5M43q7Wgc/MbQ ITxOUSQv7c7ugFFDzQGBzZswY6786m86gpEIbb3OhjZnzcvQAaRHhdlQWIMm2nr AgMBAAEwDQYJKoZIhvcNAQEFBQADgYEAtCu4nUhVVxYUntneD9+h8Mg9q6q+auN KyExzyLwaxlAoo7TJHidbtS4J5iNmZgXL0FkbFFBjvSfpJIlJ00zbhNYS5f6Guo EDmFJl0ZxBHjJnyp378OD8uTs7fLvjx79LjSTbNYiytVbZPQUQ5Yaxu2jXnimvw 3rrszlaEXAMPLE=", "accessKeyId": "AKIAIOSFODNN7EXAMPLE" }, "continuationToken": "A continuation token if continuing job", "encryptionKey": { "id": "arn:aws:kms:us-west-2:111122223333:key/1234abcd-12ab-34cd-56ef-1234567890ab", "type": "KMS" } } } }
Weitere Beispielfunktionen
Die folgenden Lambda-Beispielfunktionen demonstrieren zusätzliche Funktionen, die Sie für Ihre Pipelines in verwenden können. CodePipeline Um diese Funktionen verwenden zu können, müssen Sie möglicherweise die Richtlinie für die Lambda-Ausführungsrolle ändern, wie in der Einführung für jedes Beispiel angegeben.
Beispiel für eine Python-Funktion, die eine AWS CloudFormation Vorlage verwendet
Das folgende Beispiel zeigt eine Funktion, die einen Stack auf der Grundlage einer bereitgestellten CloudFormation Vorlage erstellt oder aktualisiert. Die Vorlage erstellt einen Amazon S3 S3-Bucket. Dies erfolgt nur zu Demonstrationszwecken, um Kosten zu sparen. Im Idealfall sollten Sie den Stack löschen, bevor Sie Inhalte in den Bucket hochladen. Falls Sie Dateien in den Bucket hochladen, können Sie den Bucket nicht mehr löschen, wenn Sie den Stack löschen. In diesem Fall müssen Sie alle Inhalte des Buckets manuell löschen, bevor Sie den Bucket selbst löschen können.
In diesem Python-Beispiel wird davon ausgegangen, dass Sie über eine Pipeline verfügen, die einen Amazon S3 S3-Bucket als Quellaktion verwendet, oder dass Sie Zugriff auf einen versionierten Amazon S3 S3-Bucket haben, den Sie mit der Pipeline verwenden können. Sie erstellen die CloudFormation Vorlage, komprimieren sie und laden sie als ZIP-Datei in diesen Bucket hoch. Anschließend müssen Sie Ihrer Pipeline eine Quellaktion hinzufügen, welche die ZIP-Datei aus dem Bucket abruft.
Anmerkung
Wenn Amazon S3 der Quellanbieter für Ihre Pipeline ist, können Sie Ihre Quelldatei (en) in eine einzige ZIP-Datei komprimieren und die ZIP-Datei in Ihren Quell-Bucket hochladen. Sie können auch eine einzelne Datei ungezippt hochladen, aber nachgelagerte Aktionen, die eine ZIP-Datei erwarten, schlagen dann fehl.
In diesem Beispiel wird Folgendes gezeigt:
-
Die Verwendung von JSON-verschlüsselten Benutzerparametern für die Weiterleitung mehrerer Konfigurationswerte an die Funktion (
get_user_params) -
Die Interaktion mit ZIP-Artefakten in einem Artefakt-Bucket (
get_template) -
Die Verwendung eines Fortsetzungstokens, um einen lange andauernden asynchronen Prozess zu überwachen (
continue_job_later). Dadurch kann die Aktion fortgesetzt und die Funktion erfolgreich ausgeführt werden, auch wenn sie eine Laufzeit von fünfzehn Minuten überschreitet (ein Limit in Lambda).
Um diese Lambda-Beispielfunktion verwenden zu können, muss die Richtlinie für die Lambda-Ausführungsrolle über Allow Berechtigungen in Amazon S3 verfügen und CloudFormation, wie in dieser Beispielrichtlinie gezeigt CodePipeline, folgende Berechtigungen haben:
Um die CloudFormation Vorlage zu erstellen, öffnen Sie einen beliebigen Klartext-Editor und kopieren Sie den folgenden Code und fügen Sie ihn ein:
{ "AWSTemplateFormatVersion" : "2010-09-09", "Description" : "CloudFormation template which creates an S3 bucket", "Resources" : { "MySampleBucket" : { "Type" : "AWS::S3::Bucket", "Properties" : { } } }, "Outputs" : { "BucketName" : { "Value" : { "Ref" : "MySampleBucket" }, "Description" : "The name of the S3 bucket" } } }
Speichern Sie dies als JSON-Datei mit dem Namen template.json in einem Verzeichnis mit dem Namen template-package. Erstellen Sie eine komprimierte Datei (.zip) mit diesem Verzeichnis und der Datei mit dem Namen template-package.zip und laden Sie die komprimierte Datei in einen versionierten Amazon S3 S3-Bucket hoch. Wenn Sie bereits einen Bucket für Ihre Pipeline konfiguriert haben, können Sie diesen verwenden. Bearbeiten Sie als Nächstes Ihre Pipeline und fügen Sie eine Quellaktion hinzu, welche die ZIP-Datei abruft. Benennen Sie die Ausgabe für diese Aktion. MyTemplate Weitere Informationen finden Sie unter Eine Pipeline bearbeiten in CodePipeline.
Anmerkung
Die Lambda-Beispielfunktion erwartet diese Dateinamen und die komprimierte Struktur. Sie können dieses Beispiel jedoch durch Ihre eigene CloudFormation Vorlage ersetzen. Wenn Sie Ihre eigene Vorlage verwenden, stellen Sie sicher, dass Sie die Richtlinie für die Lambda-Ausführungsrolle ändern, um alle zusätzlichen Funktionen zuzulassen, die für Ihre CloudFormation Vorlage erforderlich sind.
Um den folgenden Code als Funktion in Lambda hinzuzufügen
-
Öffnen Sie die Lambda-Konsole und wählen Sie Create function.
-
Wählen Sie auf der Seite Create function die Option Author from scratch. Geben Sie im Feld Funktionsname einen Namen für Ihre Lambda-Funktion ein.
-
Wählen Sie unter Runtime (Laufzeit) die Option Python 2.7 aus.
-
Wählen Sie unter Ausführungsrolle auswählen oder erstellen die Option Vorhandene Rolle verwenden aus. Wählen Sie Ihre Rolle unter Existing role (Vorhandene Rolle) aus und klicken Sie dann auf Create function (Funktion erstellen).
Die Detailseite für Ihre erstellte Funktion wird geöffnet.
-
Fügen Sie den folgenden Code in das Feld Function code (Funktionscode) ein:
from __future__ import print_function from boto3.session import Session import json import urllib import boto3 import zipfile import tempfile import botocore import traceback print('Loading function') cf = boto3.client('cloudformation') code_pipeline = boto3.client('codepipeline') def find_artifact(artifacts, name): """Finds the artifact 'name' among the 'artifacts' Args: artifacts: The list of artifacts available to the function name: The artifact we wish to use Returns: The artifact dictionary found Raises: Exception: If no matching artifact is found """ for artifact in artifacts: if artifact['name'] == name: return artifact raise Exception('Input artifact named "{0}" not found in event'.format(name)) def get_template(s3, artifact, file_in_zip): """Gets the template artifact Downloads the artifact from the S3 artifact store to a temporary file then extracts the zip and returns the file containing the CloudFormation template. Args: artifact: The artifact to download file_in_zip: The path to the file within the zip containing the template Returns: The CloudFormation template as a string Raises: Exception: Any exception thrown while downloading the artifact or unzipping it """ tmp_file = tempfile.NamedTemporaryFile() bucket = artifact['location']['s3Location']['bucketName'] key = artifact['location']['s3Location']['objectKey'] with tempfile.NamedTemporaryFile() as tmp_file: s3.download_file(bucket, key, tmp_file.name) with zipfile.ZipFile(tmp_file.name, 'r') as zip: return zip.read(file_in_zip) def update_stack(stack, template): """Start a CloudFormation stack update Args: stack: The stack to update template: The template to apply Returns: True if an update was started, false if there were no changes to the template since the last update. Raises: Exception: Any exception besides "No updates are to be performed." """ try: cf.update_stack(StackName=stack, TemplateBody=template) return True except botocore.exceptions.ClientError as e: if e.response['Error']['Message'] == 'No updates are to be performed.': return False else: raise Exception('Error updating CloudFormation stack "{0}"'.format(stack), e) def stack_exists(stack): """Check if a stack exists or not Args: stack: The stack to check Returns: True or False depending on whether the stack exists Raises: Any exceptions raised .describe_stacks() besides that the stack doesn't exist. """ try: cf.describe_stacks(StackName=stack) return True except botocore.exceptions.ClientError as e: if "does not exist" in e.response['Error']['Message']: return False else: raise e def create_stack(stack, template): """Starts a new CloudFormation stack creation Args: stack: The stack to be created template: The template for the stack to be created with Throws: Exception: Any exception thrown by .create_stack() """ cf.create_stack(StackName=stack, TemplateBody=template) def get_stack_status(stack): """Get the status of an existing CloudFormation stack Args: stack: The name of the stack to check Returns: The CloudFormation status string of the stack such as CREATE_COMPLETE Raises: Exception: Any exception thrown by .describe_stacks() """ stack_description = cf.describe_stacks(StackName=stack) return stack_description['Stacks'][0]['StackStatus'] def put_job_success(job, message): """Notify CodePipeline of a successful job Args: job: The CodePipeline job ID message: A message to be logged relating to the job status Raises: Exception: Any exception thrown by .put_job_success_result() """ print('Putting job success') print(message) code_pipeline.put_job_success_result(jobId=job) def put_job_failure(job, message): """Notify CodePipeline of a failed job Args: job: The CodePipeline job ID message: A message to be logged relating to the job status Raises: Exception: Any exception thrown by .put_job_failure_result() """ print('Putting job failure') print(message) code_pipeline.put_job_failure_result(jobId=job, failureDetails={'message': message, 'type': 'JobFailed'}) def continue_job_later(job, message): """Notify CodePipeline of a continuing job This will cause CodePipeline to invoke the function again with the supplied continuation token. Args: job: The JobID message: A message to be logged relating to the job status continuation_token: The continuation token Raises: Exception: Any exception thrown by .put_job_success_result() """ # Use the continuation token to keep track of any job execution state # This data will be available when a new job is scheduled to continue the current execution continuation_token = json.dumps({'previous_job_id': job}) print('Putting job continuation') print(message) code_pipeline.put_job_success_result(jobId=job, continuationToken=continuation_token) def start_update_or_create(job_id, stack, template): """Starts the stack update or create process If the stack exists then update, otherwise create. Args: job_id: The ID of the CodePipeline job stack: The stack to create or update template: The template to create/update the stack with """ if stack_exists(stack): status = get_stack_status(stack) if status not in ['CREATE_COMPLETE', 'ROLLBACK_COMPLETE', 'UPDATE_COMPLETE']: # If the CloudFormation stack is not in a state where # it can be updated again then fail the job right away. put_job_failure(job_id, 'Stack cannot be updated when status is: ' + status) return were_updates = update_stack(stack, template) if were_updates: # If there were updates then continue the job so it can monitor # the progress of the update. continue_job_later(job_id, 'Stack update started') else: # If there were no updates then succeed the job immediately put_job_success(job_id, 'There were no stack updates') else: # If the stack doesn't already exist then create it instead # of updating it. create_stack(stack, template) # Continue the job so the pipeline will wait for the CloudFormation # stack to be created. continue_job_later(job_id, 'Stack create started') def check_stack_update_status(job_id, stack): """Monitor an already-running CloudFormation update/create Succeeds, fails or continues the job depending on the stack status. Args: job_id: The CodePipeline job ID stack: The stack to monitor """ status = get_stack_status(stack) if status in ['UPDATE_COMPLETE', 'CREATE_COMPLETE']: # If the update/create finished successfully then # succeed the job and don't continue. put_job_success(job_id, 'Stack update complete') elif status in ['UPDATE_IN_PROGRESS', 'UPDATE_ROLLBACK_IN_PROGRESS', 'UPDATE_ROLLBACK_COMPLETE_CLEANUP_IN_PROGRESS', 'CREATE_IN_PROGRESS', 'ROLLBACK_IN_PROGRESS', 'UPDATE_COMPLETE_CLEANUP_IN_PROGRESS']: # If the job isn't finished yet then continue it continue_job_later(job_id, 'Stack update still in progress') else: # If the Stack is a state which isn't "in progress" or "complete" # then the stack update/create has failed so end the job with # a failed result. put_job_failure(job_id, 'Update failed: ' + status) def get_user_params(job_data): """Decodes the JSON user parameters and validates the required properties. Args: job_data: The job data structure containing the UserParameters string which should be a valid JSON structure Returns: The JSON parameters decoded as a dictionary. Raises: Exception: The JSON can't be decoded or a property is missing. """ try: # Get the user parameters which contain the stack, artifact and file settings user_parameters = job_data['actionConfiguration']['configuration']['UserParameters'] decoded_parameters = json.loads(user_parameters) except Exception as e: # We're expecting the user parameters to be encoded as JSON # so we can pass multiple values. If the JSON can't be decoded # then fail the job with a helpful message. raise Exception('UserParameters could not be decoded as JSON') if 'stack' not in decoded_parameters: # Validate that the stack is provided, otherwise fail the job # with a helpful message. raise Exception('Your UserParameters JSON must include the stack name') if 'artifact' not in decoded_parameters: # Validate that the artifact name is provided, otherwise fail the job # with a helpful message. raise Exception('Your UserParameters JSON must include the artifact name') if 'file' not in decoded_parameters: # Validate that the template file is provided, otherwise fail the job # with a helpful message. raise Exception('Your UserParameters JSON must include the template file name') return decoded_parameters def setup_s3_client(job_data): """Creates an S3 client Uses the credentials passed in the event by CodePipeline. These credentials can be used to access the artifact bucket. Args: job_data: The job data structure Returns: An S3 client with the appropriate credentials """ key_id = job_data['artifactCredentials']['accessKeyId'] key_secret = job_data['artifactCredentials']['secretAccessKey'] session_token = job_data['artifactCredentials']['sessionToken'] session = Session(aws_access_key_id=key_id, aws_secret_access_key=key_secret, aws_session_token=session_token) return session.client('s3', config=botocore.client.Config(signature_version='s3v4')) def lambda_handler(event, context): """The Lambda function handler If a continuing job then checks the CloudFormation stack status and updates the job accordingly. If a new job then kick of an update or creation of the target CloudFormation stack. Args: event: The event passed by Lambda context: The context passed by Lambda """ try: # Extract the Job ID job_id = event['CodePipeline.job']['id'] # Extract the Job Data job_data = event['CodePipeline.job']['data'] # Extract the params params = get_user_params(job_data) # Get the list of artifacts passed to the function artifacts = job_data['inputArtifacts'] stack = params['stack'] artifact = params['artifact'] template_file = params['file'] if 'continuationToken' in job_data: # If we're continuing then the create/update has already been triggered # we just need to check if it has finished. check_stack_update_status(job_id, stack) else: # Get the artifact details artifact_data = find_artifact(artifacts, artifact) # Get S3 client to access artifact with s3 = setup_s3_client(job_data) # Get the JSON template file out of the artifact template = get_template(s3, artifact_data, template_file) # Kick off a stack update or create start_update_or_create(job_id, stack, template) except Exception as e: # If any other exceptions which we didn't expect are raised # then fail the job and log the exception message. print('Function failed due to exception.') print(e) traceback.print_exc() put_job_failure(job_id, 'Function exception: ' + str(e)) print('Function complete.') return "Complete." -
Belassen Sie Handler auf dem Standardwert und belassen Sie Role bei dem Namen, den Sie zuvor ausgewählt oder erstellt haben
CodePipelineLambdaExecRole. -
Ersetzen Sie unter Basic settings (Grundlegende Einstellungen) im Feld Timeout den Standardwert von 3 Sekunden durch
20. -
Wählen Sie Speichern.
-
Bearbeiten Sie in der CodePipeline Konsole die Pipeline, um die Funktion als Aktion in einer Phase Ihrer Pipeline hinzuzufügen. Wählen Sie Bearbeiten für die Pipeline-Phase, die Sie ändern möchten, und wählen Sie Aktionsgruppe hinzufügen aus. Geben Sie auf der Seite Aktion bearbeiten im Feld Aktionsname einen Namen für Ihre Aktion ein. Wählen Sie unter Aktionsanbieter die Option Lambda aus.
Wählen Sie unter Eingabeartefakte die Option aus
MyTemplate. UserParametersIn müssen Sie eine JSON-Zeichenfolge mit drei Parametern angeben:-
Stack name
-
CloudFormation Vorlagenname und Pfad zur Datei
-
Eingabeartefakt
Verwenden Sie geschweifte Klammern ({}) und trennen Sie die Parameter durch Kommas. Um beispielsweise einen Stack mit dem Namen
MyTestStackfür eine Pipeline mit dem Eingabeartefakt in zu erstellenMyTemplate, geben Sie Folgendes ein: {"stack“:“MyTestStack„UserParameters, "file“ :"template-package/template.json“, "artifact“:“ „}.MyTemplateAnmerkung
Obwohl Sie das Eingabeartefakt in angegeben haben, müssen Sie dieses Eingabeartefakt auch für die Aktion unter UserParametersEingabeartefakte angeben.
-
-
Speichern Sie Ihre Änderungen an der Pipeline und geben Sie dann manuell eine Änderung frei, um die Aktion und die Lambda-Funktion zu testen.
