AWS Data Pipeline ist für Neukunden nicht mehr verfügbar. Bestandskunden von AWS Data Pipeline können den Service weiterhin wie gewohnt nutzen. Weitere Informationen
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Arbeiten an vorhandenen Ressourcen mit Task Runner ausführen
Sie können Task Runner auf Rechenressourcen installieren, die Sie verwalten, z. B. einer Amazon EC2 EC2-Instance oder einem physischen Server oder einer Workstation. Task Runner kann überall auf jeder kompatiblen Hardware oder jedem kompatiblen Betriebssystem installiert werden, vorausgesetzt, es kann mit dem AWS Data Pipeline Webservice kommunizieren.
Dieser Ansatz kann nützlich sein, wenn Sie beispielsweise Daten verarbeiten AWS Data Pipeline möchten, die in der Firewall Ihres Unternehmens gespeichert sind. Durch die Installation von Task Runner auf einem Server im lokalen Netzwerk können Sie sicher auf die lokale Datenbank zugreifen und dann die AWS Data Pipeline nächste auszuführende Aufgabe abfragen. Wenn die Verarbeitung AWS Data Pipeline beendet oder die Pipeline gelöscht wird, läuft die Task Runner-Instanz weiterhin auf Ihrer Rechenressource, bis Sie sie manuell herunterfahren. Die Task Runner-Protokolle bleiben bestehen, nachdem die Pipeline-Ausführung abgeschlossen ist.
Um Task Runner auf einer von Ihnen verwalteten Ressource zu verwenden, müssen Sie zuerst Task Runner herunterladen und ihn dann mithilfe der Verfahren in diesem Abschnitt auf Ihrer Rechenressource installieren.
Anmerkung
Sie können Task Runner nur unter Linux, UNIX oder macOS installieren. Task Runner wird auf dem Windows-Betriebssystem nicht unterstützt.
Um Task Runner 2.0 verwenden zu können, ist mindestens die Java-Version 1.7 erforderlich.
Um einen Task Runner, den Sie installiert haben, mit den Pipeline-Aktivitäten zu verbinden, die er verarbeiten soll, fügen Sie dem Objekt ein workerGroup Feld hinzu und konfigurieren Sie Task Runner so, dass er diesen Workergruppenwert abfragt. Dazu übergeben Sie die Worker-Group-Zeichenfolge als Parameter (z. B.--workerGroup=wg-12345), wenn Sie die Task Runner-JAR-Datei ausführen.
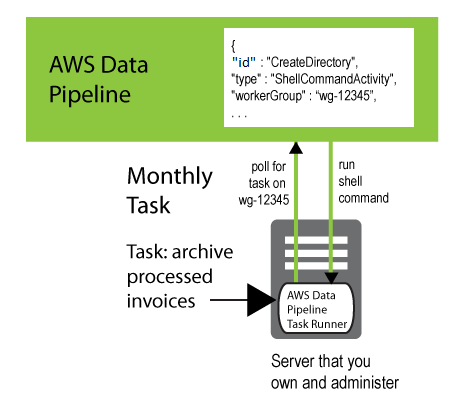
{ "id" : "CreateDirectory", "type" : "ShellCommandActivity", "workerGroup" : "wg-12345", "command" : "mkdir new-directory" }
Task Runner wird installiert
In diesem Abschnitt wird erklärt, wie Task Runner installiert und konfiguriert wird und welche Voraussetzungen dafür erforderlich sind. Die Installation ist ein einfacher manueller Prozess.
Um Task Runner zu installieren
-
Task Runner benötigt die Java-Versionen 1.6 oder 1.8. Verwenden Sie den folgenden Befehl, um festzustellen, ob Java installiert ist und welche Version ausgeführt wird:
java -versionWenn Sie Java 1.6 oder 1.8 nicht auf Ihrem Computer installiert haben, laden Sie eine dieser Versionen von http://www.oracle herunter. com/technetwork/java/index
.html. Laden Sie Java herunter und installieren Sie es und fahren Sie mit dem nächsten Schritt fort. -
Laden Sie es
TaskRunner-1.0.jarvon https://s3.amazonaws.com/datapipeline-us-east-1/us-east-1/ software/latest/TaskRunner/TaskRunner -1.0.jarherunter und kopieren Sie es dann in einen Ordner auf der Ziel-Computerressource. Für Amazon EMR-Cluster, die EmrActivityAufgaben ausführen, installieren Sie Task Runner auf dem Master-Knoten des Clusters. -
Wenn Sie Task Runner verwenden, um eine Verbindung zum AWS Data Pipeline Webservice herzustellen, um Ihre Befehle zu verarbeiten, benötigen Benutzer programmatischen Zugriff auf eine Rolle, die über Berechtigungen zum Erstellen oder Verwalten von Daten-Pipelines verfügt. Weitere Informationen finden Sie unter Erteilen programmgesteuerten Zugriffs.
-
Task Runner stellt über HTTPS eine Verbindung zum AWS Data Pipeline Webdienst her. Wenn Sie eine AWS Ressource verwenden, stellen Sie sicher, dass HTTPS in der entsprechenden Routingtabelle und Subnetz-ACL aktiviert ist. Wenn Sie eine Firewall oder einen Proxy verwenden, stellen Sie sicher, dass der Port 443 geöffnet ist.
Task Runner starten
Starten Sie Task Runner in einem neuen Befehlszeilenfenster, das sich auf das Verzeichnis bezieht, in dem Sie Task Runner installiert haben, mit dem folgenden Befehl.
java -jar TaskRunner-1.0.jar --config ~/credentials.json--workerGroup=myWorkerGroup--region=MyRegion--logUri=s3://amzn-s3-demo-bucket/foldername
Die Option --config zeigt auf Ihre Anmeldedaten-Datei.
Die Option --workerGroup gibt den Namen Ihrer Auftragnehmergruppe an, der für die zu verarbeitenden Aufgaben in Ihrer Pipeline den gleichen Wert haben muss.
Die Option --region gibt den Servicebereich an, von dem aus Aufgaben ausgeführt werden sollen.
Die --logUri Option wird verwendet, um Ihre komprimierten Protokolle an einen Speicherort in Amazon S3 zu übertragen.
Wenn Task Runner aktiv ist, gibt es den Pfad, in den die Protokolldateien geschrieben werden, im Terminalfenster aus. Im Folgenden wird ein -Beispiel gezeigt.
Logging to /Computer_Name/.../output/logs
Task-Runner sollte von Ihrer Anmelde-Shell getrennt ausgeführt werden. Wenn Sie eine Terminalanwendung verwenden, um eine Verbindung zu Ihrem Computer herzustellen, müssen Sie möglicherweise ein Dienstprogramm wie nohup oder screen verwenden, um zu verhindern, dass die Task-Runner-Anwendung beendet wird, wenn Sie sich abmelden. Weitere Informationen zu diesen Befehlszeilenoptionen finden Sie unter Task Runner-Konfigurationsoptionen.
Die Task Runner-Protokollierung wird überprüft
Der einfachste Weg, um zu überprüfen, ob Task Runner funktioniert, besteht darin, zu überprüfen, ob er Protokolldateien schreibt. Task Runner schreibt stündlich Protokolldateien in das Verzeichnis,output/logs, unter dem Verzeichnis, in dem Task Runner installiert ist. Der Dateiname ist Task Runner.log.YYYY-MM-DD-HH, wobei HH von 00 bis 23 in UDT läuft. Um Speicherplatz zu sparen, werden alle Protokolldateien, die älter als acht Stunden sind, mit komprimiert GZip.
