Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Elastische Amazon DocumentDB-Cluster: So funktioniert's
Die Themen in diesem Abschnitt enthalten Informationen zu den Mechanismen und Funktionen, die Amazon DocumentDB Elastic Clusters zugrunde liegen.
Topics
Elastisches Cluster-Sharding von Amazon DocumentDB
Elastische Amazon DocumentDB-Cluster verwenden Hash-basiertes Sharding, um Daten in einem verteilten Speichersystem zu partitionieren. Sharding, auch Partitionierung genannt, teilt große Datensätze auf mehrere Knoten in kleine Datensätze auf, sodass Sie Ihre Datenbank über vertikale Skalierungsgrenzen hinaus skalieren können. Elastische Cluster nutzen die Trennung oder „Entkopplung“ von Rechenleistung und Speicher in Amazon DocumentDB, sodass Sie unabhängig voneinander skalieren können. Anstatt Sammlungen neu zu partitionieren, indem kleine Datenblöcke zwischen Rechenknoten verschoben werden, kopieren elastische Cluster Daten effizient innerhalb des verteilten Speichersystems.
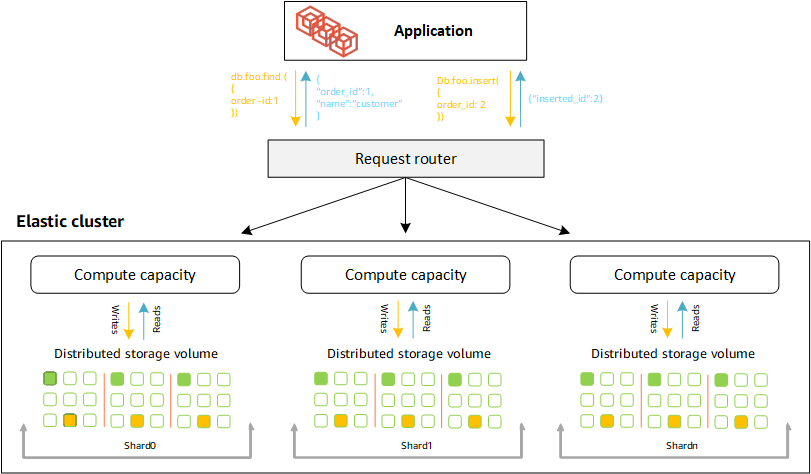
Shard-Definitionen
Definitionen der Shard-Nomenklatur:
Shard — Ein Shard stellt Rechenleistung für einen elastischen Cluster bereit. Er wird über eine einzelne Writer-Instance und 0—15 Read Replicas verfügen. Standardmäßig hat ein Shard zwei Instanzen: eine Writer- und eine einzelne Read-Replica. Sie können maximal 32 Shards konfigurieren und jede Shard-Instanz kann maximal 64 vCPUs haben.
Shard-Schlüssel — Ein Shard-Schlüssel ist ein Pflichtfeld in Ihren JSON-Dokumenten in Sharded-Collections, die Elastic Cluster verwenden, um Lese- und Schreibverkehr auf den entsprechenden Shard zu verteilen.
Sharded Collection — Eine Sharded Collection ist eine Sammlung, deren Daten über einen Elastic Cluster in Datenpartitionen verteilt sind.
Partition — Eine Partition ist ein logischer Teil von Shard-Daten. Wenn Sie eine fragmentierte Sammlung erstellen, werden die Daten innerhalb jedes Shards automatisch auf der Grundlage des Shard-Schlüssels in Partitionen organisiert. Jeder Shard hat mehrere Partitionen.
Verteilung von Daten auf konfigurierte Shards
Erstellen Sie einen Shard-Schlüssel mit vielen eindeutigen Werten. Ein guter Shard-Schlüssel verteilt Ihre Daten gleichmäßig auf die zugrunde liegenden Shards, sodass Ihr Workload den besten Durchsatz und die beste Leistung erhält. Das folgende Beispiel zeigt Daten zu Mitarbeiternamen, die einen Shard-Schlüssel mit dem Namen „user_id“ verwenden:
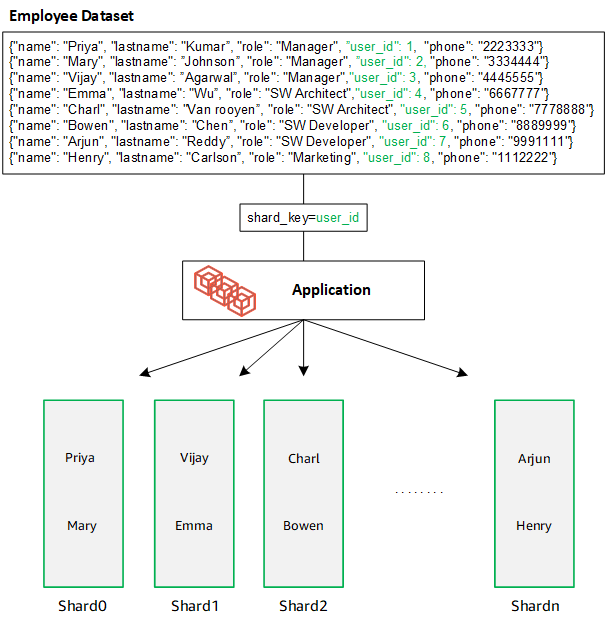
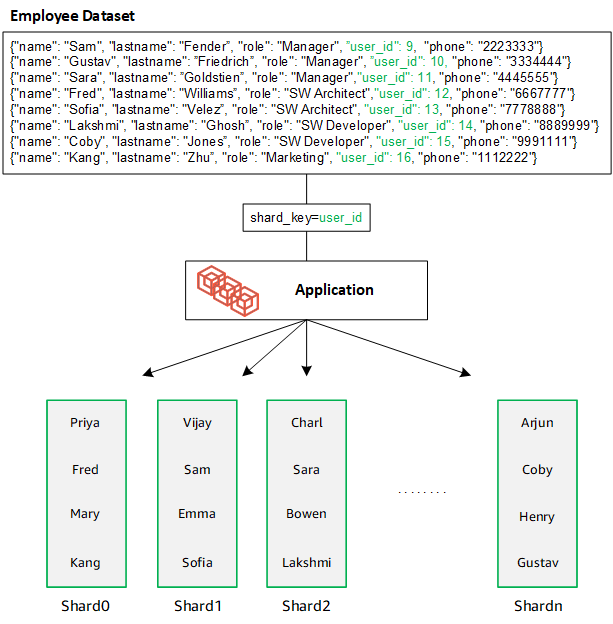
DocumentDB verwendet Hash-Sharding, um Ihre Daten auf die zugrunde liegenden Shards zu partitionieren. Zusätzliche Daten werden auf die gleiche Weise eingefügt und verteilt:
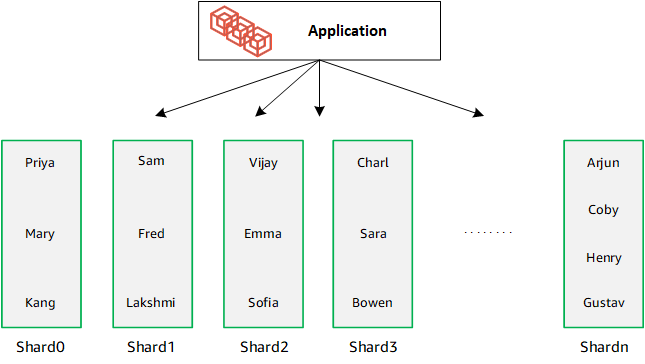
Wenn Sie Ihre Datenbank skalieren, indem Sie zusätzliche Shards hinzufügen, verteilt Amazon DocumentDB die Daten automatisch neu:
Elastische Cluster-Migration
Amazon DocumentDB unterstützt die Migration von mongoDB-Sharded-Daten zu elastischen Clustern. Offline-, Online- und Hybridmigrationsmethoden werden unterstützt. Weitere Informationen finden Sie unter Migration zu Amazon DocumentDB.
Elastische Cluster-Skalierung
Elastische Amazon DocumentDB-Cluster bieten die Möglichkeit, die Anzahl der Shards (Scale Out) in Ihrem Elastic Cluster und die Anzahl der auf jeden Shard angewendeten vCPUs (Scale Up) zu erhöhen. Sie können auch die Anzahl der Shards und die Rechenkapazität (vCPUs) nach Bedarf reduzieren.
Bewährte Methoden zur Skalierung finden Sie unter. Skalierung elastischer Cluster
Anmerkung
Cluster-level Skalierung ist ebenfalls verfügbar. Weitere Informationen finden Sie unter Skalierung von Amazon DocumentDB-Clustern.
Zuverlässigkeit elastischer Cluster
Amazon DocumentDB ist darauf ausgelegt, zuverlässig, robust und fehlertolerant zu sein. Um die Verfügbarkeit zu verbessern, stellen Elastic Cluster zwei Knoten pro Shard bereit, die in verschiedenen Availability Zones platziert sind. Amazon DocumentDB umfasst mehrere automatische Funktionen, die es zu einer zuverlässigen Datenbanklösung machen. Weitere Informationen finden Sie unter Zuverlässigkeit von Amazon DocumentDB.
Elastischer Cluster-Speicher und Verfügbarkeit
Amazon DocumentDB DocumentDB-Daten werden in einem Cluster-Volume gespeichert, bei dem es sich um ein einzelnes virtuelles Volume handelt, das Solid-State-Laufwerke (SSDs) verwendet. Ein Cluster-Volume besteht aus sechs Kopien Ihrer Daten, die automatisch über mehrere Availability Zones in einer einzigen Region repliziert werden. AWS Diese Replikation trägt dazu bei, dass Ihre Daten sehr langlebig sind und weniger Datenverlust möglich ist. Sie trägt außerdem dazu bei, dass Ihr Cluster während eines Failovers besser verfügbar ist, da Kopien Ihrer Daten bereits in anderen Availability Zones vorhanden sind. Weitere Informationen zu Speicher, Hochverfügbarkeit und Replikation finden Sie unterAmazon DocumentDB: So funktioniert es.
Funktionale Unterschiede zwischen Amazon DocumentDB 4.0 und Elastic Clusters
Die folgenden funktionalen Unterschiede bestehen zwischen Amazon DocumentDB 4.0 und Elastic Clusters.
Die Ergebnisse von
topundcollStatssind nach Shards partitioniert. Bei Datensammlungen mit mehreren Partitionen werden die Daten auf mehrere Partitionen verteilt, und diecollStatsBerichte werden aus den Partitionen aggregiert.collScansSammlungsstatistiken von
topundcollStatsfür Sammlungen mit Sharding werden zurückgesetzt, wenn die Anzahl der Cluster-Shards geändert wird.Die integrierte Backup-Rolle unterstützt jetzt.
serverStatusAktion — Entwickler und Anwendungen mit Backup-Rolle können Statistiken über den Status des Amazon DocumentDB-Clusters sammeln.Das
SecondaryDelaySecsFeld ersetztslaveDelayin derreplSetGetConfigAusgabe.Der
helloBefehl ersetztisMaster—hellogibt ein Dokument zurück, das die Rolle des elastischen Clusters beschreibt.Der
$elemMatchOperator in elastischen Clustern entspricht nur Dokumenten in der ersten Verschachtelungsebene eines Arrays. In Amazon DocumentDB 4.0 durchläuft der Operator alle Ebenen, bevor er übereinstimmende Dokumente zurücksendet. Beispiel:
db.foo.insert( [ {a: {b: 5}}, {a: {b: [5]}}, {a: {b: [3, 7]}}, {a: [{b: 5}]}, {a: [{b: 3}, {b: 7}]}, {a: [{b: [5]}]}, {a: [{b: [3, 7]}]}, {a: [[{b: 5}]]}, {a: [[{b: 3}, {b: 7}]]}, {a: [[{b: [5]}]]}, {a: [[{b: [3, 7]}]]} ]); // Elastic clusters > db.foo.find({a: {$elemMatch: {b: {$elemMatch: {$lt: 6, $gt: 4}}}}}, {_id: 0}) { "a" : [ { "b" : [ 5 ] } ] } // Docdb 4.0: traverse more than one level deep > db.foo.find({a: {$elemMatch: {b: {$elemMatch: {$lt: 6, $gt: 4}}}}}, {_id: 0}) { "a" : [ { "b" : [ 5 ] } ] } { "a" : [ [ { "b" : [ 5 ] } ] ] }
Die Projektion „$“ in Amazon DocumentDB 4.0 gibt alle Dokumente mit allen Feldern zurück. Bei elastischen Clustern gibt der
findBefehl mit einer „$“ -Projektion Dokumente zurück, die dem Abfrageparameter entsprechen und nur das Feld enthalten, das der Projektion „$“ entspricht.In elastischen Clustern geben die
findBefehle mit$regexund$optionsAbfrageparametern einen Fehler zurück: „Optionen können nicht sowohl in $regex als auch in $options festgelegt werden.“
Bei elastischen Clustern wird
$indexOfCPjetzt „-1" zurückgegeben, wenn:Die Teilzeichenfolge wurde nicht in der
string expressionDatei gefunden, oderstartist eine Zahl größer alsend, oderstartist eine Zahl, die größer als die Bytelänge der Zeichenfolge ist.
Gibt in Amazon DocumentDB 4.0 „0"
$indexOfCPzurück, wenn diestartPosition eine Zahl ist, die größer alsendoder die Bytelänge der Zeichenfolge ist.Bei elastischen Clustern geben Projektionsoperationen z. B. Dokumente zurück
{"_id.nestedField" : 1}, die nur das projizierte Feld enthalten._id fieldsIn Amazon DocumentDB 4.0 filtern Befehle zur verschachtelten Feldprojektion derweil kein Dokument heraus.
