Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Amazon DocumentDB: So funktioniert es
Amazon DocumentDB (mit MongoDB-Kompatibilität) ist ein vollständig verwalteter MongoDB-compatible Datenbankservice. Mit Amazon DocumentDB können Sie denselben Anwendungscode ausführen und dieselben Treiber und Tools verwenden, die Sie mit MongoDB verwenden. Amazon DocumentDB ist mit MongoDB 3.6, 4.0, 5.0 und 8.0 kompatibel.
Themen
Amazon DocumentDB DocumentDB-Versionen
Anmerkung
Die kleinere Versionsnummerierung gilt für Amazon DocumentDB 5.0 und höher. Amazon DocumentDB 3.6 und 4.0 verwenden nur Hauptversionen mit Engine-Patches.
Ab Amazon DocumentDB 5.0 verwendet die Engine-Version ein vierstufiges Nummerierungsschema: major.major.minor.patch.
-
Hauptversion — Identifiziert durch die ersten beiden Nummern der Version (z. B. 5.0). Die Hauptversion stellt den MongoDB-Kompatibilitätsgrad dar. Hauptversionen führen neue Funktionen, Leistungsverbesserungen und MongoDB-Kompatibilitätsupdates ein. Für ein Upgrade zwischen Hauptversionen (z. B. von 4.0 auf 5.0) ist ein Hauptversions-Upgrade (MVU) erforderlich. Weitere Informationen finden Sie unter Direktes Upgrade der Hauptversion von Amazon DocumentDB.
-
Nebenversion — Identifiziert durch die dritte Versionsnummer (z. B. die
1in 5.0.1). Nebenversionen enthalten Verbesserungen wie neue Funktionen, Sicherheitskorrekturen und Bugfixes innerhalb derselben Hauptversion. Sie können manuell auf eine neue Nebenversion aktualisieren. Weitere Informationen finden Sie unter Upgrade der Nebenversion von Amazon DocumentDB. -
Patch-Version — Engine-Patches werden innerhalb einer Nebenversion angewendet und enthalten wichtige Sicherheits- und Bugfixes. Die Patch-Version wird anhand der Engine-Patch-Version (z. B.
3.0.17983) nachverfolgt, die Sie überprüfen können, indem Sie sie ausführendb.runCommand({getEngineVersion: 1}). Patches werden während des Wartungsfensters Ihres Clusters installiert. Weitere Informationen finden Sie unter Wartung von Amazon DocumentDB.
Wenn Sie einen neuen Cluster erstellen, können Sie jede verfügbare Engine-Version angeben. Informationen zu verfügbaren Versionen und Support-Daten finden Sie unterUnterstützungstermine der Amazon DocumentDB DocumentDB-Engine-Version.
Wenn Sie Amazon DocumentDB verwenden, erstellen Sie zunächst einen Cluster. Ein DB-Cluster besteht aus null oder mehreren Datenbank-Instances und einem Cluster-Volume, das die Daten für diese Instances verwaltet. Ein Amazon DocumentDB-Cluster-Volume ist ein virtuelles Datenbankspeicher-Volume, das sich über mehrere Availability Zones erstreckt. Jede Availability Zone verfügt über eine Kopie der Cluster-Daten.
Ein Amazon DocumentDB-Cluster besteht aus zwei Komponenten:
-
Cluster-Volume — Verwendet einen Cloud-nativen Speicherservice, um Daten auf sechs Arten über drei Availability Zones hinweg zu replizieren und bietet so äußerst beständigen und verfügbaren Speicher. Ein Amazon DocumentDB-Cluster hat genau ein Cluster-Volume, das bis zu 128 TiB an Daten speichern kann.
-
Instances — Stellen die Rechenleistung für die Datenbank bereit, indem sie Daten auf das Cluster-Speichervolume schreiben und Daten aus dem Cluster-Speichervolume lesen. Ein Amazon DocumentDB-Cluster kann 0—16 Instances haben.
Instances erfüllen eine von zwei Rollen:
-
Primäre Instance — Unterstützt Lese- und Schreibvorgänge und führt alle Datenänderungen am Cluster-Volume durch. Jeder Amazon DocumentDB-Cluster hat eine primäre Instance.
-
Replica-Instance — Unterstützt nur Lesevorgänge. Ein Amazon DocumentDB-Cluster kann zusätzlich zur primären Instance bis zu 15 Replikate haben. Die Verwendung mehrerer Replikate ermöglicht es Ihnen, die Leseauslastungen zu verteilen. Darüber hinaus erhöhen Sie durch die Platzierung von Replikaten in separaten Availability Zones auch die Cluster-Verfügbarkeit.
Das folgende Diagramm veranschaulicht die Beziehung zwischen dem Cluster-Volume, der primären Instance und den Replikaten in einem Amazon DocumentDB-Cluster:
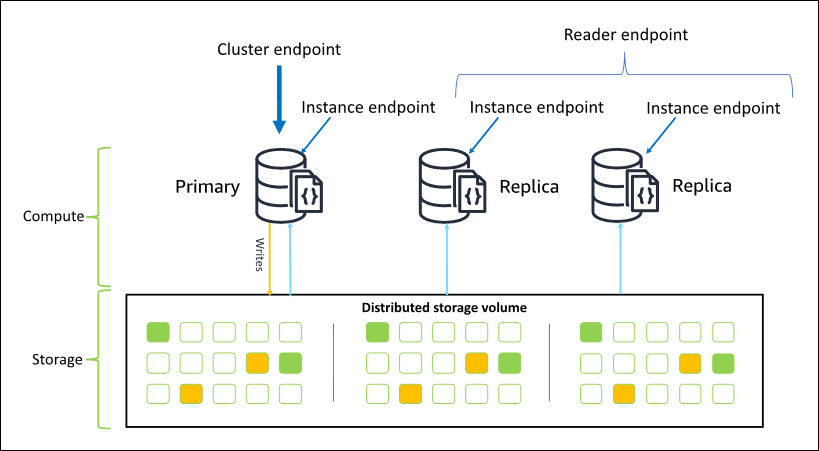
Cluster-Instances müssen nicht von derselben Instance-Klasse sein. Sie können beliebig bereitgestellt und beendet werden. Mit dieser Architektur können Sie die Rechenkapazität Ihres Clusters unabhängig von seiner Storage-Funktionalität skalieren.
Wenn Ihre Anwendung Daten in die Primär-Instance schreibt, schreibt diese die Daten dauerhaft in das Cluster-Volume. Anschließend repliziert es den Status dieses Schreibvorgangs (nicht die Daten) auf jedes aktive Replikat. Amazon DocumentDB DocumentDB-Replikate sind nicht an der Verarbeitung von Schreibvorgängen beteiligt, weshalb Amazon DocumentDB DocumentDB-Replikate für die Leseskalierung von Vorteil sind. Lesevorgänge von Amazon DocumentDB DocumentDB-Repliken sind letztlich konsistent mit minimaler Replikatverzögerung — in der Regel weniger als 100 Millisekunden, nachdem die primäre Instance die Daten geschrieben hat. Lesezugriffe von den Replikaten werden garantiert in der Reihenfolge gelesen, in der sie auf die primäre Instance geschrieben wurden. Die Replikationsverzögerung hängt von der Rate der Datenänderung ab. Perioden mit hoher Schreibaktivität können die Replikationsverzögerung erhöhen. Weitere Informationen finden Sie in den ReplicationLag-Metriken unter Amazon DocumentDB-Metriken.
Amazon DocumentDB DocumentDB-Endpunkte
Amazon DocumentDB bietet mehrere Verbindungsoptionen für eine Vielzahl von Anwendungsfällen. Um eine Verbindung zu einer Instance in einem Amazon DocumentDB-Cluster herzustellen, geben Sie den Endpunkt der Instance an. Ein Endpunkt ist eine Host-Adresse und eine Portnummer, getrennt durch einen Doppelpunkt.
Es wird empfohlen, dass Sie mithilfe des Clusterendpunkts und im Replikatsatzmodus eine Verbindung mit dem Cluster herstellen (siehe Als Replikatsatz eine Verbindung zu Amazon DocumentDB herstellen), es sei denn, es liegt ein bestimmter Anwendungsfall für die Verbindung mit dem Reader-Endpunkt oder einem Instanceendpunkt vor. Um Anforderungen an Ihre Replikate weiterzuleiten, wählen Sie eine Treibereinstellung für die Leseeinstellung aus, die die Leseskalierung maximiert und gleichzeitig die Anforderungen für die Lesekonsistenz Ihrer Anwendung erfüllt. Die Leseeinstellung secondaryPreferred ermöglicht Replica-Lesevorgänge, sodass die primäre Instance produktiver sein kann.
Die folgenden Endpunkte sind in einem Amazon DocumentDB-Cluster verfügbar.
Cluster-Endpunkt
Der Cluster-Endpunkt verbindet sich mit der aktuellen primären Instance Ihres Clusters. Der Cluster-Endpunkt kann für Lese- und Schreibvorgänge verwendet werden. Ein Amazon DocumentDB-Cluster hat genau einen Cluster-Endpunkt.
Der Cluster-Endpunkt bietet Failover-Support für Lese-/Schreibverbindungen zum Cluster. Wenn die aktuelle primäre Instance Ihres Clusters ausfällt und Ihr Cluster mindestens eine aktive Read Replica hat, leitet der Cluster-Endpunkt Verbindungsanforderungen automatisch an eine neue primäre Instance weiter. Wenn Sie eine Verbindung zu Ihrem Amazon DocumentDB-Cluster herstellen, empfehlen wir, dass Sie die Verbindung zu Ihrem Cluster über den Cluster-Endpunkt und im Replikatsatzmodus herstellen (sieheAls Replikatsatz eine Verbindung zu Amazon DocumentDB herstellen).
Im Folgenden finden Sie ein Beispiel für einen Amazon DocumentDB-Cluster-Endpunkt:
sample-cluster.cluster-123456789012.us-east-1.docdb.amazonaws.com:27017
Im Folgenden finden Sie ein Beispiel für eine Verbindungszeichenfolge für diesen Cluster-Endpunkt:
mongodb://username:password@sample-cluster.cluster-123456789012.us-east-1.docdb.amazonaws.com:27017
Informationen zum Suchen der Endpunkte eines Clusters finden Sie unter Die Endpunkte eines Clusters finden.
Leser-Endpunkt
Der Reader-Endpunkt agiert als Load-Balancer für schreibgeschützte Verbindungen für alle verfügbaren Replikate in Ihrem Cluster. Ein Cluster-Reader-Endpunkt fungiert als Cluster-Endpunkt, wenn Sie eine Verbindung über den replicaSet Modus herstellen, d. h. in der Verbindungszeichenfolge lautet der Replikatsatzparameter. &replicaSet=rs0 In diesem Fall können Sie Schreibvorgänge auf der Primärseite ausführen. Wenn Sie jedoch eine Verbindung zu dem angegebenen Cluster herstellendirectConnection=true, führt der Versuch, einen Schreibvorgang über eine Verbindung zum Leser-Endpunkt auszuführen, zu einem Fehler. Ein Amazon DocumentDB-Cluster hat genau einen Leser-Endpunkt.
Wenn der Cluster nur eine (primäre) Instance enthält, verbindet sich der Reader-Endpunkt mit der primären Instance. Wenn Sie Ihrem Amazon DocumentDB-Cluster eine Replikat-Instance hinzufügen, öffnet der Reader-Endpunkt schreibgeschützte Verbindungen zu dem neuen Replikat, nachdem es aktiv ist.
Im Folgenden finden Sie ein Beispiel für einen Reader-Endpunkt für einen Amazon DocumentDB-Cluster:
sample-cluster.cluster-ro-123456789012.us-east-1.docdb.amazonaws.com:27017
Im Folgenden finden Sie ein Beispiel für eine Verbindungszeichenfolge unter Verwendung eines Reader-Endpunkts:
mongodb://username:password@sample-cluster.cluster-ro-123456789012.us-east-1.docdb.amazonaws.com:27017
Der Reader-Endpunkt verteilt nur die Last der Read-only-Verbindungen – nicht die der Leseanforderungen. Wenn einige Reader-Endpunktverbindungen stärker genutzt werden als andere, sind Ihre Leseanforderungen möglicherweise nicht gleichmäßig zwischen Instances im Cluster verteilt. Es wird empfohlen, dass Sie zum Verteilen von Anforderungen eine Verbindung zum Clusterendpunkt als Replikatsatz herstellen und die Lesevorstellungsoption secondaryPreferred nutzen.
Informationen zum Suchen der Endpunkte eines Clusters finden Sie unter Die Endpunkte eines Clusters finden.
Instance-Endpunkt
Ein Instance-Endpunkt verbindet sich mit einer bestimmten Instance innerhalb Ihres Clusters. Der Instance-Endpunkt für die aktuelle Primär-Instance kann für Lese- und Schreibvorgänge verwendet werden. Der Versuch, Schreiboperationen auf einen Instance-Endpunkt für ein Lesereplikat durchzuführen, führt jedoch zu einem Fehler. Ein Amazon DocumentDB-Cluster hat einen Instance-Endpunkt pro aktiver Instance.
Ein Instance-Endpunkt bietet für Szenarien, in denen der Cluster-Endpunkt oder der Lese-Endpunkt möglicherweise nicht geeignet ist, direkte Kontrolle über Verbindungen zu einer bestimmten Instance. Ein Beispiel für einen Anwendungsfall ist die Bereitstellung für einen periodischen Read-Only-Analyse-Workload. Sie können eine Replikat-Instance bereitstellen, die größer als üblich ist, sich direkt mit der neuen größeren Instance und ihrem Instance-Endpunkt verbinden, die Analyseabfragen ausführen und die Instance dann beenden. Die Verwendung des Instance-Endpunkts verhindert, dass sich der Analyseverkehr auf andere Cluster-Instances auswirkt.
Im Folgenden finden Sie ein Beispiel für einen Instance-Endpunkt für eine einzelne Instance in einem Amazon DocumentDB-Cluster:
sample-instance.123456789012.us-east-1.docdb.amazonaws.com:27017
Im Folgenden finden Sie ein Beispiel für eine Verbindungszeichenfolge mit diesem Instance-Endpunkt:
mongodb://username:password@sample-instance.123456789012.us-east-1.docdb.amazonaws.com:27017
Anmerkung
Die Rolle einer Instance als "Primär" oder "Replikat" kann sich aufgrund eines Failover-Ereignisses ändern. Ihre Anwendungen sollten niemals davon ausgehen, dass ein bestimmter Instance-Endpunkt die primäre Instance ist. Es wird nicht empfohlen, eine Verbindung zu Instance-Endpunkten für Produktionsanwendungen herzustellen. Stattdessen wird empfohlen, dass Sie mithilfe des Clusterendpunkts und im Replikatsatzmodus eine Verbindung zum Cluster herstellen (siehe Als Replikatsatz eine Verbindung zu Amazon DocumentDB herstellen). Weitere Informationen zur erweiterten Kontrolle der Instance-Failover-Priorität finden Sie unter Grundlegendes zur Amazon DocumentDB-Cluster-Fehlertoleranz.
Informationen zum Suchen der Endpunkte eines Clusters finden Sie unter Den Endpunkt einer Instanz finden.
Replikat-Set-Modus
Sie können im Replikatsatzmodus eine Verbindung zu Ihrem Amazon DocumentDB-Cluster-Endpunkt herstellen, indem Sie den Namen des Replikatsatzes angeben. rs0 Die Verbindung im Replikatsatzmodus bietet die Möglichkeit, die Optionen Read Concern, Write Concern und Read Preference festzulegen. Weitere Informationen finden Sie unter Lesekonsistenz.
Im Folgenden finden Sie ein Beispiel für eine Verbindungszeichenfolge, die im Replikatsatzmodus verbunden ist:
mongodb://username:password@sample-cluster.cluster-123456789012.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0
Wenn Sie eine Verbindung im Replikatgruppenmodus herstellen, wird Ihr Amazon DocumentDB-Cluster Ihren Treibern und Clients als Replikatsatz angezeigt. Instances, die Ihrem Amazon DocumentDB-Cluster hinzugefügt und daraus entfernt wurden, werden automatisch in der Konfiguration des Replikatsatzes wiedergegeben.
Jeder Amazon DocumentDB-Cluster besteht aus einem einzelnen Replikatsatz mit dem Standardnamen. rs0 Der Name des Replikatsatzes kann nicht geändert werden.
Die Verbindung mit dem Cluster-Endpunkt im Replikatsatzmodus ist die empfohlene Methode für den allgemeinen Gebrauch.
Anmerkung
Alle Instances in einem Amazon DocumentDB-Cluster überwachen denselben TCP-Port auf Verbindungen.
TLS-Unterstützung
Weitere Informationen zur Verbindung mit Amazon DocumentDB mithilfe von Transport Layer Security (TLS) finden Sie unterVerschlüsseln von Daten während der Übertragung.
Amazon DocumentDB DocumentDB-Speicher
Amazon DocumentDB DocumentDB-Daten werden in einem Cluster-Volume gespeichert, bei dem es sich um ein einzelnes virtuelles Volume handelt, das Solid-State-Laufwerke (SSDs) verwendet. Ein Cluster-Volume besteht aus sechs Kopien Ihrer Daten, die automatisch über mehrere Availability Zones hinweg in einer einzigen repliziert werden. AWS-Region Diese Replikation trägt dazu bei, dass Ihre Daten sehr langlebig sind und weniger Datenverlust möglich ist. Sie trägt außerdem dazu bei, dass Ihr Cluster während eines Failovers besser verfügbar ist, da Kopien Ihrer Daten bereits in anderen Availability Zones vorhanden sind. Diese Kopien können weiterhin Datenanfragen an die Instances in Ihrem Amazon DocumentDB-Cluster bearbeiten.
Informationen zur Abrechnung des -Datenspeichers
Amazon DocumentDB erhöht automatisch die Größe eines Cluster-Volumes, wenn die Datenmenge zunimmt. Ein Amazon DocumentDB-Cluster-Volume kann auf eine maximale Größe von 128 TiB anwachsen. Ihnen wird jedoch nur der Speicherplatz in Rechnung gestellt, den Sie in einem Amazon DocumentDB-Cluster-Volume verwenden. Ab Amazon DocumentDB 4.0 verringert sich der zugewiesene Speicherplatz um einen vergleichbaren Betrag, wenn Daten entfernt werden, z. B. durch Löschen einer Sammlung oder eines Indexes. Somit können Sie die Speichergebühren senken, indem Sie Sammlungen, Indizes und Datenbanken löschen, die Sie nicht mehr benötigen. In Amazon DocumentDB Version 3.6 kann das Cluster-Volume Speicherplatz wiederverwenden, der beim Entfernen von Daten frei wird, aber das Volume selbst nimmt nie an Größe ab. Daher werden Sie in Version 3.6 möglicherweise keine Änderung des Speicherplatzes feststellen, wenn Sie eine Sammlung oder einen Index löschen, obwohl der freigewordene Speicherplatz wiederverwendet wird.
Anmerkung
Bei Amazon DocumentDB 3.6 basieren die Speicherkosten auf der Speichergrenze (der Höchstmenge, die dem Amazon DocumentDB-Cluster zu einem beliebigen Zeitpunkt zugewiesen wurde). Sie können die Kosten kontrollieren, indem Sie ETL-Praktiken vermeiden, die große Mengen temporärer Informationen erzeugen oder große Mengen neuer Daten laden, bevor nicht benötigte ältere Daten entfernt werden. Wenn das Entfernen von Daten aus einem Amazon DocumentDB-Cluster dazu führt, dass eine beträchtliche Menge an zugewiesenem, aber ungenutztem Speicherplatz zur Verfügung steht, müssen Sie zum Zurücksetzen der Höchstgrenze einen logischen Datendump und eine Wiederherstellung auf einem neuen Cluster mit einem Tool wie oder durchführen. mongodump mongorestore Das Erstellen und Wiederherstellen eines Snapshots führt nicht zur Reduzierung des zugeteilten Speichers, da das physische Layout des zugrunde liegenden Speichers im wiederhergestellten Snapshot unverändert bleibt.
Anmerkung
Für die Nutzung von mongodump Hilfsprogrammen mongorestore fallen I/O Gebühren an, die von der Größe der Daten abhängen, die auf das Speichervolume gelesen und geschrieben werden.
Informationen zur Amazon DocumentDB-Datenspeicherung und zu den I/O Preisen finden Sie in den häufig gestellten Fragen zu Preisen und Preisen von Amazon DocumentDB (mit MongoDB-Kompatibilität)
Amazon DocumentDB DocumentDB-Replikation
In einem Amazon DocumentDB-Cluster macht jede Replikatinstanz einen unabhängigen Endpunkt verfügbar. Diese Replikat-Endpunkte bieten Lesezugriff auf die Daten im Cluster-Volume. Mit ihnen können Sie die Leselast für Ihre Daten über mehrere replizierte Instances hinweg skalieren. Sie tragen auch dazu bei, die Leistung von Datenlesevorgängen zu verbessern und die Verfügbarkeit der Daten in Ihrem Amazon DocumentDB-Cluster zu erhöhen. Amazon DocumentDB-Replikate sind auch Failover-Ziele und werden schnell hochgestuft, wenn die primäre Instance für Ihren Amazon DocumentDB-Cluster ausfällt.
Zuverlässigkeit von Amazon DocumentDB
Amazon DocumentDB ist darauf ausgelegt, zuverlässig, robust und fehlertolerant zu sein. (Um die Verfügbarkeit zu verbessern, sollten Sie Ihren Amazon DocumentDB-Cluster so konfigurieren, dass er über mehrere Replikat-Instances in verschiedenen Availability Zones verfügt.) Amazon DocumentDB umfasst mehrere automatische Funktionen, die es zu einer zuverlässigen Datenbanklösung machen.
Automatische Speicherplatzreparatur
Amazon DocumentDB verwaltet mehrere Kopien Ihrer Daten in drei Availability Zones, wodurch das Risiko eines Datenverlusts aufgrund eines Speicherausfalls erheblich reduziert wird. Amazon DocumentDB erkennt automatisch Fehler im Cluster-Volume. Wenn ein Segment eines Cluster-Volumes ausfällt, repariert Amazon DocumentDB das Segment sofort. Es verwendet die Daten der anderen Volumes, aus denen sich das Cluster-Volumen zusammensetzt, um sicherzustellen, dass die Daten im reparierten Segment aktuell sind. Dadurch vermeidet Amazon DocumentDB Datenverluste und reduziert die Notwendigkeit, eine Point-in-Time-Wiederherstellung durchzuführen, um die Wiederherstellung nach einem Instance-Ausfall durchzuführen.
Überlebensfähiges Cache-Warming
Amazon DocumentDB verwaltet seinen Seiten-Cache in einem von der Datenbank getrennten Prozess, sodass der Seiten-Cache unabhängig von der Datenbank bestehen kann. Im unwahrscheinlichen Fall eines Datenbankausfalls, bleibt der Seiten-Cache im Arbeitsspeicher. Auf diese Weise wird sichergestellt, dass der Pufferpool beim Neustart der Datenbank mit dem aktuellen Zustand vorbereitet wird.
Wiederherstellung nach einem Ausfall
Amazon DocumentDB ist so konzipiert, dass es nach einem Absturz fast sofort wiederhergestellt wird und Ihre Anwendungsdaten weiterhin bereitgestellt werden. Amazon DocumentDB führt die Wiederherstellung nach einem Absturz asynchron auf parallel Threads durch, sodass Ihre Datenbank nach einem Absturz fast unmittelbar geöffnet und verfügbar ist.
Verwaltung von Ressourcen
Amazon DocumentDB schützt Ressourcen, die für die Ausführung kritischer Prozesse im Service benötigt werden, wie z. B. Zustandsprüfungen. Zu diesem Zweck drosselt Amazon DocumentDB Anfragen, wenn eine Instance unter hohem Speicherdruck steht. Daher können einige Operationen in die Warteschlange gestellt werden, um darauf zu warten, dass der Speicherdruck nachlässt. Wenn die Speicherauslastung anhält, kann es bei Vorgängen in der Warteschlange zu einer Zeitüberschreitung kommen. Anhand der folgenden CloudWatch Messwerte können Sie überwachen, ob der Dienst aufgrund von zu wenig Arbeitsspeicher Drosselungen durchführt oder nicht:LowMemThrottleQueueDepth,,. LowMemThrottleMaxQueueDepth LowMemNumOperationsThrottled LowMemNumOperationsTimedOut Weitere Informationen finden Sie unter Amazon DocumentDB überwachen mit CloudWatch. Wenn Sie aufgrund der LowMem CloudWatch Metriken einen anhaltenden Speicherdruck auf Ihrer Instance feststellen, empfehlen wir Ihnen, Ihre Instance hochzuskalieren, um zusätzlichen Speicher für Ihre Arbeitslast bereitzustellen.
Lesen Sie die Einstellungsoptionen
Amazon DocumentDB verwendet einen Cloud-nativen Shared Storage-Service, der Daten sechsmal über drei Availability Zones hinweg repliziert, um ein hohes Maß an Haltbarkeit zu gewährleisten. Amazon DocumentDB ist nicht darauf angewiesen, Daten auf mehrere Instanzen zu replizieren, um Haltbarkeit zu erreichen. Die Daten Ihres Clusters sind beständig, unabhängig davon, ob sie eine einzelne Instance oder 15 Instances enthalten.
Themen
Haltbarkeit beim Schreiben
Amazon DocumentDB verwendet ein einzigartiges, verteiltes, fehlertolerantes, selbstheilendes Speichersystem. Dieses System repliziert sechs Kopien (V=6) Ihrer Daten in drei AWS Availability Zones, um eine hohe Verfügbarkeit und Beständigkeit zu gewährleisten. Beim Schreiben von Daten stellt Amazon DocumentDB sicher, dass alle Schreibvorgänge dauerhaft auf den meisten Knoten aufgezeichnet werden, bevor der Schreibvorgang an den Client bestätigt wird. Wenn Sie einen MongoDB-Replikatsatz mit drei Knoten ausführen, {w:3, j:true} würde die Verwendung eines Schreibproblems von die bestmögliche Konfiguration im Vergleich zu Amazon DocumentDB ergeben.
Schreibvorgänge in einen Amazon DocumentDB-Cluster müssen von der Writer-Instance des Clusters verarbeitet werden. Der Versuch, in ein Lesegerät zu schreiben, führt zu einem Fehler. Ein bestätigter Schreibvorgang von einer primären Amazon DocumentDB-Instance ist dauerhaft und kann nicht rückgängig gemacht werden. Amazon DocumentDB ist standardmäßig sehr robust und unterstützt keine nicht dauerhafte Schreiboption. Sie können die Zuverlässigkeitsstufe (d. h. die Option Write Concern) nicht ändern. Amazon DocumentDB ignoriert w=anything und ist effektiv w: 3 und j: true. Sie können es nicht reduzieren.
Da Speicher und Datenverarbeitung in der Amazon DocumentDB DocumentDB-Architektur getrennt sind, ist ein Cluster mit einer einzigen Instanz äußerst robust. Die Zuverlässigkeit wird auf der Speicherschicht geregelt. Dadurch erreichen ein Amazon DocumentDB-Cluster mit einer einzigen Instance und ein Cluster mit drei Instances das gleiche Maß an Haltbarkeit. Sie können Ihren Cluster für Ihren speziellen Anwendungsfall konfigurieren und gleichzeitig für eine hohe Datenbeständigkeit sorgen.
Schreibvorgänge in einen Amazon DocumentDB-Cluster erfolgen innerhalb eines einzigen Dokuments atomar.
Amazon DocumentDB unterstützt wtimeout diese Option nicht und gibt keinen Fehler zurück, wenn ein Wert angegeben wird. Schreibvorgänge in die primäre Amazon DocumentDB DocumentDB-Instance werden garantiert nicht auf unbestimmte Zeit blockiert.
Isolierung lesen
Lesevorgänge aus einer Amazon DocumentDB DocumentDB-Instance geben nur Daten zurück, die vor Beginn der Abfrage dauerhaft sind. Lesezugriffe geben niemals Daten zurück, die nach Beginn der Ausführung der Abfrage geändert wurden. Auch "Dirty-Reads" sind unter keinen Umständen möglich.
Lesekonsistenz
Aus einem Amazon DocumentDB-Cluster gelesene Daten sind dauerhaft und werden nicht zurückgesetzt. Sie können die Lesekonsistenz für Amazon DocumentDB-Lesevorgänge ändern, indem Sie die Lesepräferenz für die Anfrage oder Verbindung angeben. Amazon DocumentDB unterstützt keine dauerhafte Leseoption.
Lesevorgänge aus der primären Instance eines Amazon DocumentDB-Clusters sind unter normalen Betriebsbedingungen sehr konsistent und weisen auch beim Lesen nach dem Schreiben eine Konsistenz auf. Tritt zwischen dem Schreiben und dem nachfolgenden Lesen ein Failover-Ereignis auf, kann das System kurzzeitig einen nicht "Strongly Consistent"-Wert zurückgeben. Alle Lesezugriffe auf einer gelesenen Replik sind "Eventually Consistent" und geben die Daten in der gleichen Reihenfolge zurück, oft mit weniger als 100 ms Replikationsverzögerung.
Amazon DocumentDB Leseeinstellungen
Amazon DocumentDB unterstützt das Festlegen einer Lesepräferenzoption nur beim Lesen von Daten vom Cluster-Endpunkt im Replikatsatzmodus. Das Festlegen einer Lesepräferenzoption wirkt sich darauf aus, wie Ihr MongoDB-Client oder -Treiber Leseanfragen an Instances in Ihrem Amazon DocumentDB-Cluster weiterleitet. Sie können Leseeinstellungen für eine bestimmte Abfrage oder als allgemeine Option in Ihrem MongoDB-Treiber festlegen. (Lesen Sie in der Dokumentation Ihres Clients oder Treibers nach, wie Sie eine Leseeinstellung festlegen können.)
Wenn Ihr Client oder Treiber im Replikatsatzmodus keine Verbindung zu einem Amazon DocumentDB-Cluster-Endpunkt herstellt, ist das Ergebnis der Angabe einer Lesepräferenz undefiniert.
Amazon DocumentDB unterstützt die Einstellung von Tag-Sets als Lesepräferenz nicht.
Unterstützte Leseeinstellungsoptionen
-
primary— Durch die Angabe einerprimaryLesepräferenz wird sichergestellt, dass alle Lesevorgänge an die primäre Instance des Clusters weitergeleitet werden. Wenn die primäre Instance nicht verfügbar ist, schlägt der Lesevorgang fehl. Die Leseeinstellungprimaryergibt Lese-After-Write-Konsistenz und eignet sich für Anwendungsfälle, die die Lese-nach-Schreib-Konsistenz über Hochverfügbarkeit und Leseskalierung priorisieren.Im folgenden Beispiel wird die Leseeinstellung
primaryangegeben:db.example.find().readPref('primary') -
primaryPreferred— Durch die Angabe einerprimaryPreferredLesepräferenz werden Lesevorgänge bei normalem Betrieb an die primäre Instance weitergeleitet. Wenn es ein primäres Failover gibt, leitet der Client Anfragen an ein Replikat weiter. Die LeseeinstellungprimaryPreferredsorgt für Lese-nach-Schreib-Konsistenz im Normalbetrieb und Eventually Consistent-Lesezugriffe während eines Failoverereignisses. Die LeseeinstellungprimaryPreferredist für Anwendungsfälle geeignet, die die Lese-nach-Schreib-Konsistenz über Hochverfügbarkeit und Leseskalierung priorisieren, jedoch trotzdem eine Hochverfügbarkeit erfordern.Im folgenden Beispiel wird die Leseeinstellung
primaryPreferredangegeben:db.example.find().readPref('primaryPreferred') -
secondary— Durch die Angabe einersecondaryLesepräferenz wird sichergestellt, dass Lesevorgänge nur an ein Replikat und niemals an die primäre Instanz weitergeleitet werden. Wenn es in einem Cluster keine Replikat-Instances gibt, schlägt die Leseanforderung fehl. Die Leseeinstellungsecondaryergibt Eventually Consistent-Lesezugriffe und ist für Anwendungsfälle geeignet, die den Schreibdurchsatz der primären Instance über die Hochverfügbarkeit und die Lesen-nach-Schreiben-Konsistenz priorisiert.Im folgenden Beispiel wird die Leseeinstellung
secondaryangegeben:db.example.find().readPref('secondary') -
secondaryPreferred— Durch die Angabe einersecondaryPreferredLesepräferenz wird sichergestellt, dass Lesevorgänge an eine Read Replica weitergeleitet werden, wenn ein oder mehrere Replikate aktiv sind. Wenn es in einem Cluster keine aktiven Replikat-Instances gibt, wird die Leseanforderung an die primäre Instance weitergeleitet. Die LeseeinstellungsecondaryPreferredergibt Eventually Consistent-Lesezugriffe, wenn der Lesezugriff durch ein Read Replica bedient wird. Sie liefert eine Lese-nach-Schreib-Konsistenz, wenn das Lesen von der primären Instance bedient wird (mit Ausnahme von Failover-Ereignissen). Die LeseeinstellungsecondaryPreferredist für Anwendungsfälle geeignet, die Leseskalierung und Hochverfügbarkeit über Lese-nach-Schreib-Konsistenz priorisieren.Im folgenden Beispiel wird die Leseeinstellung
secondaryPreferredangegeben:db.example.find().readPref('secondaryPreferred') -
nearest— Die Angabe einernearestLesepräferenz leitet Lesevorgänge ausschließlich auf der Grundlage der gemessenen Latenz zwischen dem Client und allen Instances im Amazon DocumentDB-Cluster weiter. Die Leseeinstellungnearestergibt Eventually Consistent-Lesezugriffe, wenn der Lesezugriff durch ein Read Replica bedient wird. Sie liefert eine Lese-nach-Schreib-Konsistenz, wenn das Lesen von der primären Instance bedient wird (mit Ausnahme von Failover-Ereignissen). Die Leseeinstellungnearestist für Anwendungsfälle geeignet, die das Erreichen einer möglichst geringen Leselatenz und die Hochverfügbarkeit über die Lese-zu-Schreib-Konsistenz und Leseskalierung priorisieren.Im folgenden Beispiel wird die Leseeinstellung
nearestangegeben:db.example.find().readPref('nearest')
Hohe Verfügbarkeit
Amazon DocumentDB unterstützt hochverfügbare Cluster-Konfigurationen, indem Repliken als Failover-Ziele für die primäre Instance verwendet werden. Wenn die primäre Instance ausfällt, wird ein Amazon DocumentDB DocumentDB-Replikat zur neuen primären Instance hochgestuft, mit einer kurzen Unterbrechung, während der Lese- und Schreibanforderungen an die primäre Instance mit einer Ausnahme fehlschlagen.
Wenn Ihr Amazon DocumentDB-Cluster keine Replikate enthält, wird die primäre Instance bei einem Ausfall neu erstellt. Das Heraufstufen eines Amazon DocumentDB DocumentDB-Replikats ist jedoch viel schneller als das Neuerstellen der primären Instance. Wir empfehlen daher, ein oder mehrere Amazon DocumentDB DocumentDB-Replikate als Failover-Ziele zu erstellen.
Replikate, die als Failover-Ziele verwendet werden sollen, sollten dieselbe DB-Instance-Klasse haben wie die primäre Instance. Sie sollten von der primären Instance in verschiedenen Availability Zones bereitgestellt werden. Sie können steuern, welche Replikate als Failover-Ziele bevorzugt werden. Bewährte Methoden zur Konfiguration von Amazon DocumentDB für hohe Verfügbarkeit finden Sie unterGrundlegendes zur Amazon DocumentDB-Cluster-Fehlertoleranz.
Lesevorgänge skalieren
Amazon DocumentDB DocumentDB-Repliken eignen sich ideal für die Skalierung von Lesevorgängen. Sie sind in Ihrem Cluster-Volume vollständig auf Lesevorgänge ausgerichtet, d. h. Replikate verarbeiten keine Schreibvorgänge. Die Datenreplikation geschieht innerhalb des Cluster-Volumes und nicht zwischen Instances. Deshalb sind die Replikat-Ressourcen auf die Verarbeitung von Abfragen ausgelegt und nicht auf das Schreiben und Replizieren von Daten.
Wenn Ihre Anwendung mehr Lesekapazität benötigt, können Sie Ihrem Cluster schnell (in der Regel in weniger als zehn Minuten) eine Replik hinzufügen. Wenn Ihr Lesekapazitätsbedarf sinkt, können Sie nicht benötigte Replikate entfernen. Mit Amazon DocumentDB DocumentDB-Repliken zahlen Sie nur für die Lesekapazität, die Sie benötigen.
Amazon DocumentDB unterstützt die clientseitige Leseskalierung mithilfe von Read Preference-Optionen. Weitere Informationen finden Sie unter Amazon DocumentDB Leseeinstellungen.
TTL löscht
Löschungen aus einem TTL-Indexbereich über einen Hintergrundprozess erfolgen nach dem Best-Effort-Prinzip und können nicht für einen bestimmten Zeitrahmen garantiert werden. Faktoren wie Instance-Größe, Instance-Ressourcenauslastung, Dokumentgröße und Gesamtdurchsatz können sich auf den Zeitpunkt einer TTL-Löschung auswirken.
Wenn der TTL-Monitor Ihre Dokumente löscht, entstehen bei jeder Löschung E/A-Kosten, was den Rechnungsbetrag erhöht. Wenn die Durchsatz- und TTL-Löschraten steigen, sollten Sie aufgrund der erhöhten I/O-Auslastung mit einer Erhöhung Ihrer Rechnung rechnen.
Wenn Sie einen TTL-Index für eine bestehende Sammlung erstellen, müssen Sie alle abgelaufenen Dokumente löschen, bevor Sie den Index erstellen. Die aktuelle TTL-Implementierung ist für das Löschen eines kleinen Teils der Dokumente in der Sammlung optimiert. Dies ist typisch, wenn TTL für die Sammlung von Anfang an aktiviert war. Dies kann zu höheren IOPS als nötig führen, wenn eine große Anzahl von Dokumenten gleichzeitig gelöscht werden muss.
Wenn Sie keinen TTL-Index zum Löschen von Dokumenten erstellen möchten, können Sie Dokumente stattdessen nach Zeit in Sammlungen unterteilen und diese Sammlungen einfach löschen, wenn die Dokumente nicht mehr benötigt werden. Beispiel: Sie können eine Sammlung pro Woche erstellen und diese löschen, ohne dass IO-Kosten anfallen. Dies kann deutlich kostengünstiger sein als die Verwendung eines TTL-Index.
Abrechnungsfähige Ressourcen
Identifizieren von kostenpflichtigen Amazon DocumentDB DocumentDB-Ressourcen
Als vollständig verwalteter Datenbankservice berechnet Amazon DocumentDB Gebühren für Instances, Speicher I/Os, Backups und Datenübertragung. Weitere Informationen finden Sie unter Preise für Amazon DocumentDB (mit MongoDB-Kompatibilität)
Um abrechnungsfähige Ressourcen in Ihrem Konto zu finden und die Ressourcen möglicherweise zu löschen, können Sie das oder verwenden. AWS-Managementkonsole AWS CLI
Verwendung der AWS-Managementkonsole
Mithilfe von können Sie die AWS-Managementkonsole Amazon DocumentDB-Cluster, -Instances und -Snapshots ermitteln, die Sie für eine bestimmte Person bereitgestellt haben. AWS-Region
So ermitteln Sie Cluster, Instances und Snapshots:
Melden Sie sich bei der AWS-Managementkonsole an und öffnen Sie die Amazon DocumentDB DocumentDB-Konsole unter https://console.aws.amazon.com/docdb
. -
Um nach abrechnungsfähigen Ressourcen in einer anderen Region als Ihrer Standardregion zu suchen, wählen Sie in der oberen rechten Ecke des Bildschirms die Region aus, nach der AWS-Region Sie suchen möchten.
-
Wählen Sie im Navigationsbereich die Art der kostenpflichtigen Ressource aus: Clusters (Cluster), Instances oder Snapshots.
-
Im rechten Bereich werden alle bereitgestellten Cluster, Instances oder Snapshots für die Region aufgelistet. Für Cluster, Instances und Snapshots werden Gebühren berechnet.
Verwendung der AWS CLI
Mithilfe von können Sie die AWS CLI Amazon DocumentDB-Cluster, -Instances und -Snapshots ermitteln, die Sie für eine bestimmte Person bereitgestellt haben. AWS-Region
So ermitteln Sie Cluster und Instances:
Der folgende Code listet Ihre gesamten Cluster und Instances für die angegebene Region auf. Wenn Sie nach Clustern und Instances in Ihrer Standardregion suchen möchten, können Sie den Parameter --region weglassen.
Beispiel
Für Linux, macOS oder Unix:
aws docdb describe-db-clusters \ --region us-east-1 \ --query 'DBClusters[?Engine==`docdb`]' | \ grep -e "DBClusterIdentifier" -e "DBInstanceIdentifier"
Für Windows:
aws docdb describe-db-clusters ^ --region us-east-1 ^ --query 'DBClusters[?Engine==`docdb`]' | ^ grep -e "DBClusterIdentifier" -e "DBInstanceIdentifier"
Die Ausgabe dieser Operation sieht in etwa folgendermaßen aus.
"DBClusterIdentifier": "docdb-2019-01-09-23-55-38",
"DBInstanceIdentifier": "docdb-2019-01-09-23-55-38",
"DBInstanceIdentifier": "docdb-2019-01-09-23-55-382",
"DBClusterIdentifier": "sample-cluster",
"DBClusterIdentifier": "sample-cluster2",So ermitteln Sie Snapshots:
Der folgende Code listet Ihre gesamten Snapshots für die angegebene Region auf. Wenn Sie in Ihrer Standardregion nach Snapshots suchen möchten, können Sie den Parameter --region weglassen.
Für Linux, macOS oder Unix:
aws docdb describe-db-cluster-snapshots \ --region us-east-1 \ --query 'DBClusterSnapshots[?Engine==`docdb`].[DBClusterSnapshotIdentifier,SnapshotType]'
Für Windows:
aws docdb describe-db-cluster-snapshots ^ --region us-east-1 ^ --query 'DBClusterSnapshots[?Engine==`docdb`].[DBClusterSnapshotIdentifier,SnapshotType]'
Die Ausgabe dieser Operation sieht in etwa folgendermaßen aus.
[
[
"rds:docdb-2019-01-09-23-55-38-2019-02-13-00-06",
"automated"
],
[
"test-snap",
"manual"
]
]Sie müssen nur manual-Snapshots löschen. Automated-Snapshots werden gelöscht, wenn Sie den Cluster löschen.
Löschen unerwünschter kostenpflichtiger Ressourcen
Um einen Cluster zu löschen, müssen Sie zunächst alle Instances im Cluster löschen.
-
Weitere Informationen zum Löschen von Instances finden Sie unter Löschen einer Amazon DocumentDB DocumentDB-Instance.
Wichtig
Auch wenn Sie die Instances in einem Cluster löschen, wird Ihnen die mit diesem Cluster verbundene Speicher- und Sicherungsnutzung in Rechnung gestellt. Um alle Kosten zu stoppen, müssen Sie auch Ihren Cluster und manuelle Snapshots löschen.
-
Weitere Informationen zum Löschen von Clustern finden Sie unter Löschen eines Amazon DocumentDB-Clusters.
-
Weitere Informationen zum Löschen manueller Snapshots finden Sie unter Löschen eines Cluster-Snapshots.
