Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Lösung für die Überwachung der Amazon EKS-Infrastruktur mit Amazon Managed Grafana
Die Überwachung der Amazon Elastic Kubernetes Service Service-Infrastruktur ist eines der häufigsten Szenarien, für die Amazon Managed Grafana verwendet wird. Auf dieser Seite wird eine Vorlage beschrieben, die Ihnen eine Lösung für dieses Szenario bietet. Die Lösung kann mit AWS Cloud Development Kit (AWS CDK)oder mit Terraform
Diese Lösung konfiguriert:
-
Ihr Amazon Managed Service for Prometheus-Workspace speichert Metriken aus Ihrem Amazon EKS-Cluster und erstellt einen verwalteten Collector, um die Metriken zu scrapen und in diesen Workspace zu übertragen. Weitere Informationen finden Sie unter Metriken mit verwalteten Collectors aufnehmen. AWS
-
Sammeln von Protokollen aus Ihrem Amazon EKS-Cluster mithilfe eines CloudWatch Agenten. Die Protokolle werden in Amazon Managed CloudWatch Grafana gespeichert und von Amazon abgefragt. Weitere Informationen finden Sie unter Protokollierung für Amazon EKS
-
Ihr Amazon Managed Grafana-Workspace, um diese Protokolle und Metriken abzurufen und Dashboards und Benachrichtigungen zu erstellen, mit denen Sie Ihren Cluster überwachen können.
Durch die Anwendung dieser Lösung werden Dashboards und Benachrichtigungen erstellt, die:
-
Beurteilen Sie den allgemeinen Zustand des Amazon EKS-Clusters.
-
Zeigen Sie den Zustand und die Leistung der Amazon EKS-Steuerebene an.
-
Zeigen Sie den Zustand und die Leistung der Amazon EKS-Datenebene an.
-
Zeigen Sie Einblicke in Amazon EKS-Workloads in allen Kubernetes-Namespaces an.
-
Zeigen Sie die Ressourcennutzung in allen Namespaces an, einschließlich CPU-, Arbeitsspeicher-, Festplatten- und Netzwerknutzung.
Informationen zu dieser Lösung
Diese Lösung konfiguriert einen Amazon Managed Grafana-Workspace, um Metriken für Ihren Amazon EKS-Cluster bereitzustellen. Die Metriken werden verwendet, um Dashboards und Benachrichtigungen zu generieren.
Die Metriken helfen Ihnen dabei, Amazon EKS-Cluster effektiver zu betreiben, indem sie Einblicke in den Zustand und die Leistung der Kubernetes-Steuerungs- und Datenebene bieten. Sie können Ihren Amazon EKS-Cluster von der Knotenebene über die Pods bis hin zur Kubernetes-Ebene verstehen, einschließlich einer detaillierten Überwachung der Ressourcennutzung.
Die Lösung bietet sowohl vorausschauende als auch korrektive Funktionen:
-
Zu den vorausschauenden Funktionen gehören:
-
Managen Sie die Ressourceneffizienz, indem Sie Entscheidungen zur Terminplanung treffen. Um beispielsweise Ihren internen Benutzern des Amazon EKS-Clusters SLAs für Leistung und Zuverlässigkeit zu bieten, können Sie ihren Workloads auf der Grundlage der Nachverfolgung der historischen Nutzung genügend CPU- und Speicherressourcen zuweisen.
-
Nutzungsprognosen: Basierend auf der aktuellen Auslastung Ihrer Amazon EKS-Cluster-Ressourcen wie Knoten, Persistent Volumes, die von Amazon EBS unterstützt werden, oder Application Load Balancers können Sie vorausschauend planen, z. B. für ein neues Produkt oder Projekt mit ähnlichen Anforderungen.
-
Erkennen Sie potenzielle Probleme frühzeitig: Indem Sie beispielsweise Trends beim Ressourcenverbrauch auf Kubernetes-Namespace-Ebene analysieren, können Sie die saisonale Abhängigkeit der Workload-Nutzung nachvollziehen.
-
-
Zu den Korrekturmöglichkeiten gehören:
-
Verkürzen Sie die mittlere Zeit bis zur Erkennung (MTTD) von Problemen auf Infrastruktur- und Kubernetes-Workload-Ebene. Wenn Sie sich beispielsweise das Dashboard zur Fehlerbehebung ansehen, können Sie Hypothesen darüber, was schief gelaufen ist, schnell testen und sie beseitigen.
-
Ermitteln Sie, wo im Stapel ein Problem auftritt. Beispielsweise wird die Amazon EKS-Kontrollebene vollständig von verwaltet, AWS und bestimmte Operationen wie das Aktualisieren einer Kubernetes-Bereitstellung können fehlschlagen, wenn der API-Server überlastet ist oder die Konnektivität beeinträchtigt ist.
-
Die folgende Abbildung zeigt ein Beispiel für den Dashboard-Ordner für die Lösung.
Sie können ein Dashboard auswählen, um weitere Details anzuzeigen. Wenn Sie beispielsweise die Computing-Ressourcen für Workloads anzeigen, wird ein Dashboard angezeigt, wie das in der folgenden Abbildung gezeigte.
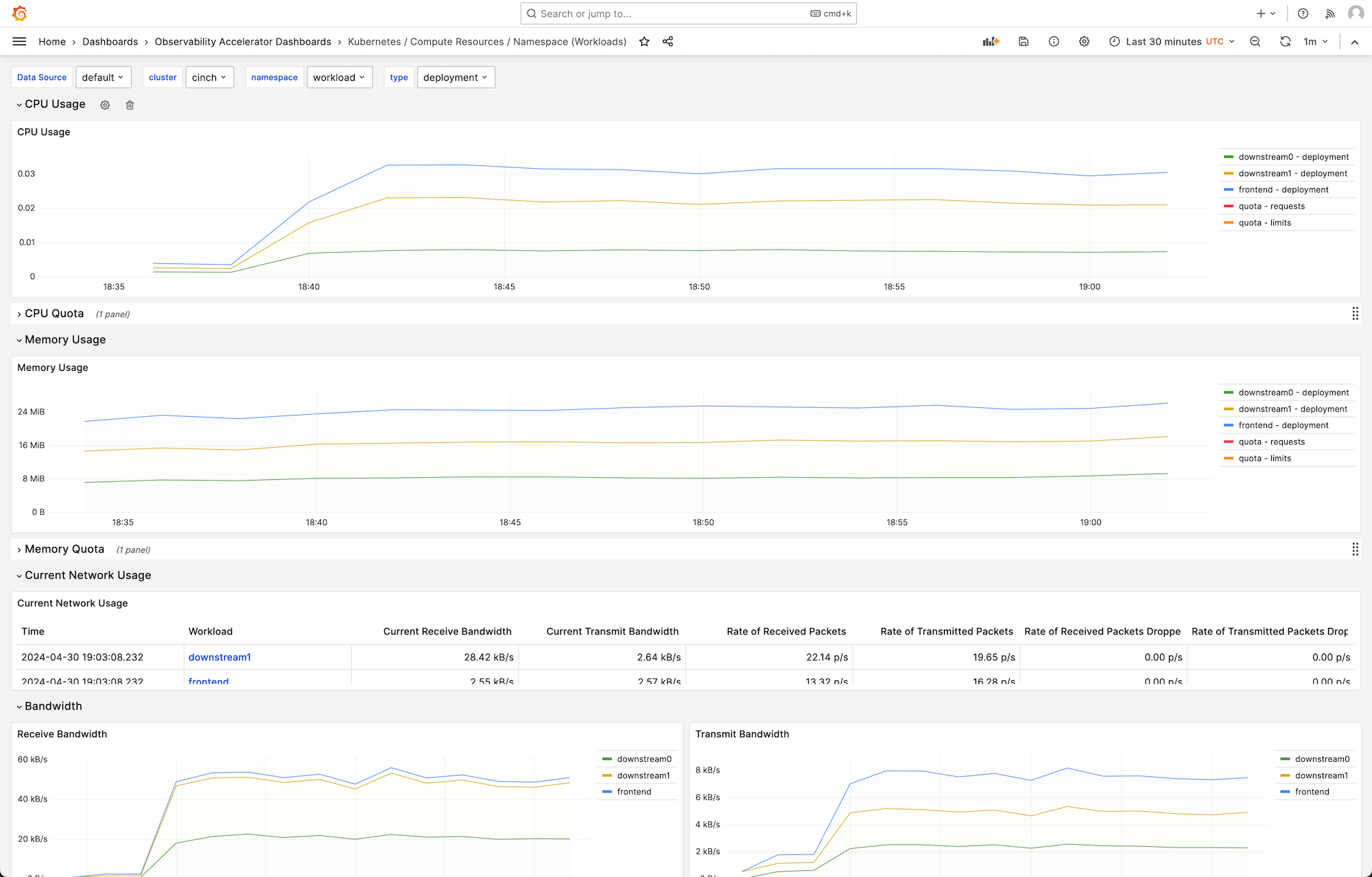
Die Metriken werden mit einem Scrape-Intervall von 1 Minute gescrapt. Die Dashboards zeigen Metriken, die auf der jeweiligen Metrik auf 1 Minute, 5 Minuten oder mehr zusammengefasst sind.
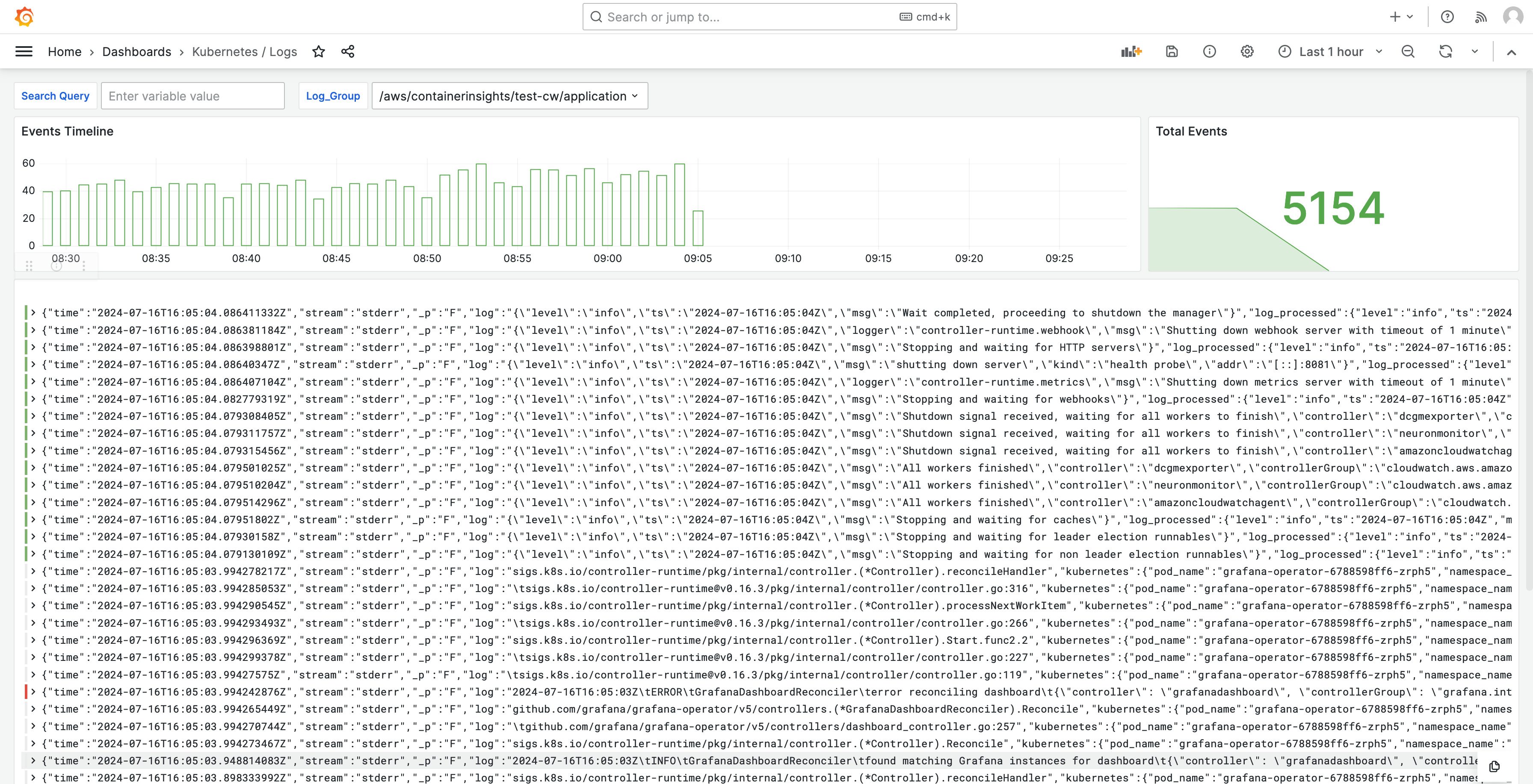
Protokolle werden auch in Dashboards angezeigt, sodass Sie Protokolle abfragen und analysieren können, um die Hauptursachen von Problemen zu finden. Die folgende Abbildung zeigt ein Protokoll-Dashboard.
Eine Liste der von dieser Lösung erfassten Metriken finden Sie unterListe der erfassten Metriken.
Eine Liste der von der Lösung erstellten Warnungen finden Sie unterListe der erstellten Alarme.
Kosten
Diese Lösung erstellt und verwendet Ressourcen in Ihrem Workspace. Ihnen wird die Standardnutzung der erstellten Ressourcen in Rechnung gestellt, einschließlich:
-
Zugriff auf Amazon Managed Grafana-Workspace durch Benutzer. Weitere Informationen zur Preisgestaltung finden Sie unter Amazon Managed Grafana-Preise
. -
Erfassung und Speicherung von Metriken durch Amazon Managed Service für Prometheus, einschließlich Nutzung des agentenlosen Sammlers Amazon Managed Service for Prometheus und Metrikanalyse (Verarbeitung von Abfrageproben). Die Anzahl der von dieser Lösung verwendeten Metriken hängt von der Konfiguration und Nutzung des Amazon EKS-Clusters ab.
Sie können die Aufnahme- und Speichermetriken in Amazon Managed Service for Prometheus unter Weitere Informationen finden Sie unter CloudWatch CloudWatchMetriken im Amazon Managed Service for Prometheus User Guide.
Sie können die Kosten mit dem Preisrechner auf der Preisseite von Amazon Managed Service für Prometheus
abschätzen. Die Anzahl der Metriken hängt von der Anzahl der Knoten in Ihrem Cluster und den Metriken ab, die Ihre Anwendungen erzeugen. -
CloudWatch Protokolliert Aufnahme, Speicherung und Analyse. Standardmäßig ist die Aufbewahrung von Protokollen so eingestellt, dass sie niemals abläuft. Sie können dies anpassen in CloudWatch. Weitere Informationen zur Preisgestaltung finden Sie unter CloudWatch Amazon-Preise
. -
Netzwerkkosten. Möglicherweise fallen AWS Standardnetzwerkgebühren für zonenübergreifenden, regionalen oder anderen Datenverkehr an.
Mithilfe der Preisrechner, die auf der Preisseite für jedes Produkt verfügbar sind, können Sie sich ein Bild über die potenziellen Kosten Ihrer Lösung machen. Die folgenden Informationen können Ihnen helfen, die Grundkosten für die Lösung zu ermitteln, die in derselben Availability Zone wie der Amazon EKS-Cluster ausgeführt wird.
| Produkt | Metrik für den Rechner | Wert |
|---|---|---|
Amazon Managed Service für Prometheus |
Aktive Serie |
8000 (Basis) 15.000 (pro Knoten) |
Durchschnittliches Erfassungsintervall |
60 (Sekunden) |
|
Amazon Managed Service für Prometheus (verwalteter Sammler) |
Anzahl der Sammler |
1 |
Anzahl der Proben |
15 (Basis) 150 (pro Knoten) |
|
Anzahl der Regeln |
161 |
|
Durchschnittliches Intervall zur Extraktion von Regeln |
60 (Sekunden) |
|
Amazon Managed Grafana |
Anzahl der aktiven editors/administrators |
1 (oder mehr, basierend auf Ihren Benutzern) |
CloudWatch (Protokolle) |
Standardprotokolle: Aufgenommene Daten |
24,5 GB (Basis) 0,5 GB (pro Knoten) |
Protokoll Storage/Archival (Standard- und Verkaufs-Protokolle) |
Ja, um Protokolle zu speichern: Es wird davon ausgegangen, dass sie 1 Monat aufbewahrt werden |
|
Erwartete Protokolle: Gescannte Daten |
Jede Log Insights-Abfrage von Grafana scannt alle Protokollinhalte der Gruppe über den angegebenen Zeitraum. |
Diese Zahlen sind die Basiszahlen für eine Lösung, auf der EKS ohne zusätzliche Software ausgeführt wird. Auf diese Weise erhalten Sie eine Schätzung der Grundkosten. Außerdem werden die Kosten für die Netzwerknutzung nicht berücksichtigt, die je nachdem, ob sich der Amazon Managed Grafana-Workspace, der Amazon Managed Service for Prometheus Workspace und der Amazon EKS-Cluster in derselben Availability Zone befinden AWS-Region, und VPN variieren.
Anmerkung
Wenn ein Element in dieser Tabelle einen (base) Wert und einen Wert pro Ressource enthält (z. B.(per node)), sollten Sie den Basiswert zum Wert pro Ressource multiplizieren mit der Anzahl, die Sie für diese Ressource haben, addieren. Geben Sie beispielsweise für Durchschnittliche aktive Zeitreihe eine Zahl ein, die ist8000 + the number of nodes in your cluster * 15,000. Wenn Sie 2 Knoten haben, würden Sie eingeben38,000, was ist8000 + ( 2 * 15,000 ).
Voraussetzungen
Für diese Lösung müssen Sie Folgendes getan haben, bevor Sie die Lösung verwenden können.
-
Sie müssen über einen Amazon Elastic Kubernetes Service Service-Cluster verfügen oder einen solchen erstellen, den Sie überwachen möchten, und der Cluster muss mindestens einen Knoten haben. Für den Cluster muss der Zugriff auf den API-Serverendpunkt so eingerichtet sein, dass er privaten Zugriff beinhaltet (er kann auch öffentlichen Zugriff zulassen).
Der Authentifizierungsmodus muss API-Zugriff beinhalten (er kann entweder auf
APIoder eingestellt werdenAPI_AND_CONFIG_MAP). Dadurch kann die Lösungsbereitstellung Zugriffseinträge verwenden.Folgendes sollte im Cluster installiert sein (standardmäßig wahr, wenn Sie den Cluster über die Konsole erstellen, muss aber hinzugefügt werden, wenn Sie den Cluster mithilfe der AWS API oder erstellen AWS CLI): AWS CNI, CoreDNS und. Kube-proxy AddOns
Speichern Sie den Clusternamen, um ihn später anzugeben. Dies finden Sie in den Cluster-Details in der Amazon EKS-Konsole.
Anmerkung
Einzelheiten zum Erstellen eines Amazon EKS-Clusters finden Sie unter Erste Schritte mit Amazon EKS.
-
Sie müssen einen Amazon Managed Service for Prometheus Workspace in derselben Umgebung AWS-Konto wie Ihr Amazon EKS-Cluster erstellen. Einzelheiten finden Sie unter Einen Workspace erstellen im Amazon Managed Service for Prometheus Benutzerhandbuch.
Speichern Sie den Workspace-ARN von Amazon Managed Service for Prometheus, um ihn später anzugeben.
-
Sie müssen einen Amazon Managed Grafana-Workspace mit Grafana-Version 9 oder neuer erstellen, genau AWS-Region wie Ihr Amazon EKS-Cluster. Einzelheiten zum Erstellen eines neuen Workspace finden Sie unter. Erstellen Sie einen Amazon Managed Grafana-Arbeitsbereich
Die Workspace-Rolle muss über Berechtigungen für den Zugriff auf Amazon Managed Service for Prometheus und Amazon CloudWatch APIs verfügen. Der einfachste Weg, dies zu tun, besteht darin, Service-managedBerechtigungen zu verwenden und Amazon Managed Service für Prometheus und auszuwählen. CloudWatch Sie können die AmazonGrafanaCloudWatchAccessRichtlinien AmazonPrometheusQueryAccessund auch manuell zu Ihrer Workspace-IAM-Rolle hinzufügen.
Speichern Sie die Amazon Managed Grafana-Workspace-ID und den Endpunkt, um sie später anzugeben. Die ID ist im Formular
g-123example. Die ID und der Endpunkt befinden sich in der Amazon Managed Grafana-Konsole. Der Endpunkt ist die URL für den Workspace und enthält die ID. Beispiel,https://g-123example.grafana-workspace.<region>.amazonaws.com/. -
Wenn Sie die Lösung mit Terraform bereitstellen, müssen Sie einen Amazon S3 S3-Bucket erstellen, auf den von Ihrem Konto aus zugegriffen werden kann. Dies wird verwendet, um Terraform-Statusdateien für die Bereitstellung zu speichern.
Speichern Sie die Amazon S3 S3-Bucket-ID, um sie später anzugeben.
-
Um die Warnregeln von Amazon Managed Service for Prometheus einzusehen, müssen Sie Grafana-Benachrichtigungen für den Amazon Managed Grafana-Arbeitsbereich aktivieren.
Darüber hinaus muss Amazon Managed Grafana über die folgenden Berechtigungen für Ihre Prometheus-Ressourcen verfügen. Sie müssen sie entweder zu den vom Service verwalteten oder den vom Kunden verwalteten Richtlinien hinzufügen, die unter Amazon Managed Grafana-Berechtigungen und Richtlinien für AWS Datenquellen beschrieben sind.
aps:ListRulesaps:ListAlertManagerSilencesaps:ListAlertManagerAlertsaps:GetAlertManagerStatusaps:ListAlertManagerAlertGroupsaps:PutAlertManagerSilencesaps:DeleteAlertManagerSilence
Anmerkung
Die Einrichtung der Lösung ist zwar nicht unbedingt erforderlich, Sie müssen jedoch die Benutzerauthentifizierung in Ihrem Amazon Managed Grafana-Arbeitsbereich einrichten, bevor Benutzer auf die erstellten Dashboards zugreifen können. Weitere Informationen finden Sie unter Authentifizieren Sie Benutzer in Amazon Managed Grafana-Arbeitsbereichen.
Verwenden Sie diese Lösung
Diese Lösung konfiguriert die AWS Infrastruktur so, dass sie Berichts- und Überwachungsmetriken aus einem Amazon EKS-Cluster unterstützt. Sie können sie entweder mit AWS Cloud Development Kit (AWS CDK)oder mit Terraform
Liste der erfassten Metriken
Diese Lösung erstellt einen Scraper, der Metriken aus Ihrem Amazon EKS-Cluster sammelt. Diese Metriken werden in Amazon Managed Service for Prometheus gespeichert und dann in Amazon Managed Grafana-Dashboards angezeigt. Standardmäßig sammelt der Scraper alle Prometheus-compatible Metriken, die vom Cluster verfügbar gemacht werden. Durch die Installation von Software in Ihrem Cluster, die mehr Metriken erzeugt, werden die gesammelten Metriken erhöht. Wenn Sie möchten, können Sie die Anzahl der Metriken reduzieren, indem Sie den Scraper mit einer Konfiguration aktualisieren, die die Metriken filtert.
Die folgenden Metriken werden mit dieser Lösung in einer Amazon EKS-Cluster-Basiskonfiguration ohne Installation zusätzlicher Software verfolgt.
| Metrik | Beschreibung/Zweck |
|---|---|
|
|
Anzeige der als nicht verfügbar markierten APIServices, aufgeschlüsselt nach APIService-Namen. |
|
|
Histogramm der Webhook-Latenz bei der Zulassung in Sekunden, identifiziert anhand des Namens und aufgeschlüsselt nach Vorgang, API-Ressource und Typ (validieren oder zulassen). |
|
|
Maximale Anzahl der aktuell verwendeten Inflight-Anfragen für diesen Apiserver pro Anforderungsart in letzter Sekunde. |
|
|
Prozent der Cache-Steckplätze, die derzeit von zwischengespeicherten DEKs belegt sind. |
|
|
Anzahl der Anfragen in der ersten Ausführungsphase (für eine WATCH) oder einer beliebigen Ausführungsphase (für eine Nicht-WATCH) Ausführungsphase im API-Subsystem Priority and Fairness. |
|
|
Anzahl der Anfragen in der ersten (für eine WATCH) oder einer beliebigen Ausführungsphase (für eine Nicht-WATCH) Ausführungsphase im API-Subsystem Priority and Fairness, die abgelehnt wurden. |
|
|
Nominale Anzahl von Ausführungsplätzen, die für jede Prioritätsstufe konfiguriert sind. |
|
|
Das gestaffelte Histogramm der Dauer der Anfangsphase (für eine WATCH) oder einer beliebigen Phase (für eine Nicht-WATCH) Phase der Anforderungsausführung im API-Subsystem Priority and Fairness. |
|
|
Die Anzahl der Anfangsphasen (für eine WATCH) oder einer beliebigen Phase (für eine Nicht-WATCH) Phase der Anforderungsausführung im API-Subsystem Priority and Fairness. |
|
|
Weist auf eine API-Serveranfrage hin. |
|
|
Anzeige der angeforderten veralteten APIs, aufgeschlüsselt nach API-Gruppe, Version, Ressource, Unterressource und removed_release. |
|
|
Verteilung der Antwortlatenz in Sekunden für jedes Verb, jeden Probelauf, jede Gruppe, Version, Ressource, Unterressource, jeden Bereich und jede Komponente. |
|
|
Das kombinierte Histogramm der Verteilung der Antwortlatenz in Sekunden für jedes Verb, jeden Probelaufwert, jede Gruppe, Version, Ressource, Unterressource, jeden Bereich und jede Komponente. |
|
|
Die Verteilung der Antwortlatenz nach Service Level Objective (SLO) in Sekunden für jedes Verb, jeden Probelauf, jede Gruppe, Version, Ressource, Unterressource, jeden Bereich und jede Komponente. |
|
|
Anzahl der Anfragen, die Apiserver aus Notwehr beendet hat. |
|
|
Zähler der Apiserver-Anfragen, aufgeschlüsselt nach Verb, Probelaufwert, Gruppe, Version, Ressource, Bereich, Komponente und HTTP-Antwortcode. |
|
|
Kumulierte verbrauchte CPU-Zeit. |
|
|
Kumulative Anzahl der gelesenen Byte. |
|
|
Gesamtzahl der abgeschlossenen Lesevorgänge. |
|
|
Kumulierte Anzahl der geschriebenen Byte. |
|
|
Kumulierte Anzahl der abgeschlossenen Schreibvorgänge. |
|
|
Gesamter Seitencache-Speicher. |
|
|
Größe von RSS. |
|
|
Nutzung von Container-Swaps. |
|
|
Aktueller Arbeitssatz. |
|
|
Kumulierte Anzahl der empfangenen Byte. |
|
|
Kumulierte Anzahl der Pakete, die beim Empfang verloren gegangen sind. |
|
|
Kumulierte Anzahl der empfangenen Pakete. |
|
|
Kumulierte Anzahl der übertragenen Byte. |
|
|
Kumulierte Anzahl von Paketen, die bei der Übertragung verloren gegangen sind. |
|
|
Kumulierte Anzahl der übertragenen Pakete. |
|
|
Das gebündelte Histogramm der etcd-Anforderungslatenz in Sekunden für jeden Vorgang und Objekttyp. |
|
|
Anzahl der Goroutinen, die derzeit existieren. |
|
|
Anzahl der erstellten Betriebssystem-Threads. |
|
|
Das gestaffelte Histogramm der Dauer in Sekunden für Cgroup Manager-Operationen. Aufgeschlüsselt nach Methode. |
|
|
Dauer in Sekunden für Gruppenmanager-Operationen. Aufgeschlüsselt nach Methode. |
|
|
Diese Metrik ist wahr (1), wenn auf dem Knoten ein konfigurationsbedingter Fehler auftritt, andernfalls falsch (0). |
|
|
Der Name des Knotens. Die Anzahl ist immer 1. |
|
|
Das gestaffelte Histogramm der Dauer in Sekunden für das Wiedereinstellen von Pods in PLEG. |
|
|
Die Anzahl der Dauer in Sekunden für das Wiedereinstellen von Pods in PLEG. |
|
|
Das gestaffelte Histogramm des Intervalls in Sekunden zwischen dem Wiedereinstellen in PLEG. |
|
|
Die Anzahl der Zeiträume in Sekunden zwischen dem ersten Erkennen eines Pods durch Kubelet und dem Starten des Pods. |
|
|
Das zusammengefasste Histogramm der Dauer in Sekunden für die Synchronisierung eines einzelnen Pods. Aufgeschlüsselt nach Vorgangstyp: Erstellen, Aktualisieren oder Synchronisieren. |
|
|
Die Anzahl der für die Synchronisierung eines einzelnen Pods erforderlichen Dauer in Sekunden. Aufgeschlüsselt nach Vorgangstyp: Erstellen, Aktualisieren oder Synchronisieren. |
|
|
Anzahl der aktuell laufenden Container. |
|
|
Anzahl der Pods, auf denen eine Pod-Sandbox läuft. |
|
|
Das gestaffelte Histogramm der Dauer von Laufzeitvorgängen in Sekunden. Aufgeschlüsselt nach Vorgangstyp. |
|
|
Kumulierte Anzahl von Laufzeitvorgangsfehlern nach Vorgangstyp. |
|
|
Kumulierte Anzahl von Laufzeitoperationen nach Vorgangstyp. |
|
|
Die Menge der Ressourcen, die Pods zugewiesen werden können (nachdem einige Ressourcen für System-Daemons reserviert wurden). |
|
|
Die Gesamtmenge der für einen Knoten verfügbaren Ressourcen. |
|
|
Die Anzahl der von einem Container angeforderten Limit-Ressourcen. |
|
|
Die Anzahl der von einem Container angeforderten Limitressourcen. |
|
|
Die Anzahl der von einem Container angeforderten Anforderungsressourcen. |
|
|
Die Anzahl der von einem Container angeforderten Anforderungsressourcen. |
|
|
Informationen über den Besitzer des Pods. |
|
|
Ressourcenkontingente in Kubernetes setzen Nutzungsbeschränkungen für Ressourcen wie CPU, Arbeitsspeicher und Speicher innerhalb von Namespaces durch. |
|
|
Die CPU-Nutzungsmetriken für einen Knoten, einschließlich der Nutzung pro Kern und der Gesamtnutzung. |
|
|
Sekunden, die die CPUs in jedem Modus verbracht haben. |
|
|
Die kumulierte Zeit, die ein Knoten für die Ausführung von I/O Vorgängen auf der Festplatte aufgewendet hat. |
|
|
Die Gesamtzeit, die der Knoten für die Ausführung von I/O Vorgängen auf der Festplatte aufgewendet hat. |
|
|
Die Gesamtzahl der vom Knoten von der Festplatte gelesenen Byte. |
|
|
Die Gesamtzahl der vom Knoten auf die Festplatte geschriebenen Byte. |
|
|
Die Menge des verfügbaren Speicherplatzes in Byte im Dateisystem eines Knotens in einem Kubernetes-Cluster. |
|
|
Die Gesamtgröße des Dateisystems auf dem Knoten. |
|
|
Der 1-Minuten-Durchschnitt der CPU-Auslastung eines Knotens. |
|
|
Der 15-minütige Lastdurchschnitt der CPU-Auslastung eines Knotens. |
|
|
Der 5-Minuten-Durchschnitt der CPU-Auslastung eines Knotens. |
|
|
Die Speichermenge, die vom Betriebssystem des Knotens für das Puffer-Caching verwendet wird. |
|
|
Die Speichermenge, die vom Betriebssystem des Knotens für das Festplatten-Caching verwendet wird. |
|
|
Die Menge an Arbeitsspeicher, die von Anwendungen und Caches verwendet werden kann. |
|
|
Die Menge an freiem Speicher, der auf dem Knoten verfügbar ist. |
|
|
Die Gesamtmenge des auf dem Knoten verfügbaren physischen Speichers. |
|
|
Die Gesamtzahl der Byte, die der Knoten über das Netzwerk empfangen hat. |
|
|
Die Gesamtzahl der vom Knoten über das Netzwerk übertragenen Byte. |
|
|
Die gesamte verbrauchte CPU-Zeit von Benutzer und System in Sekunden. |
|
|
Größe des residenten Speichers in Byte. |
|
|
Anzahl der HTTP-Anfragen, partitioniert nach Statuscode, Methode und Host. |
|
|
Das kombinierte Histogramm der Anforderungslatenz in Sekunden. Aufgeschlüsselt nach Verb und Host. |
|
|
Das kombinierte Histogramm der Dauer von Speichervorgängen. |
|
|
Die Anzahl der Dauer von Speichervorgängen. |
|
|
Kumulierte Anzahl von Fehlern bei Speichervorgängen. |
|
|
Eine Metrik, die angibt, ob das überwachte Ziel (z. B. der Knoten) betriebsbereit ist. |
|
|
Die Gesamtzahl der vom Volume Manager verwalteten Volumes. |
|
|
Gesamtzahl der von der Workqueue bearbeiteten Hinzufügungen. |
|
|
Aktuelle Tiefe der Arbeitswarteschlange. |
|
|
Das kombinierte Histogramm, das angibt, wie lange (in Sekunden) ein Element in der Arbeitswarteschlange verbleibt, bevor es angefordert wird. |
|
|
Das Buckethistogramm, das angibt, wie lange in Sekunden die Bearbeitung eines Elements aus der Arbeitswarteschlange dauert. |
Liste der erstellten Alarme
In den folgenden Tabellen sind die Warnungen aufgeführt, die mit dieser Lösung erstellt wurden. Die Benachrichtigungen werden als Regeln in Amazon Managed Service für Prometheus erstellt und in Ihrem Amazon Managed Grafana-Arbeitsbereich angezeigt.
Sie können die Regeln ändern, einschließlich des Hinzufügens oder Löschens von Regeln, indem Sie die Regelkonfigurationsdatei in Ihrem Amazon Managed Service for Prometheus-Workspace bearbeiten.
Bei diesen beiden Alerts handelt es sich um spezielle Alerts, die etwas anders behandelt werden als typische Alerts. Anstatt Sie auf ein Problem aufmerksam zu machen, geben sie Ihnen Informationen, die zur Überwachung des Systems verwendet werden. Die Beschreibung enthält Einzelheiten zur Verwendung dieser Benachrichtigungen.
| Warnung | Beschreibung und Verwendung |
|---|---|
|
Mit dieser Warnung soll sichergestellt werden, dass die gesamte Warnungspipeline funktionsfähig ist. Diese Warnung wird immer ausgelöst, daher sollte sie immer im Alertmanager und immer gegen einen Empfänger ausgelöst werden. Sie können dies in Ihren Benachrichtigungsmechanismus integrieren, um eine Benachrichtigung zu senden, wenn dieser Alarm nicht ausgelöst wird. Sie könnten die DeadMansSnitchIntegration beispielsweise in verwenden PagerDuty. |
|
Dies ist eine Warnung, die verwendet wird, um Informationswarnungen zu verhindern. Warnmeldungen auf Informationsebene können für sich genommen sehr laut sein, aber sie sind relevant, wenn sie mit anderen Warnmeldungen kombiniert werden. Diese Warnung wird ausgelöst, wenn eine |
Die folgenden Warnmeldungen geben Ihnen Informationen oder Warnungen zu Ihrem System.
| Warnung | Schweregrad | Description |
|---|---|---|
|
|
warning |
Die Netzwerkschnittstelle ändert häufig ihren Status |
|
|
warning |
Es wird prognostiziert, dass im Dateisystem innerhalb der nächsten 24 Stunden nicht mehr genügend Speicherplatz zur Verfügung steht. |
|
|
critical |
Es wird prognostiziert, dass dem Dateisystem innerhalb der nächsten 4 Stunden der Speicherplatz ausgeht. |
|
|
warning |
Im Dateisystem sind weniger als 5% Speicherplatz übrig. |
|
|
critical |
Im Dateisystem sind weniger als 3% Speicherplatz übrig. |
|
|
warning |
Es wird prognostiziert, dass dem Dateisystem innerhalb der nächsten 24 Stunden die Inodes ausgehen werden. |
|
|
critical |
Es wird prognostiziert, dass dem Dateisystem innerhalb der nächsten 4 Stunden die Inodes ausgehen werden. |
|
|
warning |
Im Dateisystem sind weniger als 5% Inodes übrig. |
|
|
critical |
Das Dateisystem hat noch weniger als 3% Inodes übrig. |
|
|
warning |
Die Netzwerkschnittstelle meldet viele Empfangsfehler. |
|
|
warning |
Die Netzwerkschnittstelle meldet viele Übertragungsfehler. |
|
|
warning |
Die Anzahl der Conntrack-Einträge nähert sich dem Limit. |
|
|
warning |
Der Node Exporter Exporter-Textdatei-Collector konnte nicht gescrapt werden. |
|
|
warning |
Eine Zeitversetzung wurde festgestellt. |
|
|
warning |
Die Uhr wird nicht synchronisiert. |
|
|
critical |
Das RAID-Array ist heruntergestuft |
|
|
warning |
Gerät im RAID-Array ausgefallen |
|
|
warning |
Der Kernel wird voraussichtlich bald das Limit für Dateideskriptoren erschöpfen. |
|
|
critical |
Es wird vorausgesagt, dass der Kernel das Limit für Dateideskriptoren bald erschöpft. |
|
|
warning |
Der Knoten ist nicht bereit. |
|
|
warning |
Der Knoten ist nicht erreichbar. |
|
|
info |
Kubelet ist voll ausgelastet. |
|
|
warning |
Der Bereitschaftsstatus des Knotens schwankt. |
|
|
warning |
Das Wiederauflisten des Kubelet Pod Lifecycle Event Generator dauert zu lange. |
|
|
warning |
Die Startlatenz des Kubelet Pod ist zu hoch. |
|
|
warning |
Das Kubelet-Client-Zertifikat läuft bald ab. |
|
|
critical |
Das Kubelet-Client-Zertifikat läuft bald ab. |
|
|
warning |
Das Kubelet-Serverzertifikat läuft bald ab. |
|
|
critical |
Das Kubelet-Serverzertifikat läuft bald ab. |
|
|
warning |
Kubelet konnte sein Client-Zertifikat nicht erneuern. |
|
|
warning |
Kubelet konnte sein Serverzertifikat nicht erneuern. |
|
|
critical |
Target ist aus Prometheus Target Discovery verschwunden. |
|
|
warning |
Verschiedene semantische Versionen von Kubernetes-Komponenten werden ausgeführt. |
|
|
warning |
Beim Kubernetes-API-Serverclient treten Fehler auf. |
|
|
warning |
Das Client-Zertifikat läuft bald ab. |
|
|
critical |
Das Client-Zertifikat läuft bald ab. |
|
|
warning |
Die aggregierte Kubernetes-API hat Fehler gemeldet. |
|
|
warning |
Die aggregierte Kubernetes-API ist ausgefallen. |
|
|
critical |
Target ist aus Prometheus Target Discovery verschwunden. |
|
|
warning |
Der Kubernetes-Apiserver hat {{$value | humanizePercentage}} seiner eingehenden Anfragen beendet. |
|
|
critical |
Das persistente Volumen füllt sich. |
|
|
warning |
Persistent Volume füllt sich. |
|
|
critical |
Persistent Volume Inodes füllt sich. |
|
|
warning |
Persistent Volume Inodes füllen sich. |
|
|
critical |
Persistent Volume hat Probleme mit der Bereitstellung. |
|
|
warning |
Der Cluster hat zu viele CPU-Ressourcenanforderungen zugewiesen. |
|
|
warning |
Der Cluster hat zu viele Speicherressourcenanforderungen zugewiesen. |
|
|
warning |
Der Cluster hat zu viele CPU-Ressourcenanforderungen zugewiesen. |
|
|
warning |
Der Cluster hat zu viele Speicherressourcenanforderungen zugewiesen. |
|
|
info |
Das Namespace-Kontingent wird voll sein. |
|
|
info |
Das Namespace-Kontingent ist vollständig ausgeschöpft. |
|
|
warning |
Das Namespace-Kontingent hat die Grenzwerte überschritten. |
|
|
info |
Bei Prozessen kommt es zu einer erhöhten CPU-Drosselung. |
|
|
warning |
Der Pod stürzt in einer Schleife ab. |
|
|
warning |
Der Pod befindet sich seit mehr als 15 Minuten in einem nicht betriebsbereiten Zustand. |
|
|
warning |
Die Generierung der Bereitstellung stimmt aufgrund eines möglichen Rollbacks nicht überein |
|
|
warning |
Die Bereitstellung entsprach nicht der erwarteten Anzahl von Replikaten. |
|
|
warning |
StatefulSet hat nicht die erwartete Anzahl von Replikaten erreicht. |
|
|
warning |
StatefulSet Generationenkonflikt aufgrund eines möglichen Rollbacks |
|
|
warning |
StatefulSet Das Update wurde nicht eingeführt. |
|
|
warning |
DaemonSet Der Rollout steckt fest. |
|
|
warning |
Der Pod-Container wartet länger als 1 Stunde |
|
|
warning |
DaemonSet Pods sind nicht geplant. |
|
|
warning |
DaemonSet Pods sind falsch geplant. |
|
|
warning |
Job wurde nicht rechtzeitig abgeschlossen |
|
|
warning |
Der Job konnte nicht abgeschlossen werden. |
|
|
warning |
HPA hat die gewünschte Anzahl von Replikaten nicht gefunden. |
|
|
warning |
HPA wird mit der maximalen Anzahl von Replikaten ausgeführt |
|
|
critical |
Bei kube-state-metrics treten Fehler bei Listenoperationen auf. |
|
|
critical |
Bei kube-state-metrics treten Fehler bei Watch-Vorgängen auf. |
|
|
critical |
Das Sharding von kube-state-metrics ist falsch konfiguriert. |
|
|
critical |
Kube-State-Metrics-Shards fehlen. |
|
|
critical |
Der API-Server verbraucht zu viel Fehlerbudget. |
|
|
critical |
Der API-Server verbraucht zu viel Fehlerbudget. |
|
|
warning |
Der API-Server verbraucht zu viel Fehlerbudget. |
|
|
warning |
Der API-Server verbraucht zu viel Fehlerbudget. |
|
|
warning |
Ein oder mehrere Ziele sind ausgefallen. |
|
|
critical |
Etcd-Cluster hat nicht genügend Mitglieder. |
|
|
warning |
Etcd-Cluster, hohe Anzahl von Führungswechsel. |
|
|
critical |
Der Etcd-Cluster hat keinen Anführer. |
|
|
warning |
Etcd-Cluster mit hoher Anzahl fehlgeschlagener gRPC-Anfragen. |
|
|
critical |
Etcd-Cluster-gRPC-Anfragen sind langsam. |
|
|
warning |
Die Kommunikation der Etcd-Clustermitglieder ist langsam. |
|
|
warning |
Etcd-Cluster mit hoher Anzahl fehlgeschlagener Vorschläge. |
|
|
warning |
Etcd-Cluster mit hoher Fsync-Dauer. |
|
|
warning |
Der Etcd-Cluster hat eine höhere Commit-Dauer als erwartet. |
|
|
warning |
Der Etcd-Cluster hat HTTP-Anfragen nicht bestanden. |
|
|
critical |
Der Etcd-Cluster hat eine hohe Anzahl fehlgeschlagener HTTP-Anfragen. |
|
|
warning |
Etcd-Cluster-HTTP-Anfragen sind langsam. |
|
|
warning |
Die Host-Uhr wird nicht synchronisiert. |
|
|
warning |
Host-OOM-Kill erkannt. |
Fehlerbehebung
Es gibt einige Dinge, die dazu führen können, dass die Einrichtung des Projekts fehlschlägt. Stellen Sie sicher, dass Sie Folgendes überprüfen.
-
Sie müssen alle Voraussetzungen erfüllen, bevor Sie die Lösung installieren können.
-
Der Cluster muss mindestens einen Knoten enthalten, bevor Sie versuchen können, die Lösung zu erstellen oder auf die Metriken zuzugreifen.
-
In Ihrem Amazon EKS-Cluster müssen die
AWS CNICoreDNSundkube-proxyAdd-Ons installiert sein. Wenn sie nicht installiert sind, funktioniert die Lösung nicht richtig. Sie werden standardmäßig installiert, wenn der Cluster über die Konsole erstellt wird. Möglicherweise müssen Sie sie installieren, wenn der Cluster über ein AWS SDK erstellt wurde. -
Bei der Installation der Amazon EKS-Pods wurde das Zeitlimit überschritten. Dies kann passieren, wenn nicht genügend Knotenkapazität verfügbar ist. Es gibt mehrere Ursachen für diese Probleme, darunter:
-
Der Amazon EKS-Cluster wurde mit Fargate statt mit Amazon EC2 initialisiert. Für dieses Projekt ist Amazon EC2 erforderlich.
-
Die Knoten sind beschädigt und daher nicht verfügbar.
Sie können sie verwenden
kubectl describe node, um die Makel zu überprüfen. DannNODENAME| grep Taintskubectl taint nodeum die Flecken zu entfernen. Stellen Sie sicher, dass SieNODENAMETAINT_NAME--nach dem Namen des Makels den Namen angeben. -
Die Knoten haben die Kapazitätsgrenze erreicht. In diesem Fall können Sie einen neuen Knoten erstellen oder die Kapazität erhöhen.
-
-
Sie sehen in Grafana keine Dashboards: Sie verwenden die falsche Grafana-Workspace-ID.
Führen Sie den folgenden Befehl aus, um Informationen über Grafana zu erhalten:
kubectl describe grafanas external-grafana -n grafana-operatorSie können die Ergebnisse auf die richtige Workspace-URL überprüfen. Wenn es sich nicht um die erwartete handelt, führen Sie die Bereitstellung erneut mit der richtigen Workspace-ID durch.
Spec: External: API Key: Key: GF_SECURITY_ADMIN_APIKEY Name: grafana-admin-credentials URL: https://g-123example.grafana-workspace.aws-region.amazonaws.com Status: Admin URL: https://g-123example.grafana-workspace.aws-region.amazonaws.com Dashboards: ... -
In Grafana werden keine Dashboards angezeigt: Sie verwenden einen abgelaufenen API-Schlüssel.
Um nach diesem Fall zu suchen, müssen Sie den Grafana-Operator aufrufen und die Protokolle auf Fehler überprüfen. Rufen Sie den Namen des Grafana-Operators mit diesem Befehl ab:
kubectl get pods -n grafana-operatorDadurch wird der Name des Operators zurückgegeben, zum Beispiel:
NAME READY STATUS RESTARTS AGEgrafana-operator-1234abcd5678ef901/1 Running 0 1h2mVerwenden Sie den Operatornamen im folgenden Befehl:
kubectl logsgrafana-operator-1234abcd5678ef90-n grafana-operatorFehlermeldungen wie die folgenden weisen auf einen abgelaufenen API-Schlüssel hin:
ERROR error reconciling datasource {"controller": "grafanadatasource", "controllerGroup": "grafana.integreatly.org", "controllerKind": "GrafanaDatasource", "GrafanaDatasource": {"name":"grafanadatasource-sample-amp","namespace":"grafana-operator"}, "namespace": "grafana-operator", "name": "grafanadatasource-sample-amp", "reconcileID": "72cfd60c-a255-44a1-bfbd-88b0cbc4f90c", "datasource": "grafanadatasource-sample-amp", "grafana": "external-grafana", "error": "status: 401, body: {\"message\":\"Expired API key\"}\n"} github.com/grafana-operator/grafana-operator/controllers.(*GrafanaDatasourceReconciler).ReconcileErstellen Sie in diesem Fall einen neuen API-Schlüssel und stellen Sie die Lösung erneut bereit. Wenn das Problem weiterhin besteht, können Sie vor der erneuten Bereitstellung die Synchronisation mithilfe des folgenden Befehls erzwingen:
kubectl delete externalsecret/external-secrets-sm -n grafana-operator -
CDK-Installationen — Fehlender SSM-Parameter. Wenn Sie einen Fehler wie den folgenden sehen, führen Sie ihn aus
cdk bootstrapund versuchen Sie es erneut.Deployment failed: Error: aws-observability-solution-eks-infra-$EKS_CLUSTER_NAME: SSM parameter /cdk-bootstrap/xxxxxxx/version not found. Has the environment been bootstrapped? Please run 'cdk bootstrap' (see https://docs.aws.amazon.com/cdk/latest/ guide/bootstrapping.html) -
Die Bereitstellung kann fehlschlagen, wenn der OIDC-Anbieter bereits vorhanden ist. Es wird ein Fehler wie der folgende angezeigt (in diesem Fall bei CDK-Installationen):
| CREATE_FAILED | Custom::AWSCDKOpenIdConnectProvider | OIDCProvider/Resource/Default Received response status [FAILED] from custom resource. Message returned: EntityAlreadyExistsException: Provider with url https://oidc.eks.REGION.amazonaws.com/id/PROVIDER IDalready exists.Gehen Sie in diesem Fall zum IAM-Portal, löschen Sie den OIDC-Anbieter und versuchen Sie es erneut.
-
Terraform-Installationen — Es wird eine Fehlermeldung angezeigt, die und enthält.
cluster-secretstore-sm failed to create kubernetes rest client for update of resourcefailed to create kubernetes rest client for update of resourceDieser Fehler weist normalerweise darauf hin, dass der External Secrets Operator in Ihrem Kubernetes-Cluster nicht installiert oder aktiviert ist. Dieser wird als Teil der Lösungsbereitstellung installiert, ist aber manchmal nicht bereit, wenn die Lösung ihn benötigt.
Sie können mit dem folgenden Befehl überprüfen, ob sie installiert ist:
kubectl get deployments -n external-secretsWenn es installiert ist, kann es einige Zeit dauern, bis der Bediener vollständig einsatzbereit ist. Sie können den Status der benötigten benutzerdefinierten Ressourcendefinitionen (CRDs) überprüfen, indem Sie den folgenden Befehl ausführen:
kubectl get crds|grep external-secretsDieser Befehl sollte die CRDs auflisten, die sich auf den Operator für externe Geheimnisse beziehen, einschließlich
clustersecretstores.external-secrets.iound.externalsecrets.external-secrets.ioWenn sie nicht aufgeführt sind, warten Sie ein paar Minuten und überprüfen Sie es erneut.Sobald die CRDs registriert sind, können Sie sie
terraform applyerneut ausführen, um die Lösung bereitzustellen.
