Hinweis zum Ende des Supports: Am 7. Oktober 2026 AWS wird der Support für eingestellt.AWS IoT Greengrass Version 1 Nach dem 7. Oktober 2026 können Sie nicht mehr auf die Ressourcen zugreifen.AWS IoT Greengrass V1 Weitere Informationen finden Sie unter Migrieren von AWS IoT Greengrass Version 1.
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Optional: Konfigurieren des Geräts für die ML-Qualifizierung
IDT for AWS IoT Greengrass bietet Qualifizierungstests für maschinelles Lernen (ML) an, um zu überprüfen, ob Ihre Geräte ML-Inferenz lokal mithilfe von Cloud-trainierten Modellen durchführen können.
Um ML-Qualifizierungstests ausführen zu können, müssen Sie zunächst Ihre Geräte wie unter Konfigurieren Sie Ihr Gerät für die Ausführung von IDT-Tests beschrieben konfigurieren. Führen Sie dann die Schritte in diesem Thema aus, um Abhängigkeiten für die ML-Frameworks zu installieren, die Sie ausführen möchten.
Zum Ausführen von Tests für die ML-Qualifizierung ist IDT v3.1.0 oder höher erforderlich.
Installieren von Abhängigkeiten für ML-Frameworks
Alle Abhängigkeiten für ML-Frameworks müssen im Verzeichnis /usr/local/lib/python3.x/site-packages installiert werden. Um sicherzustellen, dass sie im richtigen Verzeichnis installiert sind, empfehlen wir, bei der Installation der Abhängigkeiten sudo-Root-Berechtigungen zu verwenden. Virtuelle Umgebungen werden für Qualifizierungstests nicht unterstützt.
Anmerkung
Wenn Sie Lambda-Funktionen testen, die mit Containerisierung (im Greengrass-Containermodus) ausgeführt werden, wird das Erstellen von Symlinks für Python-Bibliotheken unter nicht unterstützt. /usr/local/lib/python3.x Um Fehler zu vermeiden, müssen Sie die Abhängigkeiten im richtigen Verzeichnis installieren.
Führen Sie die Schritte aus, um die Abhängigkeiten für Ihr Ziel-Framework zu installieren:
Installieren von Apache MXNet-Abhängigkeiten
IDT-Qualifizierungstests für dieses Framework haben folgende Abhängigkeiten:
-
Python 3.6 oder Python 3.7.
Anmerkung
Wenn Sie Python 3.6 verwenden, müssen Sie einen symbolischen Link von Python 3.7- zu Python 3.6 Binärdateien erstellen. Dadurch wird Ihr Gerät so konfiguriert, dass es die Python-Anforderung für AWS IoT Greengrass erfüllt. Beispiel:
sudo ln -spath-to-python-3.6/python3.6path-to-python-3.7/python3.7 -
Apache MXNet v1.2.1 oder höher.
-
NumPy. Die Version muss mit Ihrer MXNet-Version kompatibel sein.
Installieren von MXNet
Befolgen Sie die Anweisungen in der MXNet-Dokumentation, um MXNet zu installieren
Anmerkung
Wenn sowohl Python 2.x als auch Python 3.x auf Ihrem Gerät installiert ist, verwenden Sie Python 3.x in den Befehlen, die Sie zum Installieren der Abhängigkeiten ausführen.
Validieren der MXNet-Installation
Wählen Sie eine der folgenden Optionen, um die MXNet-Installation zu validieren.
Option 1: SSH in Ihr Gerät integrieren und Skripts ausführen
-
Integrieren Sie SSH in Ihr Gerät.
-
Führen Sie die folgenden Skripts aus, um zu überprüfen, ob die Abhängigkeiten korrekt installiert sind.
sudo python3.7 -c "import mxnet; print(mxnet.__version__)"sudo python3.7 -c "import numpy; print(numpy.__version__)"Die Ausgabe gibt die Versionsnummer aus und das Skript sollte fehlerfrei beendet werden.
Option 2: IDT-Abhängigkeitstest ausführen
-
Stellen Sie sicher, dass
device.jsonfür die ML-Qualifizierung konfiguriert ist. Weitere Informationen finden Sie unter Konfigurieren von device.json für die ML-Qualifizierung. -
Führen Sie den Abhängigkeitstest für das Framework aus.
devicetester_[linux | mac | win_x86-64]run-suite --group-id mldependencies --test-id mxnet_dependency_checkIn der Testzusammenfassung wird das Ergebnis
PASSEDfürmldependenciesangezeigt.
Installieren Sie Abhängigkeiten TensorFlow
IDT-Qualifizierungstests für dieses Framework haben folgende Abhängigkeiten:
-
Python 3.6 oder Python 3.7.
Anmerkung
Wenn Sie Python 3.6 verwenden, müssen Sie einen symbolischen Link von Python 3.7- zu Python 3.6 Binärdateien erstellen. Dadurch wird Ihr Gerät so konfiguriert, dass es die Python-Anforderung für AWS IoT Greengrass erfüllt. Beispiel:
sudo ln -spath-to-python-3.6/python3.6path-to-python-3.7/python3.7 -
TensorFlow 1.x.
Wird installiert TensorFlow
Folgen Sie den Anweisungen in der TensorFlow Dokumentation, um TensorFlow 1.x mit Pip
Anmerkung
Wenn sowohl Python 2.x als auch Python 3.x auf Ihrem Gerät installiert ist, verwenden Sie Python 3.x in den Befehlen, die Sie zum Installieren der Abhängigkeiten ausführen.
Die Installation wird validiert TensorFlow
Wählen Sie eine der folgenden Optionen, um die TensorFlow Installation zu validieren.
Option 1: SSH in Ihr Gerät integrieren und ein Skript ausführen
-
Integrieren Sie SSH in Ihr Gerät.
-
Führen Sie das folgende Skript aus, um zu überprüfen, ob die Abhängigkeit korrekt installiert ist.
sudo python3.7 -c "import tensorflow; print(tensorflow.__version__)"Die Ausgabe gibt die Versionsnummer aus und das Skript sollte fehlerfrei beendet werden.
Option 2: IDT-Abhängigkeitstest ausführen
-
Stellen Sie sicher, dass
device.jsonfür die ML-Qualifizierung konfiguriert ist. Weitere Informationen finden Sie unter Konfigurieren von device.json für die ML-Qualifizierung. -
Führen Sie den Abhängigkeitstest für das Framework aus.
devicetester_[linux | mac | win_x86-64]run-suite --group-id mldependencies --test-id tensorflow_dependency_checkIn der Testzusammenfassung wird das Ergebnis
PASSEDfürmldependenciesangezeigt.
Installieren Sie die Abhängigkeiten von Amazon SageMaker AI Neo Deep Learning Runtime (DLR)
IDT-Qualifizierungstests für dieses Framework haben folgende Abhängigkeiten:
-
Python 3.6 oder Python 3.7.
Anmerkung
Wenn Sie Python 3.6 verwenden, müssen Sie einen symbolischen Link von Python 3.7- zu Python 3.6 Binärdateien erstellen. Dadurch wird Ihr Gerät so konfiguriert, dass es die Python-Anforderung für AWS IoT Greengrass erfüllt. Beispiel:
sudo ln -spath-to-python-3.6/python3.6path-to-python-3.7/python3.7 -
SageMaker AI Neo DLR.
-
numpy.
Nachdem Sie die DLR-Testabhängigkeiten installiert haben, müssen Sie das Modell kompilieren.
Installieren von DLR
Befolgen Sie die Anweisungen in der DLR-Dokumentation, um die Neo DLR zu installieren
Anmerkung
Wenn sowohl Python 2.x als auch Python 3.x auf Ihrem Gerät installiert ist, verwenden Sie Python 3.x in den Befehlen, die Sie zum Installieren der Abhängigkeiten ausführen.
Validieren der DLR-Installation
Wählen Sie eine der folgenden Optionen, um die DLR-Installation zu validieren.
Option 1: SSH in Ihr Gerät integrieren und Skripts ausführen
-
Integrieren Sie SSH in Ihr Gerät.
-
Führen Sie die folgenden Skripts aus, um zu überprüfen, ob die Abhängigkeiten korrekt installiert sind.
sudo python3.7 -c "import dlr; print(dlr.__version__)"sudo python3.7 -c "import numpy; print(numpy.__version__)"Die Ausgabe gibt die Versionsnummer aus und das Skript sollte fehlerfrei beendet werden.
Option 2: IDT-Abhängigkeitstest ausführen
-
Stellen Sie sicher, dass
device.jsonfür die ML-Qualifizierung konfiguriert ist. Weitere Informationen finden Sie unter Konfigurieren von device.json für die ML-Qualifizierung. -
Führen Sie den Abhängigkeitstest für das Framework aus.
devicetester_[linux | mac | win_x86-64]run-suite --group-id mldependencies --test-id dlr_dependency_checkIn der Testzusammenfassung wird das Ergebnis
PASSEDfürmldependenciesangezeigt.
Kompilieren des DLR-Modells
Sie müssen das DLR-Modell kompilieren, bevor Sie es für ML-Qualifizierungstests verwenden können. Wählen Sie dazu eine der folgenden Optionen:
Option 1: Verwenden Sie Amazon SageMaker AI, um das Modell zu kompilieren
Gehen Sie wie folgt vor, um mithilfe von SageMaker KI das von IDT bereitgestellte ML-Modell zu kompilieren. Dieses Modell wurde mit Apache MXNet vorgeschult.
-
Stellen Sie sicher, dass Ihr Gerätetyp von SageMaker AI unterstützt wird. Weitere Informationen finden Sie in den Optionen für Zielgeräte in der Amazon SageMaker AI API-Referenz. Wenn Ihr Gerätetyp derzeit nicht von SageMaker AI unterstützt wird, folgen Sie den Schritten unterOption 2: Kompilieren des DLR-Modells mithilfe von TVM.
Anmerkung
Die Ausführung des DLR-Tests mit einem von SageMaker KI kompilierten Modell kann 4 oder 5 Minuten dauern. Halten Sie IDT während dieser Zeit nicht an.
-
Laden Sie die Tarball-Datei herunter, die das unkompilierte, vorgeschulte MXNet-Modell für DLR enthält:
-
Extrahieren Sie die Tarball-Datei. Dieser Befehl generiert die folgende Verzeichnisstruktur.

-
Verschieben Sie
synset.txtaus dem Verzeichnisresnet18weg. Notieren Sie sich den neuen Speicherort. Sie kopieren diese Datei später in das kompilierte Modellverzeichnis. -
Komprimieren Sie den Inhalt des Verzeichnisses
resnet18.tar cvfz model.tar.gz resnet18v1-symbol.json resnet18v1-0000.params -
Laden Sie die komprimierte Datei in einen Amazon S3 S3-Bucket in Ihrem AWS-Konto hoch und folgen Sie dann den Schritten unter Modell kompilieren (Konsole), um einen Kompilierungsauftrag zu erstellen.
-
Verwenden Sie für Input configuration (Eingabekonfiguration) die folgenden Werte:
-
Geben Sie für Data input configuration (Dateneingabekonfiguration) den Wert
{"data": [1, 3, 224, 224]}ein. -
Wählen Sie für Machine Learning Framework (Machine-Learning-Framework) die Option
MXNet.
-
-
Verwenden Sie für Output configuration (Ausgabekonfiguration) die folgenden Werte:
-
Geben Sie als S3-Ausgabespeicherort den Pfad zum Amazon S3 S3-Bucket oder -Ordner ein, in dem Sie das kompilierte Modell speichern möchten.
-
Wählen Sie für Target device (Zielgerät) Ihren Gerätetyp.
-
-
-
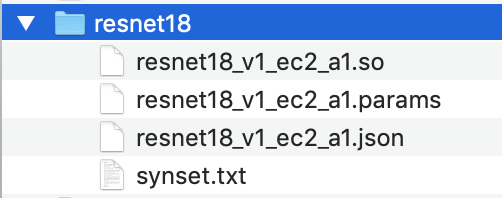
Laden Sie das kompilierte Modell vom angegebenen Ausgabespeicherort herunter und entpacken Sie die Datei.
-
Kopieren Sie
synset.txtin das kompilierte Modellverzeichnis. -
Ändern Sie den Namen des kompilierten Modellverzeichnisses in
resnet18.Das kompilierte Modellverzeichnis muss die folgende Verzeichnisstruktur aufweisen.
Option 2: Kompilieren des DLR-Modells mithilfe von TVM
Gehen Sie folgendermaßen vor, um das von IDT bereitgestellte ML-Modell mithilfe von TVM zu kompilieren. Dieses Modell wurde mit Apache MXNet vorgeschult. Daher müssen Sie MXNet auf dem Computer oder Gerät installieren, auf dem Sie das Modell kompilieren. Befolgen Sie die Anweisungen in der MXNet-Dokumentation
Anmerkung
Es wird empfohlen, das Modell auf dem Zielgerät zu kompilieren. Dies ist optional, kann jedoch zur Gewährleistung der Kompatibilität beitragen und potenzielle Probleme minimieren.
-
Laden Sie die Tarball-Datei herunter, die das unkompilierte, vorgeschulte MXNet-Modell für DLR enthält:
-
Extrahieren Sie die Tarball-Datei. Dieser Befehl generiert die folgende Verzeichnisstruktur.
-
Befolgen Sie die Anweisungen in der TVM-Dokumentation, um TVM aus der Quelle für Ihre Plattform zu erstellen und zu installieren
. -
Führen Sie nach der Erstellung von TVM die TVM-Kompilierung für das Modell resnet18 aus. Die folgenden Schritte basieren auf dem Quick Start Tutorial for Compiling Deep Learning Models
in der TVM-Dokumentation. -
Öffnen Sie die Datei
relay_quick_start.pyaus dem geklonten TVM-Repository. -
Aktualisieren Sie den Code, der ein neuronales Netzwerk im Relais definiert
. Verwenden Sie eine der folgenden Optionen: -
Option 1: Verwenden Sie
mxnet.gluon.model_zoo.vision.get_model, um das Relaismodul und die Parameter zu erhalten:from mxnet.gluon.model_zoo.vision import get_model block = get_model('resnet18_v1', pretrained=True) mod, params = relay.frontend.from_mxnet(block, {"data": data_shape}) -
Option 2: Kopieren Sie aus dem nicht kompilierten Modell, das Sie in Schritt 1 heruntergeladen haben, die folgenden Dateien in das gleiche Verzeichnis wie Datei
relay_quick_start.py. Diese Dateien enthalten das Relaismodul und die Parameter.-
resnet18v1-symbol.json -
resnet18v1-0000.params
-
-
-
Aktualisieren Sie den Code, der das kompilierte Modul speichert und lädt
, sodass der folgende Code verwendet wird. from tvm.contrib import util path_lib = "deploy_lib.so" # Export the model library based on your device architecture lib.export_library("deploy_lib.so", cc="aarch64-linux-gnu-g++") with open("deploy_graph.json", "w") as fo: fo.write(graph) with open("deploy_param.params", "wb") as fo: fo.write(relay.save_param_dict(params)) -
Erstellen Sie das Modell:
python3 tutorials/relay_quick_start.py --build-dir ./modelDieser Befehl generiert die folgenden Dateien.
-
deploy_graph.json -
deploy_lib.so -
deploy_param.params
-
-
-
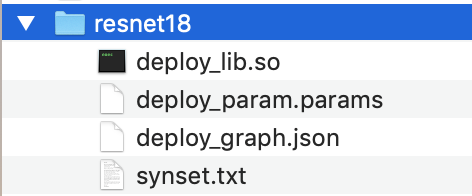
Kopieren Sie die generierten Modelldateien in ein Verzeichnis mit dem Namen
resnet18. Dies ist Ihr kompiliertes Modellverzeichnis. -
Kopieren Sie das kompilierte Modellverzeichnis auf Ihren Hostcomputer. Kopieren Sie dann
synset.txtaus dem nicht kompilierten Modell, das Sie in Schritt 1 heruntergeladen haben, in das kompilierte Modellverzeichnis.Das kompilierte Modellverzeichnis muss die folgende Verzeichnisstruktur aufweisen.
Als Nächstes konfigurieren Sie Ihre AWS Anmeldeinformationen und Ihre device.json Datei.
