Nach reiflicher Überlegung haben wir uns entschieden, Amazon Kinesis Data Analytics für SQL-Anwendungen einzustellen:
1. Ab dem 1. September 2025 werden wir keine Bugfixes für Amazon Kinesis Data Analytics for SQL-Anwendungen bereitstellen, da wir aufgrund der bevorstehenden Einstellung nur eingeschränkten Support dafür haben werden.
2. Ab dem 15. Oktober 2025 können Sie keine neuen Kinesis Data Analytics for SQL-Anwendungen mehr erstellen.
3. Wir werden Ihre Anwendungen ab dem 27. Januar 2026 löschen. Sie können Ihre Amazon Kinesis Data Analytics for SQL-Anwendungen nicht starten oder betreiben. Ab diesem Zeitpunkt ist kein Support mehr für Amazon Kinesis Data Analytics for SQL verfügbar. Weitere Informationen finden Sie unter Einstellung von Amazon Kinesis Data Analytics für SQL-Anwendungen.
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Arbeiten mit dem Schema-Editor
Das Schema für den Eingabe-Stream einer Amazon-Kinesis-Data-Analytics-Anwendung definiert, wie Daten aus dem Stream für SQL-Abfragen in der Anwendung zur Verfügung gestellt werden.
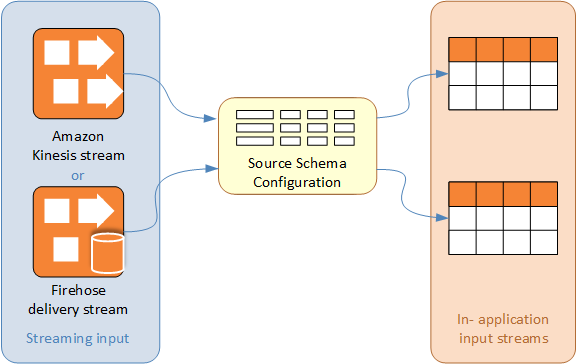
Das Schema enthält Auswahlkriterien, mit denen Sie festlegen können, welcher Teil der Streaming-Eingabe im In-Application-Eingabe-Stream in eine Datenspalte umgewandelt wird. Bei dieser Eingabe kann es sich Folgendes handeln:
Einen JSONPath-Ausdruck für JSON-Eingabe-Streams. JSONPath ist ein Tool für die Abfrage von JSON-Daten.
Eine Spaltennummer für Eingabe-Streams im CSV-Format (durch Komma getrennte Werte).
Ein Spaltenname und ein SQL-Datentyp für die Darstellung der Daten im In-Application-Daten-Stream. Der Datentyp enthält auch eine Länge für Zeichen oder Binärdaten.
Die Konsole versucht, das Schema mittels DiscoverInputSchema zu generieren. Wenn eine Schemaerkennung fehlschlägt oder ein falsches oder unvollständiges Schema zurückgegeben wird, müssen Sie das Schema mit dem Schema-Editor manuell bearbeiten.
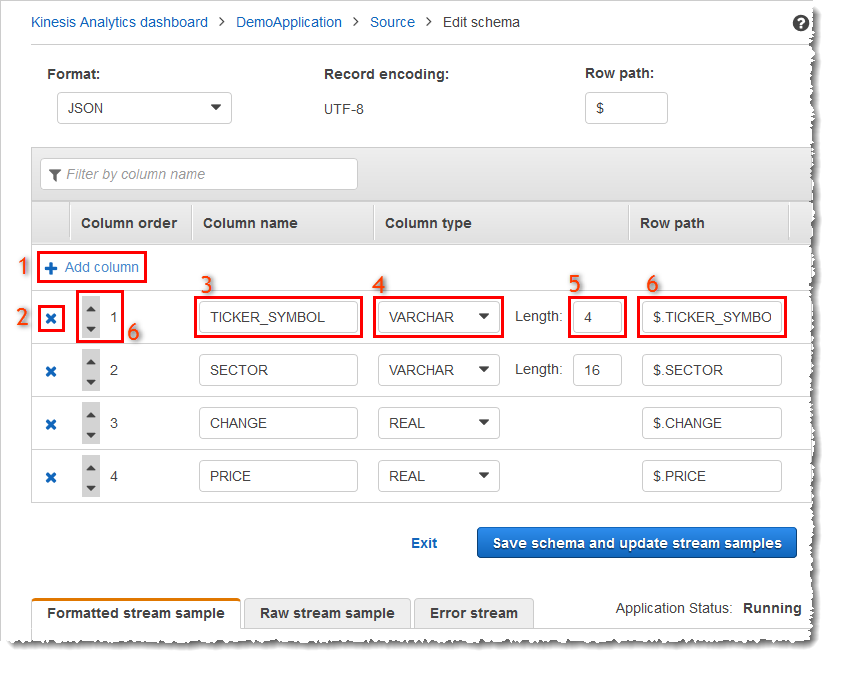
Hauptbildschirm des Schema-Editors
Der folgende Screenshot zeigt den Hauptbildschirm des Schema-Editors.
Sie können die folgenden Bearbeitungen auf das Schema anwenden:
Hinzufügen einer Spalte (1): Möglicherweise müssen Sie eine Datenspalte hinzufügen, wenn ein Datenelement nicht automatisch erkannt wird.
Löschen einer Spalte (2): Sie können Daten aus dem Quell-Stream ausschließen, wenn Ihre Anwendung diese nicht benötigt. Dieser Ausschluss wirkt sich nicht auf die Daten im Quell-Stream aus. Wenn Daten ausgeschlossen werden, werden sie der Anwendung einfach nicht zur Verfügung gestellt.
Umbenennen einer Spalte (3): Ein Spaltenname darf nicht leer sein, muss mehr als ein einzelnes Zeichen enthalten und darf keine reservierten SQL-Schlüsselwörter enthalten. Der Name muss darüber hinaus Namenskriterien für gewöhnliche SQL-Kennungen entsprechen: Er muss mit einem Buchstaben beginnen und darf nur Buchstaben, Unterstriche und Ziffern enthalten.
Ändern des Datentyps (4) oder der Länge (5) einer Spalte: Sie können einen kompatiblen Datentyp für eine Spalte angeben. Wenn Sie einen nicht kompatiblen Datentyp angeben, wird die Spalte entweder mit NULL aufgefüllt oder der In-Application-Stream wird überhaupt nicht aufgefüllt. In letzteren Fall werden Fehler in den Fehler-Stream geschrieben. Wenn Sie eine Länge für eine Spalte angeben, die zu klein ist, werden die eingehenden Daten abgeschnitten.
Ändern der Auswahlkriterien einer Spalte (6): Sie können den JSONPath-Ausdruck oder die CSV-Spaltenreihenfolge bearbeiten, die zur Ermittlung der Quelle der Daten in einer Spalte verwendet werden. Um die Auswahlkriterien für ein JSON-Schema zu ändern, geben Sie einen neuen Wert für den Zeilenpfadausdruck ein. Ein CSV-Schema verwendet die Spaltenreihenfolge als Auswahlkriterium. Um die Auswahlkriterien für ein CSV-Schema zu ändern, ändern Sie die Reihenfolge der Spalten.
Bearbeiten des Schemas für eine Streaming-Quelle
Wenn Sie ein Schema für eine Streaming-Quelle bearbeiten müssen, führen Sie die folgenden Schritte aus.
So bearbeiten Sie das Schema für eine Streaming-Quelle
Wählen Sie auf der Seite Source die Option Edit schema.

Bearbeiten Sie auf der Seite Edit schema das Quell-Schema.
Wählen Sie für Format JSON oder CSV. Für das JSON- oder CSV-Format wird die Kodierung ISO-8859-1 unterstützt.
Weitere Informationen zum Bearbeiten des Schemas für das JSON- oder CSV-Format finden Sie in den Verfahren in den nächsten Abschnitten.
Bearbeiten eines JSON-Schemas
Sie können JSON-Schemata bearbeiten, indem Sie die folgenden Schritte ausführen.
So bearbeiten Sie ein JSON-Schema
Wählen Sie im Schema-Editor Add column, um eine Spalte hinzuzufügen.
In der ersten Spaltenposition wird eine neue Spalte angezeigt. Zum Ändern der Spaltenreihenfolge wählen Sie die nach oben und unten zeigenden Pfeile neben dem Spaltennamen.
Geben Sie für neue Spalte folgende Informationen an:
Geben Sie in Column name einen Namen ein.
Ein Spaltenname darf nicht leer sein, muss mehr als ein einzelnes Zeichen enthalten und darf keine reservierten SQL-Schlüsselwörter enthalten. Dieser muss ebenfalls den Namenskriterien für gewöhnliche SQL-Kennungen entsprechen: Er muss mit einem Buchstaben beginnen und darf nur Buchstaben, Unterstriche und Ziffern enthalten.
Geben Sie für Column Type einen SQL-Datentyp ein.
Jeder unterstützte SQL-Datentyp kann ein Spaltentyp sein. Wenn es sich beim neuen Datentyp um CHAR, VARBINARY oder VARCHAR handelt, geben Sie für Length eine Datenlänge an. Weitere Informationen finden Sie unter Data Types.
Geben Sie für Row path einen Zeilenpfad an. Ein Zeilenpfad ist ein gültiger JSONPath-Ausdruck, der einem JSON-Element zugeordnet ist.
Anmerkung
Der Basiswert für Row path ist der Pfad zum übergeordneten Element auf höchster Ebene, das die zu importierenden Daten enthält. Dieser Wert ist standardmäßig $. Weitere Informationen finden Sie unter
RecordRowPathinJSONMappingParameters.
Um eine Spalte zu löschen, wählen Sie das Symbol x neben der Spaltennummer.
Geben Sie unter Column name (Spaltenname) einen neuen Namen für eine Spalte ein, um diese umzubenennen. Der Name der neuen Spalte darf nicht leer sein, muss mehr als ein einzelnes Zeichen enthalten und darf keine reservierten SQL-Schlüsselwörter enthalten. Dieser muss ebenfalls den Namenskriterien für gewöhnliche SQL-Kennungen entsprechen: Er muss mit einem Buchstaben beginnen und darf nur Buchstaben, Unterstriche und Ziffern enthalten.
-
Um den Datentyp einer Spalte zu ändern, wählen Sie für Column type einen neuen Datentyp aus. Handelt es sich beim neuen Datentyp um
CHAR,VARBINARYoderVARCHAR, geben Sie unter Length (Länge) eine Datenlänge ein. Weitere Informationen finden Sie unter Data Types. -
Wählen Sie Save schema and update stream, um Ihre Änderungen zu speichern.
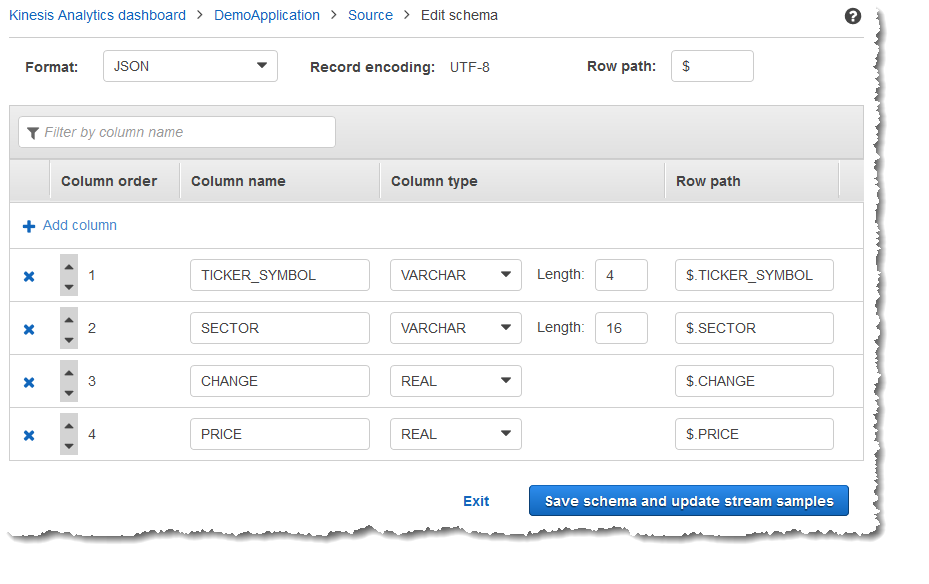
Das geänderte Schema wird im Editor angezeigt und sieht ähnlich dem folgenden Schema aus.

Wenn Ihr Schema zahlreiche Zeilen besitzt, können Sie die Zeilen mittels Filter by column name filtern. Um beispielsweise Spaltennamen zu bearbeiten, die mit P beginnen, wie eine Price-Spalte, geben Sie P im Feld Nach Spaltennamen filtern ein.
Bearbeiten eines CSV-Schemas
Sie können CSV-Schemata bearbeiten, indem Sie die folgenden Schritte ausführen.
So bearbeiten Sie ein CSV-Schema
Wählen Sie im Schema-Editor für Row delimiter das Trennzeichen aus, das im eingehenden Daten-Stream verwendet wird. Dies ist das Trennzeichen zwischen Datensätzen von Daten in Ihrem Stream, z. B. ein Zeilenumbruchzeichen.
Wählen Sie für Column delimiter das Trennzeichen aus, das im eingehenden Daten-Stream verwendet wird. Dies ist das Trennzeichen zwischen Feldern von Daten in Ihrem Stream, z. B. ein Komma.
Um eine Spalte hinzuzufügen, wählen Sie Add column.
In der ersten Spaltenposition wird eine neue Spalte angezeigt. Zum Ändern der Spaltenreihenfolge wählen Sie die nach oben und unten zeigenden Pfeile neben dem Spaltennamen.
Geben Sie für neue Spalte folgende Informationen an:
Geben Sie unter Column name (Spaltenname) einen Namen ein.
Ein Spaltenname darf nicht leer sein, muss mehr als ein einzelnes Zeichen enthalten und darf keine reservierten SQL-Schlüsselwörter enthalten. Dieser muss ebenfalls den Namenskriterien für gewöhnliche SQL-Kennungen entsprechen: Er muss mit einem Buchstaben beginnen und darf nur Buchstaben, Unterstriche und Ziffern enthalten.
Geben Sie unter Column Type (Spaltentyp) einen SQL-Datentyp ein.
Jeder unterstützte SQL-Datentyp kann ein Spaltentyp sein. Wenn es sich beim neuen Datentyp um CHAR, VARBINARY oder VARCHAR handelt, geben Sie für Length eine Datenlänge an. Weitere Informationen finden Sie unter Data Types.
Um eine Spalte zu löschen, wählen Sie das Symbol x neben der Spaltennummer.
Geben Sie unter Column name (Spaltenname) einen neuen Namen für eine Spalte ein, um diese umzubenennen. Der Name der neuen Spalte darf nicht leer sein, muss mehr als ein einzelnes Zeichen enthalten und darf keine reservierten SQL-Schlüsselwörter enthalten. Dieser muss ebenfalls den Namenskriterien für gewöhnliche SQL-Kennungen entsprechen: Er muss mit einem Buchstaben beginnen und darf nur Buchstaben, Unterstriche und Ziffern enthalten.
-
Um den Datentyp einer Spalte zu ändern, wählen Sie für Column type einen neuen Datentyp aus. Wenn es sich beim neuen Datentyp um CHAR, VARBINARY oder VARCHAR handelt, geben Sie für Length eine Datenlänge an. Weitere Informationen finden Sie unter Data Types.
-
Wählen Sie Save schema and update stream, um Ihre Änderungen zu speichern.
Das geänderte Schema wird im Editor angezeigt und sieht ähnlich dem folgenden Schema aus.
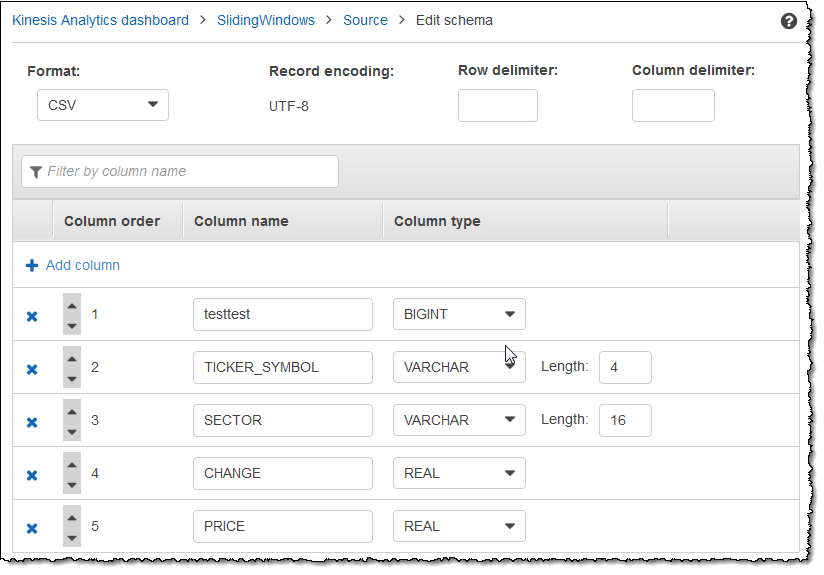
Wenn Ihr Schema zahlreiche Zeilen besitzt, können Sie die Zeilen mittels Filter by column name filtern. Um beispielsweise Spaltennamen zu bearbeiten, die mit P beginnen, wie eine Price-Spalte, geben Sie P im Feld Nach Spaltennamen filtern ein.
