Nach reiflicher Überlegung haben wir uns entschieden, Amazon Kinesis Data Analytics für SQL-Anwendungen einzustellen:
1. Ab dem 1. September 2025 werden wir keine Bugfixes für Amazon Kinesis Data Analytics for SQL-Anwendungen bereitstellen, da wir aufgrund der bevorstehenden Einstellung nur eingeschränkten Support dafür haben werden.
2. Ab dem 15. Oktober 2025 können Sie keine neuen Kinesis Data Analytics for SQL-Anwendungen mehr erstellen.
3. Wir werden Ihre Anwendungen ab dem 27. Januar 2026 löschen. Sie können Ihre Amazon Kinesis Data Analytics for SQL-Anwendungen nicht starten oder betreiben. Ab diesem Zeitpunkt ist kein Support mehr für Amazon Kinesis Data Analytics for SQL verfügbar. Weitere Informationen finden Sie unter Einstellung von Amazon Kinesis Data Analytics für SQL-Anwendungen.
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Beispiel: Aggregieren von Teilergebnissen aus einer Abfrage
Wenn ein Amazon-Kinesis-Datenstrom Datensätze mit einer Ereigniszeit enthält, die nicht genau dem Zeitpunkt der Datenübernahme entspricht, enthalten bestimmte Ergebnisse in einem rollierenden Fenster Datensätze, die innerhalb des Fensters eingetroffen sind, aber nicht unbedingt eingetreten sein müssen. In diesem Fall enthält das rollierende Fenster nur eine Teilmenge der gewünschten Ergebnisse. Es gibt mehrere Möglichkeiten, wie Sie dieses Problem beheben können:
-
Verwenden Sie nur ein rollierendes Fenster und aggregieren Sie Teilergebnisse in der Nachverarbeitung über eine Datenbank oder ein Data Warehouse mithilfe von upsert-Operationen. Dieser Ansatz ist bei der Verarbeitung einer Anwendung sehr effizient. Verspätete Daten für Aggregat-Operatoren (
sum,min,maxusw.) werden ohne jegliche Einschränkungen verarbeitet. Der Nachteil dieser Methode besteht darin, dass Sie eine zusätzliche Anwendungslogik im Datenbank-Layer entwickeln und pflegen müssen. -
Verwenden Sie ein rollierendes und ein gleitendes Fenster, das früh zu Teilergebnissen führt, aber innerhalb des Zeitraums des gleitenden Fensters zudem vollständige Ergebnisse erzielen wird. Dieser Ansatz verarbeitet verspätete Daten durch Überschreiben anstatt mit einer upsert-Operation. Daher muss keine zusätzliche Anwendungslogik im Datenbank-Layer hinzugefügt werden. Der Nachteil dieses Ansatzes besteht darin, dass mehr Kinesis-Verarbeitungseinheiten (KPUs) verwendet werden und dennoch zwei Ergebnisse erzielt werden, die in einigen Anwendungsfällen möglicherweise nicht funktionieren.
Weitere Informationen zu rollierenden und gleitenden Fenstern finden Sie unter Abfragen mit Fenstern.
Im folgenden Verfahren erzielt die Aggregation über ein rollierendes Fenster zwei (an den CALC_COUNT_SQL_STREAM-In-Application-Stream übermittelte) Teilergebnisse, die zusammen das Endergebnis ergeben. Die Anwendung erstellt dann eine zweite (an den DESTINATION_SQL_STREAM-In-Application-Stream übermittelte) Aggregation, um die beiden Teilergebnisse zu vereinen.
So erstellen Sie eine Anwendung, die Teilergebnisse mittels einer Ereigniszeit aggregiert
Melden Sie sich bei der an AWS Management Console und öffnen Sie die Kinesis-Konsole unter https://console.aws.amazon.com/kinesis
. -
Klicken Sie im Navigationsbereich auf Data Analytics (Datenanalyse). Erstellen Sie eine Kinesis Data Analytics-Anwendung gemäß der Beschreibung im Erste Schritte mit Amazon-Kinesis-Data-Analytics for SQL-Anwendungen-Tutorial.
-
Ersetzen Sie im SQL-Editor den Anwendungscode durch Folgendes:
CREATE OR REPLACE STREAM "CALC_COUNT_SQL_STREAM" (TICKER VARCHAR(4), TRADETIME TIMESTAMP, TICKERCOUNT DOUBLE); CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" (TICKER VARCHAR(4), TRADETIME TIMESTAMP, TICKERCOUNT DOUBLE); CREATE PUMP "CALC_COUNT_SQL_PUMP_001" AS INSERT INTO "CALC_COUNT_SQL_STREAM" ("TICKER","TRADETIME", "TICKERCOUNT") SELECT STREAM "TICKER_SYMBOL", STEP("SOURCE_SQL_STREAM_001"."ROWTIME" BY INTERVAL '1' MINUTE) as "TradeTime", COUNT(*) AS "TickerCount" FROM "SOURCE_SQL_STREAM_001" GROUP BY STEP("SOURCE_SQL_STREAM_001".ROWTIME BY INTERVAL '1' MINUTE), STEP("SOURCE_SQL_STREAM_001"."APPROXIMATE_ARRIVAL_TIME" BY INTERVAL '1' MINUTE), TICKER_SYMBOL; CREATE PUMP "AGGREGATED_SQL_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" ("TICKER","TRADETIME", "TICKERCOUNT") SELECT STREAM "TICKER", "TRADETIME", SUM("TICKERCOUNT") OVER W1 AS "TICKERCOUNT" FROM "CALC_COUNT_SQL_STREAM" WINDOW W1 AS (PARTITION BY "TRADETIME" RANGE INTERVAL '10' MINUTE PRECEDING);Die
SELECT-Anweisung im Anwendungscode filtert Zeilen imSOURCE_SQL_STREAM_001nach Aktien mit Preisänderungen von mehr als 1 % und fügt diese Zeilen mittels eines Pump in einen anderenCHANGE_STREAM-In-Application-Stream ein. -
Klicken Sie auf Save and run SQL (SQL speichern und ausführen).
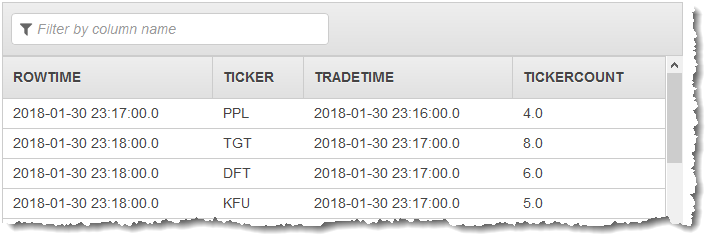
Die erste Pumpe gibt einen Stream ähnlich dem Folgenden an CALC_COUNT_SQL_STREAM aus. Beachten Sie, dass der Ergebnissatz unvollständig ist:
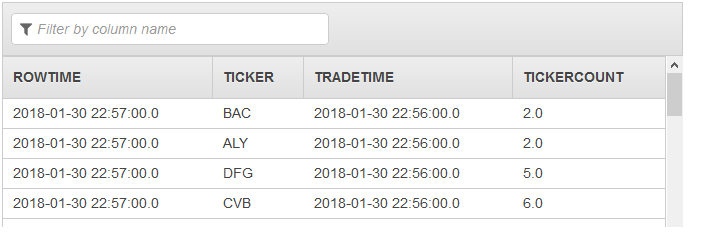
Die zweite Pumpe gibt dann einen Stream mit dem vollständigen Ergebnissatz an DESTINATION_SQL_STREAM aus: