Wir aktualisieren den Amazon Machine Learning Learning-Service nicht mehr und akzeptieren auch keine neuen Nutzer mehr dafür. Diese Dokumentation ist für bestehende Benutzer verfügbar, wir aktualisieren sie jedoch nicht mehr. Weitere Informationen finden Sie unter Was ist Amazon Machine Learning.
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Cross-Validation
Cross-validation ist eine Technik zur Bewertung von ML-Modellen, bei der mehrere ML-Modelle anhand von Teilmengen der verfügbaren Eingabedaten trainiert und anhand der komplementären Teilmenge der Daten ausgewertet werden. Verwenden Sie die Kreuzvalidierung, um eine Überanpassung zu erkennen, d. h. wenn ein Muster nicht verallgemeinert wird.
In Amazon ML können Sie die K-fache Kreuzvalidierungsmethode verwenden, um eine Kreuzvalidierung durchzuführen. Bei der k-fachen Kreuzvalidierung teilen Sie die Eingabedaten in k Teilmengen von Daten auf (auch bekannt als Falten). Sie trainieren ein ML-Modell mit allen Teilmengen außer einer (k-1) und evaluieren das Modell dann anhand der Teilmenge, die nicht für das Training verwendet wurde. Dieser Vorgang wird k-Mal wiederholt, wobei jedes Mal eine andere Teilmenge für die Auswertung verwendet wird (die für Schulungen ausgeschlossen ist).
Das folgende Diagramm zeigt ein Beispiel der Schulungsteilmengen und der ergänzenden Auswertungsteilmengen, die für jedes der vier Modelle generiert werden, die während einer 4-fachen Kreuzvalidierung erstellt und geschult werden. Modell 1 verwendet die ersten 25 Prozent der Daten für die Auswertung und die verbleibenden 75 Prozent für die Schulung. Modell 2 verwendet die zweite Teilmenge von 25 Prozent (25 Prozent bis 50 Prozent) für die Auswertung und die verbleibenden drei Teilmengen der Daten für Schulungen und so weiter.
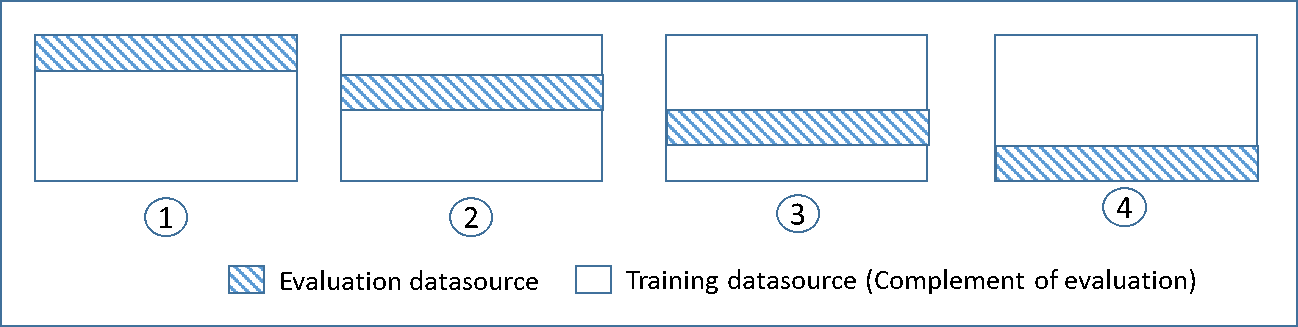
Jedes Modell wird mithilfe der ergänzenden Datenquellen geschult und ausgewertet – die Daten in der Auswertungsdatenquelle umfassen und sind auf alle Daten beschränkt, die sich nicht in der Schulungsdatenquelle befinden. Sie erstellen den Datenquellen für jede dieser Untergruppen mit dem Parameter DataRearrangement in den createDatasourceFromS3-, createDatasourceFromRedShift- und createDatasourceFromRDS-APIs. Geben Sie im Parameter DataRearrangement an, welche Teilmenge von Daten in eine Datenquelle eingeschlossen werden soll, indem Sie angeben, wo jedes Segment angefangen und beendet werden soll. Um die ergänzenden Datenquellen zu erstellen, die für ein 4000-fache Kreuzvalidierung erforderlich sind, geben Sie den Parameter DataRearrangement wie im folgenden Beispiel an:
Modell 1:
Auswertungsdatenquelle:
{"splitting":{"percentBegin":0, "percentEnd":25}}
Schulungsdatenquelle:
{"splitting":{"percentBegin":0, "percentEnd":25, "complement":"true"}}
Modell 2:
Auswertungsdatenquelle:
{"splitting":{"percentBegin":25, "percentEnd":50}}
Schulungsdatenquelle:
{"splitting":{"percentBegin":25, "percentEnd":50, "complement":"true"}}
Modell 3:
Auswertungsdatenquelle:
{"splitting":{"percentBegin":50, "percentEnd":75}}
Schulungsdatenquelle:
{"splitting":{"percentBegin":50, "percentEnd":75, "complement":"true"}}
Modell 4:
Auswertungsdatenquelle:
{"splitting":{"percentBegin":75, "percentEnd":100}}
Schulungsdatenquelle:
{"splitting":{"percentBegin":75, "percentEnd":100, "complement":"true"}}
Bei einer vierfachen Kreuzvalidierung werden vier Modelle generiert: vier Datenquellen zum Trainieren der Modelle, vier Datenquellen zur Evaluierung der Modelle und vier Evaluierungen, eine für jedes Modell. Amazon ML generiert für jede Bewertung eine Modellleistungsmetrik. Bei einer 4-fachen Kreuzvalidierung für ein binäres Klassifizierungsproblem erstellt jede der Auswertungen einen Bericht für eine sogenannte Area Under a Curve (AUC). Die Gesamtleistung erhalten Sie, indem Sie den Durchschnitt der vier AUC-Metriken berechnen. Weitere Informationen zur AUC-Metrik finden Sie unter Messung der ML-Modellgenauigkeit.
Einen Beispielcode, der zeigt, wie eine Kreuzvalidierung erstellt und der Durchschnitt der Modellwerte ermittelt wird, finden Sie im Amazon ML-Beispielcode
Anpassen Ihrer Modelle
Nachdem Sie die Modelle kreuzvalidiert haben, können Sie die Einstellungen für das nächste Modell anpassen, wenn das Modell nicht Ihren Standards entspricht. Weitere Informationen zur Überanpassung finden Sie unter Modellanpassung: Unteranpassung vs. Überanpassung. Weitere Informationen zur Regularisation finden Sie unter Regularisation. Weitere Informationen zum Ändern der Regularisationseinstellungen finden Sie unter Erstellen eines ML-Modells mit benutzerdefinierten Optionen.
