Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Was ist Amazon Managed Service für Apache Flink?
Mit Amazon Managed Service für Apache Flink können Sie Java, Scala, Python oder SQL verwenden, um Streaming-Daten zu verarbeiten und zu analysieren. Der Service ermöglicht es Ihnen, Code für Streaming-Quellen und statische Quellen zu erstellen und auszuführen, um Zeitreihenanalysen durchzuführen, Echtzeit-Dashboards und Metriken bereitzustellen.
Mithilfe von Open-Source-Bibliotheken, die auf Apache Flink basieren, können Sie in Managed Service für Apache Flink Anwendungen mit der Sprache Ihrer Wahl erstellen.
Managed Service für Apache Flink stellt die zugrunde liegende Infrastruktur für Ihre Apache-Flink-Anwendungen bereit. Es verarbeitet Kernfunktionen wie die Bereitstellung von Rechenressourcen, AZ-Failover-Resilienz, parallel Berechnung, automatische Skalierung und Anwendungs-Backups (implementiert als Checkpoints und Snapshots). Sie können die allgemeinen Flink-Programmier-Features (wie Operatoren, Funktionen, Quellen und Senken) genauso verwenden, wie Sie sie verwenden, wenn Sie die Flink-Infrastruktur selbst hosten.
Entscheiden Sie sich zwischen der Verwendung von Managed Service für Apache Flink oder Managed Service für Apache Flink Studio
Sie haben zwei Möglichkeiten, Ihre Flink-Jobs mit Amazon Managed Service für Apache Flink auszuführen. Mit Managed Service für Apache Flink erstellen Sie Flink-Anwendungen in Java, Scala oder Python (und Embedded SQL) mit einer IDE Ihrer Wahl und den Apache Flink Datastream- oder Tabellen-APIs. Mit Managed Service für Apache Flink Studio können Sie Datenströme interaktiv in Echtzeit abfragen und problemlos Streamverarbeitungsanwendungen mit Standard-SQL, Python und Scala erstellen und ausführen.
Sie können auswählen, welche Methode am besten zu Ihrem Anwendungsfall passt. Wenn Sie sich nicht sicher sind, finden Sie in diesem Abschnitt allgemeine Anleitungen, die Ihnen weiterhelfen sollen.
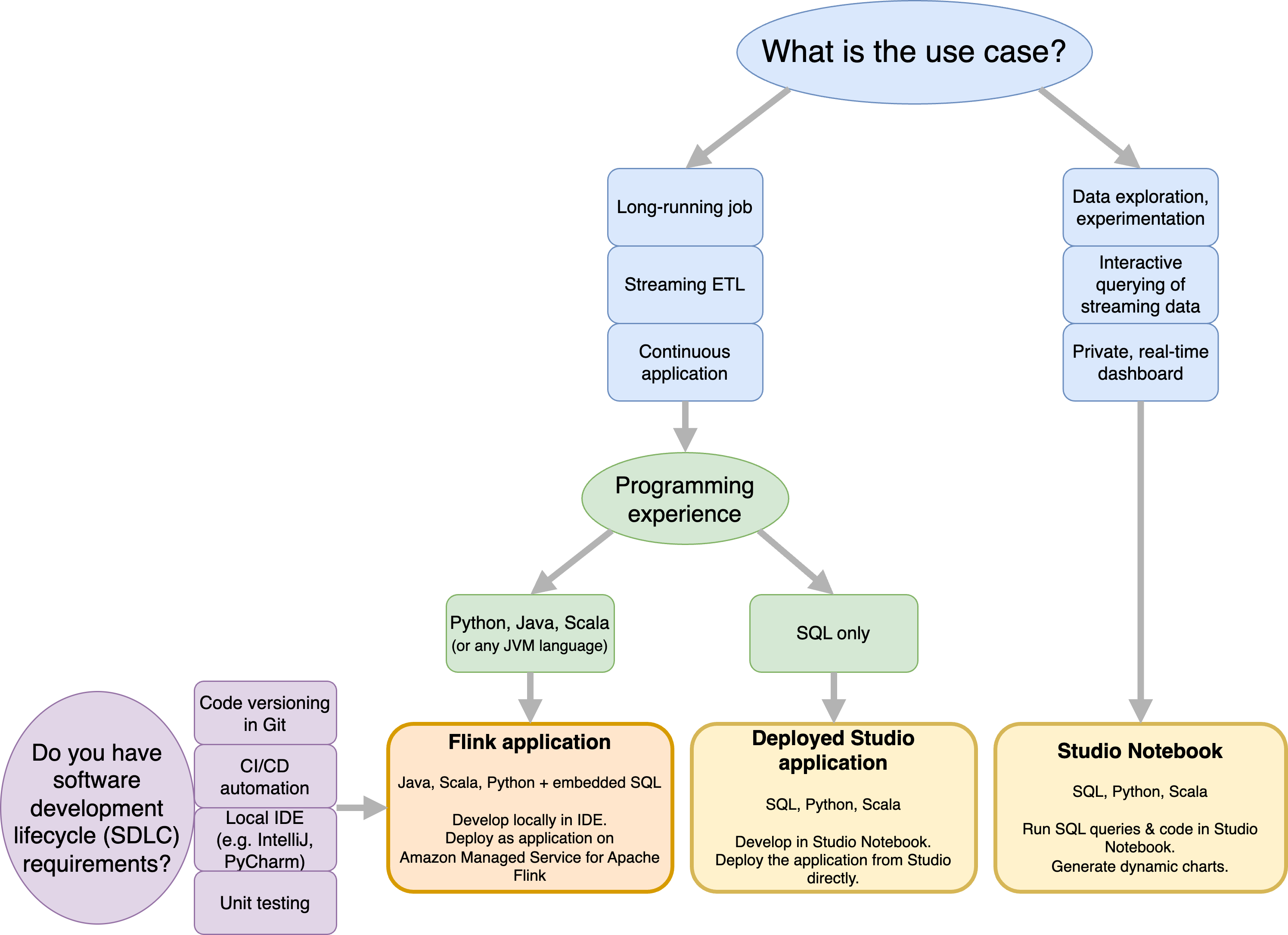
Bevor Sie sich entscheiden, ob Sie Amazon Managed Service für Apache Flink oder Amazon Managed Service für Apache Flink Studio verwenden möchten, sollten Sie Ihren Anwendungsfall berücksichtigen.
Wenn Sie planen, eine lang laufende Anwendung zu betreiben, die Workloads wie Streaming ETL oder Continuous Applications übernimmt, sollten Sie die Verwendung von Managed Service für Apache Flink in Betracht ziehen. Das liegt daran, dass Sie Ihre Flink-Anwendung mithilfe der Flink-APIs direkt in der IDE Ihrer Wahl erstellen können. Durch die lokale Entwicklung mit Ihrer IDE können Sie außerdem sicherstellen, dass Sie die gängigen Prozesse und Tools des Software Development Lifecycle (SDLC) wie Codeversionierung in Git, CI/CD Automatisierung oder Unit-Tests nutzen können.
Wenn Sie an der Ad-hoc-Datenexploration interessiert sind, Streaming-Daten interaktiv abfragen oder private Echtzeit-Dashboards erstellen möchten, hilft Ihnen Managed Service für Apache Flink Studio dabei, diese Ziele mit nur wenigen Klicks zu erreichen. Benutzer, die mit SQL vertraut sind, können erwägen, eine Anwendung mit langer Laufzeit direkt von Studio aus bereitzustellen.
Anmerkung
Sie können Ihr Studio-Notizbuch zu einer Anwendung mit langer Laufzeit heraufstufen. Wenn Sie jedoch Tools wie Codeversionierung auf Git und CI/CD Automatisierung oder Techniken wie Unit-Tests in Ihre SDLC-Tools integrieren möchten, empfehlen wir Managed Service for Apache Flink mit der IDE Ihrer Wahl.
Wählen Sie aus, welche Apache Flink-APIs in Managed Service für Apache Flink verwendet werden sollen
Sie können Anwendungen mit Java, Python und Scala in Managed Service für Apache Flink mithilfe von Apache Flink-APIs in einer IDE Ihrer Wahl erstellen. In der Dokumentation finden Sie Anleitungen zum Erstellen von Anwendungen mit dem Flink Datastream und der Tabellen-API. Sie können die Sprache, in der Sie Ihre Flink-Anwendung erstellen, und die APIs, die Sie verwenden, auswählen, um den Anforderungen Ihrer Anwendung und Ihres Betriebs am besten gerecht zu werden. Wenn Sie sich nicht sicher sind, finden Sie in diesem Abschnitt allgemeine Anleitungen, die Ihnen weiterhelfen sollen.
Wählen Sie eine Flink-API
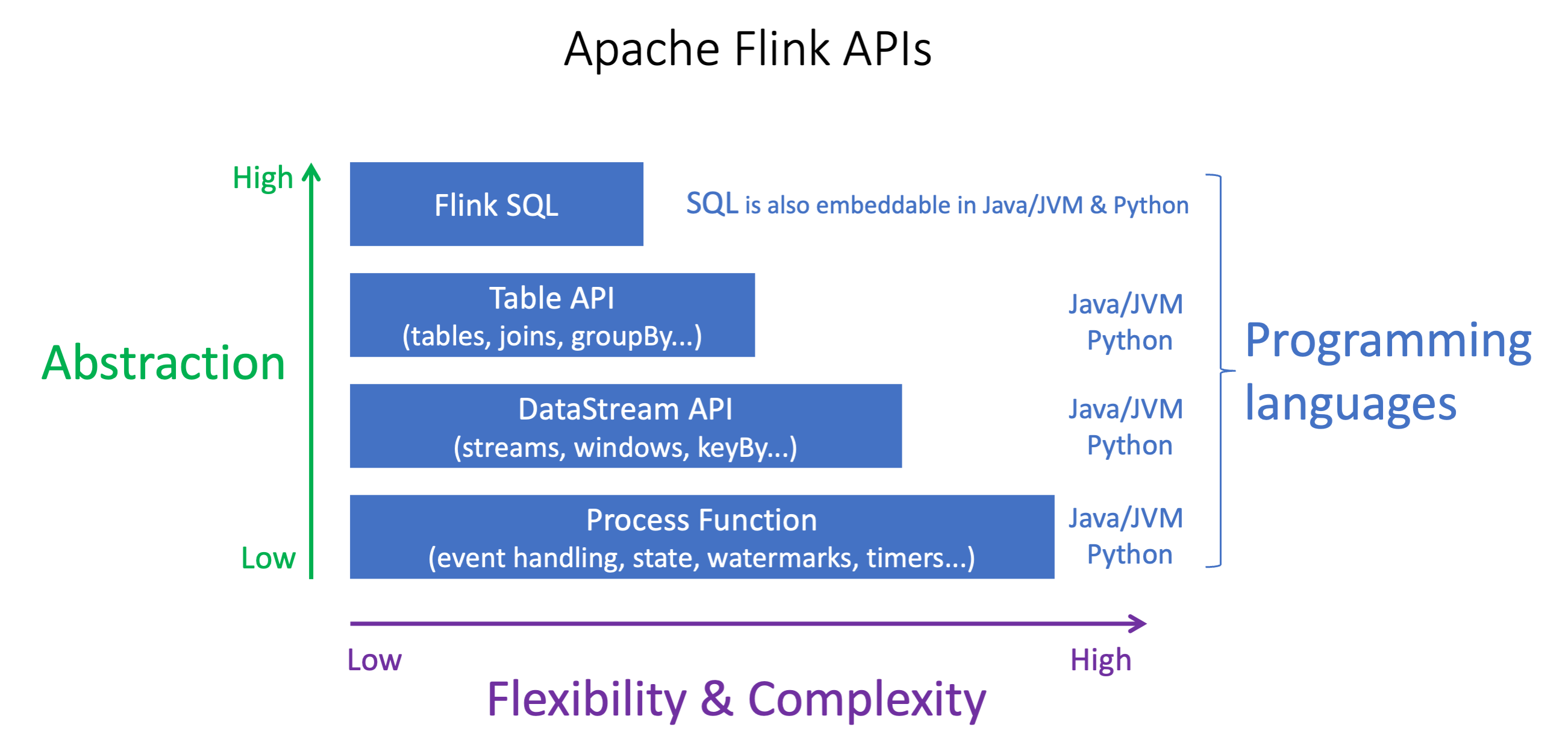
Die Apache Flink-APIs haben unterschiedliche Abstraktionsebenen, die sich darauf auswirken können, wie Sie Ihre Anwendung erstellen möchten. Sie sind ausdrucksstark und flexibel und können zusammen verwendet werden, um Ihre Anwendung zu erstellen. Sie müssen nicht nur eine Flink-API verwenden. Weitere Informationen zu den Flink-APIs finden Sie in der Apache Flink-Dokumentation
Flink bietet vier Ebenen der API-Abstraktion: Flink SQL, Tabellen-API, DataStream API und Process Function, die in Verbindung mit der API verwendet wird. DataStream Diese werden alle in Amazon Managed Service für Apache Flink unterstützt. Es ist ratsam, wenn möglich mit einer höheren Abstraktionsebene zu beginnen. Einige Flink-Funktionen sind jedoch nur mit der Datastream-API verfügbar, mit der Sie Ihre Anwendung in Java, Python oder Scala erstellen können. Sie sollten die Verwendung der Datastream-API in Betracht ziehen, wenn:
Sie benötigen eine detaillierte Kontrolle über den Status
Sie möchten die Möglichkeit nutzen, eine externe Datenbank oder einen externen Endpunkt asynchron aufzurufen (z. B. für Inferenzen)
Sie möchten benutzerdefinierte Timer verwenden (z. B. um benutzerdefiniertes Windowing oder Late-Event-Handling zu implementieren)
-
Sie möchten in der Lage sein, den Ablauf Ihrer Anwendung zu ändern, ohne den Status zurückzusetzen
Anmerkung
Auswahl einer Sprache mit der DataStream API:
SQL kann in jede Flink-Anwendung eingebettet werden, unabhängig von der gewählten Programmiersprache.
Wenn Sie planen, die DataStream API zu verwenden, werden nicht alle Konnektoren in Python unterstützt.
Wenn Sie einen niedrigen latency/high Durchsatz benötigen, sollten Sie Java/Scala unabhängig von der API in Betracht ziehen.
Wenn Sie Async IO in der Process Functions API verwenden möchten, müssen Sie Java verwenden.
Die Wahl der API kann sich auch auf Ihre Fähigkeit auswirken, die Anwendungslogik weiterzuentwickeln, ohne den Status zurücksetzen zu müssen. Dies hängt von einer bestimmten Funktion ab, der Fähigkeit, UID für Operatoren festzulegen, die nur in der DataStream API für Java und Python verfügbar ist. Weitere Informationen finden Sie unter UUIDs für alle Operatoren festlegen
Beginnen Sie mit Streaming-Datenanwendungen
Sie können damit beginnen, eine Anwendung, die Managed Service für Apache Flink nutzt, zu erstellen, die kontinuierlich Streaming-Daten liest und verarbeitet. Verfassen Sie dann Ihren Code mit der IDE Ihrer Wahl und testen Sie ihn mit Live-Streaming-Daten. Sie können auch Ziele konfigurieren, an die Managed Service für Apache Flink die Ergebnisse senden soll.
Um loszulegen, empfehlen wir Ihnen, die folgenden Abschnitte zu lesen:
Alternativ können Sie damit beginnen, ein Managed Service for Apache Flink Studio-Notebook zu erstellen, mit dem Sie Datenströme interaktiv in Echtzeit abfragen und Streamverarbeitungsanwendungen mit Standard-SQL, Python und Scala einfach erstellen und ausführen können. Mit ein paar Klicks können Sie ein serverloses Notebook starten AWS-Managementkonsole, um Datenströme abzufragen und innerhalb von Sekunden Ergebnisse zu erhalten. Um loszulegen, empfehlen wir Ihnen, die folgenden Abschnitte zu lesen:
