Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Optimieren von Gremlin-Abfragen mit explain und profile
Sie können Ihre Gremlin-Abfragen in Amazon Neptune häufig optimieren, um eine bessere Leistung zu erzielen, indem Sie die Informationen verwenden, die Ihnen in den Berichten zur Verfügung stehen, die Sie von Neptune Explain and Profile erhalten. APIs Daher sollten Sie wissen, wie Neptune Gremlin-Traversierungen verarbeitet.
Wichtig
In TinkerPop Version 3.4.11 wurde eine Änderung vorgenommen, die die Richtigkeit der Verarbeitung von Abfragen verbessert, die Abfrageleistung jedoch vorerst ernsthaft beeinträchtigen kann.
Zum Beispiel könnte eine Abfrage dieser Art deutlich langsamer ausgeführt werden:
g.V().hasLabel('airport'). order(). by(out().count(),desc). limit(10). out()
Die Scheitelpunkte nach dem Limit-Schritt werden jetzt aufgrund der Änderung in 3.4.11 nicht optimal abgerufen. TinkerPop Um dies zu vermeiden, können Sie die Abfrage ändern, indem Sie den Schritt barrier() an einer beliebigen Stelle nach order().by() hinzufügen. Beispielsweise:
g.V().hasLabel('airport'). order(). by(out().count(),desc). limit(10). barrier(). out()
TinkerPop 3.4.11 wurde in der Neptune-Engine-Version 1.0.5.0 aktiviert.
Informationen zur Verarbeitung von Gremlin-Traversierungen in Neptune
Wenn eine Gremlin-Traversierung an Neptune gesendet wird, gibt es drei Hauptprozesse für die Transformierung der Traversierung in einen zugrunde liegenden Ausführungsplan zur Ausführung durch die Engine. Diese Schritte sind Parsing, Konvertierung und Optimierung:

Parsing von Traversierungen
Der erste Schritt bei der Verarbeitung einer Traversierung besteht darin, sie in eine gemeinsame Sprache zu parsen. In Neptune ist diese gemeinsame Sprache die Reihe von TinkerPop Schritten, die Teil von sind. TinkerPopAPI
Sie können eine Gremlin-Traversierung als Zeichenfolge oder als Bytecode an Neptune senden. Der REST Endpunkt und die submit() Java-Client-Treibermethode senden Durchläufe als Zeichenketten, wie in diesem Beispiel:
client.submit("g.V()")
Anwendungen und Sprachtreiber, die Gremlin-Sprachvarianten (GLV)
Konvertierung von Traversierungen
Der zweite Schritt bei der Verarbeitung einer Traversierung besteht darin, ihre TinkerPop Schritte in eine Reihe von konvertierten und nicht umgewandelten Neptunschritten umzuwandeln. Die meisten Schritte in der Apache TinkerPop Gremlin-Abfragesprache werden in Neptun-spezifische Schritte konvertiert, die für die Ausführung auf der zugrunde liegenden Neptune-Engine optimiert sind. Wenn bei einer Durchquerung ein TinkerPop Schritt ohne Neptun-Äquivalent gefunden wird, werden dieser Schritt und alle nachfolgenden Schritte der Durchquerung von der Abfrage-Engine verarbeitet. TinkerPop
Weitere Informationen zu den Schritten, die unter bestimmten Umständen konvertiert werden können, finden Sie unter Unterstützung für Gremlin-Schritte.
Optimierung von Traversierungen
Der letzte Schritt bei der Verarbeitung der Traversierung besteht darin, die konvertierten und nicht konvertierten Schritte durch den Optimierer laufen zu lassen, um den besten Ausführungsplan zu ermitteln. Das Ergebnis dieser Optimierung ist der Ausführungsplan, den die Neptune-Engine verarbeitet.
Verwenden des Neptune explain API Gremlin zur Optimierung von Abfragen
Die Neptun-Erklärung API ist nicht dasselbe wie der explain() Gremlin-Schritt. Sie gibt den endgültigen Ausführungsplan zurück, den die Neptune-Engine bei Ausführung der Abfrage verarbeiten würde. Da sie keine Verarbeitung ausführt, gibt sie unabhängig von den verwendeten Parametern denselben Plan zurück und die Ausgabe enthält keine Statistiken zu einer tatsächlichen Ausführung.
Betrachten Sie die folgende einfache Traversierung, die alle Flughafen-Eckpunkte für Anchorage sucht:
g.V().has('code','ANC')
Es gibt zwei Möglichkeiten, diese Reise durch den Neptune durchzuführen. explain API Die erste Möglichkeit besteht darin, den Explain-Endpunkt wie folgt REST aufzurufen:
curl -X POST https://your-neptune-endpoint:port/gremlin/explain -d '{"gremlin":"g.V().has('code','ANC')"}'
Die zweite Möglichkeit besteht in der Verwendung der Zellen-Magics %%gremlin der Neptune-Workbench mit dem Parameter explain. Dadurch wird die im Zellkörper enthaltene Durchquerung an den Neptune weitergegeben explain API und dann die resultierende Ausgabe angezeigt, wenn Sie die Zelle ausführen:
%%gremlin explain g.V().has('code','ANC')
Die resultierende explain API Ausgabe beschreibt Neptuns Ausführungsplan für die Durchquerung. Wie Sie in der Abbildung unten sehen können, umfasst der Plan jeden der 3 Schritte in der Verarbeitungspipeline:

Traversierungsoptimierung durch Untersuchung nicht konvertierter Schritte
Eines der ersten Dinge, nach denen Sie in der explain API Neptun-Ausgabe suchen sollten, sind Gremlin-Schritte, die nicht in native Neptun-Schritte umgewandelt wurden. Wenn in einem Abfrageplan ein Schritt gefunden wird, der nicht in einen nativen Neptune-Schritt konvertiert werden kann, werden dieser und alle nachfolgenden Schritte im Plan durch den Gremlin-Server verarbeitet.
Im Beispiel oben wurden alle Schritte der Traversierung konvertiert. Lassen Sie uns die Ausgabe für diese Traversierung untersuchen: explain API
g.V().has('code','ANC').out().choose(hasLabel('airport'), values('code'), constant('Not an airport'))
Wie Sie in der Abbildung unten sehen können, konnte Neptune den Schritt choose() nicht konvertieren:
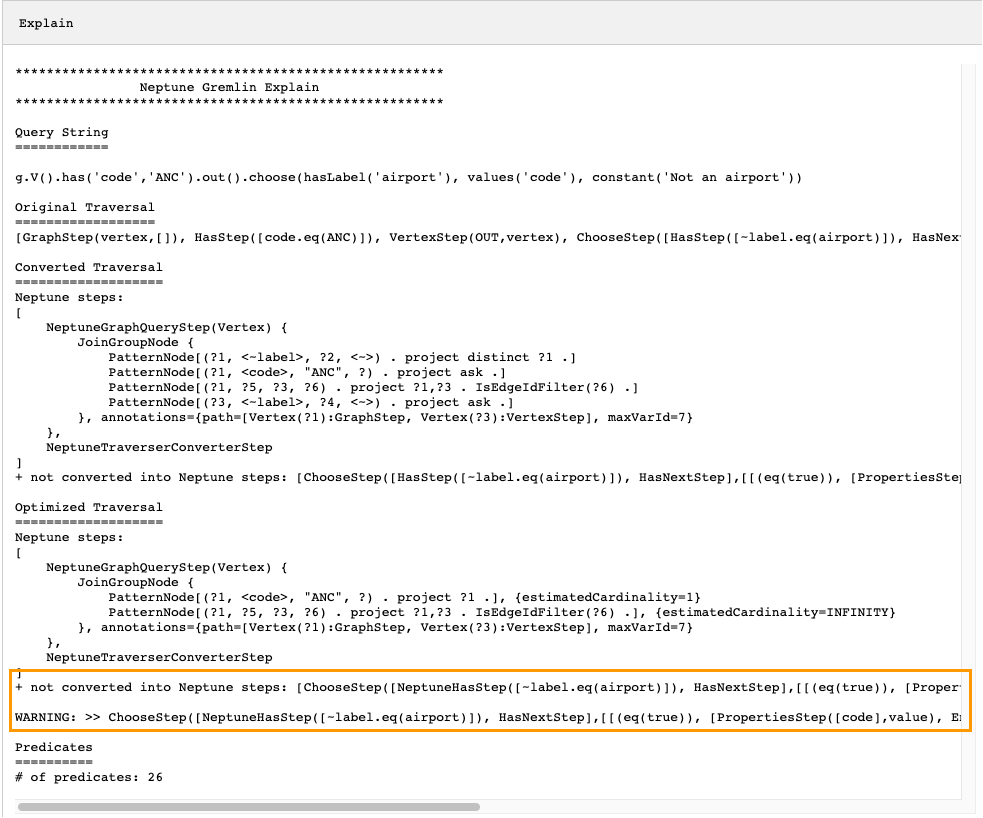
Es gibt verschiedene Möglichkeiten, wie Sie die Leistung der Traversierung optimieren können. Die erste Möglichkeit besteht darin, sie ohne den Schritt neu zu schreiben, der nicht konvertiert werden konnte. Eine andere Möglichkeit besteht darin, den Schritt an das Ende der Traversierung zu verschieben, damit alle anderen Schritte in native Schritte konvertiert werden können.
Ein Abfrageplan mit Schritten, die nicht konvertiert werden können, muss nicht immer optimiert werden. Wenn sich die Schritte, die nicht konvertiert werden können, am Ende der Traversierung befinden und eher die Formatierung der Ausgabe als die Art der Traversierung des Diagramms betreffen, haben sie möglicherweise nur geringe Auswirkungen auf die Leistung.
Eine weitere Sache, auf die Sie bei der Untersuchung der Ergebnisse des Neptune achten sollten, explain API sind Schritte, die keine Indizes verwenden. Die folgende Traversierung sucht nach allen Flughäfen mit Flügen, die in Anchorage landen:
g.V().has('code','ANC').in().values('code')
Die Ergebnisse der Erklärung API für diese Durchquerung lauten wie folgt:
******************************************************* Neptune Gremlin Explain ******************************************************* Query String ============ g.V().has('code','ANC').in().values('code') Original Traversal ================== [GraphStep(vertex,[]), HasStep([code.eq(ANC)]), VertexStep(IN,vertex), PropertiesStep([code],value)] Converted Traversal =================== Neptune steps: [ NeptuneGraphQueryStep(PropertyValue) { JoinGroupNode { PatternNode[(?1, <~label>, ?2, <~>) . project distinct ?1 .] PatternNode[(?1, <code>, "ANC", ?) . project ask .] PatternNode[(?3, ?5, ?1, ?6) . project ?1,?3 . IsEdgeIdFilter(?6) .] PatternNode[(?3, <~label>, ?4, <~>) . project ask .] PatternNode[(?3, ?7, ?8, <~>) . project ?3,?8 . ContainsFilter(?7 in (<code>)) .] }, annotations={path=[Vertex(?1):GraphStep, Vertex(?3):VertexStep, PropertyValue(?8):PropertiesStep], maxVarId=9} }, NeptuneTraverserConverterStep ] Optimized Traversal =================== Neptune steps: [ NeptuneGraphQueryStep(PropertyValue) { JoinGroupNode { PatternNode[(?1, <code>, "ANC", ?) . project ?1 .], {estimatedCardinality=1} PatternNode[(?3, ?5, ?1, ?6) . project ?1,?3 . IsEdgeIdFilter(?6) .], {estimatedCardinality=INFINITY} PatternNode[(?3, ?7=<code>, ?8, <~>) . project ?3,?8 .], {estimatedCardinality=7564} }, annotations={path=[Vertex(?1):GraphStep, Vertex(?3):VertexStep, PropertyValue(?8):PropertiesStep], maxVarId=9} }, NeptuneTraverserConverterStep ] Predicates ========== # of predicates: 26 WARNING: reverse traversal with no edge label(s) - .in() / .both() may impact query performance
Die WARNING-Meldung am Ende der Ausgabe erscheint, weil der Schritt in() in der Traversierung nicht mit einem der 3 Indizes behandelt werden kann, die Neptune verwaltet (siehe Indizierung von Anweisungen in Neptune und Gremlin-Anweisungen in Neptune). Da der Schritt in() keinen Kantenfilter enthält, kann er nicht mit dem Index SPOG, POGS oder GPSO aufgelöst werden. Stattdessen muss Neptune einen Union-Scan ausführen, um die angeforderten Eckpunkte zu suchen, was sehr viel ineffizienter ist.
In dieser Situation gibt es zwei Möglichkeiten für die Optimierung der Traversierung. Die erste Möglichkeit besteht in der Hinzufügung eines oder mehrerer Kriterien zum Schritt in(), um eine indizierte Suche zur Auflösung der Abfrage zu verwenden. Für das Beispiel oben könnte das sein:
g.V().has('code','ANC').in('route').values('code')
Die Ausgabe des Neptune explain API für die überarbeitete Durchquerung enthält nicht mehr die Meldung: WARNING
******************************************************* Neptune Gremlin Explain ******************************************************* Query String ============ g.V().has('code','ANC').in('route').values('code') Original Traversal ================== [GraphStep(vertex,[]), HasStep([code.eq(ANC)]), VertexStep(IN,[route],vertex), PropertiesStep([code],value)] Converted Traversal =================== Neptune steps: [ NeptuneGraphQueryStep(PropertyValue) { JoinGroupNode { PatternNode[(?1, <~label>, ?2, <~>) . project distinct ?1 .] PatternNode[(?1, <code>, "ANC", ?) . project ask .] PatternNode[(?3, ?5, ?1, ?6) . project ?1,?3 . IsEdgeIdFilter(?6) . ContainsFilter(?5 in (<route>)) .] PatternNode[(?3, <~label>, ?4, <~>) . project ask .] PatternNode[(?3, ?7, ?8, <~>) . project ?3,?8 . ContainsFilter(?7 in (<code>)) .] }, annotations={path=[Vertex(?1):GraphStep, Vertex(?3):VertexStep, PropertyValue(?8):PropertiesStep], maxVarId=9} }, NeptuneTraverserConverterStep ] Optimized Traversal =================== Neptune steps: [ NeptuneGraphQueryStep(PropertyValue) { JoinGroupNode { PatternNode[(?1, <code>, "ANC", ?) . project ?1 .], {estimatedCardinality=1} PatternNode[(?3, ?5=<route>, ?1, ?6) . project ?1,?3 . IsEdgeIdFilter(?6) .], {estimatedCardinality=32042} PatternNode[(?3, ?7=<code>, ?8, <~>) . project ?3,?8 .], {estimatedCardinality=7564} }, annotations={path=[Vertex(?1):GraphStep, Vertex(?3):VertexStep, PropertyValue(?8):PropertiesStep], maxVarId=9} }, NeptuneTraverserConverterStep ] Predicates ========== # of predicates: 26
Wenn Sie zahlreiche Traversierungen dieser Art ausführen, besteht eine weitere Möglichkeit darin, sie in einem Neptune-DB-Cluster auszuführen, für den der optionale OSGP-Index aktiviert ist (siehe Einen OSGP Index aktivieren). Die Aktivierung eines OSGP-Indexes hat Nachteile:
Er muss im DB-Cluster aktiviert werden, bevor Daten geladen werden.
Die Einfügeraten für Eckpunkte und Kanten können um bis zu 23 % verlangsamt werden.
Die Speichernutzung wird um ungefähr 20 % steigen.
Leseabfragen, die Anforderungen über alle Indizes verteilen, können zu einer höheren Latenz führen.
Ein OSGP-Index ist für einen eingeschränkten Satz von Abfragemustern sehr sinnvoll. Wenn Sie diese jedoch nicht häufig ausführen, ist es in der Regel besser, die geschriebenen Traversierungen mithilfe der drei primären Indizes aufzulösen.
Verwenden einer großen Anzahl von Prädikaten
Neptune behandelt jede Kantenbezeichnung und jeden eindeutigen Eckpunkt- oder Kanteneigenschaftsnamen in Ihrem Diagramm als Prädikat. ist jedoch für die Verarbeitung einer relativ geringen Anzahl unterschiedlicher Prädikate vorgesehen. Wenn Ihre Diagrammdaten mehr als einige tausend Prädikate enthalten, kann sich die Leistung verschlechtern.
Die Neptune-Ausgabe für explain warnt Sie, wenn dies der Fall ist:
Predicates ========== # of predicates: 9549 WARNING: high predicate count (# of distinct property names and edge labels)
Wenn eine Überarbeitung des Datenmodells zur Reduzierung der Anzahl der Bezeichnungen und Eigenschaften nicht praktikabel ist, können Sie Traversierungen am besten optimieren, indem Sie diese in einem DB-Cluster mit aktiviertem OSGP-Index ausführen, wie oben beschrieben.
Den profile API Neptun-Gremlin zum Tunen von Traversalen verwenden
Der Neptune profile API ist ganz anders als der profile() Gremlinschritt. Wie die explain API enthält auch die Ausgabe den Abfrageplan, den die Neptune-Engine bei der Ausführung der Durchquerung verwendet. Zusätzlich enthält die profile-Ausgabe tatsächliche Ausführungsstatistiken für die Traversierung, abhängig von der Einstellung der Parameter.
Betrachten Sie erneut die folgende einfache Traversierung, die alle Flughafen-Eckpunkte für Anchorage sucht:
g.V().has('code','ANC')
Wie bei der können Sie explain API das mit einem Aufruf aufrufen: profile API REST
curl -X POST https://your-neptune-endpoint:port/gremlin/profile -d '{"gremlin":"g.V().has('code','ANC')"}'
Sie verwenden auch die Zellen-Magics %%gremlin der Neptune-Workbench mit dem Parameter profile. Dadurch wird die im Zellkörper enthaltene Durchquerung an den Neptune weitergegeben profile API und dann die resultierende Ausgabe angezeigt, wenn Sie die Zelle ausführen:
%%gremlin profile g.V().has('code','ANC')
Die resultierende profile API Ausgabe enthält sowohl Neptuns Ausführungsplan für die Durchquerung als auch Statistiken über die Ausführung des Plans, wie Sie in dieser Abbildung sehen können:
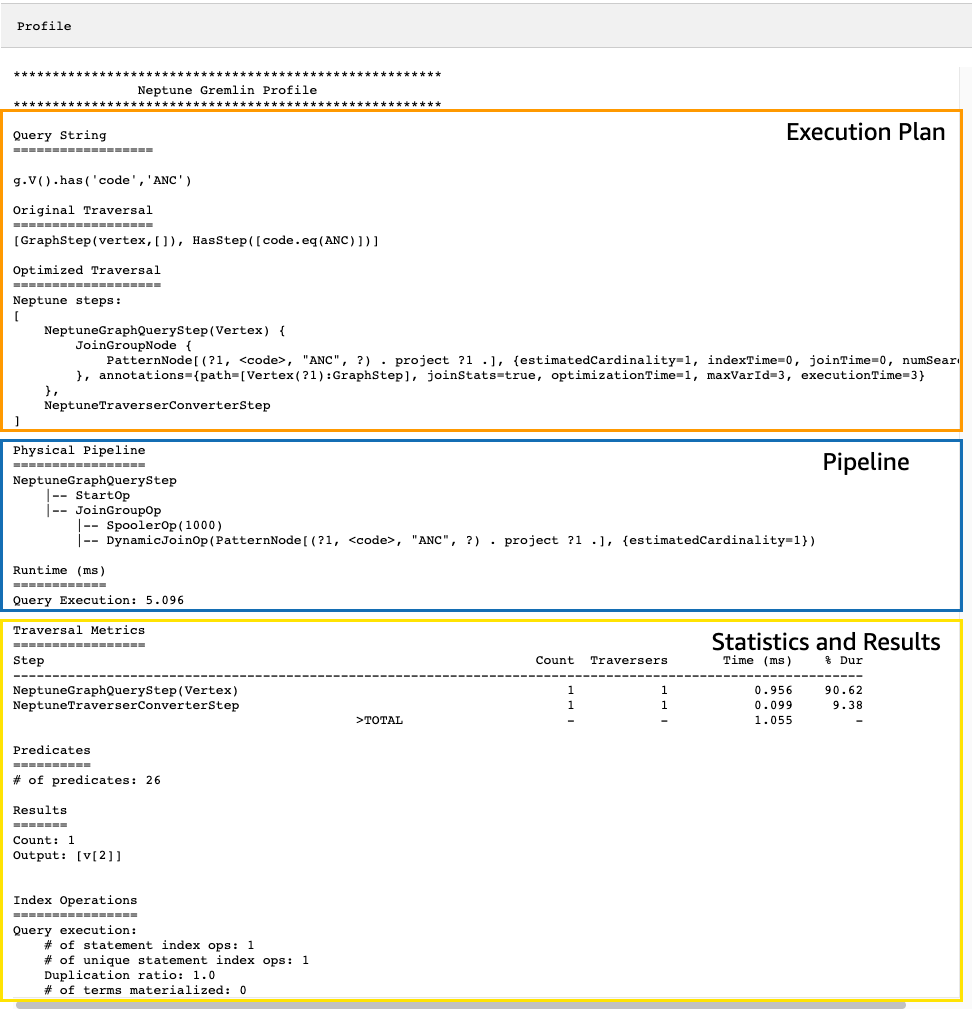
In der profile-Ausgabe enthält der Abschnitt zum Ausführungsplan nur den endgültigen Ausführungsplan für die Traversierung, keine Zwischenschritte. Der Abschnitt zur Pipeline enthält die physischen Pipeline-Operationen, die ausgeführt wurden, sowie die tatsächliche Dauer (in Millisekunden) der Ausführung der Traversierung. Die Laufzeitmetrik ist äußerst nützlich, um während der Optimierung die Dauer von zwei verschiedenen Traversierungsversionen zu vergleichen.
Anmerkung
Die anfängliche Laufzeit einer Traversierung ist in der Regel länger als die nachfolgenden Laufzeiten, da während der ersten Laufzeit die relevanten Daten im Cache gespeichert werden.
Der dritte Abschnitt der profile-Ausgabe enthält Ausführungsstatistiken und die Ergebnisse der Traversierung. Die folgende Traversierung zeigt, wie diese Informationen für die Optimierung einer Traversierung nützlich sein können. Sie sucht alle Flughäfen, deren Name mit „Anchora“ beginnt, und alle Flughäfen, die in zwei Hops von diesen Flughäfen aus erreichbar sind. Anschließend werden Flughafencodes, Flugrouten und Entfernungen zurückgegeben:
%%gremlin profile g.withSideEffect("Neptune#fts.endpoint", "{your-OpenSearch-endpoint-URL"). V().has("city", "Neptune#fts Anchora~"). repeat(outE('route').inV().simplePath()).times(2). project('Destination', 'Route'). by('code'). by(path().by('code').by('dist'))
Traversalmetriken in der Neptun-Ausgabe profile API
Der erste Satz von Metriken, der in allen profile-Ausgaben verfügbar ist, sind die Traversierungsmetriken. Sie sind den Metriken für den Gremlin-Schritt profile() ähnlich, mit einigen Unterschieden:
Traversal Metrics ================= Step Count Traversers Time (ms) % Dur ------------------------------------------------------------------------------------------------------------- NeptuneGraphQueryStep(Vertex) 3856 3856 91.701 9.09 NeptuneTraverserConverterStep 3856 3856 38.787 3.84 ProjectStep([Destination, Route],[value(code), ... 3856 3856 878.786 87.07 PathStep([value(code), value(dist)]) 3856 3856 601.359 >TOTAL - - 1009.274 -
Die erste Spalte der Tabelle für Traversierungsmetriken listet die Schritte auf, die durch die Traversierung ausgeführt werden. Die ersten beiden Schritte sind im Allgemeinen die Neptune-spezifischen Schritte, NeptuneGraphQueryStep und NeptuneTraverserConverterStep.
NeptuneGraphQueryStep stellt die Ausführungszeit für den gesamten Teil der Traversierung dar, der von der Neptune-Engine konvertiert und nativ ausgeführt werden konnte.
NeptuneTraverserConverterStepstellt den Prozess dar, bei dem die Ausgabe dieser konvertierten Schritte in TinkerPop Durchlaufverfahren umgewandelt wird, sodass Schritte, die nicht konvertiert werden konnten, verarbeitet werden können, wenn überhaupt, oder die Ergebnisse in einem -kompatiblen Format zurückgegeben werden können. TinkerPop
Im obigen Beispiel haben wir mehrere nicht konvertierte Schritte, sodass wir sehen, dass jeder dieser TinkerPop Schritte (ProjectStep,PathStep) dann als Zeile in der Tabelle erscheint.
Im Beispiel werden 3.856 Eckpunkte und 3.856 Traverser von NeptuneGraphQueryStep zurückgegeben. Diese Zahlen bleiben während der gesamten restlichen Verarbeitung gleich, da ProjectStep und PathStep die Ergebnisse formatieren, nicht filtern.
Anmerkung
Im TinkerPop Gegensatz dazu optimiert der Neptune-Motor die Leistung nicht, indem er seine und seine NeptuneGraphQueryStep Stufen vergrößert. NeptuneTraverserConverterStep Bulking ist eine TinkerPop Operation, bei der Traversen auf demselben Scheitelpunkt kombiniert werden, um den Betriebsaufwand zu reduzieren. Dadurch unterscheiden sich die Zahlen und. Count Traversers Da Bulking nur in Schritten erfolgt, an die Neptune delegiert TinkerPop, und nicht in Schritten, die Neptune nativ verarbeitet, unterscheiden sich die Spalten und D selten. Count Traverser
Die Spalte „Zeit“ meldet die Anzahl der Millisekunden, die für den Schritt benötigt wurden. Die Spalte % Dur meldet, wie viel Prozent der gesamten Verarbeitungszeit der Schritt in Anspruch genommen hat. Diese Metriken zeigen Ihnen, worauf Sie sich bei der Optimierung konzentrieren sollten, da sie die zeitaufwändigsten Schritte identifizieren.
Operationsmetriken in der Neptun-Ausgabe profile API indizieren
Ein weiterer Satz von Metriken in der Ausgabe des Neptun-Profils API sind die Indexoperationen:
Index Operations ================ Query execution: # of statement index ops: 23191 # of unique statement index ops: 5960 Duplication ratio: 3.89 # of terms materialized: 0
Diese geben Folgendes an:
Die Gesamtzahl der Indexsuchvorgänge.
Die Anzahl der eindeutigen ausgeführten Indexsuchvorgänge.
Das Verhältnis zwischen der Gesamtzahl der Indexsuchvorgänge und den eindeutigen Indexsuchvorgängen. Je niedriger diese Zahl ist, desto weniger Redundanz gibt es.
Die Anzahl der Begriffe aus dem Begriffsverzeichnis.
Metriken in der Neptun-Ausgabe profile API wiederholen
Wenn die Traversierung den Schritt repeat() wie im Beispiel oben gezeigt verwendet, erscheint in der profile-Ausgabe ein Abschnitt mit Wiederholungsmetriken:
Repeat Metrics ============== Iteration Visited Output Until Emit Next ------------------------------------------------------ 0 2 0 0 0 2 1 53 0 0 0 53 2 3856 3856 3856 0 0 ------------------------------------------------------ 3911 3856 3856 0 55
Diese geben Folgendes an:
Die Anzahl der Schleifen für eine Zeile (Spalte
Iteration).Die Anzahl der von der Schleife aufgerufenen Elemente (Spalte
Visited).Die Anzahl der von der Schleife ausgegebenen Elemente (Spalte
Output).Das letzte von der Schleife ausgegebene Element (Spalte
Until).Die Anzahl der von der Schleife ausgesendeten Elemente (Spalte
Emit).Die Anzahl der Elemente, die von der Schleife an die nachfolgende Schleife übergeben wurden (Spalte
Next).
Diese Wiederholungsmetriken sind sehr nützlich, um den Verzweigungsfaktor der Traversierung zu verstehen und ein Gefühl dafür zu bekommen, wie viel Arbeit von der Datenbank geleistet wird. Sie können diese Zahlen für die Diagnose von Leistungsproblemen verwenden, insbesondere wenn die Leistung derselben Traversierung mit unterschiedlichen Parametern stark unterschiedlich ist.
Metriken für die Volltextsuche in der profile API Neptun-Ausgabe
Wenn bei einer Durchquerung eine Volltextsuche verwendet wird, wie im obigen Beispiel, wird in der Ausgabe ein Abschnitt mit den Metriken für die Volltextsuche () FTS angezeigt: profile
FTS Metrics ============== SearchNode[(idVar=?1, query=Anchora~, field=city) . project ?1 .], {endpoint=your-OpenSearch-endpoint-URL, incomingSolutionsThreshold=1000, estimatedCardinality=INFINITY, remoteCallTimeSummary=[total=65, avg=32.500000, max=37, min=28], remoteCallTime=65, remoteCalls=2, joinTime=0, indexTime=0, remoteResults=2} 2 result(s) produced from SearchNode above
Darin wird die an den ElasticSearch (ES) -Cluster gesendete Abfrage angezeigt und es werden verschiedene Metriken zur Interaktion mit gemeldet ElasticSearch , anhand derer Sie Leistungsprobleme im Zusammenhang mit der Volltextsuche lokalisieren können:
-
Zusammenfassende Informationen zu den Aufrufen des ElasticSearch Index:
Die Gesamtzahl der Millisekunden, die von allen benötigt wurden, um die Abfrage () remoteCalls zu erfüllen.
totalDie durchschnittliche Anzahl der Millisekunden, die in a () verbracht wurden. remoteCall
avgDie Mindestanzahl von Millisekunden, die in a () verbracht wurden. remoteCall
minDie maximale Anzahl von Millisekunden, die in a () verbracht wurden. remoteCall
max
Gesamtzeit, die remoteCalls bis ElasticSearch () verbraucht hat.
remoteCallTimeDie Anzahl der Dateien, die bis ElasticSearch (
remoteCalls) remoteCalls gemacht wurden.Die Anzahl der Millisekunden, die für Zusammenführungen von ElasticSearch Ergebnissen () aufgewendet wurden.
joinTimeDie Anzahl der Millisekunden, die für Index-Lookups (
indexTime) aufgewendet wurden.Die Gesamtzahl der von () zurückgegebenen ElasticSearch Ergebnisse.
remoteResults
