Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Klonen von Datenbanken in Neptune
Mit dem Klonen von Datenbanken können Sie schnell und kosteneffizient Klone aller Ihrer Datenbanken in Amazon Neptune erstellen. Die Klon-Datenbanken erfordern nur eine kleine Menge an zusätzlichem Speicherplatz beim ersten Erstellungsvorgang. Beim Klonen von Datenbanken wird ein Copy-On-Write-Protokoll verwendet. Die Daten werden zu dem Zeitpunkt, an dem sie sich ändern, entweder in den Quelldatenbanken oder in den Klondatenbanken kopiert. Sie können mehrere Klone aus demselben DB-Cluster erstellen. Es ist auch möglich, zusätzliche Klone aus anderen Klonen zu erstellen. Weitere Informationen zur Funktionsweise von Copy-On-Write-Protokollen im Kontext von Neptune-Speicherplatz finden Sie unter Copy-On-Write-Protokoll.
Sie können das Klonen von Datenbanken in einer Vielzahl von Anwendungsfällen einsetzen, insbesondere dann, wenn Sie keine Auswirkungen auf Ihre Produktionsumgebung haben wollen, wie zum Beispiel in den folgenden Fällen:
Experimentieren Sie mit Änderungen und bewerten Sie die Auswirkungen, wie z. B. die Änderung von Schemata oder Parametergruppen.
Führen Sie Workload-intensive Vorgänge durch, wie zum Beispiel das Exportieren von Daten oder das Ausführen von analytischen Abfragen.
Erstellen Sie eine Kopie eines Produktions-DB-Clusters in einer Nicht-Produktionsumgebung zu Entwicklungs- oder Testzwecken.
So erstellen Sie einen Klon eines DB-Clusters mittels der AWS Management Console
Melden Sie sich bei der AWS-Managementkonsole an und öffnen Sie die Amazon-Neptune-Konsole unter https://console.aws.amazon.com/neptune/home
. Wählen Sie im Navigationsbereich Instances aus. Wählen Sie eine primäre Instance für das DB-Cluster aus, für das Sie einen Klon erstellen möchten.
Wählen Sie Instance actions (Instance-Aktionen) und anschließend Create clone (Klon erstellen) aus.
-
Geben Sie auf der Seite Create Clone (Klon erstellen) einen Namen für die primäre Instance des DB-Klon-Clusters als DB Instance Identifier (DB-Instance-ID) ein.
Wenn Sie möchten, können Sie weitere beliebige Einstellungen für das Klon-DB-Cluster konfigurieren. Weitere Informationen zu den unterschiedlichen DB-Cluster-Einstellungen finden Sie unter Starten über die Konsole.
Wählen Sie Create Clone (Klon erstellen) aus, um das DB-Klon-Cluster zu starten.
So erstellen Sie einen Klon eines DB-Clusters mittels der AWS CLI
-
Rufen Sie den Neptune-Befehl restore-db-cluster-to-point-in-time auf und stellen Sie die folgenden Werte bereit:
--source-db-cluster-identifier– Der Name des DB-Quell-Clusters, dessen Klon erstellt werden soll.--db-cluster-identifier– Der Name des DB-Klon-Clusters.--restore-type copy-on-write– Der Wert fürcopy-on-writegibt an, dass ein DB-Klon-Cluster erstellt werden soll.--use-latest-restorable-time– Dies gibt an, dass die letzte Sicherung verwendet werden soll, die wiederhergestellt werden kann.
Anmerkung
Der restore-db-cluster-to-point-in-timeAWS CLI-Befehl klont nur das DB-Cluster, nicht die DB-Instances für dieses DB-Cluster.
Im folgenden Linux/UNIX-Beispiel wird ein Klon aus dem
source-db-cluster-id-DB-Cluster erstellt und alsdb-clone-cluster-idbenannt.aws neptune restore-db-cluster-to-point-in-time \ --region us-east-1 \ --source-db-cluster-identifier source-db-cluster-id \ --db-cluster-identifier db-clone-cluster-id \ --restore-type copy-on-write \ --use-latest-restorable-timeDas gleiche Beispiel funktioniert unter Windows, wenn das
\-Zeilenende-Escape-Zeichen durch das Windows-^-Äquivalent ersetzt wird:aws neptune restore-db-cluster-to-point-in-time ^ --region us-east-1 ^ --source-db-cluster-identifier source-db-cluster-id ^ --db-cluster-identifier db-clone-cluster-id ^ --restore-type copy-on-write ^ --use-latest-restorable-time
Einschränkungen
Das DB-Klonen in Neptune unterliegt den folgenden Einschränkungen:
Sie können Klon-Datenbanken nicht über AWS-Regionen hinweg erstellen. Die Klon-Datenbanken müssen in derselben Region wie die Quelldatenbanken erstellt worden sein.
Eine Klon-Datenbank verwendet stets den neuesten Patch der Neptune-Engine-Version der Datenbank, deren Klon sie ist. Dies gilt auch dann, wenn die Quelldatenbank noch nicht auf diese Patch-Version aktualisiert wurde. Die Engine-Version selbst ändert sich jedoch nicht.
Zurzeit können Sie maximal 15 Klone pro Kopie Ihres Neptune-DB-Clusters erstellen, einschließlich Klonen von anderen Klonen. Wenn Sie dieses Limit erreicht haben, müssen Sie eine weitere Kopie Ihrer Datenbank erstellen, anstatt sie zu klonen. Wenn Sie eine neue Kopie erstellen, kann diese jedoch erneut bis zu 15 Klone haben.
Die kontoübergreifende DB-Klonung wird aktuell nicht unterstützt.
Sie können eine andere Virtual Private Cloud (VPC) für Ihren Klon anbieten. Die Subnetze in diesen VPCs müssen jedoch demselben Datensatz der Availability Zones zugeordnet sein.
Copy-On-Write-Protokoll für das DB-Klonen
Die folgenden Szenarien veranschaulichen, wie das Copy-On-Write-Protokoll funktioniert.
Neptune-Datenbank vor dem Klonen
Die Daten in einer Quelldatenbank werden in Seiten gespeichert. Im folgenden Diagramm hat die Quelldatenbank vier Seiten.

Neptune-Datenbank nach dem Klonen
Nach der Datenbankklonung gibt es, wie das folgende Diagramm zeigt, in der Quelldatenbank keine Änderungen. Sowohl die Quelldatenbank als auch die Klondatenbank verweisen auf dieselben vier Seiten. Es wurden keine Seiten physikalisch kopiert, daher wird kein zusätzlicher Speicherplatz benötigt.
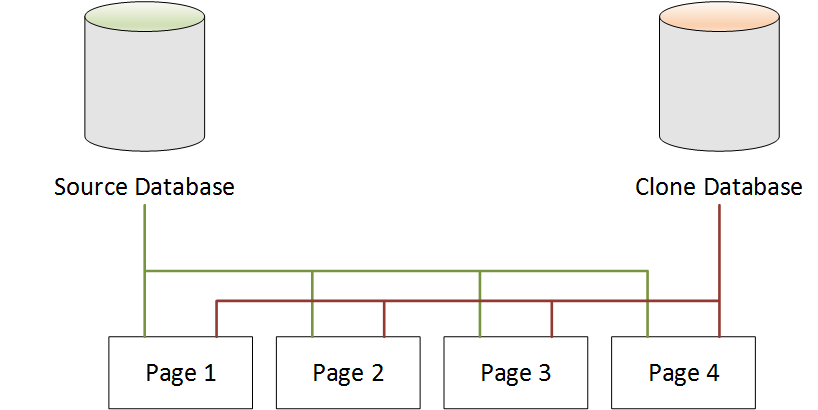
Bei einer Änderung an der Quelldatenbank
Im folgenden Beispiel wird in der Quelldatenbank eine Änderung an den Daten auf Page
1 vorgenommen. Anstatt in den ursprünglichen Page 1 zu schreiben, wird zusätzlicher Speicher verwendet, um eine neue Seite mit dem Namen Page 1' zu erstellen. Die Quelldatenbank verweist nun auf die neue Page 1' und auch auf Page 2, Page 3 und Page 4. Die Klondatenbank verweist weiterhin auf Page 1 über Page 4.
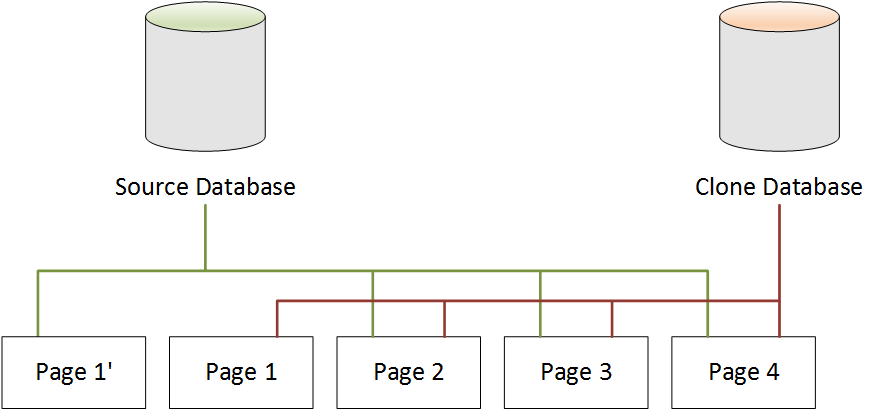
Bei einer Änderung an der Klondatenbank
Im folgenden Diagramm hat sich auch die Klondatenbank geändert, diesmal auf Page 4. Anstatt den ursprünglichen Page 4 zu schreiben, wird zusätzlicher Speicher verwendet, um eine neue Seite mit dem Namen Page 4' zu erstellen. Die Quelldatenbank verweist weiter auf Page 1' und auch auf Page 2 über Page 4. Die Klondatenbank verweist jetzt jedoch auf Page 1 über Page 3 und auch auf Page 4'.
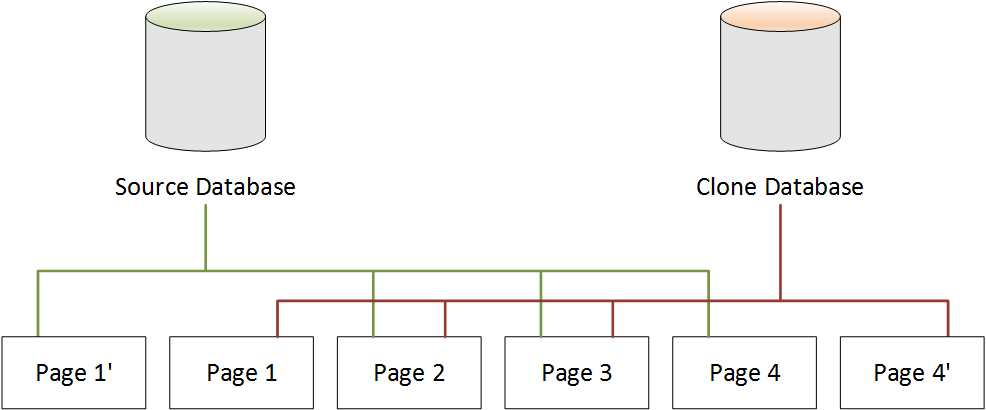
Wie im zweiten Szenario gezeigt, ist nach der Datenbankklonung zum Zeitpunkt der Klon-Erstellung kein zusätzlicher Speicherplatz erforderlich. Da jedoch Änderungen sowohl an der Quell- als auch an der Klondatenbank vorgenommen werden, werden nur die geänderten Seiten erstellt, wie im dritten und vierten Szenario erklärt wird. Mit den über die Zeit zunehmenden Änderungen in der Quell- und Klondatenbank werden Sie zunehmend mehr Speicherplatz benötigen, um Änderungen zu erfassen und zu speichern.
Löschen einer Quelldatenbank
Das Löschen einer Quelldatenbank wirkt sich nicht auf die zugehörigen Klondatenbanken aus. Die Klondatenbanken verweisen weiterhin auf die Seiten, die vorher zur Quelldatenbank gehörten.
