Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwaltung des Cluster-Cachach
Caching ist eine der wichtigsten Funktionen jeder Datenbank (DB), da es dazu beiträgt, die Festplatten-I/O zu reduzieren. Die Daten, auf die am häufigsten zugegriffen wird, werden in einem Speicherbereich gespeichert, der als Puffercache bezeichnet wird. Wenn eine Abfrage häufig ausgeführt wird, ruft sie die Daten direkt aus dem Cache statt von der Festplatte ab. Dies ist schneller und bietet eine bessere Skalierbarkeit und Anwendungsleistung. Sie konfigurieren die PostgreSQL-Cachegröße mithilfe desshared_buffers Parameters. Weitere Informationen finden Sie unter Memory
Nach einem Failover ist das Cluster Cache Management (CCM) in der Amazon Aurora PostgreSQL-Compatible Edition darauf ausgelegt, die Leistung der Anwendungs- und Datenbankwiederherstellung zu verbessern. In einer typischen Failover-Situation ohne CCM kommt es möglicherweise zu einem temporären, aber erheblichen Leitungsabfall. Der Grund ist, dass der Failover-DB-Instance der Failover-DB-Instance der Failover-DB-Instance Instance Instance Instance Ein leerer Cache wird auch als kalter Cache bezeichnet. Die DB-Instance muss von der Festplatte lesen, was langsamer ist als das Lesen aus dem Cache.
Wenn Sie CCM implementieren, wählen Sie eine bevorzugte Reader-DB-Instance aus, und CCM synchronisiert seinen Cache-Speicher kontinuierlich mit dem der primären oder Writer-DB-Instance. Wenn ein Failover auftritt, wird die bevorzugte Reader-DB-Instance auf die neue Writer-DB-Instance befördert. Da es bereits über einen Cache-Speicher, einen sogenannten warmen Cache, verfügt, werden die Auswirkungen des Failovers auf die Anwendungsleistung minimiert.
Wie funktioniert das Cluster-Cache-Management?
Failover-DB-Instances befinden sich in anderen Availability Zones als die primäre Writer-DB-Instance. Die bevorzugte Reader-DB-Instance ist das Prioritäts-Failover-Ziel, das spezifiziert wird, indem ihr die Tier-0-Prioritätsstufe zugewiesen wird.
Anmerkung
Die Prioritätsstufe für das Hochstufen gibt die Reihenfolge an, in der ein Aurora-Reader nach einem Ausfall zur Writer-DB-Instance hochgestuft wird. Gültige Werte sind 0 – 15, wobei 0 die erste und 15 die letzte Prioritätsstufe darstellt. Weitere Informationen zur Hochstufungspriorität finden Sie unter Fehlertoleranz für einen Aurora-DB-Cluster. Das Ändern der Hochstufungspriorität führt nicht zu einem Nutzungsausfall.
CCM synchronisiert den Cache von der Writer-DB-Instance mit der bevorzugten Reader-DB-Instance. Die Reader-DB-Instance sendet den Satz von Pufferadressen, die derzeit zwischengespeichert sind, als Bloom-Filter an die Writer-DB-Instance. Ein Bloomfilter ist eine probabilistische, speichereffiziente Datenstruktur, mit der getestet wird, ob ein Element Teil einer Menge ist. Die Verwendung eines Bloom-Filters verhindert, dass die Reader-DB-Instance wiederholt dieselben Pufferadressen an die Writer-DB-Instance sendet. Wenn die Writer-DB-Instance den Bloom-Filter empfängt, vergleicht sie die Blöcke in ihrem Puffercache und sendet häufig verwendete Puffer an die Reader-DB-Instance. Standardmäßig gilt ein Puffer als häufig verwendet, wenn er eine Benutzungszahl von mehr als drei hat.
Das folgende Diagramm zeigt, wie CCM den Puffercache der Writer-DB-Instance mit der bevorzugten Reader-DB-Instance synchronisiert.
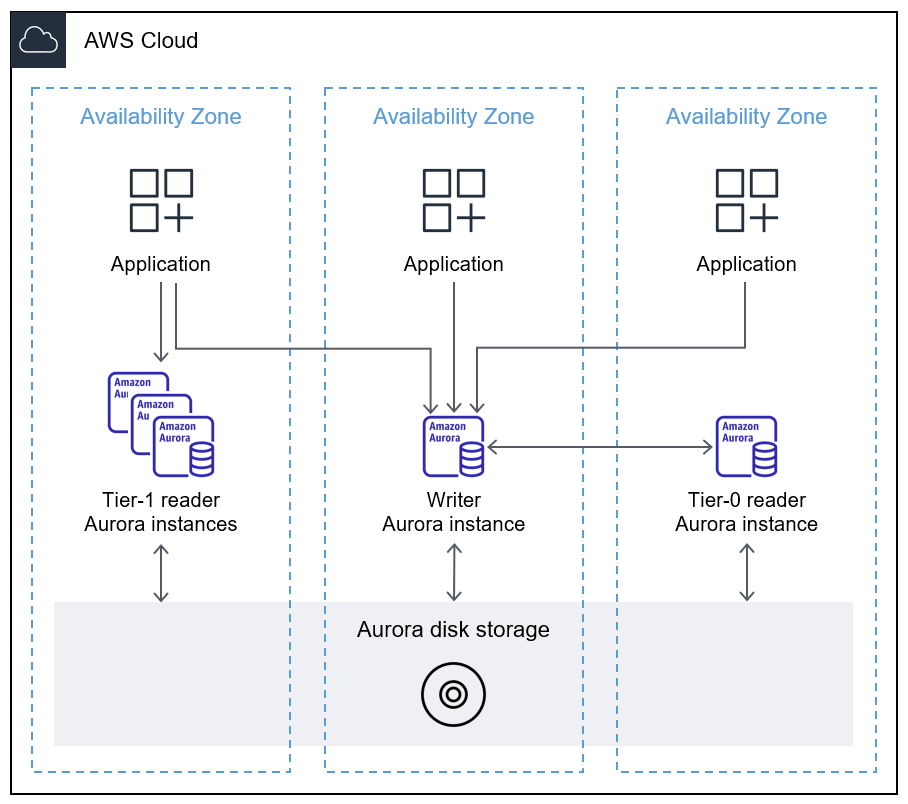
Weitere Informationen zu CCM finden Sie unter Schnelle Wiederherstellung nach einem Failover mit Cluster-Cache-Management für Aurora PostgreSQL (Aurora-Dokumentation) und Einführung in das Aurora PostgreSQL-Cluster-Cache-Management
Einschränkungen
Die CCM-Funktion hat die folgenden Einschränkungen:
-
Die Reader-DB-Instance muss den gleichen Typ und die gleiche Größe der DB-Instance-Klasse wie die Writer-DB-Instance haben, z. B.
r5.2xlargeoderdb.r5.xlarge. -
CCM wird für Aurora-PostgreSQL-DB-Cluster, die Teil der globalen Aurora-Datenbanken sind, nicht unterstützt.
Anwendungsfälle für die Cluster-CachachachVerwaltung
In einigen Branchen, wie dem Einzelhandel, dem Bank- und Finanzwesen, können Verzögerungen von nur wenigen Millisekunden zu Problemen mit der Anwendungsleistung führen und zu erheblichen Geschäftsverlusten führen. Da CCM dabei hilft, die Anwendungs- und Datenbankleistung wiederherzustellen, indem es den Puffercache der primären Datenbankinstanz mit der bevorzugten Backup-Instance synchronisiert, kann es dazu beitragen, Unternehmensverluste im Zusammenhang mit Failovers zu verhindern.
