Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Ein Automobilunternehmen möchte ein transaktionales Komponentenverwaltungssystem aufbauen, um alle verfügbaren Autoteile zu speichern und danach zu suchen und Beziehungen zwischen verschiedenen Komponenten und Teilen aufzubauen. Ein Auto enthält beispielsweise mehrere Batterien, jede Batterie enthält mehrere High-Level-Module, jedes Modul enthält mehrere Zellen und jede Zelle enthält mehrere Low-Level-Komponenten.
Im Allgemeinen ist für den Aufbau eines hierarchischen Beziehungsmodells eine Graphdatenbank wie Amazon Neptune eine bessere Wahl. In einigen Fällen ist Amazon DynamoDB jedoch aufgrund seiner Flexibilität, Sicherheit, Leistung und Skalierbarkeit eine bessere Alternative für die hierarchische Datenmodellierung.
Sie könnten beispielsweise ein System erstellen, in dem 80–90 Prozent der Abfragen transaktionaler Natur sind, wofür DynamoDB gut geeignet ist. In diesem Beispiel sind die anderen 10—20 Prozent der Abfragen relational, sodass eine Graphdatenbank wie Neptune besser passt. In diesem Fall könnte die Integration einer zusätzlichen Datenbank in die Architektur, die nur 10—20 Prozent der Abfragen erfüllt, die Kosten erhöhen. Dies erhöht auch den betrieblichen Aufwand, der durch die Wartung mehrerer Systeme und die Synchronisation der Daten entsteht. Stattdessen können Sie diese 10 bis 20 Prozent relationalen Abfragen in DynamoDB modellieren.
Wenn Sie einen Beispielbaum für Fahrzeugkomponenten grafisch darstellen, können Sie die Beziehung zwischen diesen Komponenten besser abbilden. Das folgende Diagramm zeigt ein Abhängigkeitsdiagramm mit vier Stufen. CM1 ist die oberste Komponente für das Beispielfahrzeug selbst. Es hat zwei Unterkomponenten für zwei Beispielbatterien, und CM2 . CM3 Jede Batterie hat zwei Unterkomponenten, die Module. CM2 hat Module CM4 und CM5, und CM3 hat Module CM6 und CM7. Jedes Modul hat mehrere Unterkomponenten, nämlich die Zellen. Das CM4 Modul hat zwei Zellen CM8 und CM9. CM5 hat eine Zelle, CM1 0. CM6 und CM7 habe noch keine zugehörigen Zellen.
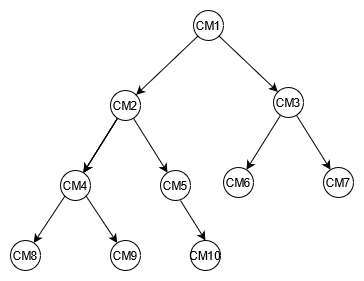
In diesem Handbuch werden dieser Baum und seine Komponenten-IDs als Referenz verwendet. Eine der obersten Komponenten wird als Elternteil bezeichnet und eine Unterkomponente wird als Kind bezeichnet. Beispielsweise CM1 ist die oberste Komponente das übergeordnete Element von CM2 und CM3. CM2 ist das übergeordnete Element von CM4 und CM5. Dadurch werden die Eltern-Kind-Beziehungen grafisch dargestellt.
In der Baumstruktur können Sie das vollständige Abhängigkeitsdiagramm einer Komponente sehen. Zum Beispiel CM8 ist abhängig von CM4, was ist abhängig von CM2, was ist abhängig von CM1. Der Baum definiert den vollständigen Abhängigkeitsgraphen als Pfad. Ein Pfad beschreibt zwei Dinge:
-
Das Abhängigkeitsdiagramm
-
Die Position im Baum
Ausfüllen der Vorlagen für Geschäftsanforderungen:
Geben Sie Informationen über Ihre Benutzer an:
Nutzer |
Beschreibung |
Mitarbeiter |
Interner Mitarbeiter des Automobilunternehmens, der Informationen über Autos und deren Komponenten benötigt |
Geben Sie Informationen über die Datenquellen und die Art und Weise, wie Daten aufgenommen werden, an:
Quelle |
Beschreibung |
Nutzer |
Managementsystem |
System, das alle Daten zu verfügbaren Autoteilen und deren Beziehungen zu anderen Komponenten und Teilen speichert. |
Mitarbeiter |
Geben Sie Informationen darüber an, wie Daten genutzt werden:
Verbraucher |
Beschreibung |
Nutzer |
Managementsystem |
Ruft alle unmittelbar untergeordneten Komponenten einer übergeordneten Komponenten-ID ab. |
Mitarbeiter |
Managementsystem |
Ruft eine rekursive Liste aller untergeordneten Komponenten für eine Komponenten-ID ab. |
Mitarbeiter |
Managementsystem |
Sehen Sie sich die Vorfahren einer Komponente an. |
Mitarbeiter |
