Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Fähigkeit 2. Bereitstellung von sicherem Zugriff, Nutzung und Implementierung generativer RAG KI-Techniken
Das folgende Diagramm zeigt die AWS Dienste, die für die Funktion Generative AI Account for Retrieval Augmented Generation (RAG) empfohlen werden. Der Umfang dieses Szenarios besteht in der Sicherung der RAG Funktionalität.
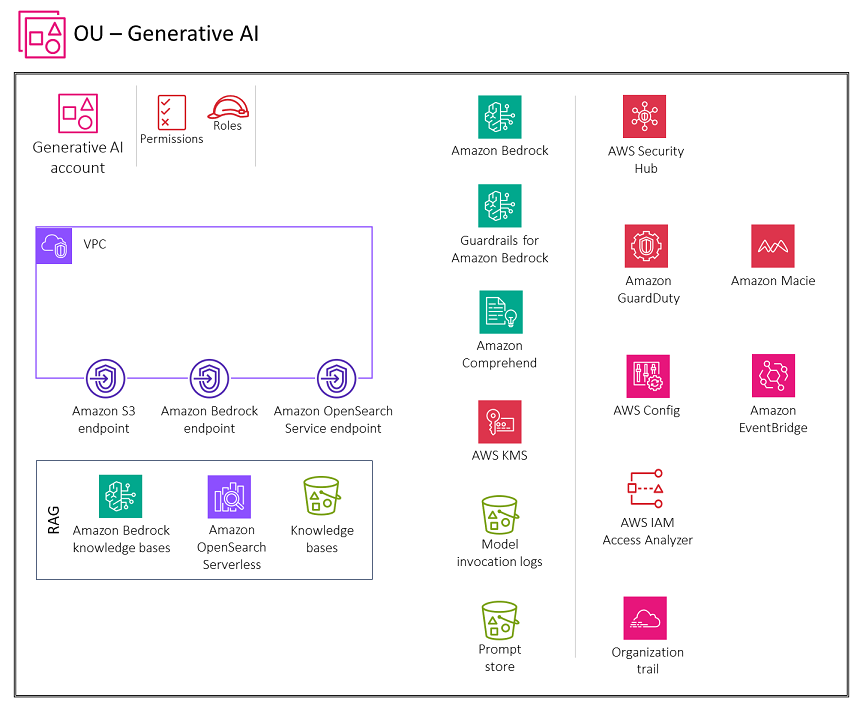
Das Generative AI-Konto umfasst Dienste, die für das Speichern von Einbettungen in einer Vektordatenbank, das Speichern von Konversationen für Benutzer und die Verwaltung eines schnellen Speichers erforderlich sind, sowie eine Reihe erforderlicher Sicherheitsdienste zur Implementierung von Sicherheitsvorkehrungen und zentraler Sicherheitssteuerung. Sie sollten Amazon S3-Gateway-Endpunkte für die Modellaufrufprotokolle, den Prompt Store und die Knowledge-Base-Datenquellen-Buckets in Amazon S3 erstellen, für deren Zugriff die VPC Umgebung konfiguriert ist. Sie sollten auch einen CloudWatch Logs-Gateway-Endpunkt für die CloudWatch Protokolle erstellen, für deren Zugriff die VPC Umgebung konfiguriert ist.
Begründung
Retrieval Augmented Generation (RAG)
Wenn Sie Benutzern Zugriff auf Amazon Bedrock-Wissensdatenbanken gewähren, sollten Sie die folgenden wichtigen Sicherheitsaspekte berücksichtigen:
-
Sicherer Zugriff auf den Modellaufruf, die Wissensdatenbanken, den Konversationsverlauf und den Prompt-Speicher
-
Verschlüsselung von Konversationen, Speicherung von Eingabeaufforderungen und Wissensdatenbanken
-
Warnmeldungen vor potenziellen Sicherheitsrisiken wie der unverzüglichen Dateneingabe oder der Offenlegung vertraulicher Informationen
Im nächsten Abschnitt werden diese Sicherheitsüberlegungen und die generative KI-Funktionalität erörtert.
Designüberlegungen
Wir empfehlen, die Anpassung eines FM mit sensiblen Daten zu vermeiden (siehe den Abschnitt zur generativen KI-Modellanpassung weiter unten in diesem Handbuch). Verwenden Sie diese RAG Technik stattdessen, um mit vertraulichen Informationen zu interagieren. Diese Methode bietet mehrere Vorteile:
-
Bessere Kontrolle und bessere Sichtbarkeit. Indem Sie sensible Daten vom Modell trennen, können Sie die vertraulichen Informationen besser kontrollieren und transparenter gestalten. Die Daten können bei Bedarf einfach bearbeitet, aktualisiert oder entfernt werden, was zu einer besseren Datenverwaltung beiträgt.
-
Eindämmung der Offenlegung sensibler Informationen. RAGermöglicht kontrolliertere Interaktionen mit sensiblen Daten beim Modellaufruf. Dies trägt dazu bei, das Risiko einer unbeabsichtigten Offenlegung vertraulicher Informationen zu verringern, die auftreten könnte, wenn die Daten direkt in die Modellparameter integriert würden.
-
Flexibilität und Anpassungsfähigkeit. Die Trennung sensibler Daten vom Modell sorgt für mehr Flexibilität und Anpassungsfähigkeit. Wenn sich Datenanforderungen oder Vorschriften ändern, können die sensiblen Informationen aktualisiert oder geändert werden, ohne dass das gesamte Sprachmodell neu trainiert oder neu erstellt werden muss.
Amazon Bedrock Wissensdatenbanken
Sie können Amazon Bedrock Knowledge Bases verwenden, um RAG Anwendungen zu erstellen, indem Sie sich sicher und effizient FMs mit Ihren eigenen Datenquellen verbinden. Diese Funktion verwendet Amazon OpenSearch Serverless als Vektorspeicher, um relevante Informationen effizient aus Ihren Daten abzurufen. Die Daten werden dann vom FM verwendet, um Antworten zu generieren. Ihre Daten werden von Amazon S3 mit der Wissensdatenbank synchronisiert, und Einbettungen
Sicherheitsüberlegungen
Generative RAG KI-Workloads sind mit einzigartigen Risiken konfrontiert, darunter Datenexfiltration von Datenquellen und Vergiftung von RAG RAG Datenquellen durch sofortige Injektionen oder Malware durch Bedrohungsakteure. Die Wissensdatenbanken von Amazon Bedrock bieten robuste Sicherheitskontrollen für Datenschutz, Zugriffskontrolle, Netzwerksicherheit, Protokollierung und Überwachung sowie Eingabe-/Ausgabevalidierung, die zur Minderung dieser Risiken beitragen können.
Abhilfemaßnahmen
Datenschutz
Verschlüsseln Sie Ihre gespeicherten Wissensdatenbankdaten mithilfe eines vom Kunden verwalteten AWS Key Management Service (AWSKMS) -Schlüssels, den Sie selbst erstellen, besitzen und verwalten. Wenn Sie einen Datenerfassungsauftrag für Ihre Wissensdatenbank konfigurieren, verschlüsseln Sie den Job mit einem vom Kunden verwalteten Schlüssel. Wenn Sie sich dafür entscheiden, Amazon Bedrock in Amazon OpenSearch Service einen Vector Store für Ihre Wissensdatenbank erstellen zu lassen, kann Amazon Bedrock einen AWS KMS Schlüssel Ihrer Wahl zur Verschlüsselung an Amazon OpenSearch Service weitergeben.
Sie können Sitzungen verschlüsseln, in denen Sie Antworten generieren, indem Sie eine Wissensdatenbank mit einem Schlüssel abfragen. AWS KMS Sie speichern die Datenquellen für Ihre Wissensdatenbank in Ihrem S3-Bucket. Wenn Sie Ihre Datenquellen in Amazon S3 mit einem vom Kunden verwalteten Schlüssel verschlüsseln, fügen Sie Ihrer Knowledge-Base-Servicerolle eine Richtlinie hinzu. Wenn der Vector Store, der Ihre Wissensdatenbank enthält, mit einem AWS Secrets Manager Manager-Geheimnis konfiguriert ist, verschlüsseln Sie das Geheimnis mit einem vom Kunden verwalteten Schlüssel.
Weitere Informationen und die zu verwendenden Richtlinien finden Sie unter Verschlüsselung von Wissensdatenbank-Ressourcen in der Amazon Bedrock-Dokumentation.
Verwalten von Identitäten und Zugriff
Erstellen Sie eine benutzerdefinierte Servicerolle für Wissensdatenbanken für Amazon Bedrock, indem Sie dem Prinzip der geringsten Rechte folgen. Schaffen Sie eine Vertrauensbeziehung, die es Amazon Bedrock ermöglicht, diese Rolle zu übernehmen und Wissensdatenbanken zu erstellen und zu verwalten. Fügen Sie der benutzerdefinierten Knowledgebase-Servicerolle die folgenden Identitätsrichtlinien hinzu:
-
Berechtigungen für den Zugriff auf Amazon Bedrock-Modelle
-
Berechtigungen für den Zugriff auf Ihre Datenquellen in Amazon S3
-
Berechtigungen für den Zugriff auf Ihre Vektordatenbank in OpenSearch Service
-
Berechtigungen für den Zugriff auf Ihren Amazon Aurora Aurora-Datenbankcluster (optional)
-
Berechtigungen für den Zugriff auf eine Vektordatenbank, die mit einem AWS Secrets Manager Manager-Geheimnis konfiguriert ist (optional)
-
Berechtigungen für AWS die Verwaltung eines AWS KMS Schlüssels für die vorübergehende Datenspeicherung während der Datenaufnahme
-
Berechtigungen zum Chatten mit Ihrem Dokument
-
Berechtigungen für AWS die Verwaltung einer Datenquelle über das AWS Konto eines anderen Benutzers (optional).
Wissensdatenbanken unterstützen Sicherheitskonfigurationen zur Einrichtung von Datenzugriffsrichtlinien für Ihre Wissensdatenbank und Netzwerkzugriffsrichtlinien für Ihre private Amazon OpenSearch Serverless-Wissensdatenbank. Weitere Informationen finden Sie unter Erstellen einer Wissensdatenbank und Servicerollen in der Amazon Bedrock-Dokumentation.
Validierung von Eingabe und Ausgabe
Die Eingabevalidierung ist für die Amazon Bedrock-Wissensdatenbanken von entscheidender Bedeutung. Verwenden Sie den Malware-Schutz in Amazon S3, um Dateien auf schädliche Inhalte zu scannen, bevor Sie sie in eine Datenquelle hochladen. Weitere Informationen finden Sie im AWS Blogbeitrag Integration von Malware-Scanning in Ihre Datenerfassungspipeline mit Antivirus für Amazon S3
Identifizieren und filtern Sie potenzielle Prompt-Injections bei Benutzer-Uploads in Wissensdatenbanken heraus. Erkennen und redigieren Sie außerdem personenbezogene Daten (PII) als weitere Kontrolle zur Eingabevalidierung in Ihrer Datenerfassungspipeline. Amazon Comprehend kann dabei helfen, PII Daten in Benutzer-Uploads in Wissensdatenbanken zu erkennen und zu redigieren. Weitere Informationen finden Sie unter Erkennen von PII Entitäten in der Amazon Comprehend Comprehend-Dokumentation.
Wir empfehlen Ihnen außerdem, Amazon Macie zu verwenden, um potenzielle vertrauliche Daten in den Datenquellen der Wissensdatenbank zu erkennen und Warnmeldungen zu generieren, um die allgemeine Sicherheit und Compliance zu verbessern. Implementieren Sie Guardrails für Amazon Bedrock, um Inhaltsrichtlinien durchzusetzen, unsichere Ein-/Ausgaben zu blockieren und das Modellverhalten auf der Grundlage Ihrer Anforderungen zu kontrollieren.
Empfohlene Dienste AWS
Amazon OpenSearch Serverlos
Amazon OpenSearch Serverless ist eine On-Demand-Konfiguration mit auto-scaling für Amazon OpenSearch Service. Eine OpenSearch serverlose Sammlung ist ein OpenSearch Cluster, der die Rechenkapazität entsprechend den Anforderungen Ihrer Anwendung skaliert. Die Wissensdatenbanken von Amazon Bedrock verwenden Amazon OpenSearch Serverless für Einbettungen
Implementieren Sie eine starke Authentifizierung und Autorisierung für Ihren serverlosen Vektorspeicher. OpenSearch Implementieren Sie das Prinzip der geringsten Rechte, das Benutzern und Rollen nur die erforderlichen Berechtigungen gewährt.
Mit der Datenzugriffskontrolle in OpenSearch Serverless können Sie Benutzern den Zugriff auf Sammlungen und Indizes ermöglichen, unabhängig von ihren Zugriffsmechanismen oder Netzwerkquellen. Sie verwalten Zugriffsberechtigungen mithilfe von Datenzugriffsrichtlinien, die für Sammlungen und Indexressourcen gelten. Wenn Sie dieses Muster verwenden, stellen Sie sicher, dass die Anwendung die Identität des Benutzers an die Wissensdatenbank weitergibt und dass die Wissensdatenbank Ihre rollen- oder attributbasierten Zugriffskontrollen durchsetzt. Dies wird erreicht, indem die Knowledge Base-Dienstrolle nach dem Prinzip der geringsten Rechte konfiguriert und der Zugriff auf die Rolle streng kontrolliert wird.
OpenSearch Serverless unterstützt serverseitige Verschlüsselung, AWS KMS um Daten im Ruhezustand zu schützen. Verwenden Sie einen vom Kunden verwalteten Schlüssel, um diese Daten zu verschlüsseln. Um die Erstellung eines AWS KMS Schlüssels für die Speicherung vorübergehender Daten während der Aufnahme Ihrer Datenquelle zu ermöglichen, fügen Sie Ihren Wissensdatenbanken eine Richtlinie für die Amazon Bedrock-Servicerolle bei.
Der private Zugriff kann für einen oder beide der folgenden VPC Punkte gelten: OpenSearch Serverlos verwaltete Endgeräte und unterstützte AWS Dienste wie Amazon Bedrock. Verwenden Sie diese Option AWS PrivateLink, um eine private Verbindung zwischen Ihren und serverlosen Endpunktdiensten herzustellen. VPC OpenSearch Verwenden Sie Netzwerkrichtlinienregeln, um den Zugriff auf Amazon Bedrock zu spezifizieren.
Überwachen Sie OpenSearch Serverless mithilfe von Amazon CloudWatch, das Rohdaten sammelt und sie zu lesbaren, nahezu in Echtzeit verfügbaren Metriken verarbeitet. OpenSearch Serverless ist integriert AWS CloudTrailund erfasst API Aufrufe für OpenSearch Serverless als Ereignisse. OpenSearch Der Service ist in Amazon integriert EventBridge, um Sie über bestimmte Ereignisse zu informieren, die sich auf Ihre Domains auswirken. Externe Prüfer können die Sicherheit und Konformität von OpenSearch Serverless im Rahmen mehrerer AWS Compliance-Programme beurteilen.
Amazon S3
Speichern Sie Ihre Datenquellen für Ihre Wissensdatenbank in einem S3-Bucket. Wenn Sie Ihre Datenquellen in Amazon S3 mit einem benutzerdefinierten AWS KMS Schlüssel verschlüsselt haben (empfohlen), fügen Sie Ihrer Knowledge-Base-Servicerolle eine Richtlinie hinzu. Verwenden Sie den Malware-Schutz in Amazon S3
Amazon Comprehend
Amazon Comprehend verwendet natürliche Sprachverarbeitung (NLP), um Erkenntnisse aus dem Inhalt von Dokumenten zu gewinnen. Sie können Amazon Comprehend verwenden, um PII Entitäten in englischen oder spanischen Textdokumenten zu erkennen und zu redigieren. Integrieren Sie Amazon Comprehend in Ihre Datenerfassungspipeline
Mit Amazon S3 können Sie Ihre Eingabedokumente verschlüsseln, wenn Sie eine Textanalyse, Themenmodellierung oder einen benutzerdefinierten Amazon Comprehend Comprehend-Job erstellen. Amazon Comprehend integriert AWS KMS, um die Daten auf dem Speichervolume für Start*- und Create*-Jobs zu verschlüsseln, und verschlüsselt die Ausgabeergebnisse von Start*-Jobs mithilfe eines vom Kunden verwalteten Schlüssels. Wir empfehlen, die Kontextschlüssel aws: SourceArn und aws: SourceAccount global condition in Ressourcenrichtlinien zu verwenden, um die Berechtigungen einzuschränken, die Amazon Comprehend einem anderen Service für die Ressource gewährt. Wird verwendet AWS PrivateLink, um eine private Verbindung zwischen Ihren VPC und Amazon Comprehend Endpoint Services herzustellen. Implementieren Sie identitätsbasierte Richtlinien für Amazon Comprehend nach dem Prinzip der geringsten Rechte. Amazon Comprehend ist integriert AWS CloudTrail, wodurch API Aufrufe von Amazon Comprehend als Ereignisse erfasst werden. Externe Prüfer können die Sicherheit und Konformität von Amazon Comprehend im Rahmen mehrerer AWSCompliance-Programme beurteilen.
Amazon Macie
Macie kann Ihnen helfen, sensible Daten in Ihren Wissensdatenbanken zu identifizieren, die als Datenquellen gespeichert sind, Aufrufprotokolle zu modellieren und umgehend in S3-Buckets zu speichern. Bewährte Sicherheitsmethoden für Macie finden Sie im Abschnitt Macie weiter oben in dieser Anleitung.
AWS KMS
Verwenden Sie vom Kunden verwaltete Schlüssel, um Folgendes zu verschlüsseln: Datenaufnahmeaufträge für Ihre Wissensdatenbank, die Amazon OpenSearch Service-Vektordatenbank, Sitzungen, in denen Sie Antworten aus der Abfrage einer Wissensdatenbank generieren, Modellaufrufprotokolle in Amazon S3 und den S3-Bucket, der die Datenquellen hostet.
Verwenden Sie Amazon CloudWatch und Amazon CloudTrail wie im vorherigen Abschnitt zur Modellinferenz erklärt.
