Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Skalieren Sie die Clusterkapazität
Wenn Ihr Job zu viel Zeit in Anspruch nimmt, die Executoren jedoch ausreichend Ressourcen verbrauchen und Spark im Verhältnis zu den verfügbaren Kernen eine große Menge an Aufgaben erstellt, sollten Sie eine Skalierung der Clusterkapazität in Betracht ziehen. Verwenden Sie die folgenden Kennzahlen, um zu beurteilen, ob dies angemessen ist.
CloudWatch Metriken
-
Überprüfen Sie CPULast und Speicherauslastung, um festzustellen, ob die Executoren ausreichend Ressourcen verbrauchen.
-
Prüfen Sie, wie lange der Job ausgeführt wurde, um festzustellen, ob die Verarbeitungszeit zu lang ist, um Ihre Leistungsziele zu erreichen.
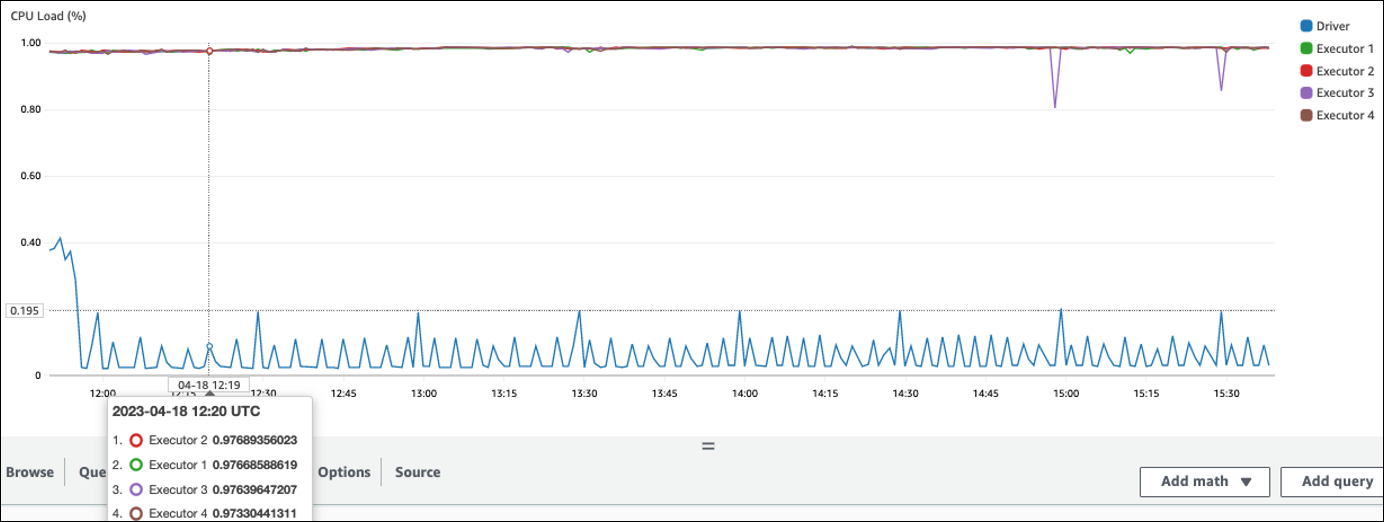
Im folgenden Beispiel werden vier Executoren mit einer CPU Auslastung von mehr als 97 Prozent ausgeführt, aber die Verarbeitung ist nach etwa drei Stunden noch nicht abgeschlossen.
Anmerkung
Wenn die CPU Auslastung gering ist, werden Sie wahrscheinlich nicht von der Skalierung der Clusterkapazität profitieren.
Spark-Benutzeroberfläche
Auf der Registerkarte Job oder der Registerkarte Phase können Sie die Anzahl der Aufgaben für jeden Job oder jede Phase sehen. Im folgenden Beispiel hat Spark 58100 Aufgaben erstellt.

Auf der Registerkarte Executor können Sie die Gesamtzahl der Executoren und Aufgaben sehen. Im folgenden Screenshot hat jeder Spark-Executor vier Kerne und kann vier Aufgaben gleichzeitig ausführen.
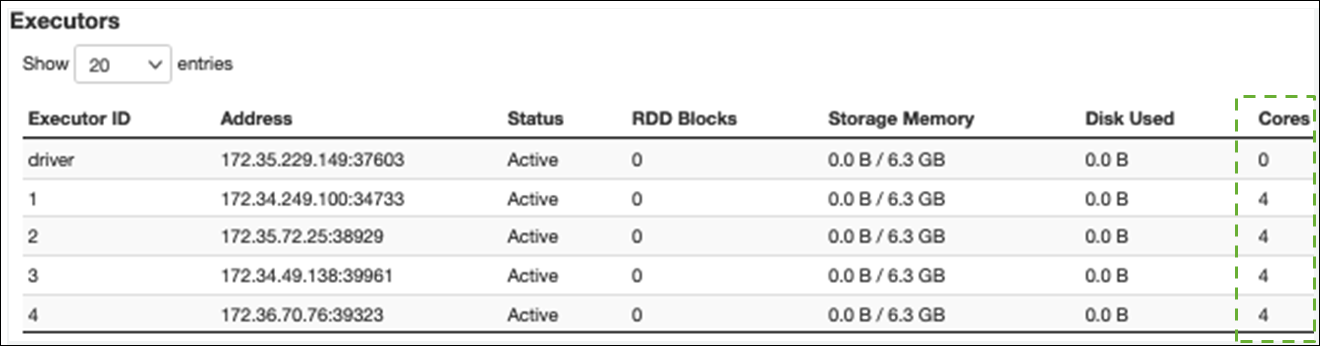
In diesem Beispiel 58100) ist die Anzahl der Spark-Aufgaben () viel größer als die 16 Aufgaben, die die Executoren gleichzeitig verarbeiten können (4 Executors × 4 Cores).
Wenn Sie diese Symptome beobachten, sollten Sie eine Skalierung des Clusters in Betracht ziehen. Sie können die Clusterkapazität mithilfe der folgenden Optionen skalieren:
-
AWS Glue Auto Scaling aktivieren — Auto Scaling ist für Ihre AWS Glue Extraktions-, Transformations- und Load (ETL) - und Streaming-Jobs in AWS Glue Version 3.0 oder höher verfügbar. AWS Glue fügt dem Cluster automatisch Worker hinzu oder entfernt sie aus dem Cluster, abhängig von der Anzahl der Partitionen in jeder Phase oder der Geschwindigkeit, mit der Mikrobatches bei der Jobausführung generiert werden.
Wenn Sie eine Situation beobachten, in der die Anzahl der Mitarbeiter nicht zunimmt, obwohl Auto Scaling aktiviert ist, sollten Sie erwägen, Mitarbeiter manuell hinzuzufügen. Beachten Sie jedoch, dass die manuelle Skalierung für eine Phase dazu führen kann, dass viele Mitarbeiter in späteren Phasen untätig sind, was mehr kostet, ohne dass die Leistung gesteigert wird.
Nachdem Sie Auto Scaling aktiviert haben, können Sie die Anzahl der Executors in den Executor-Metriken CloudWatch sehen. Verwenden Sie die folgenden Metriken, um die Nachfrage nach Executoren in Spark-Anwendungen zu überwachen:
-
glue.driver.ExecutorAllocationManager.executors.numberAllExecutors -
glue.driver.ExecutorAllocationManager.executors.numberMaxNeededExecutors
Weitere Informationen zu Metriken finden Sie unter Überwachung AWS Glue mithilfe von CloudWatch Amazon-Metriken.
-
-
Skalieren: Erhöhen Sie die Anzahl der AWS Glue Mitarbeiter — Sie können die Anzahl der AWS Glue Mitarbeiter manuell erhöhen. Fügen Sie nur so lange Arbeitskräfte hinzu, bis Sie untätige Mitarbeiter beobachten. Zu diesem Zeitpunkt erhöht das Hinzufügen weiterer Mitarbeiter die Kosten, ohne dass sich die Ergebnisse verbessern. Weitere Informationen finden Sie unter Aufgaben parallelisieren.
-
Skalieren: Verwenden Sie einen größeren Worker-Typ — Sie können den Instance-Typ Ihrer Worker manuell ändern, um AWS Glue Worker mit mehr Kernen, Arbeitsspeicher und Speicher zu verwenden. Größere Workertypen ermöglichen Ihnen die vertikale Skalierung und Ausführung intensiver Datenintegrationsaufgaben, wie z. B. speicherintensive Datentransformationen, schiefe Aggregationen und Entitätserkennungsprüfungen mit Petabytes an Daten.
Die Skalierung hilft auch in Fällen, in denen der Spark-Treiber mehr Kapazität benötigt, z. B. weil der Job-Abfrageplan recht umfangreich ist. Weitere Informationen zu Arbeitstypen und Leistung finden Sie im AWS Big-Data-Blogbeitrag Scale Your AWS Glue für Apache Spark-Jobs mit den neuen größeren Workertypen G.4X und G.8X
. Durch den Einsatz größerer Arbeitskräfte kann auch die Gesamtzahl der benötigten Arbeitskräfte reduziert werden, wodurch die Leistung gesteigert wird, da bei intensiven Vorgängen wie dem Zusammenführen weniger häufig gemischt wird.
