Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Aufgaben parallelisieren
Um die Leistung zu optimieren, ist es wichtig, Aufgaben für das Laden und Transformieren von Daten zu parallelisieren. Wie wir unter Wichtige Themen in Apache Spark besprochen haben, ist die Anzahl der belastbaren Partitionen mit verteilten Datensätzen (RDD) wichtig, da sie den Grad der Parallelität bestimmt. Jede Aufgabe, die Spark erstellt, entspricht einer RDD Partition im Verhältnis 1:1. Um die beste Leistung zu erzielen, müssen Sie verstehen, wie die Anzahl der RDD Partitionen bestimmt und wie diese Anzahl optimiert wird.
Wenn Sie nicht genug Parallelität haben, werden die folgenden Symptome in CloudWatchMetriken und der Spark-Benutzeroberfläche aufgezeichnet.
CloudWatch Metriken
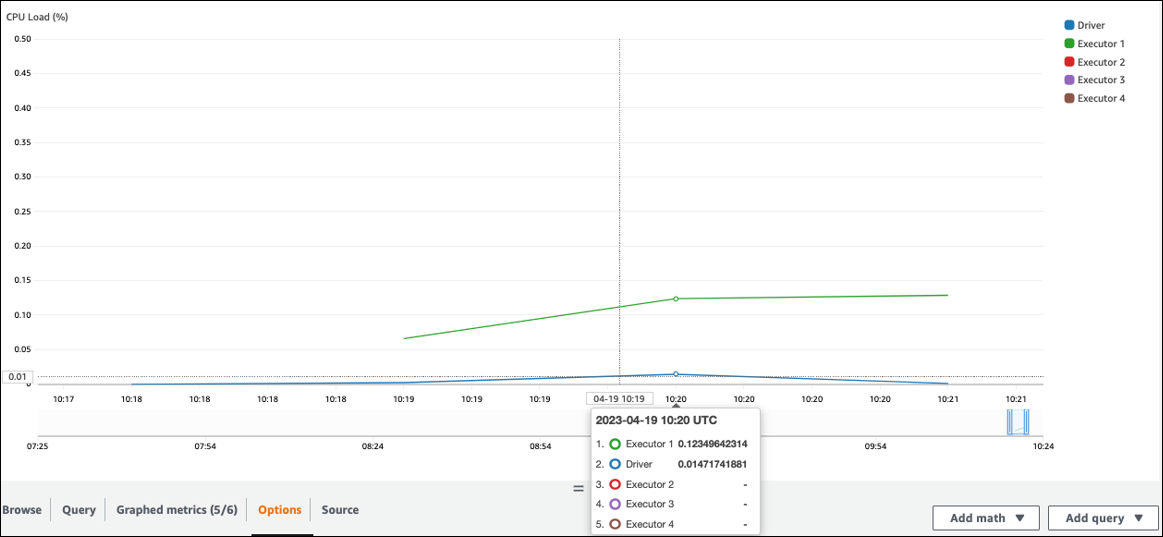
Überprüfen Sie die CPUAuslastung und die Speicherauslastung. Wenn einige Executoren während einer Phase Ihres Jobs keine Verarbeitung durchführen, ist es angebracht, die Parallelität zu verbessern. In diesem Fall führte Executor 1 während des visualisierten Zeitrahmens eine Aufgabe aus, die übrigen Executoren (2, 3 und 4) jedoch nicht. Sie können daraus schließen, dass diesen Executoren vom Spark-Treiber keine Aufgaben zugewiesen wurden.
Spark-Benutzeroberfläche
Auf der Registerkarte Phase in der Spark-Benutzeroberfläche können Sie die Anzahl der Aufgaben in einer Phase sehen. In diesem Fall hat Spark nur eine Aufgabe ausgeführt.

Darüber hinaus zeigt die Event-Timeline, dass Executor 1 eine Aufgabe bearbeitet. Das bedeutet, dass die Arbeit in dieser Phase ausschließlich auf einem Testamentsvollstrecker ausgeführt wurde, während die anderen inaktiv waren.

Wenn Sie diese Symptome beobachten, versuchen Sie es mit den folgenden Lösungen für jede Datenquelle.
Parallelisieren Sie das Laden von Daten aus Amazon S3
Um Datenladungen aus Amazon S3 zu parallelisieren, überprüfen Sie zunächst die Standardanzahl von Partitionen. Sie können dann manuell eine Zielanzahl von Partitionen bestimmen, achten Sie jedoch darauf, zu viele Partitionen zu vermeiden.
Ermitteln Sie die Standardanzahl von Partitionen
Für Amazon S3 wird die anfängliche Anzahl von RDD Spark-Partitionen (von denen jede einer Spark-Aufgabe entspricht) durch die Funktionen Ihres Amazon S3 S3-Datensatzes (z. B. Format, Komprimierung und Größe) bestimmt. Wenn Sie einen AWS Glue DynamicFrame oder einen Spark DataFrame aus in Amazon S3 gespeicherten CSV Objekten erstellen, kann die anfängliche Anzahl von RDD Partitionen (NumPartitions) ungefähr wie folgt berechnet werden:
-
Objektgröße <= 64 MB:
NumPartitions = Number of Objects -
Objektgröße > 64 MB:
NumPartitions = Total Object Size / 64 MB -
Nicht teilbar (gzip):
NumPartitions = Number of Objects
Wie im Abschnitt Reduzieren Sie die Menge der gescannten Daten beschrieben, unterteilt Spark große S3-Objekte in Splits, die parallel verarbeitet werden können. Wenn das Objekt größer als die geteilte Größe ist, teilt Spark das Objekt auf und erstellt für jede RDD Teilung eine Partition (und Aufgabe). Die Split-Größe von Spark basiert auf Ihrem Datenformat und Ihrer Laufzeitumgebung, aber das ist eine vernünftige erste Näherung. Einige Objekte werden mit nicht teilbaren Komprimierungsformaten wie Gzip komprimiert, sodass Spark sie nicht aufteilen kann.
Der NumPartitions Wert kann je nach Datenformat, Komprimierung, AWS Glue Version, Anzahl der AWS Glue Worker und Spark-Konfiguration variieren.
Wenn Sie beispielsweise ein einzelnes csv.gz 10-GB-Objekt mit einem Spark laden DataFrame, erstellt der Spark-Treiber nur eine RDD Partition (NumPartitions=1), da Gzip nicht teilbar ist. Dies führt zu einer starken Belastung eines bestimmten Spark-Executors und den verbleibenden Executoren werden keine Aufgaben zugewiesen, wie in der folgenden Abbildung beschrieben.
Überprüfen Sie die tatsächliche Anzahl der Aufgaben (NumPartitions) für die Phase auf der Registerkarte Stage der Spark Web UI, oder führen Sie die Ausführung df.rdd.getNumPartitions() in Ihrem Code aus, um die Parallelität zu überprüfen.
Wenn Sie auf eine 10-GB-GZIP-Datei stoßen, prüfen Sie, ob das System, das diese Datei generiert, sie in einem aufteilbaren Format generieren kann. Wenn dies keine Option ist, müssen Sie möglicherweise die Clusterkapazität skalieren, um die Datei verarbeiten zu können. Um Transformationen auf effiziente Weise auf den von Ihnen geladenen Daten auszuführen, müssen Sie mithilfe der Repartitionierung eine RDD Neuverteilung zwischen den Workern in Ihrem Cluster vornehmen.
Ermitteln Sie manuell eine Zielanzahl von Partitionen
Abhängig von den Eigenschaften Ihrer Daten und der Implementierung bestimmter Funktionen durch Spark kann es sein, dass Sie am Ende einen niedrigen NumPartitions Wert erhalten, obwohl die zugrunde liegende Arbeit immer noch parallelisiert werden kann. Wenn der NumPartitions Wert zu klein ist, führen Sie den Befehl aus, df.repartition(N) um die Anzahl der Partitionen zu erhöhen, sodass die Verarbeitung auf mehrere Spark-Executoren verteilt werden kann.
In diesem Fall df.repartition(100) wird die Anzahl der ausgeführten Partitionen NumPartitions von 1 auf 100 erhöht, sodass 100 Partitionen Ihrer Daten erstellt werden, von denen jede eine Aufgabe hat, die den anderen Executoren zugewiesen werden kann.
Bei diesem Vorgang werden die repartition(N) gesamten Daten gleichmäßig aufgeteilt (10 GB/100 Partitionen = 100 MB/Partition), wodurch Datenverzerrungen zu bestimmten Partitionen vermieden werden.
Anmerkung
Wenn ein Shuffle-Vorgang wie z. B. ausgeführt join wird, wird die Anzahl der Partitionen je nach dem Wert von oder dynamisch erhöht oder verringert. spark.sql.shuffle.partitions spark.default.parallelism Dies ermöglicht einen effizienteren Datenaustausch zwischen Spark-Executoren. Weitere Informationen finden Sie in der Spark-Dokumentation
Ihr Ziel bei der Festlegung der Zielanzahl von Partitionen besteht darin, die Nutzung der bereitgestellten AWS Glue Worker zu maximieren. Die Anzahl der AWS Glue Worker und die Anzahl der Spark-Aufgaben hängen von der Anzahl der vCPUs ab. Spark unterstützt eine Aufgabe für jeden CPU v-Core. In AWS Glue Version 3.0 oder höher können Sie mithilfe der folgenden Formel eine Zielanzahl von Partitionen berechnen.
# Calculate NumPartitions by WorkerType numExecutors = (NumberOfWorkers - 1) numSlotsPerExecutor = 4 if WorkerType is G.1X 8 if WorkerType is G.2X 16 if WorkerType is G.4X 32 if WorkerType is G.8X NumPartitions = numSlotsPerExecutor * numExecutors # Example: Glue 4.0 / G.1X / 10 Workers numExecutors = ( 10 - 1 ) = 9 # 1 Worker reserved on Spark Driver numSlotsPerExecutor = 4 # G.1X has 4 vCpu core ( Glue 3.0 or later ) NumPartitions = 9 * 4 = 36
In diesem Beispiel stellt jeder G.1X-Worker einem Spark-Executor () vier CPU V-Kerne zur Verfügung. spark.executor.cores = 4 Spark unterstützt eine Aufgabe für jeden CPU v-Core, sodass G.1X-Spark-Executoren vier Aufgaben gleichzeitig ausführen können (). numSlotPerExecutor Diese Anzahl von Partitionen nutzt den Cluster voll aus, wenn Aufgaben die gleiche Zeit in Anspruch nehmen. Einige Aufgaben dauern jedoch länger als andere, wodurch Kerne im Leerlauf entstehen. In diesem Fall sollten Sie eine Multiplikation mit numPartitions 2 oder 3 in Betracht ziehen, um Engpassaufgaben aufzuschlüsseln und effizient zu planen.
Zu viele Partitionen
Eine übermäßige Anzahl von Partitionen führt zu einer übermäßigen Anzahl von Aufgaben. Dies führt zu einer starken Belastung des Spark-Treibers aufgrund des Mehraufwands im Zusammenhang mit der verteilten Verarbeitung, wie z. B. Verwaltungsaufgaben und dem Datenaustausch zwischen Spark-Executoren.
Wenn die Anzahl der Partitionen in Ihrem Job wesentlich größer ist als Ihre Zielanzahl von Partitionen, sollten Sie erwägen, die Anzahl der Partitionen zu reduzieren. Sie können Partitionen mithilfe der folgenden Optionen reduzieren:
-
Wenn Ihre Dateien sehr klein sind, verwenden Sie AWS Glue groupFiles. Sie können die übermäßige Parallelität reduzieren, die sich aus dem Start einer Apache Spark-Aufgabe zur Verarbeitung jeder Datei ergibt.
-
Wird verwendet
coalesce(N), um Partitionen zusammenzuführen. Dies ist ein kostengünstiger Prozess. Beim Reduzieren der Anzahl der Partitionencoalesce(N)wird der Vorzugrepartition(N)gegeben,repartition(N)da durch Mischen die Anzahl der Datensätze in jeder Partition gleichmäßig verteilt wird. Das erhöht die Kosten und den Verwaltungsaufwand. -
Verwenden Sie Spark 3.x Adaptive Query Execution. Wie im Abschnitt Die wichtigsten Themen in Apache Spark beschrieben, bietet Adaptive Query Execution eine Funktion zum automatischen Zusammenführen der Anzahl von Partitionen. Sie können diesen Ansatz verwenden, wenn Sie die Anzahl der Partitionen erst kennen, wenn Sie die Ausführung durchgeführt haben.
Parallelisieren Sie das Laden von Daten JDBC
Die Anzahl der RDD Spark-Partitionen wird durch die Konfiguration bestimmt. Beachten Sie, dass standardmäßig nur eine einzige Aufgabe ausgeführt wird, um einen gesamten Quelldatensatz mithilfe einer SELECT Abfrage zu scannen.
AWS Glue DynamicFrames Sowohl Spark als auch Spark DataFrames unterstützen das parallelisierte Laden JDBC von Daten über mehrere Aufgaben hinweg. Dies wird erreicht, indem where Prädikate verwendet werden, um eine SELECT Abfrage in mehrere Abfragen aufzuteilen. Um Lesevorgänge von zu parallelisierenJDBC, konfigurieren Sie die folgenden Optionen:
-
Für AWS Glue DynamicFrame, setze
hashfield(oderhashexpression)) und.hashpartitionWeitere Informationen finden Sie unter Paralleles Lesen aus JDBC Tabellen.connection_mysql8_options = { "url": "jdbc:mysql://XXXXXXXXXX.XXXXXXX.us-east-1.rds.amazonaws.com:3306/test", "dbtable": "medicare_tb", "user": "test", "password": "XXXXXXXXX", "hashexpression":"id", "hashpartitions":"10" } datasource0 = glueContext.create_dynamic_frame.from_options( 'mysql', connection_options=connection_mysql8_options, transformation_ctx= "datasource0" ) -
Für Spark legen Sie DataFrame
numPartitions,partitionColumnlowerBound, und festupperBound. Weitere Informationen finden Sie unter JDBCZu anderen Datenbanken. df = spark.read \ .format("jdbc") \ .option("url", "jdbc:mysql://XXXXXXXXXX.XXXXXXX.us-east-1.rds.amazonaws.com:3306/test") \ .option("dbtable", "medicare_tb") \ .option("user", "test") \ .option("password", "XXXXXXXXXX") \ .option("partitionColumn", "id") \ .option("numPartitions", "10") \ .option("lowerBound", "0") \ .option("upperBound", "1141455") \ .load() df.write.format("json").save("s3://bucket_name/Tests/sparkjdbc/with_parallel/")
Parallelisieren Sie das Laden von Daten aus DynamoDB, wenn Sie den Connector verwenden ETL
Die Anzahl der RDD Spark-Partitionen wird durch den Parameter bestimmt. dynamodb.splits Um Lesevorgänge aus Amazon DynamoDB zu parallelisieren, konfigurieren Sie die folgenden Optionen:
-
Erhöhen Sie den Wert von.
dynamodb.splits -
Optimieren Sie den Parameter, indem Sie der Formel folgen, die unter Verbindungstypen und Optionen für ETL in AWS Glue for Spark erklärt wird.
Parallelisieren Sie das Laden von Daten aus Kinesis Data Streams
Die Anzahl der RDD Spark-Partitionen wird durch die Anzahl der Shards im Amazon Kinesis Data Streams Streams-Quelldatenstream bestimmt. Wenn Sie nur wenige Shards in Ihrem Datenstream haben, wird es nur wenige Spark-Aufgaben geben. Dies kann zu einer geringen Parallelität bei nachgelagerten Prozessen führen. Um Lesevorgänge aus Kinesis Data Streams zu parallelisieren, konfigurieren Sie die folgenden Optionen:
-
Erhöhen Sie die Anzahl der Shards, um mehr Parallelität beim Laden von Daten aus Kinesis Data Streams zu erreichen.
-
Wenn Ihre Logik im Mikro-Batch komplex genug ist, sollten Sie erwägen, die Daten zu Beginn des Batches neu zu partitionieren, nachdem Sie nicht benötigte Spalten gelöscht haben.
Weitere Informationen finden Sie unter Bewährte Methoden zur Kosten- und Leistungsoptimierung für Streaming-Jobs
Parallelisieren Sie Aufgaben nach dem Laden der Daten
Um Aufgaben nach dem Laden von Daten zu parallelisieren, erhöhen Sie die Anzahl der RDD Partitionen, indem Sie die folgenden Optionen verwenden:
-
Partitionieren Sie Daten neu, um eine größere Anzahl von Partitionen zu generieren, insbesondere direkt nach dem ersten Laden, wenn der Ladevorgang selbst nicht parallelisiert werden konnte.
Rufen Sie
repartition()entweder auf DynamicFrame oder DataFrame auf und geben Sie dabei die Anzahl der Partitionen an. Eine gute Faustregel lautet, dass die Anzahl der verfügbaren Kerne zwei- oder dreimal so hoch ist.Beim Schreiben einer partitionierten Tabelle kann dies jedoch zu einer Explosion von Dateien führen (jede Partition kann potenziell eine Datei in jeder Tabellenpartition generieren). Um dies zu vermeiden, können Sie Ihre Datei DataFrame nach Spalten neu partitionieren. Dabei werden die Spalten der Tabellenpartition verwendet, sodass die Daten vor dem Schreiben organisiert werden. Sie können eine höhere Anzahl von Partitionen angeben, ohne dass kleine Dateien auf den Tabellenpartitionen gespeichert werden. Achten Sie jedoch darauf, Datenverzerrungen zu vermeiden, bei denen einige Partitionswerte die meisten Daten enthalten und die Ausführung der Aufgabe verzögern.
-
Wenn es zu Shuffles kommt, erhöhen Sie den Wert.
spark.sql.shuffle.partitionsDies kann auch bei Speicherproblemen beim Mischen helfen.Wenn Sie mehr als 2.001 Shuffle-Partitionen haben, verwendet Spark ein komprimiertes Speicherformat. Wenn Sie eine Zahl haben, die dieser Zahl nahe kommt, möchten Sie vielleicht den
spark.sql.shuffle.paritionsWert über dieser Grenze setzen, um eine effizientere Darstellung zu erhalten.
