Amazon Redshift unterstützt die Verwendung von Python-UDFs nach dem 30. Juni 2026 nicht mehr. Wir werden damit beginnen, es schrittweise durchzusetzen. Weitere Informationen zu den Einzelheiten zum Ende der Lebensdauer und zu den Migrationsoptionen von Python finden Sie in dem Blogbeitrag
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Workflow der Abfrageplanung und -ausführung
Die folgende Abbildung gibt eine allgemeine Übersicht über den Workflow der Abfrageplanung und -ausführung.
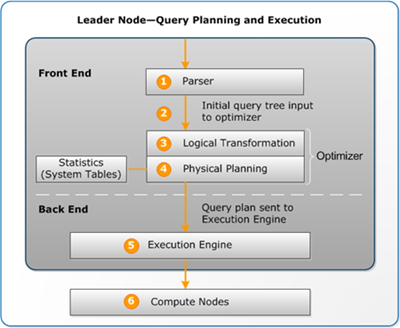
Der Workflow der Abfrageplanung und -ausführung folgt diesen Schritten:
-
Die Abfrage wird an den Führungsknoten übermittelt und dort geparst.
-
Der Parser erzeugt eine erste Version einer Abfragestruktur, die eine logische Repräsentation der ursprünglichen Abfrage ist. Amazon Redshift gibt dann diese Abfragestruktur in den Abfrageoptimierer ein.
-
Der Optimierer bewertet die Abfragestruktur und transformiert sie ggf., um sie maximal effizient zu machen. Eine solche Transformation zur Optimierung der Effizienz kann beispielsweise so aussehen, dass anstelle einer Abfrage mehrere zusammengehörige Abfragen ausgeführt werden.
-
Der Optimierer erzeugt für diese transformierten Abfragestrukturen einen Abfrageplan, in dem der Ausführungsablauf mit der besten Ausführungsperformance. In dem Abfrageplan sind bestimmte Ausführungsoptionen angegeben, über die beispielsweise Art und Reihenfolge von Join-Operationen, Aggregierungsoptionen und Anforderungen an die Datenverteilung gesteuert werden.
Sie können den Befehl EXPLAIN verwenden, um den Abfrageplan anzuzeigen. Der Abfrageplan ist ein grundlegendes Werkzeug für die Analyse und Optimierung komplexer Abfragen. Weitere Informationen finden Sie unter Erstellen und Interpretieren eines Abfrageplans.
-
Die Ausführungs-Engine übersetzt den Abfrageplan in Schritte, Segmente und Streams:
- Schritt
-
Ein Schritt ist eine Einzeloperation, die zur Ausführung der Abfrage durchgeführt werden muss. Schritte können zusammengefasst werden und ermöglichen so den Verarbeitungsknoten, Abfragen, Join- und andere Datenbankoperationen auszuführen.
- Segment
-
Eine Kombination von Schritten, der von einem einzelnen Prozess verarbeitet werden kann; Ein Segment ist auch die kleinste Kompilierungseinheit, die von einem Verarbeitungsknoten in einer Slice verarbeitet werden kann. Ein Slice ist die Parallelverarbeitungseinheit in Amazon Redshift. Die Segmente in einem Stream werden parallel ausgeführt.
- Stream
-
Eine Sammlung von Segmenten, die an die verfügbaren Slices in Verarbeitungsknoten übermittelt werden.
Die Ausführungs-Engine erzeugt anhand der Schritte, Segmente und Streams kompilierten Code. Kompilierter Code wird schneller ausgeführt als interpretierter Code und verbraucht auch weniger Rechenkapazität. Anschließend wird dieser kompilierte Code an alle Verarbeitungsknoten gesendet.
Anmerkung
Wenn Sie die Abfragen anhand verschiedener Benchmark-Metriken testen, sollten Sie jeweils die zweite Ausführung der Abfrage messen, da bei der ersten Ausführung der Verwaltungsaufwand zum Kompilieren des Codes mitgezählt wird. Weitere Informationen finden Sie unter Für die Abfrageleistung relevante Faktoren.
-
Die Abfragesegmente werden in den Slices der Verarbeitungsknoten parallel ausgeführt. Bei diesem Vorgang nutzt Amazon Redshift eine optimierte Netzwerkkommunikation und optimiertes Speicher- und Datenträgermanagement, um Zwischenergebnisse von einem Schritt des Abfrageplans in den nächsten zu übernehmen. Dadurch lässt sich auch die Abfrageausführung beschleunigen.
Die Schritte 5 und 6 erfolgen für jeden Stream getrennt. Die Engine erstellt die ausführbaren Segmente für einen Stream sendet sie an die Verarbeitungsknoten. Wenn die Segmente eines Streams vollständig erzeugt sind, generiert die Engine die Segmente für den nächsten Stream. Dies ermöglicht der Engine eine Analyse des jeweiligen vorangehenden Streams, beispielsweise, ob die Operationen datenträgerbasiert waren, und eine Optimierung der Generierung der Segmente für den nächsten Stream.
Wenn die Verarbeitungsknoten die Berechnungen abgeschlossen haben, senden Sie die Abfrageergebnisse zur Weiterverarbeitung an den Führungsknoten zurück. Der Führungsknoten fügt die Daten zu einem Ergebnissatz zusammen und sortiert und gruppiert das Gesamtergebnis. Dann sendet der Führungsknoten das Ergebnis an den Client zurück.
Anmerkung
Die Verarbeitungsknoten können während der Ausführung der Abfrage bei Bedarf bestimmte Daten an den Führungsknoten zurücksenden. Wenn beispielsweise in einer Unterabfrage eine LIMIT-Klausel vorkommt, wird der Grenzwert auf dem Führungsknoten angewendet, bevor die Daten zur Weiterverarbeitung an den Cluster verteilt werden.
