Amazon Redshift unterstützt die Verwendung von Python-UDFs nach dem 30. Juni 2026 nicht mehr. Wir werden damit beginnen, es schrittweise durchzusetzen. Weitere Informationen zu den Einzelheiten zum Ende der Lebensdauer und zu den Migrationsoptionen von Python finden Sie in dem Blogbeitrag
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwenden der Ansicht SVL_QUERY_REPORT
Gehen Sie wie folgt vor, um mit SVL_QUERY_REPORT eine Abfragezusammenfassung nach Slices zu analysieren:
-
Führen Sie die folgende Abfrage aus, um die Abfrage-ID anzuzeigen:
select query, elapsed, substring from svl_qlog order by query desc limit 5;Untersuchen Sie den Abfrageausschnitt im Feld
substring, um herauszufinden, welcherquery-Wert Ihrer Abfrage entspricht. Wenn Sie die Abfrage mehrmals ausgeführt haben, verwenden Sie denquery-Wert aus der Zeile mit dem niedrigerenelapsed-Wert. Dies ist die Zeile für die kompilierte Version. Wenn Sie viele Abfragen ausgeführt haben, können Sie den in der LIMIT-Klausel verwendeten Wert heraufsetzen, um sicherzustellen, dass die Abfrage berücksichtigt wird. -
Wählen Sie Zeilen aus SVL_QUERY_REPORT für Ihre Abfrage aus. Ordnen Sie die Ergebnisse nach Segment, Schritt, verbrauchter Zeit und Zeilen an:
select * from svl_query_report where query = MyQueryID order by segment, step, elapsed_time, rows; -
Überprüfen Sie, ob auch alle Slices etwa dieselbe Anzahl an Zeilen verarbeiten:
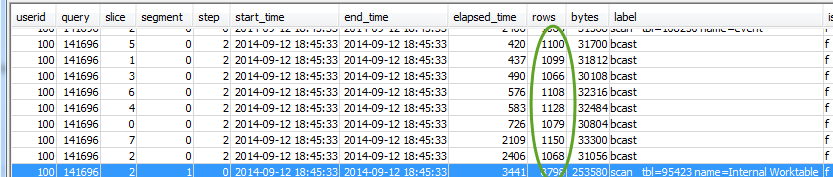
Überprüfen Sie auch, ob auch alle Slices etwa dieselbe Verarbeitungsdauer haben:
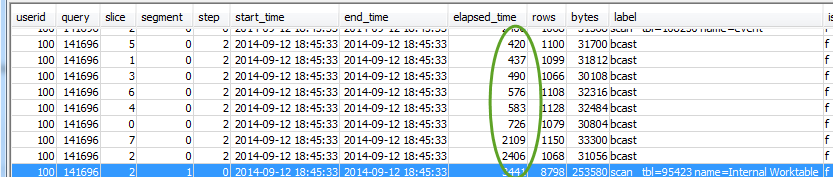
Große Unterschiede zwischen diesen Werten können auf eine verzerrte Datenverteilung hinweisen, weil für diese Abfrage nicht der beste Verteilungsstil verwendet wird. Empfohlene Lösungen finden Sie unter Suboptimale Datenverteilung.
