Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Minimierung der Vakuumzeiten
Amazon Redshift sortiert Daten automatisch und läuft VACUUM DELETE im Hintergrund. Dadurch muss der Befehl nicht mehr ausgeführt werden. VACUUM Das Staubsaugen ist möglicherweise ein zeitaufwändiger Vorgang. Je nach Art Ihrer Daten empfehlen wir die folgenden Methoden, um die Vakuumzeiten zu minimieren.
Themen
Entscheiden Sie, ob Sie erneut indizieren möchten
Häufig können Sie die Abfrageleistung deutlich verbessern, indem Sie einen überlappenden Sortierstil verwenden. Mit der Zeit verschlechtert sich die Leistung jedoch möglicherweise, wenn die Verteilung der Werte in den Sortierschlüsselspalten geändert wird.
Wenn Sie zum ersten Mal eine leere verschachtelte Tabelle mit COPY oder CREATE TABLE AS laden, erstellt Amazon Redshift automatisch den verschachtelten Index. Wenn Sie zunächst eine Interleaved-Tabelle mit laden, müssen Sie den Interleaved-Index anschließend ausführenINSERT, um den Interleaved-Index zu initialisieren VACUUMREINDEX.
Während Sie Zeilen mit neuen Sortierschlüsselwerten hinzufügen, kann sich die Leistung verschlechtern, wenn die Verteilung der Werte in den Sortierschlüsselspalten geändert wird. Wenn Ihre neuen Zeilen primär innerhalb des Bereichs der vorhandenen Sortierschlüsselwerte liegen, müssen Sie keine Neuindizierung ausführen. Führen Sie VACUUM SORT ONLY oder aus, um die VACUUM FULL Sortierreihenfolge wiederherzustellen.
Das Abfragemodul kann die Sortierreihenfolge verwenden, um effizient festzulegen, welche Datenblöcke gescannt werden müssen, um eine Abfrage zu verarbeiten. Im Fall einer überlappenden Sortierung analysiert Amazon Redshift die Sortierschlüsselspaltenwerte, um die optimale Sortierreihenfolge zu ermitteln. Wenn aufgrund hinzugefügter Zeilen die Verteilung der Schlüsselwerte geändert oder verschoben wird, ist die Sortierstrategie nicht mehr optimal und der Vorteil, den die Sortierung für die Leistung hat, nimmt ab. Um die Sortierschlüsselverteilung erneut zu analysieren, können Sie eine VACUUM REINDEX ausführen. Die Neuindizierungsoperation ist zeitaufwändig. Um festzustellen, ob eine Tabelle von einer Neuindizierung profitiert, führen Sie eine Abfrage für die Ansicht SVV_INTERLEAVED_COLUMNS aus.
Beispielsweise zeigt die folgende Abfrage Details für Tabellen an, die überlappende Sortierschlüssel verwenden.
select tbl as tbl_id, stv_tbl_perm.name as table_name, col, interleaved_skew, last_reindex from svv_interleaved_columns, stv_tbl_perm where svv_interleaved_columns.tbl = stv_tbl_perm.id and interleaved_skew is not null;tbl_id | table_name | col | interleaved_skew | last_reindex --------+------------+-----+------------------+-------------------- 100048 | customer | 0 | 3.65 | 2015-04-22 22:05:45 100068 | lineorder | 1 | 2.65 | 2015-04-22 22:05:45 100072 | part | 0 | 1.65 | 2015-04-22 22:05:45 100077 | supplier | 1 | 1.00 | 2015-04-22 22:05:45 (4 rows)
Der Wert für interleaved_skew ist ein Verhältnis, das die Menge der Verschiebung angibt. Ein Wert von 1 bedeutet, dass es keine Verschiebung gegeben hat. Wenn die Schräglage größer als 1,4 ist, verbessert a in der Regel VACUUM REINDEX die Leistung, es sei denn, die Schräglage ist dem zugrunde liegenden Satz inhärent.
Sie können den Datumswert in last_reindex verwenden, um festzustellen, wie viel Zeit seit der letzten Neuindizierung verstrichen ist.
Verkleinern Sie den unsortierten Bereich
Die nicht sortierte Region nimmt an Größe zu, wenn Sie große Mengen neuer Daten in Tabellen laden, die bereits Daten enthalten, oder wenn Sie Tabellen nicht als Teil der routinemäßigen Wartungsoperationen bereinigen. Um lange Ausführungszeiten von Bereinigungsoperationen zu vermeiden, verwenden Sie die folgenden Verfahren:
-
Führen Sie Bereinigungsoperationen regelmäßig aus.
Wenn Sie Ihre Tabellen in kleinen Schritten laden (z. B. tägliche Aktualisierungen, die einen kleinen Prozentsatz der Gesamtzahl der Zeilen in der Tabelle ausmachen), können Sie durch VACUUM regelmäßiges Ausführen sicherstellen, dass einzelne Vakuumvorgänge schnell ausgeführt werden.
-
Führen Sie den größten Ladevorgang zuerst aus.
Wenn Sie eine neue Tabelle mit mehreren COPY Operationen laden müssen, führen Sie zuerst den größten Ladevorgang aus. Wenn Sie einen Ladevorgang zum ersten Mal in eine neue oder verkürzte Tabelle ausführen, werden alle Daten direkt in die sortierte Region geladen, sodass keine Bereinigung erforderlich ist.
-
Verkürzen Sie eine Tabelle, statt alle Zeilen zu löschen.
Durch das Löschen von Zeilen aus einer Tabelle wird der Platz nicht zurückgewonnen, den die Zeilen vor der Ausführung der Bereinigungsoperation belegt haben. Durch das Verkürzen einer Tabelle werden jedoch die Tabelle geleert und der Festplattenplatz zurückgewonnen; daher ist keine Bereinigung erforderlich. Alternativ können Sie die Tabelle entfernen und neu erstellen.
-
Verkürzen oder entfernen Sie Testtabellen.
Wenn Sie zu Testzwecken eine kleine Zahl von Zeilen in eine Tabelle laden, sollten Sie die Zeilen nach Abschluss des Vorgangs nicht löschen. Verkürzen Sie stattdessen die Tabelle und laden Sie diese Zeilen als Teil der anschließenden Produktionsladeoperation neu.
-
Führen Sie eine Deep Copy-Operation aus.
Wenn eine Tabelle mit einer zusammengesetzten Sortierschlüsseltabelle einen großen, nicht sortierten Bereich besitzt, ist eine Deep Copy-Operation sehr viel schneller als eine Bereinigung. Eine Deep-Kopie erstellt eine Tabelle neu und füllt diese, indem sie einen Bulk-Insert verwendet, der die Tabelle automatisch neu sortiert. Wenn eine Tabelle einen großen, nicht sortierten Bereich besitzt, ist eine Deep Copy-Operation sehr viel schneller als eine Bereinigung. Der Kompromiss besteht darin, dass Sie während einer Deep Copy-Operation anders als bei einer Bereinigung nicht gleichzeitig Aktualisierungen ausführen können. Weitere Informationen finden Sie unter Bewährte Methoden für die Gestaltung von Abfragen mit Amazon Redshift.
Reduzieren Sie das Volumen der zusammengeführten Zeilen
Wenn eine Bereinigungsoperation neue Zeilen mit der sortierten Region einer Tabelle zusammenführen muss, nimmt der für die Bereinigung benötigte Zeitraum zu, wenn die Tabelle größer wird. Sie können die Leistung der Bereinigung verbessern, indem Sie die Zahl der Zeilen reduzieren, die zusammengeführt werden müssen.
Vor einer Bereinigung besteht eine Tabelle aus einer sortierten Region zu Beginn der Tabelle, gefolgt von einer nicht sortierten Region, deren Größe jedes Mal zunimmt, wenn Zeilen hinzugefügt oder aktualisiert werden. Wenn ein Satz von Zeilen durch einen COPY Vorgang hinzugefügt wird, wird der neue Satz von Zeilen nach dem Sortierschlüssel sortiert, so wie er dem unsortierten Bereich am Ende der Tabelle hinzugefügt wird. Die neuen Zeilen werden innerhalb des eigenen Satzes, jedoch nicht innerhalb der nicht sortierten Region sortiert.
Das folgende Diagramm zeigt den unsortierten Bereich nach zwei aufeinanderfolgenden COPY Operationen, in dem sich der Sortierschlüssel befindet. CUSTID Aus Gründen der Einfachheit zeigt dieses Beispiel einen zusammengesetzten Sortierschlüssel. Für überlappende Sortierschlüssel gelten jedoch dieselben Grundsätze, abgesehen davon, dass die Auswirkungen der nicht sortierten Region bei überlappenden Tabellen größer sind.
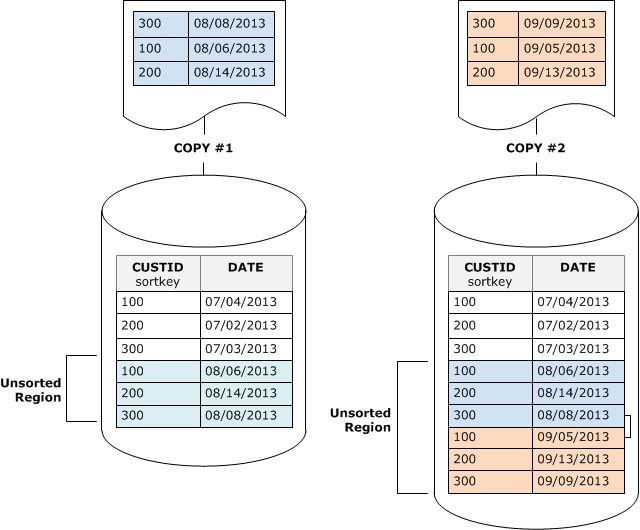
Eine Bereinigung stellt die Sortierreihenfolge der Tabelle in zwei Phasen wieder her:
-
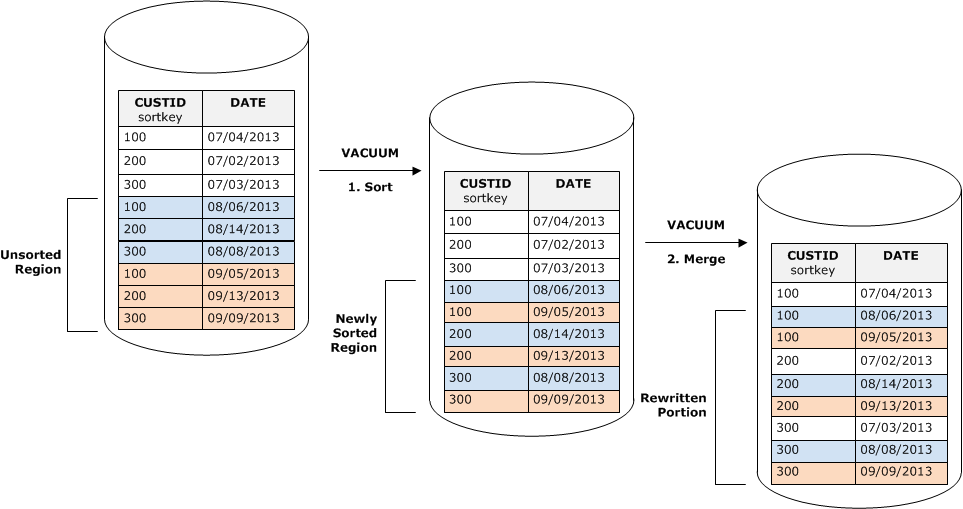
Die nicht sortierte Region wird zu einer neu sortierten Region sortiert.
Die erste Phase ist vergleichsweise kostengünstig, da nur die nicht sortierte Region neu geschrieben wird. Wenn der Bereich der Sortierschlüsselwerte der neu sortierten Region größer als der vorhandene Bereich ist, müssen nur die neuen Zeilen neu geschrieben werden und die Bereinigung ist abgeschlossen. Wenn die sortierte Region beispielsweise ID-Werte von 1 bis 500 enthält und nachfolgende COPY-Operationen Schlüsselwerte hinzufügen, die größer als 500 sind, dann muss nur die nicht sortierte Region neu geschrieben werden.
-
Führen Sie die neu sortierte Region mit der zuvor sortierten Region zusammen.
Wenn sich die Schlüssel im neu sortierten Bereich mit den Schlüsseln im sortierten Bereich überschneiden, VACUUM müssen die Zeilen zusammengeführt werden. Beginnend mit dem Anfang der neu sortierten Region (beim niedrigsten Sortierschlüssel) schreibt die Bereinigungsoperation die zusammengeführten Zeilen aus der zuvor sortierten Region und der neu sortierten Region in einen neuen Satz von Blöcken.
Der Umfang, mit dem der neue Sortierschlüsselbereich mit den vorhandenen Sortierschlüsseln überlappt, legt den Umfang fest, in dem die zuvor sortierte Region neu geschrieben werden muss. Wenn die nicht sortierten Schlüssel über den vorhandenen Sortierbereich verstreut sind, muss eine Bereinigungsoperation möglicherweise vorhandene Teile der Tabelle neu schreiben.
Das folgende Diagramm zeigt, wie ein Vakuum Zeilen sortieren und zusammenführen würde, die zu einer Tabelle hinzugefügt wurden, in der sich der Sortierschlüssel CUSTID befindet. Da jede Kopieroperation einen neuen Satz von Zeilen mit Schlüsselwerten hinzufügt, die die vorhandenen Schlüssel überlappen, muss beinahe die gesamte Tabelle neu geschrieben werden. Das Diagramm zeigt einen einzelnen Sortierungs- und Zusammenführungsvorgang. In der Praxis bestehen große Bereinigungen jedoch aus einer Reihe inkrementeller Sortierungs- und Zusammenführungsvorgänge.
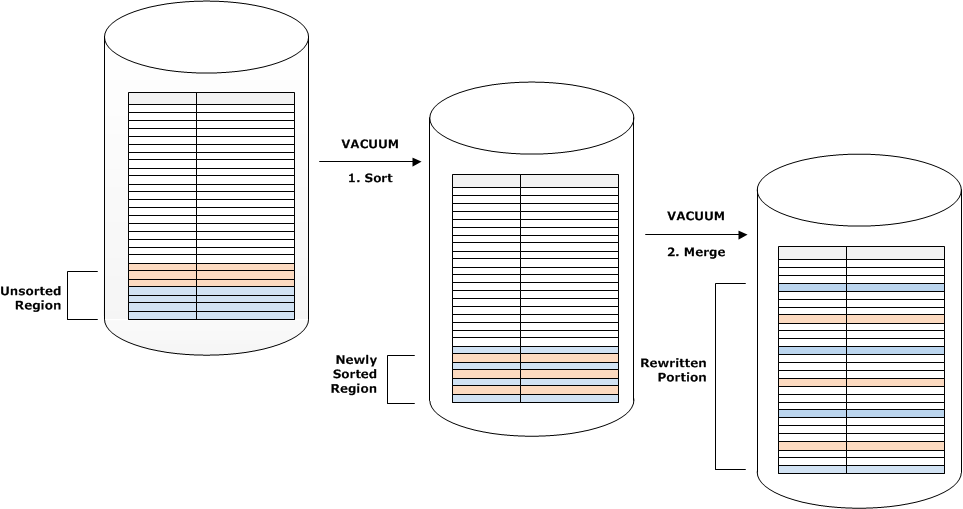
Wenn der Bereich von Sortierschlüsseln in einem Satz neuer Zeilen mit dem Bereich vorhandener Schlüssel überlappt, nehmen die Kosten der Zusammenführungsphase entsprechend der Tabellengröße zu, während die Tabelle an Größe zunimmt. Die Kosten der Sortierphase entsprechen jedoch weiter der Größe der nicht sortierten Region. In diesem Fall sind die Kosten der Zusammenführungsphase größer als die Kosten der Sortierphase, wie das folgende Diagramm zeigt.
Um zu ermitteln, welcher Anteil einer Tabelle erneut zusammengeführt wurde, fragen Sie SUMMARY nach Abschluss des Vakuumvorgangs SVV VACUUM _ _ ab. Die folgende Abfrage zeigt, wie sich die Wirkung von sechs aufeinanderfolgenden Vakuumvorgängen im Laufe der Zeit CUSTSALES vergrößert hat.
select * from svv_vacuum_summary where table_name = 'custsales';table_name | xid | sort_ | merge_ | elapsed_ | row_ | sortedrow_ | block_ | max_merge_ | | partitions | increments | time | delta | delta | delta | partitions -----------+------+------------+------------+------------+-------+------------+---------+--------------- custsales | 7072 | 3 | 2 | 143918314 | 0 | 88297472 | 1524 | 47 custsales | 7122 | 3 | 3 | 164157882 | 0 | 88297472 | 772 | 47 custsales | 7212 | 3 | 4 | 187433171 | 0 | 88297472 | 767 | 47 custsales | 7289 | 3 | 4 | 255482945 | 0 | 88297472 | 770 | 47 custsales | 7420 | 3 | 5 | 316583833 | 0 | 88297472 | 769 | 47 custsales | 9007 | 3 | 6 | 306685472 | 0 | 88297472 | 772 | 47 (6 rows)
Die Spalte merge_increments zeigt die Menge der Daten an, die für die einzelnen Bereinigungsoperationen zusammengeführt wurden. Wenn die Zahl der Zusammenführungsinkremente über aufeinanderfolgende Bereinigungen entsprechend dem Wachstum der Tabellengröße zunimmt, ist das ein Anzeichen dafür, dass jede Bereinigungsoperation eine zunehmende Zahl von Zeilen in der Tabelle neu zusammenführt, da die vorhandenen und neu sortierten Regionen überlappen.
Laden Sie Ihre Daten in der Reihenfolge der Sortierschlüssel
Wenn Sie Ihre Daten mithilfe eines COPY Befehls in der Reihenfolge der Sortierschlüssel laden, können Sie die Notwendigkeit des Vakuumierens reduzieren oder sogar ganz vermeiden.
COPYfügt dem sortierten Bereich der Tabelle automatisch neue Zeilen hinzu, wenn alle der folgenden Bedingungen zutreffen:
-
Die Tabelle verwendet einen zusammengesetzten Sortierschlüssel mit nur einer Sortierspalte.
-
Die Sortierspalte ist NOTNULL.
-
Die Tabelle ist zu 100 Prozent sortiert oder leer.
-
Alle neuen Zeilen liegen in der Sortierreihenfolge höher als die vorhandenen Zeilen, einschließlich Zeilen, die zum Löschen markiert sind. In diesem Beispiel verwendet Amazon Redshift die ersten acht Bytes des Sortierschlüssels, um die Sortierreihenfolge festzulegen.
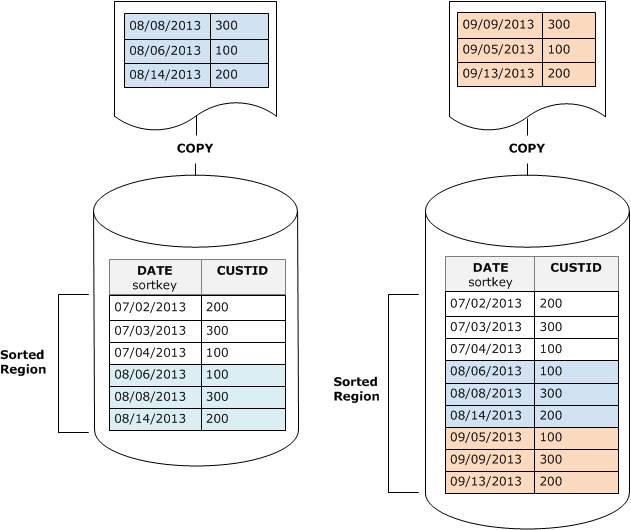
Angenommen, Sie verfügen beispielsweise über eine Tabelle, die Kundenveranstaltungen mittels einer Kunden-ID und eines Zeitpunkts aufzeichnet. Wenn Sie die Tabelle nach der Kunden-ID sortieren, überlappt der Sortierschlüsselbereich der neuen, durch inkrementelle Ladevorgänge hinzugefügten Zeilen wahrscheinlich den vorhandenen Bereich, wie im vorherigen Beispiel gezeigt. Dies führt zu einer kostspieligen Bereinigungsoperation.
Wenn Sie den Sortierschlüssel auf eine Zeitstempelspalte festlegen, werden die neuen Zeilen in Sortierreihenfolge am Ende der Tabelle angefügt, wie im folgenden Diagramm dargestellt. Dies reduziert die Notwendigkeit einer Bereinigung oder macht diese sogar überflüssig.
Verwenden Sie Zeitreihentabellen, um gespeicherte Daten zu reduzieren
Wenn Sie Daten für einen rollierenden Zeitraum warten, verwenden Sie eine Reihe von Tabellen wie im folgenden Diagramm gezeigt.
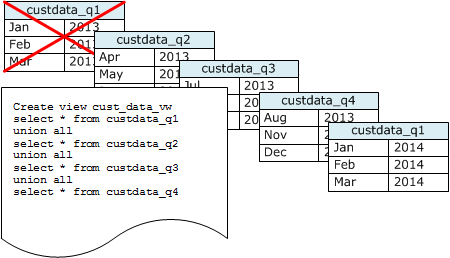
Erstellen Sie jedes Mal, wenn Sie einen Satz von Daten hinzufügen, eine neue Tabelle. Löschen Sie anschließend die älteste Tabelle in der Reihe. Sie erzielen einen doppelten Vorteil:
-
Sie vermeiden die zusätzlichen Kosten, die durch das Löschen von Zeilen entstehen, da eine DROP TABLE Operation viel effizienter ist als eine MassenoperationDELETE.
-
Wenn die Tabellen nach Zeitstempel sortiert sind, wird keine Bereinigung benötigt. Wenn jede Tabelle die Daten für einen Monat enthält, muss eine Bereinigung höchstens die Daten eines Monats neu schreiben, auch wenn die Tabellen nicht nach Zeitstempel sortiert sind.
Sie können eine UNION ALL Ansicht für Berichtsabfragen erstellen, die verschleiert, dass die Daten in mehreren Tabellen gespeichert sind. Wenn eine Abfrage nach dem Sortierschlüssel filtert, kann der Abfrageplaner effizient alle nicht verwendeten Tabellen überspringen. A UNION ALL kann für andere Abfragetypen weniger effizient sein. Daher sollten Sie die Abfrageleistung im Kontext aller Abfragen bewerten, die die Tabellen verwenden.
