Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Testen von Modellen mit Produktionsvarianten
In produktiven ML-Workflows versuchen Datenwissenschaftler und -ingenieure häufig, die Leistung mit verschiedenen Methoden zu verbessern, z. B. durch Automatische Modelloptimierung mit KI SageMaker, Training auf zusätzlichen oder aktuelleren Daten, Verbesserung der Merkmalsauswahl, Verwendung besser aktualisierter Instances und Bereitstellung von Containern. Sie können Produktionsvarianten verwenden, um Ihre Modelle, Instances und Container zu vergleichen und den Kandidaten mit der besten Leistung für die Beantwortung von Inferenzanfragen auszuwählen.
Mit variantenreichen SageMaker KI-Endpunkten können Sie Anfragen zum Endpunktaufruf auf mehrere Produktionsvarianten verteilen, indem Sie die Verkehrsverteilung für jede Variante angeben, oder Sie können für jede Anfrage direkt eine bestimmte Variante aufrufen. In diesem Thema betrachten wir beide Methoden zum Testen von ML-Modellen.
Themen
Testen von Modellen durch Angabe der Verteilung des Datenverkehrs
Um mehrere Modelle zu testen, indem der Datenverkehr zwischen ihnen verteilt wird, geben Sie den Prozentsatz des Datenverkehrs an, der an jedes Modell weitergeleitet wird, indem Sie die Gewichtung für jede Produktionsvariante in der Endpunktkonfiguration angeben. Weitere Informationen finden Sie unter CreateEndpointConfig. Das folgende Diagramm zeigt, wie dies im Detail funktioniert.
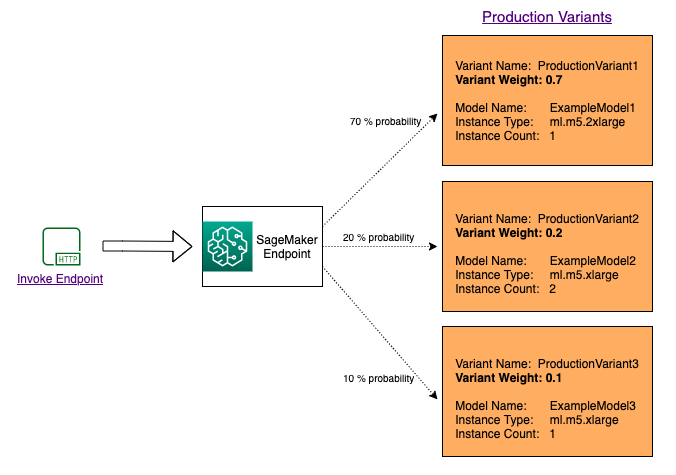
Testen von Modellen durch Aufrufen bestimmter Varianten
Um mehrere Modelle zu testen, indem Sie für jede Anfrage spezifische Modelle aufrufen, geben Sie die spezifische Version des Modells an, das Sie aufrufen möchten, indem Sie beim Aufruf einen Wert für den TargetVariant Parameter angeben. InvokeEndpoint SageMaker KI stellt sicher, dass die Anfrage von der von Ihnen angegebenen Produktionsvariante verarbeitet wird. Wenn Sie die Verteilung des Datenverkehrs bereits angegeben und einen Wert für den Parameter TargetVariant angegeben haben, überschreibt das Ziel-Routing die zufällige Verteilung des Datenverkehrs. Das folgende Diagramm zeigt, wie dies im Detail funktioniert.
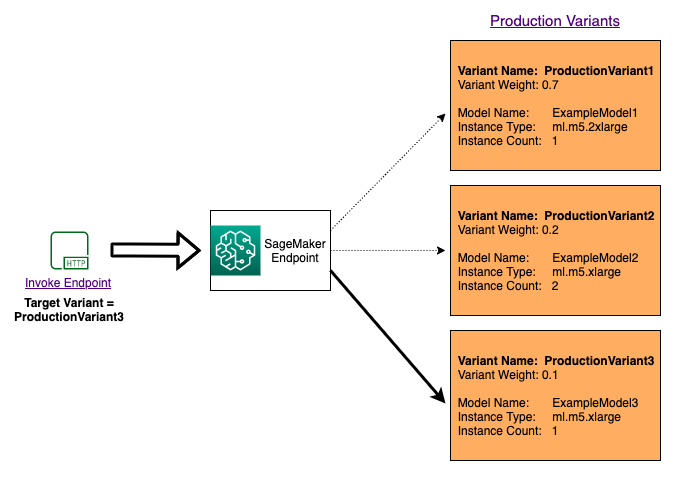
Beispiel für einen A/B Modelltest
Die Durchführung von A/B Tests zwischen einem neuen Modell und einem alten Modell mit Produktionsverkehr kann ein effektiver letzter Schritt im Validierungsprozess für ein neues Modell sein. Beim A/B Testen testen Sie verschiedene Varianten Ihrer Modelle und vergleichen die Leistung der einzelnen Varianten. Wenn die neuere Version des Modells eine bessere Leistung erbringt als die bisherige Version, ersetzen Sie die alte Version des Modells durch die neue Version in der Produktion.
Das folgende Beispiel zeigt, wie Sie A/B Modelltests durchführen. Ein Beispielnotizbuch, das dieses Beispiel implementiert, finden Sie unter "A/B Testen von ML-Modellen in der Produktion
Schritt 1: Erstellen und Bereitstellen von Modellen
Zunächst legen wir fest, wo sich unsere Modelle in Amazon S3 befinden. Diese Standorte werden verwendet, wenn wir unsere Modelle in folgenden Schritten bereitstellen:
model_url = f"s3://{path_to_model_1}" model_url2 = f"s3://{path_to_model_2}"
Als Nächstes erstellen wir die Modellobjekte mit den Bild- und Modelldaten. Diese Modellobjekte werden verwendet, um Produktionsvarianten auf einem Endpunkt bereitzustellen. Die Modelle werden durch Training von ML-Modellen auf verschiedenen Datensätzen, verschiedenen Algorithmen oder ML-Frameworks und verschiedenen Hyperparametern entwickelt:
from sagemaker.amazon.amazon_estimator import get_image_uri model_name = f"DEMO-xgb-churn-pred-{datetime.now():%Y-%m-%d-%H-%M-%S}" model_name2 = f"DEMO-xgb-churn-pred2-{datetime.now():%Y-%m-%d-%H-%M-%S}" image_uri = get_image_uri(boto3.Session().region_name, 'xgboost', '0.90-1') image_uri2 = get_image_uri(boto3.Session().region_name, 'xgboost', '0.90-2') sm_session.create_model( name=model_name, role=role, container_defs={ 'Image': image_uri, 'ModelDataUrl': model_url } ) sm_session.create_model( name=model_name2, role=role, container_defs={ 'Image': image_uri2, 'ModelDataUrl': model_url2 } )
Wir erstellen nun zwei Produktionsvarianten mit jeweils eigenem Modell und Ressourcenanforderungen (Instance-Typ und -Anzahl). Auf diese Weise können Sie auch Modelle mit verschiedenen Instance-Typen testen.
Wir legen ein initial_weight von 1 für beide Varianten fest. Dies bedeutet, dass 50 % der Anfragen an Variant1 und die restlichen 50 % der Anfragen an Variant2 gehen. Die Summe der Gewichtungen in beiden Varianten ist 2 und jede Variante hat eine Gewichtungszuweisung von 1. Das bedeutet, dass jede Variante 50% des gesamten Traffics erhält 1/2.
from sagemaker.session import production_variant variant1 = production_variant( model_name=model_name, instance_type="ml.m5.xlarge", initial_instance_count=1, variant_name='Variant1', initial_weight=1, ) variant2 = production_variant( model_name=model_name2, instance_type="ml.m5.xlarge", initial_instance_count=1, variant_name='Variant2', initial_weight=1, )
Endlich sind wir bereit, diese Produktionsvarianten auf einem SageMaker KI-Endpunkt bereitzustellen.
endpoint_name = f"DEMO-xgb-churn-pred-{datetime.now():%Y-%m-%d-%H-%M-%S}" print(f"EndpointName={endpoint_name}") sm_session.endpoint_from_production_variants( name=endpoint_name, production_variants=[variant1, variant2] )
Schritt 2: Aufrufen der bereitgestellten Modelle
Jetzt senden wir Anfragen an diesen Endpunkt, um Inferenzen in Echtzeit zu erhalten. Wir verwenden sowohl die Verteilung des Datenverkehrs als auch das direkte Targeting.
Zuerst verwenden wir die Verteilung des Datenverkehrs, die wir im vorherigen Schritt konfiguriert haben. Jede Inferenzantwort enthält den Namen der Produktionsvariante, die die Anforderung verarbeitet, sodass wir sehen können, dass der Datenverkehr zu den beiden Produktionsvarianten ungefähr gleich ist.
# get a subset of test data for a quick test !tail -120 test_data/test-dataset-input-cols.csv > test_data/test_sample_tail_input_cols.csv print(f"Sending test traffic to the endpoint {endpoint_name}. \nPlease wait...") with open('test_data/test_sample_tail_input_cols.csv', 'r') as f: for row in f: print(".", end="", flush=True) payload = row.rstrip('\n') sm_runtime.invoke_endpoint( EndpointName=endpoint_name, ContentType="text/csv", Body=payload ) time.sleep(0.5) print("Done!")
SageMaker KI gibt Metriken wie Latency und Invocations für jede Variante in Amazon CloudWatch aus. Eine vollständige Liste der von SageMaker KI ausgegebenen Metriken finden Sie unter. SageMaker Amazon-KI-Metriken bei Amazon CloudWatch Lassen Sie uns die Anzahl der Aufrufe pro Variante abfragen CloudWatch , um zu zeigen, wie Aufrufe standardmäßig auf die Varianten aufgeteilt werden:
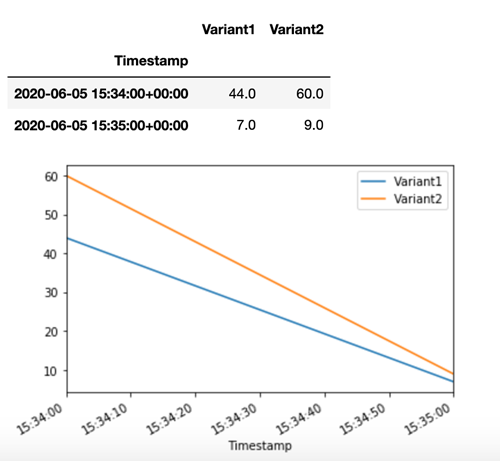
Lassen Sie uns nun eine bestimmte Version des Modells aufrufen, indem Sie Variant1 als TargetVariant im Aufruf von invoke_endpoint angeben.
print(f"Sending test traffic to the endpoint {endpoint_name}. \nPlease wait...") with open('test_data/test_sample_tail_input_cols.csv', 'r') as f: for row in f: print(".", end="", flush=True) payload = row.rstrip('\n') sm_runtime.invoke_endpoint( EndpointName=endpoint_name, ContentType="text/csv", Body=payload, TargetVariant="Variant1" ) time.sleep(0.5)
Um zu bestätigen, dass alle neuen Aufrufe von verarbeitet wurdenVariant1, können wir die Anzahl der Aufrufe pro Variante abfragen CloudWatch . Wir sehen, dass für die letzten Aufrufe (aktueller Zeitstempel) alle Anfragen von Variant1 verarbeitet wurden, wie wir angegeben hatten. Es wurden keine Aufrufe für Variant2 gemacht.
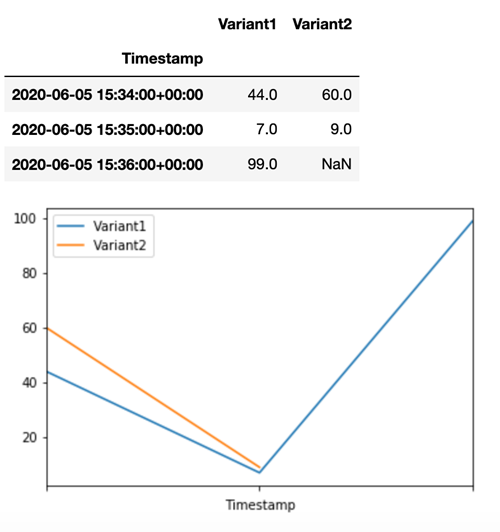
Schritt 3: Beurteilen der Leistung des Modells
Um herauszufinden, welche Modellversion besser abschneidet, bewerten wir für jede Variante die Genauigkeit, die Präzision, den Erinnerungswert, den F1-Wert und die Leistung von Receiver charactersistic/Area unter der Kurve. Betrachten wir zunächst diese Metriken für Variant1:
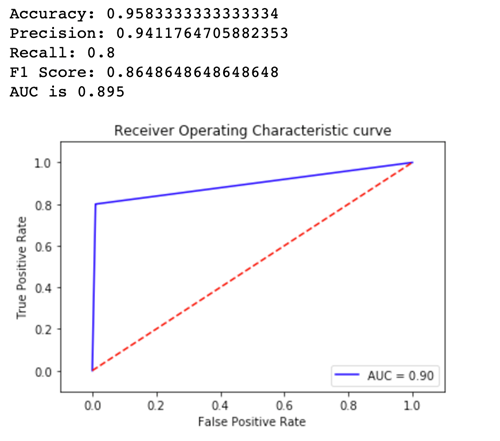
Betrachten wir nun die Metriken für Variant2:
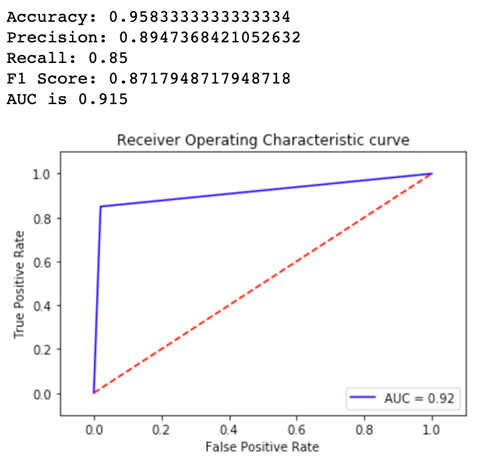
Für die meisten unserer definierten Metriken, ist die Leistung von Variant2 besser, also ist dies diejenige, die wir in der Produktion verwenden möchten.
Schritt 4: Erhöhen des Datenverkehrs auf das beste Modell
Nun, da wir festgestellt haben, dass Variant2 eine bessere Leistung erzielt als Variant1, verlagern wir mehr Verkehr darauf. Wir können weiterhin verwendenTargetVariant, um eine bestimmte Modellvariante aufzurufen, aber ein einfacherer Ansatz besteht darin, die jeder Variante zugewiesenen Gewichtungen durch einen Aufruf UpdateEndpointWeightsAndCapacitieszu aktualisieren. Dadurch wird die Verteilung des Datenverkehrs in Ihre Produktionsvarianten geändert, ohne dass Aktualisierungen des Endpunkts erforderlich sind. Erinnern Sie sich im Einrichtungsbereich daran, dass wir Variantengewichte festgelegt haben, um den Traffic 50/50 aufzuteilen. Die folgenden CloudWatch Kennzahlen für die Gesamtzahl der Aufrufe für jede Variante zeigen uns die Aufrufmuster für jede Variante:
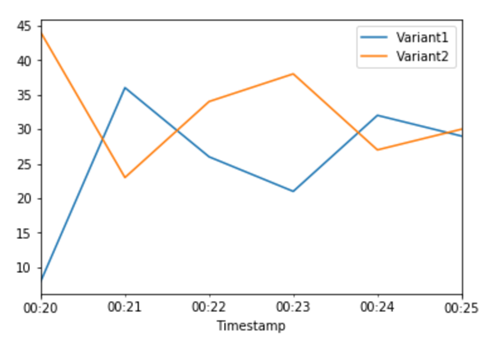
Jetzt verlagern wir 75% des Traffics auf, Variant2 indem wir jeder Variante neue Gewichtungen zuweisen. UpdateEndpointWeightsAndCapacities SageMaker KI sendet jetzt 75% der Inferenzanfragen an Variant2 und die restlichen 25% der Anfragen an. Variant1
sm.update_endpoint_weights_and_capacities( EndpointName=endpoint_name, DesiredWeightsAndCapacities=[ { "DesiredWeight": 25, "VariantName": variant1["VariantName"] }, { "DesiredWeight": 75, "VariantName": variant2["VariantName"] } ] )
Die CloudWatch Kennzahlen für die Gesamtzahl der Aufrufe für jede Variante zeigen uns höhere Aufrufe für als für: Variant2 Variant1
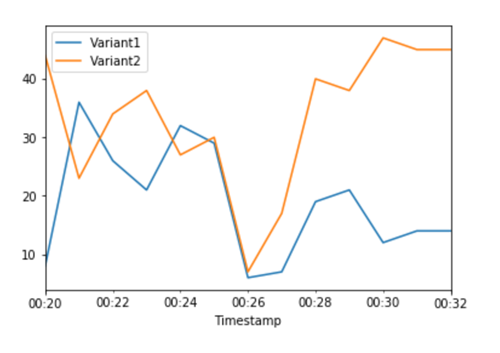
Wir können unsere Metriken weiterhin überwachen, und wenn wir mit der Leistung einer Variante zufrieden sind, können wir 100 % des Datenverkehrs an diese Variante weiterleiten. Wir verwenden UpdateEndpointWeightsAndCapacities, um die Zuweisungen des Datenverkehrs für die Varianten zu aktualisieren. Die Gewichtung für Variant1 ist auf 0 und die Gewichtung für Variant2 auf 1 gesetzt. SageMaker KI sendet jetzt 100% aller Inferenzanfragen anVariant2.
sm.update_endpoint_weights_and_capacities( EndpointName=endpoint_name, DesiredWeightsAndCapacities=[ { "DesiredWeight": 0, "VariantName": variant1["VariantName"] }, { "DesiredWeight": 1, "VariantName": variant2["VariantName"] } ] )
Die CloudWatch Metriken für die Gesamtzahl der Aufrufe für jede Variante zeigen, dass alle Inferenzanfragen von verarbeitet werden Variant2 und dass es keine Inferenzanfragen gibt. Variant1
Sie können Ihren Endpunkt jetzt sicher aktualisieren und Variant1 aus Ihrem Endpunkt löschen. Sie können auch mit dem Testen neuer Modelle in der Produktion fortfahren, indem Sie dem Endpunkt neue Varianten hinzufügen und die Schritte 2 – 4 ausführen.
