Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Modelle für Echtzeit-Inferenzen bereitstellen
Wichtig
Benutzerdefinierte IAM-Richtlinien, die es Amazon SageMaker Studio oder Amazon SageMaker Studio Classic ermöglichen, SageMaker Amazon-Ressourcen zu erstellen, müssen auch Berechtigungen zum Hinzufügen von Tags zu diesen Ressourcen gewähren. Die Berechtigung zum Hinzufügen von Tags zu Ressourcen ist erforderlich, da Studio und Studio Classic automatisch alle von ihnen erstellten Ressourcen taggen. Wenn eine IAM-Richtlinie Studio und Studio Classic das Erstellen von Ressourcen, aber kein Tagging erlaubt, können "AccessDenied" Fehler beim Versuch, Ressourcen zu erstellen, auftreten. Weitere Informationen finden Sie unter Erteilen Sie Berechtigungen für das Taggen von SageMaker KI-Ressourcen.
AWS verwaltete Richtlinien für Amazon SageMaker AIdie Berechtigungen zum Erstellen von SageMaker Ressourcen gewähren, beinhalten bereits Berechtigungen zum Hinzufügen von Tags beim Erstellen dieser Ressourcen.
Es gibt mehrere Möglichkeiten, ein Modell mithilfe von SageMaker KI-Hosting-Diensten bereitzustellen. Sie können ein Modell interaktiv mit SageMaker Studio bereitstellen. Oder Sie können ein Modell mithilfe eines AWS SDK programmgesteuert bereitstellen, z. B. mit dem Python-SDK oder dem SDK für SageMaker Python (Boto3). Sie können die Bereitstellung auch mit dem durchführen. AWS CLI
Bevor Sie beginnen
Bevor Sie ein SageMaker KI-Modell bereitstellen, suchen und notieren Sie sich Folgendes:
-
AWS-Region Wo sich Ihr Amazon S3 S3-Bucket befindet
-
Pfad des Amazon S3 URI, in dem die Modellartefakte gespeichert sind
-
Die IAM-Rolle für KI SageMaker
-
Der Docker Amazon ECR URI-Registrierungspfad für das benutzerdefinierte Image, das den Inferenzcode enthält, oder das Framework und die Version eines integrierten Docker-Images, das unterstützt wird und von AWS
Eine Liste der jeweils AWS-Services verfügbaren Netzwerke finden Sie unter Regionskarten AWS-Region
Wichtig
Der Amazon-S3-Bucket, in dem die Modellartefakte gespeichert sind, muss sich in derselben AWS-Region wie das Modell, das Sie erstellen, befinden.
Gemeinsame Ressourcennutzung mit mehreren Modellen
Mit Amazon SageMaker AI können Sie ein oder mehrere Modelle auf einem Endpunkt bereitstellen. Wenn sich mehrere Modelle einen Endpunkt teilen, nutzen sie gemeinsam die Ressourcen, die dort gehostet werden, wie z. B. die ML-Rechen-Instances, CPUs und Accelerators. Die flexibelste Methode, mehrere Modelle auf einem Endpunkt bereitzustellen, besteht darin, jedes Modell als Inferenzkomponente zu definieren.
Inferenzkomponenten
Eine Inferenzkomponente ist ein SageMaker KI-Hosting-Objekt, mit dem Sie ein Modell auf einem Endpunkt bereitstellen können. In den Einstellungen für die Inferenzkomponente geben Sie das Modell, den Endpunkt und die Art und Weise an, wie das Modell die vom Endpunkt gehosteten Ressourcen nutzt. Um das Modell zu spezifizieren, können Sie ein SageMaker AI-Model-Objekt angeben, oder Sie können die Modellartefakte und das Bild direkt angeben.
In den Einstellungen können Sie die Ressourcennutzung optimieren, indem Sie anpassen, wie die erforderlichen CPU-Kerne, Accelerators und Speicher dem Modell zugewiesen werden. Sie können mehrere Inferenzkomponenten für einen Endpunkt bereitstellen, wobei jede Inferenzkomponente ein Modell und die für dieses Modell erforderliche Ressourcennutzung enthält.
Nachdem Sie eine Inferenzkomponente bereitgestellt haben, können Sie das zugehörige Modell direkt aufrufen, wenn Sie die InvokeEndpoint Aktion in der SageMaker API verwenden.
Inferenzkomponenten bieten die folgenden Vorteile:
- Flexibilität
-
Die Inferenzkomponente entkoppelt die Einzelheiten zum Hosting des Modells vom Endpunkt selbst. Dies bietet mehr Flexibilität und Kontrolle darüber, wie Modelle über einen Endpunkt gehostet und bereitgestellt werden. Sie können mehrere Modelle auf derselben Infrastruktur hosten und je nach Bedarf Modelle zu einem Endpunkt hinzufügen oder daraus entfernen. Sie können jedes Modell unabhängig aktualisieren.
- Skalierbarkeit
-
Sie können angeben, wie viele Kopien jedes Modells gehostet werden sollen, und Sie können eine Mindestanzahl von Kopien festlegen, um sicherzustellen, dass das Modell in der Menge geladen wird, die Sie für die Bearbeitung von Anforderungen benötigen. Sie können jede Kopie einer Inferenzkomponente auf Null herunterskalieren, sodass Platz für eine weitere Kopie zum Hochskalieren geschaffen wird.
SageMaker KI verpackt Ihre Modelle als Inferenzkomponenten, wenn Sie sie bereitstellen, indem Sie Folgendes verwenden:
-
SageMaker Studio Classic.
-
Das SageMaker Python-SDK zur Bereitstellung eines Model-Objekts (wobei Sie den Endpunkttyp auf festlegen
EndpointType.INFERENCE_COMPONENT_BASED). -
Das AWS SDK für Python (Boto3) zur Definition von
InferenceComponentObjekten, die Sie auf einem Endpunkt bereitstellen.
Stellen Sie Modelle mit SageMaker Studio bereit
Führen Sie die folgenden Schritte aus, um Ihr Modell interaktiv über SageMaker Studio zu erstellen und bereitzustellen. Weitere Informationen über Studio finden Sie in der Studio-Dokumentation. Weitere Anleitungen zu verschiedenen Bereitstellungsszenarien finden Sie im Blog Einfache Paketierung und Bereitstellung klassischer ML-Modelle und LLMs mit Amazon SageMaker AI — Teil 2.
Vorbereiten Ihrer Artefakte und Berechtigungen
Füllen Sie diesen Abschnitt aus, bevor Sie ein Modell in Studio erstellen. SageMaker
Sie haben zwei Möglichkeiten, Ihre eigenen Artefakte zu verwenden und ein Modell in Studio zu erstellen:
-
Sie können ein vorgefertigtes
tar.gz-Archiv verwenden, das Ihre Modellartefakte, benutzerdefinierten Inferenzcode und alle in einerrequirements.txt-Datei aufgelisteten Abhängigkeiten enthalten sollte. -
SageMaker KI kann Ihre Artefakte für Sie verpacken. Sie müssen nur Ihre Rohmodellartefakte und alle Abhängigkeiten in einer
requirements.txtDatei zusammenführen, und SageMaker AI kann Ihnen den Standard-Inferenzcode zur Verfügung stellen (oder Sie können den Standardcode mit Ihrem eigenen benutzerdefinierten Inferenzcode überschreiben). SageMaker AI unterstützt diese Option für die folgenden Frameworks: PyTorch, XGBoost.
Sie müssen nicht nur Ihr Modell, Ihre AWS Identity and Access Management (IAM-) Rolle und einen Docker-Container (oder das gewünschte Framework und die gewünschte Version, für die SageMaker AI einen vorgefertigten Container hat) mitbringen, sondern auch Berechtigungen zum Erstellen und Bereitstellen von Modellen über AI Studio erteilen. SageMaker
Sie sollten die AmazonSageMakerFullAccessRichtlinie an Ihre IAM-Rolle angehängt haben, damit Sie auf SageMaker KI und andere relevante Dienste zugreifen können. Um die Preise der Instance-Typen in Studio zu sehen, müssen Sie auch die AWS PriceListServiceFullAccessRichtlinie anhängen (oder, wenn Sie nicht die gesamte Richtlinie anhängen möchten, genauer gesagt die pricing:GetProducts Aktion).
Wenn Sie beim Erstellen eines Modells Ihre Modellartefakte hochladen möchten (oder eine Beispiel-Nutzlastdatei für Inferenzempfehlungen hochladen), müssen Sie einen Amazon-S3-Bucket erstellen. Dem Bucket-Namen muss das Wort SageMaker AI vorangestellt werden. Alternative Groß-/Kleinschreibung von SageMaker KI ist ebenfalls zulässig: Sagemaker odersagemaker.
Es wird empfohlen, die Benennungskonvention für Buckets zu verwenden: sagemaker-{. Dieser Bucket wird verwendet, um die Artefakte zu speichern, die Sie hochladen.Region}-{accountID}
Nachdem Sie den Bucket erstellt haben, fügen Sie ihm die folgende CORS-Richtlinie (Cross-Origin Resource Sharing) hinzu:
[ { "AllowedHeaders": ["*"], "ExposeHeaders": ["Etag"], "AllowedMethods": ["PUT", "POST"], "AllowedOrigins": ['https://*.sagemaker.aws'], } ]
Sie können eine CORS-Richtlinie mit einer der folgenden Methoden an einen Amazon-S3-Bucket anfügen:
-
über die Seite Bearbeiten von Cross-Origin Resource Sharing (CORS)
in der Amazon-S3-Konsole -
Verwenden der Amazon S3 S3-API PutBucketCors
-
Mit dem Befehl AWS CLI put-bucket-cors:
aws s3api put-bucket-cors --bucket="..." --cors-configuration="..."
Erstellen eines bereitstellbaren Modells
In diesem Schritt erstellen Sie eine bereitstellbare Version Ihres Modells in SageMaker KI, indem Sie Ihre Artefakte zusammen mit zusätzlichen Spezifikationen wie Ihrem gewünschten Container und Framework, beliebigen benutzerdefinierten Inferenzcode und Netzwerkeinstellungen bereitstellen.
Erstellen Sie ein bereitstellbares Modell in SageMaker Studio, indem Sie wie folgt vorgehen:
-
Öffnen Sie die SageMaker Studio-Anwendung.
-
Wählen Sie im linken Navigationsbereich Models (Modelle) aus.
-
Wählen Sie die Registerkarte Bereitstellbare Modelle aus.
-
Wählen Sie auf der Seite Bereitstellbare Modelle die Option Erstellen aus.
-
Geben Sie auf der Seite Bereitstellbares Modell erstellen in das Feld Modellname einen Namen für das Modell ein.
Auf der Seite Bereitstellbares Modell erstellengibt es mehrere weitere Abschnitte, die Sie ausfüllen müssen.
Der Abschnitt Container-Definition sieht wie der folgende Screenshot aus:
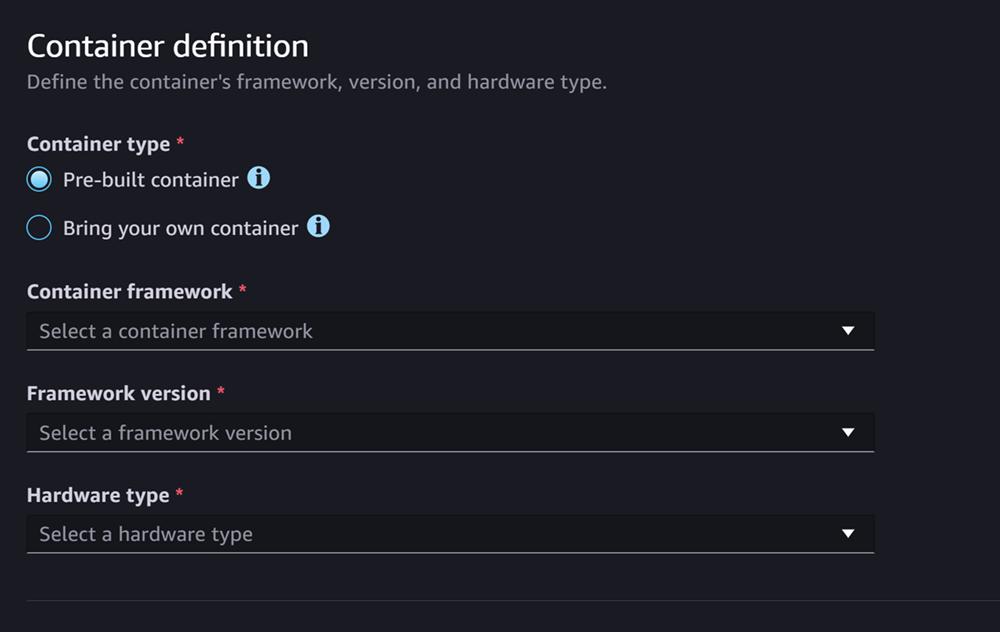
Für den Container-Definition Abschnitt, gehen Sie wie folgt vor:
-
Wählen Sie als Containertyp Pre-built Container aus, wenn Sie einen SageMaker KI-verwalteten Container verwenden möchten, oder wählen Sie Bring your own container aus, wenn Sie Ihren eigenen Container haben.
-
Wenn Sie Pre-built Container ausgewählt haben, wählen Sie das Container-Framework, die Framework-Version und den Hardwaretyp aus, den Sie verwenden möchten.
-
Wenn Sie Eigenen Container verwenden ausgewählt haben, geben Sie einen Amazon-ECR-Pfad für den ECR-Pfad zum Container-Image ein.
Füllen Sie dann den Abschnitt Artefakte aus, der wie der folgende Screenshot aussieht:

Für den -Artefakte Abschnitt, gehen Sie wie folgt vor:
-
Wenn Sie eines der Frameworks verwenden, die SageMaker AI für das Verpacken von Modellartefakten (PyTorch oder XGBoost) unterstützt, können Sie für Artefakte die Option Artefakte hochladen wählen. Mit dieser Option können Sie einfach Ihre Rohmodellartefakte, jeden benutzerdefinierten Inferenzcode, den Sie haben, und Ihre Datei requirements.txt angeben, und SageMaker AI kümmert sich für Sie um die Paketierung des Archivs. Gehen Sie wie folgt vor:
-
Wählen Sie für Artefakte die Option Artefakte hochladen aus, um Ihre Dateien weiterhin bereitzustellen. Andernfalls, wenn Sie bereits über ein
tar.gz-Archiv verfügen, das Ihre Modelldateien, Ihren Inferenzcode und Ihrerequirements.txt-Datei enthält, wählen Sie S3-URI für vorgefertigte Artefakte eingeben aus. -
Wenn Sie Ihre Artefakte hochladen möchten, geben Sie für den S3-Bucket den Amazon S3 S3-Pfad zu einem Bucket ein, in dem SageMaker KI Ihre Artefakte speichern soll, nachdem sie für Sie verpackt wurden. Führen Sie anschließend die folgenden Schritte aus.
-
Laden Sie unter Modellartefakte hochladen Ihre Modelldateien hoch.
-
Wählen Sie unter Inferenzcode die Option Standard-Inferenzcode verwenden aus, wenn Sie den Standardcode verwenden möchten, den SageMaker KI für die Bereitstellung von Inferenzen bereitstellt. Wenn Sie stattdessen Ihren eigenen Inferenzcode verwenden möchten, wählen Sie Benutzerdefinierten Inferenzcode hochladen aus.
-
Laden Sie über requirements.txt hochladen eine Textdatei hoch, in der alle Abhängigkeiten aufgeführt sind, die Sie zur Laufzeit installieren möchten.
-
-
Wenn Sie kein Framework verwenden, das SageMaker KI für das Verpacken von Modellartefakten unterstützt, zeigt Ihnen Studio die Option Pre-packagedArtefakte an, und Sie müssen alle Ihre Artefakte, die bereits verpackt sind, als Archiv bereitstellen.
tar.gzGehen Sie wie folgt vor:-
Wählen Sie für Pre-packaged Artefakte die Option S3-URI eingeben für vorverpackte Modellartefakte aus, wenn Sie Ihr
tar.gzArchiv bereits auf Amazon S3 hochgeladen haben. Wählen Sie Vorverpackte Modellartefakte hochladen aus, wenn Sie Ihr Archiv direkt auf AI hochladen möchten. SageMaker -
Wenn Sie S3-URI für vorgefertigte Modellartefakte eingeben ausgewählt haben, geben Sie unter S3-URI den Amazon-S3-Pfad zu Ihrem Archiv ein. Andernfalls wählen Sie das Archiv aus und laden es von Ihrem lokalen Rechner hoch.
-
Der nächste Abschnitt ist Sicherheit und sieht wie der folgende Screenshot aus:
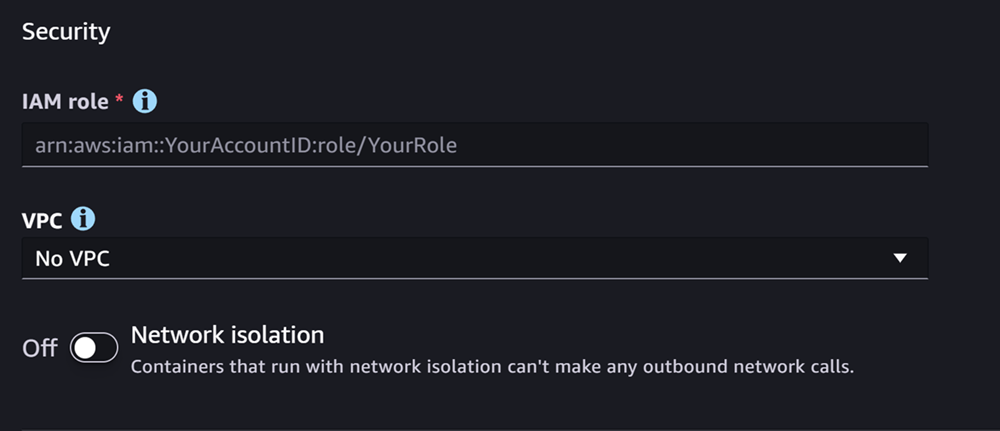
Für den Sicherheit Gehen Sie im Abschnitt wie folgt vor:
-
Geben Sie unter IAM-Rolle den ARN für eine IAM-Rolle ein.
-
(Optional) Unter Virtual Private Cloud (VPC) können Sie eine Amazon-VPC zum Speichern Ihrer Modellkonfiguration und Ihrer Artefakte auswählen.
-
(Optional) Aktivieren Sie die Option Netzwerkisolierung, wenn Sie den Internetzugang Ihres Containers einschränken möchten.
Abschließend können Sie bei Bedarf den Abschnitt Erweiterte Optionen ausfüllen, der wie der folgende Screenshot aussieht:
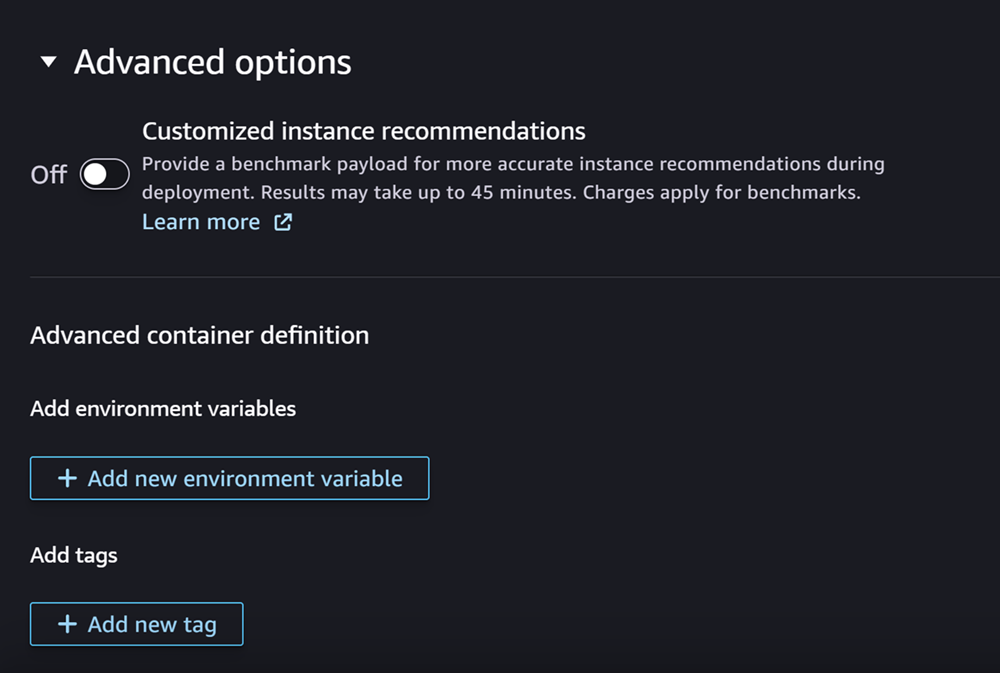
(Optional) Für Erweiterte Optionen Abschnitt, gehen Sie wie folgt vor:
-
Aktivieren Sie die Option Benutzerdefinierte Instanzempfehlungen, wenn Sie nach der Erstellung einen Amazon SageMaker Inference Recommender-Job für Ihr Modell ausführen möchten. Inference Recommender ist ein Feature, das Ihnen empfohlene Instance-Typen zur Optimierung der Leistung und der Kosten von Inferenzen bietet. Sie können sich diese Instance-Empfehlungen ansehen, wenn Sie sich auf die Bereitstellung Ihres Modells vorbereiten.
-
Geben Sie unter Umgebungsvariablen hinzufügen die Umgebungsvariablen für Ihren Container als Schlüssel-Wert-Paare ein.
-
Geben Sie unter Tags beliebige Tags als Schlüssel-Wert-Paare ein.
-
Wählen Sie nach Abschluss der Modell- und Container-Konfiguration die Option Bereitstellbares Modell erstellen aus.
Sie sollten jetzt über ein Modell in SageMaker Studio verfügen, das für die Bereitstellung bereit ist.
Bereitstellen Ihres Modells
Schließlich stellen Sie das Modell, das Sie im vorherigen Schritt konfiguriert haben, auf einem HTTPS-Endpunkt bereit. Sie können entweder ein einzelnes oder mehrere Modelle für den Endpunkt bereitstellen.
Modell- und Endpunktkompatibilität
Bevor Sie ein Modell auf einem Endpunkt bereitstellen können, müssen Modell und Endpunkt kompatibel sein und dieselben Werte für die folgenden Einstellungen aufweisen:
-
die IAM-Rolle
-
die Amazon VPC, einschließlich ihrer Subnetze und Sicherheitsgruppen
-
die Netzwerkisolierung (aktiviert oder deaktiviert)
Studio verhindert auf folgende Weise, dass Sie Modelle auf inkompatiblen Endpunkten bereitstellen:
-
Wenn Sie versuchen, ein Modell auf einem neuen Endpunkt bereitzustellen, konfiguriert SageMaker AI den Endpunkt mit kompatiblen Anfangseinstellungen. Wenn Sie die Kompatibilität durch eine Änderung dieser Einstellungen beeinträchtigen, zeigt Studio eine Warnung an und verhindert die Bereitstellung.
-
Wenn Sie versuchen, eine Bereitstellung auf einem vorhandenen Endpunkt durchzuführen und dieser Endpunkt nicht kompatibel ist, zeigt Studio eine Warnung an und verhindert die Bereitstellung.
-
Wenn Sie versuchen, einer Bereitstellung mehrere Modelle hinzuzufügen, die nicht miteinander kompatibel sind, verhindert Studio die Bereitstellung dieser Modelle.
Wenn Studio die Warnung zur Modell- und Endpunktinkompatibilität anzeigt, können Sie über die Schaltfläche Details anzeigen prüfen, welche Einstellungen nicht kompatibel sind.
Eine Möglichkeit, ein Modell bereitzustellen, besteht darin, in Studio wie folgt vorzugehen:
-
Öffnen Sie die SageMaker Studio-Anwendung.
-
Wählen Sie im linken Navigationsbereich Models (Modelle) aus.
-
Wählen Sie auf der Seite Modelle ein oder mehrere Modelle aus der Liste der SageMaker KI-Modelle aus.
-
Wählen Sie Bereitstellen.
-
Öffnen Sie das Dropdown-Menü unter Endpunktname. Sie können entweder einen vorhandenen Endpunkt auswählen oder einen neuen Endpunkt erstellen, auf dem Sie das Modell bereitstellen.
-
Wählen Sie unter Instance-Typ den Instance-Typ aus, den Sie für den Endpunkt verwenden möchten. Wenn Sie zuvor einen Inference-Recommender-Job für das Modell ausgeführt haben, werden Ihre empfohlenen Instance-Typen in der Liste unter dem Titel Empfohlen angezeigt. Andernfalls werden Ihnen einige voraussichtliche Instances angezeigt, die möglicherweise für Ihr Modell geeignet sind.
Kompatibilität mit dem Instanztyp für JumpStart
Wenn Sie ein JumpStart Modell bereitstellen, zeigt Studio nur Instanztypen an, die das Modell unterstützt.
-
Geben Sie unter Anfängliche Instance-Anzahl die anfängliche Anzahl der Instances ein, die Sie für Ihren Endpunkt bereitstellen möchten.
-
Geben Sie unter Maximale Instance-Anzahl die maximale Anzahl von Instances an, die der Endpunkt bereitstellen kann, wenn er entsprechend einem Anstieg des Datenverkehrs skaliert wird.
-
Wenn es sich bei dem Modell, das Sie bereitstellen, um eines der am häufigsten verwendeten JumpStart LLMs aus dem Model Hub handelt, wird die Option Alternative Konfigurationen hinter den Feldern Instanztyp und Instanzanzahl angezeigt.
Bei den gängigsten JumpStart LLMs wurden Instance-Typen vorab mit Benchmarks verglichen, AWS um entweder Kosten oder Leistung zu optimieren. Diese Daten können Ihnen bei der Entscheidung helfen, welchen Instance-Typ Sie für die Bereitstellung Ihres LLM verwenden möchten. Wählen Sie Alternative Konfigurationen aus, um ein Dialogfeld zu öffnen, das die vorab geprüften Daten enthält. Das Panel sieht wie im folgenden Screenshot aus:
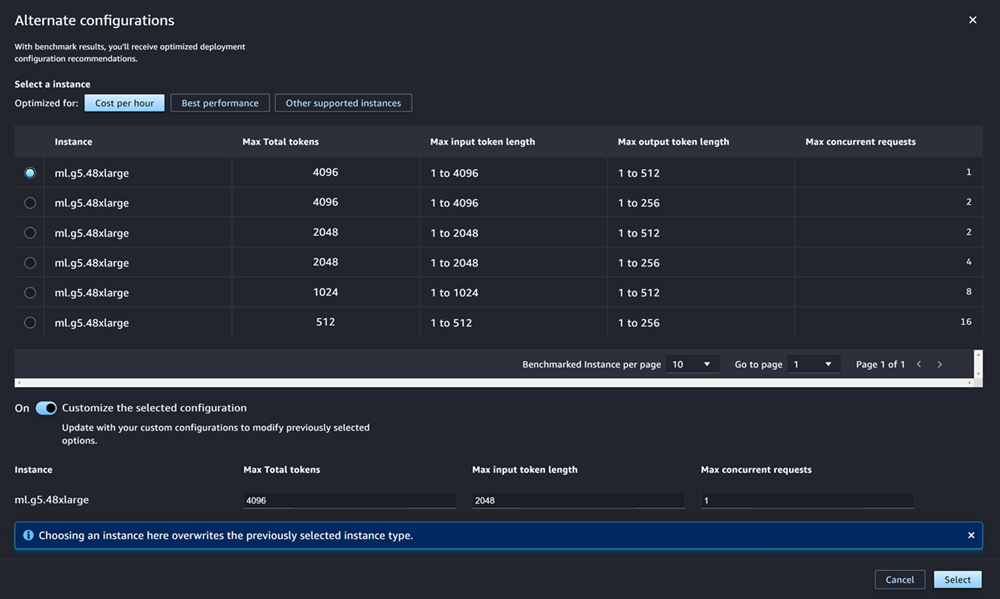
Gehen Sie im Feld Alternative Konfigurationen wie folgt vor:
-
Auswahl von Instance-Typen Sie können Kosten pro Stunde oder Beste Leistung wählen, um Instance-Typen anzuzeigen, die entweder die Kosten oder die Leistung für das angegebene Modell optimieren. Sie können auch Andere unterstützte Instanzen wählen, um eine Liste anderer Instanztypen anzuzeigen, die mit dem JumpStart Modell kompatibel sind. Beachten Sie, dass die Auswahl eines Instance-Typs hier alle zuvor in Schritt 6 ausgewählten Instances überschreibt.
-
(Optional) Aktivieren Sie die Option Ausgewählte Konfiguration anpassen, um Max. Token-Gesamtzahl (die maximale Anzahl von Tokens, die Sie zulassen möchten, d. h. die Summe Ihrer Eingabe-Token und der generierten Ausgabe des Modells), Max. Länge des Eingabe-Tokens (die maximale Anzahl von Tokens, die Sie für die Eingabe jeder Anforderung zulassen möchten) und Max. Anzahl gleichzeitiger Anfragen (die maximale Anzahl von Anfragen, die das Modell gleichzeitig verarbeiten kann) anzugeben.
-
Wählen Sie Auswählen, um Ihren Instance-Typ und Ihre Konfigurationseinstellungen zu bestätigen.
-
-
Das Feld Modell sollte bereits mit dem Namen des Modells oder der Modelle ausgefüllt sein, das bzw. die Sie bereitstellen. Sie können Modell hinzufügen auswählen, um der Bereitstellung weitere Modelle hinzuzufügen. Füllen Sie für jedes Modell, das Sie hinzufügen, die folgenden Felder aus:
-
Geben Sie unter Anzahl der CPU-Kerne die CPU-Kerne ein, die Sie für die Nutzung des Modells reservieren möchten.
-
Geben Sie unter Mindestanzahl an Kopien die Mindestanzahl von Modellkopien ein, die zu einem bestimmten Zeitpunkt auf dem Endpunkt gehostet werden sollen.
-
Geben Sie unter Min. CPU-Speicher (MB) die Mindestmenge an Arbeitsspeicher (in MB) ein, die das Modell benötigt.
-
Geben Sie für Max. CPU-Speicher (MB) die maximale Speichermenge (in MB) ein, die das Modell verwenden darf.
-
-
(Optional) Führen Sie unter Erweiterte Optionen Folgendes aus:
-
Verwenden Sie für die IAM-Rolle entweder die standardmäßige SageMaker AI IAM-Ausführungsrolle oder geben Sie Ihre eigene Rolle an, die über die erforderlichen Berechtigungen verfügt. Beachten Sie, dass diese IAM-Rolle mit der Rolle identisch sein muss, die Sie beim Erstellen des bereitstellbaren Modells angegeben haben.
-
Unter Virtual Private Cloud (VPC) können Sie eine VPC angeben, in der Sie Ihren Endpunkt hosten möchten.
-
Wählen Sie für Encryption KMS Key einen AWS KMS Schlüssel aus, um Daten auf dem Speichervolume zu verschlüsseln, das an die ML-Compute-Instanz angehängt ist, die den Endpunkt hostet.
-
Aktivieren Sie die Option Netzwerkisolierung aktivieren, um den Internetzugang Ihres Containers einzuschränken.
-
Füllen Sie unter Timeout-Konfiguration die Felder Timeout beim Herunterladen von Modelldaten (Sekunden) und Timeout für die Zustandsprüfung beim Container-Start (Sekunden) aus. Diese Werte bestimmen die maximale Zeit, die SageMaker KI für das Herunterladen des Modells in den Container bzw. das Starten des Containers einräumt.
-
Geben Sie unter Tags beliebige Tags als Schlüssel-Wert-Paare ein.
Anmerkung
SageMaker AI konfiguriert die IAM-Rollen-, VPC- und Netzwerkisolationseinstellungen mit Anfangswerten, die mit dem Modell kompatibel sind, das Sie bereitstellen. Wenn Sie die Kompatibilität durch eine Änderung dieser Einstellungen beeinträchtigen, zeigt Studio eine Warnung an und verhindert die Bereitstellung.
-
Nachdem Sie die Optionen konfiguriert haben, sollte die Seite wie im folgenden Screenshot aussehen.
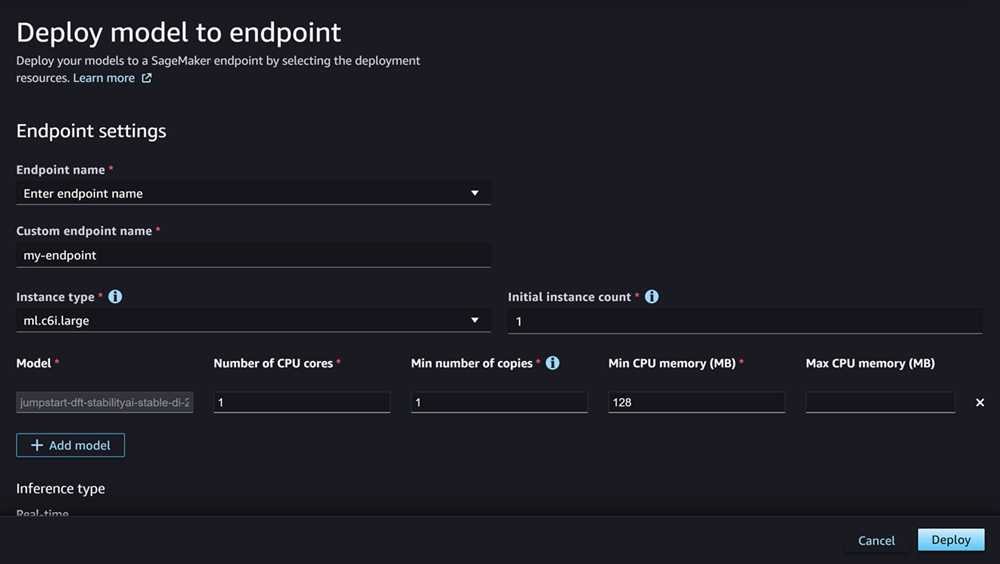
Nachdem Sie die Bereitstellung konfiguriert haben, wählen Sie Bereitstellen aus, um den Endpunkt zu erstellen und Ihr Modell bereitzustellen.
Bereitstellen von Modellen mit den Python-SDKs
Mit dem SageMaker Python-SDK können Sie Ihr Modell auf zwei Arten erstellen. Die erste Möglichkeit besteht darin, ein Modellobjekt aus der Klasse Model oder ModelBuilder zu erstellen. Wenn Sie die Model-Klasse verwenden, um Ihr Model-Objekt zu erstellen, müssen Sie das Modellpaket oder den Inferenzcode (abhängig von Ihrem Modellserver), Skripte für die Serialisierung und Deserialisierung von Daten zwischen dem Client und dem Server sowie alle Abhängigkeiten angeben, die zur Nutzung auf Amazon S3 hochgeladen werden sollen. Alternativ können Sie Ihr Modell mit ModelBuilder erstellen, wofür Sie Modellartefakte oder Inferenzcode bereitstellen. ModelBuilder erfasst automatisch Ihre Abhängigkeiten, leitet die benötigten Serialisierungs- und Deserialisierungsfunktionen ab und verpackt Ihre Abhängigkeiten, um Ihr Model-Objekt zu erstellen. Mehr über ModelBuilder erfahren Sie unter Erstellen Sie ein Modell in Amazon SageMaker AI mit ModelBuilder.
Im folgenden Abschnitt werden beide Methoden beschrieben, mit denen Sie Ihr Modell erstellen und Ihr Modellobjekt bereitstellen können.
Einrichten
Die folgenden Beispiele bereiten den Prozess der Modellbereitstellung vor. Sie importieren die erforderlichen Bibliotheken und definieren die S3-URL, die die Modellartefakte lokalisiert.
Beispiel Modellartefakt-URL
Der folgende Code erstellt eine beispielhafte Amazon-S3-URL. Die URL sucht nach Modellartefakten für ein vortrainiertes Modell in einem Amazon-S3-Bucket.
# Create a variable w/ the model S3 URL # The name of your S3 bucket: s3_bucket = "amzn-s3-demo-bucket" # The directory within your S3 bucket your model is stored in: bucket_prefix = "sagemaker/model/path" # The file name of your model artifact: model_filename = "my-model-artifact.tar.gz" # Relative S3 path: model_s3_key = f"{bucket_prefix}/"+model_filename # Combine bucket name, model file name, and relate S3 path to create S3 model URL: model_url = f"s3://{s3_bucket}/{model_s3_key}"
Die vollständige Amazon-S3-URL wird in der Variablen model_url gespeichert, die in den folgenden Beispielen verwendet wird.
-Übersicht
Es gibt mehrere Möglichkeiten, Modelle mit dem SageMaker Python-SDK oder dem SDK für Python (Boto3) bereitzustellen. In den folgenden Abschnitten werden die Schritte zusammengefasst, die Sie für verschiedene mögliche Ansätze ausführen. Diese Schritte werden anhand der folgenden Beispiele veranschaulicht.
Konfiguration
In den folgenden Beispielen werden die Ressourcen konfiguriert, die Sie für die Bereitstellung eines Modells auf einem Endpunkt benötigen.
Bereitstellen
In den folgenden Beispielen wird ein Modell für einen Endpunkt bereitgestellt.
Stellen Sie Modelle bereit mit dem AWS CLI
Sie können ein Modell auf einem Endpunkt bereitstellen, indem Sie den verwenden AWS CLI.
-Übersicht
Wenn Sie ein Modell mit dem bereitstellen AWS CLI, können Sie es mit oder ohne Verwendung einer Inferenzkomponente bereitstellen. In den folgenden Abschnitten werden die Befehle zusammengefasst, die Sie für beide Ansätze ausführen. Diese Befehle werden anhand der folgenden Beispiele veranschaulicht.
Konfiguration
In den folgenden Beispielen werden die Ressourcen konfiguriert, die Sie für die Bereitstellung eines Modells auf einem Endpunkt benötigen.
Bereitstellen
In den folgenden Beispielen wird ein Modell für einen Endpunkt bereitgestellt.
