Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Automatisieren Sie die Datenkennzeichnung
Wenn Sie möchten, kann Amazon SageMaker Ground Truth aktives Lernen verwenden, um die Kennzeichnung Ihrer Eingabedaten für bestimmte integrierte Aufgabentypen zu automatisieren. Aktives Lernen ist eine Machine-Learning-Methode, mit der Daten identifiziert werden, die von Ihren Workern gekennzeichnet werden sollten. In Ground Truth wird diese Funktionalität als automatisches Daten-Labeling bezeichnet. Das automatische Daten-Labeling trägt dazu bei, erforderliche Kosten und Zeit für die Kennzeichnung Ihres Datasatzes im Vergleich zur ausschließlichen Verwendung von Menschen zu reduzieren. Wenn Sie die automatische Kennzeichnung verwenden, fallen für Sie SageMaker Schulungs- und Inferenzkosten an.
Es wird empfohlen, ein automatisches Daten-Labeling für große Datensätze zu verwenden, da die neuronalen Netzwerke, die mit aktivem Lernen verwendet werden, für jeden neuen Datensatz eine erhebliche Menge an Daten benötigen. Wenn Sie mehr Daten bereitstellen, sind Prognosen hoher Genauigkeit wahrscheinlicher. Daten werden nur dann automatisch gekennzeichnet, wenn das neuronale Netzwerk, das im Modell des automatischen Labeling verwendet wird, eine akzeptabel hohe Genauigkeit erreichen kann. Daher besteht bei größeren Datensätzen eher die Möglichkeit, dass die Daten automatisch gekennzeichnet werden, da das neuronale Netzwerk eine ausreichend hohe Genauigkeit für die automatische Kennzeichnung erreichen kann. Automatisches Daten-Labeling ist am besten geeignet, wenn Sie Tausende von Datenobjekten haben. Die minimale Anzahl von Objekten, die für das automatische Daten-Labeling zulässig ist, beträgt 1.250, aber wir empfehlen dringend, mindestens 5.000 Objekte bereitzustellen.
Das automatische Daten-Labeling ist nur für die folgenden in Ground Truth integrierten Algorithmen verfügbar:
Streaming-Kennzeichnungsaufträge unterstützen kein automatisches Daten-Labeling.
Wie Sie einen benutzerdefinierten Workflow für aktives Lernen unter Verwendung Ihres eigenen Modells erstellen, erfahren Sie unter Einrichten eines Workflows für aktives Lernen mit Ihrem eigenen Modell ein.
Eingabedatenkontingente gelten für Aufträge des automatischen Daten-Labeling. Informationen zur Datensatzgröße, Eingabedatengröße und Auflösungsgrenzen finden Sie unter Eingabedatenkontingente.
Anmerkung
Bevor Sie ein Modell mit automatischem Labeling in der Produktion verwenden, müssen Sie es optimieren und/oder testen. Sie können das Modell für den von Ihrem Kennzeichnungsauftrag erstellten Datensatz optimieren (oder ein anderes überwachtes Modell Ihrer Wahl erstellen und optimieren), um die Architektur und die Hyperparameter des Modells zu optimieren. Wenn Sie sich für das Modell für eine Inferenz ohne Optimierung entscheiden, empfehlen wir nachdrücklich, seine Genauigkeit unbedingt bei einer repräsentativen (z. B. zufällig ausgewählten) Teilmenge des mit Ground Truth kennzeichneten Datensätze auszuwerten und sicherzustellen, dass es Ihren Erwartungen entspricht.
Funktionsweise
Sie aktivieren das automatische Daten-Labeling, wenn Sie einen Kennzeichnungsauftrag erstellen. Es funktioniert so:
-
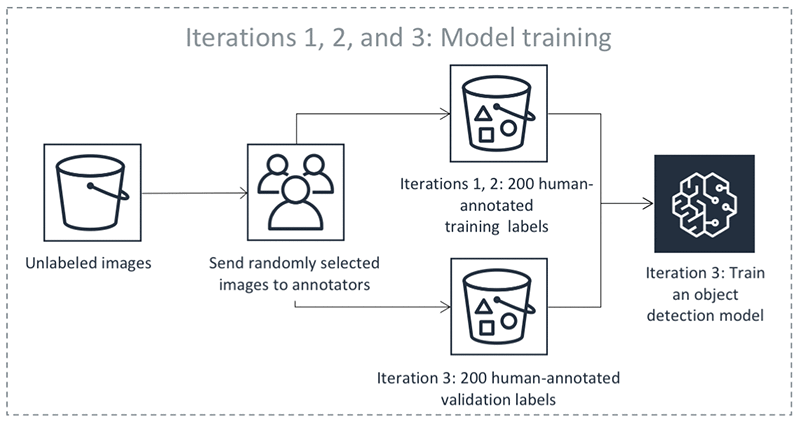
Wenn Ground Truth einen Auftrag zum automatischen Daten-Labeling startet, wählt das System eine zufällige Stichprobe von Eingabedatenobjekten aus und sendet sie an menschliche Mitarbeiter. Wenn mehr als 10 % dieser Datenobjekte ausfallen, schlägt der Kennzeichnungsauftrag fehl. Wenn der Kennzeichnungsauftrag fehlschlägt, überprüfen Sie nicht nur alle Fehlermeldungen, die Ground Truth zurückgibt, sondern überprüfen Sie auch, ob Ihre Eingabedaten auf der Worker-Benutzeroberfläche korrekt angezeigt werden, die Anweisungen klar sind und ob Sie Workern genügend Zeit gegeben haben, um Aufgaben zu erledigen.
-
Wenn die beschrifteten Daten zurückgegeben werden, werden sie zur Erstellung eines Trainingssatzes und eines Validierungssatzes verwendet. Ground Truth trainiert und überprüft anhand dieser Datensätze das für die automatische Kennzeichnung verwendete Modell.
-
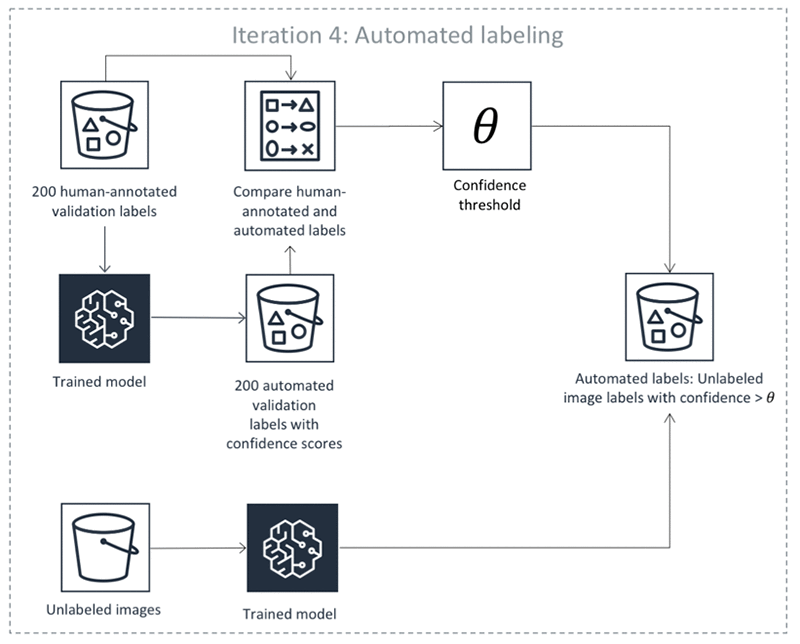
Ground Truth führt einen Batch-Transformationsauftrag aus, wobei das validierte Modell zur Inferenz für die Validierungsdaten verwendet wird. Die Batch-Inferenz erzeugt eine Konfidenzbewertung und Qualitätsmetrik für jedes Objekt in den Validierungsdaten.
-
Das automatische Labeling erstellt anhand dieser Qualitätsmetriken und Konfidenzbewertungen einen Schwellenwert für Konfidenzbewertungen, mit dem hochwertige Kennzeichnungen gewährleistet werden.
-
Ground Truth führt einen Batch-Transformationsauftrag für die nicht gekennzeichneten Daten im Datensatz aus, wobei dasselbe validierte Modell für die Inferenz verwendet wird. Dies führt zu einem Konfidenzwert für jedes Objekt.
-
Die automatische Labeling-Komponente in Ground Truth bestimmt, ob der in Schritt 5 für jedes Objekt erstellte Konfidenzwert den in Schritt 4 festgestellten erforderlichen Schwellenwert erfüllt. Wenn der Konfidenzwert den Schwellenwert erfüllt, überschreitet die erwartete Qualität des automatischen Labeling den angeforderten Genauigkeitsgrad und dieses Objekt wird als automatisch gekennzeichnet angesehen.
-
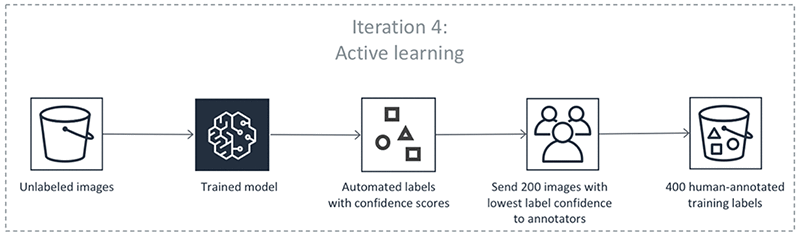
In Schritt 6 wird ein Datensatz mit nicht gekennzeichneten Daten mit Konfidenzwerten erstellt. Ground Truth wählt Datenpunkte mit niedrigen Konfidenzwerten aus diesem Datensatz aus und sendet sie an menschliche Mitarbeiter.
-
Ground Truth verwendet die vorhandenen durch Menschen gekennzeichneten Daten und diese zusätzlichen kennzeichneten Daten von menschlichen Mitarbeitern, um das Modell zu aktualisieren.
-
Der Vorgang wird wiederholt, bis der Datensatz vollständig gekennzeichnet ist oder bis eine andere Stoppbedingung erfüllt ist. Das automatische Labeling wird beispielsweise gestoppt, wenn Ihr Budget für Anmerkungen durch Menschen erreicht ist.
Die vorherigen Schritte erfolgen in einer Schleife. Wählen Sie jede Registerkarte in der folgenden Tabelle aus, um ein Beispiel für die Prozesse anzuzeigen, die in jeder Iteration für einen automatisierten Kennzeichnungsauftrag zur Objekterkennung ablaufen. Die Anzahl der in einem bestimmten Schritt in diesen Bildern verwendeten Datenobjekte (z. B. 200) gilt speziell für dieses Beispiel. Wenn weniger als 5.000 Objekte gekennzeichnet werden müssen, entspricht die Größe des Validierungssatzes 20 % des gesamten Datensatzes. Wenn Ihr Eingabedatensatz mehr als 5.000 Objekte enthält, entspricht die Größe des Validierungssatzes 10 % des gesamten Datensatzes. Sie können die Anzahl der pro aktiver Lerniteration gesammelten menschlichen Labels kontrollieren, indem Sie den Wert für ändern, MaxConcurrentTaskCountwenn Sie die Operation verwenden. API CreateLabelingJob Dieser Wert wird auf 1.000 festgelegt, wenn Sie einen Kennzeichnungsauftrag mit der Konsole erstellen. Im Workflow für aktives Lernen, der auf der Registerkarte Aktives Lernen dargestellt ist, ist dieser Wert auf 200 festgelegt.
Genauigkeit automatisierter Etiketten
Die Definition für Genauigkeit hängt vom integrierten Aufgabentyp ab, den Sie beim automatisierten Labeling verwenden. Für alle Aufgabentypen sind diese Genauigkeitsanforderungen von Ground Truth im Voraus festgelegt und können nicht manuell konfiguriert werden.
-
Für die Bildklassifizierung und Textklassifizierung verwendet Ground Truth Logik, um ein Konfidenzniveau für die Kennzeichnungsvoraussage zu ermitteln, das einer Kennzeichnungsgenauigkeit von mindestens 95 % entspricht. Dies bedeutet, dass Ground Truth erwartet, dass die Genauigkeit der automatisierten Kennzeichnungen im Vergleich zu den Kennzeichnungen, die menschliche Mitarbeiter für diese Beispiele bereitstellen würden, mindestens 95 % beträgt.
-
Bei Begrenzungsrahmen liegt der erwartete Mittelwert für Schnittmenge über Vereinigungsmenge, Intersection over Union (IoU)
der automatisch gekennzeichneten Bilder bei 0,6. Um den Mittelwert für IoU zu ermitteln, berechnet Ground Truth den mittleren IoU aller vorhergesagten und verpassten Rahmen im Bild für jede Klasse und berechnet dann den Durchschnitt dieser Werte für alle Klassen. -
Für die semantische Segmentierung beträgt der erwartete Mittelwert für IoU der automatisch beschrifteten Bilder 0,7. Um den Mittelwert für IoU zu ermitteln, verwendet Ground Truth den Mittelwert der IoU-Werte aller Klassen im Bild (mit Ausnahme des Hintergrunds).
Bei jeder Iteration des aktiven Lernens (Schritte 3–6 in der obigen Liste) wird der Konfidenzschwellenwert mithilfe des von Menschen mit Anmerkungen versehenen Validierungssatzes ermittelt, sodass die erwartete Genauigkeit der automatisch gekennzeichneten Objekte bestimmte vordefinierte Genauigkeitsanforderungen erfüllt.
Erstellen Sie einen automatisierten Job zur Datenbeschriftung (Konsole)
Gehen Sie wie folgt vor, um einen Labeling-Job zu erstellen, der automatisiertes Labeling in der SageMaker Konsole verwendet.
So erstellen Sie einen Auftrag des automatischen Daten-Labeling (Konsole)
-
Öffnen Sie den Bereich Ground Truth Labeling-Jobs in der SageMaker Konsole:https://console.aws.amazon.com/sagemaker/groundtruth
. -
Führen Sie nach der Anleitung unter Erstellen eines Kennzeichnungsauftrags (Konsole) die Schritte für Job overview (Auftragsübersicht) und Task type (Aufgabentyp) durch. Beachten Sie, dass das automatische Labeling für benutzerdefinierte Aufgabentypen nicht unterstützt wird.
-
Wählen Sie unter Workers (Arbeitnehmer) den Typ der Arbeitskräfte aus.
-
Wählen Sie im selben Bereich Enable automated data labeling (Automatisches Daten-Labeling aktivieren) aus.
-
Erstellen Sie Konfigurieren Sie das Bounding Box Tool als Leitfaden Anweisungen für Mitarbeiter im Abschnitt
Task TypeKennzeichnungswerkzeug. Wenn Sie beispielsweise Semantische Segmentierung als Kennzeichnungsauftragstyp ausgewählt haben, wird dieser Abschnitt als Kennzeichnungs-Tool für die semantische Segmentierung bezeichnet. -
Um eine Vorschau Ihrer Anweisungen für Worker und Ihres Dashboards anzuzeigen, wählen Sie Preview (Vorschau).
-
Wählen Sie Create (Erstellen) aus. Dadurch wird Ihr Kennzeichnungsauftrag und der automatische Kennzeichnungsvorgang erstellt und gestartet.
Sie können sehen, dass Ihr Labeling-Job im Bereich Labeling-Jobs der SageMaker Konsole angezeigt wird. Die Ausgabedaten werden in dem Amazon-S3-Bucket angezeigt, den Sie beim Erstellen des Kennzeichnungsauftrags angegeben haben. Weitere Hinweise zum Format und der Dateistruktur der Ausgabedaten von Kennzeichnungsaufträgen finden Sie unter Ausgabedaten des Jobs beschriften.
Erstellen Sie einen automatisierten Datenbeschriftungsauftrag (API)
Um einen automatisierten Datenbeschriftungsauftrag mit dem zu erstellen SageMaker API, verwenden Sie den LabelingJobAlgorithmsConfigParameter des CreateLabelingJobVorgangs. Informationen zum Starten eines Kennzeichnungsauftrags mithilfe der Operation CreateLabelingJob finden Sie unter Erstellen eines Kennzeichnungsauftrags (API).
Geben Sie im LabelingJobAlgorithmSpecificationArnParameter den Amazon-Ressourcennamen (ARN) des Algorithmus an, den Sie für die automatische Datenbeschriftung verwenden. Wählen Sie einen der vier in Ground Truth integrierten Algorithmen aus, die für die automatische Kennzeichnung unterstützt werden:
Wenn ein automatisierter Datenbeschriftungsjob abgeschlossen ist, gibt Ground Truth das ARN Modell zurück, das es für den automatisierten Datenbeschriftungsjob verwendet hat. Verwenden Sie dieses Modell als Startmodell für ähnliche Auftragstypen mit automatischer KennzeichnungARN, indem Sie das im Zeichenkettenformat im InitialActiveLearningModelArnParameter angeben. Um das Modell abzurufenARN, verwenden Sie einen AWS Command Line Interface (AWS CLI) -Befehl, der dem folgenden ähnelt.
# Fetch the mARN of the model trained in the final iteration of the previous labeling job.Ground Truth pretrained_model_arn = sagemaker_client.describe_labeling_job(LabelingJobName=job_name)['LabelingJobOutput']['FinalActiveLearningModelArn']
Um Daten auf dem Speichervolume zu verschlüsseln, das an die ML-Compute-Instanz (en) angehängt ist, die für die automatische Kennzeichnung verwendet werden, fügen Sie einen AWS Key Management Service (AWS KMS) -Schlüssel in den VolumeKmsKeyId Parameter ein. Informationen zu AWS KMS Schlüsseln finden Sie unter Was ist der AWS Key Management Service? im AWS Key Management Service Developer Guide.
Ein Beispiel, das den CreateLabelingJobVorgang verwendet, um einen automatisierten Datenbeschriftungsauftrag zu erstellen, finden Sie im Beispiel object_detection_tutorial im Abschnitt SageMaker Beispiele, Ground Truth Labeling-Jobs einer Notebook-Instanz. SageMaker Informationen zum Erstellen und Öffnen einer Notebook-Instance finden Sie unter Erstellen Sie eine SageMaker Amazon-Notebook-Instance. Informationen zum Zugriff auf Beispiel-Notizbücher finden Sie unter SageMaker . Rufen Sie Beispiel-Notizbücher auf
EC2Amazon-Instances, die für die automatische Datenkennzeichnung erforderlich sind
In der folgenden Tabelle sind die Amazon Elastic Compute Cloud (AmazonEC2) -Instances aufgeführt, die Sie für die automatische Datenkennzeichnung für Trainings- und Batch-Inferenzjobs benötigen.
| Auftragstyp des automatischen Daten-Labeling | Trainings-Instance-Typ | Inferenz-Instance-Typ |
|---|---|---|
|
Bildklassifizierung |
ml.p3.2xlarge* |
ml.c5.xlarge |
|
Objekterkennung (Begrenzungsrahmen) |
ml.p3.2xlarge* |
ml.c5.4xlarge |
|
Textklassifizierung |
ml.c5.2xlarge |
ml.m4.xlarge |
|
Semantische Segmentierung |
ml.p3.2xlarge* |
ml.p3.2xlarge* |
* In der Region Asien-Pazifik (Mumbai) (ap-south-1) verwenden Sie stattdessen ml.p2.8xlarge.
Ground Truth verwaltet die Instances, die Sie für Aufträge des automatischen Daten-Labeling verwenden. Es erstellt, konfiguriert und beendet die Instances wie für die Ausführung Ihres Auftrags erforderlich. Diese Instances werden nicht in Ihrem EC2 Amazon-Instance-Dashboard angezeigt.
Einrichten eines Workflows für aktives Lernen mit Ihrem eigenen Modell ein
Sie können einen Workflow für aktives Lernen mit Ihrem eigenen Algorithmus erstellen, um Trainings und Interferenzen in diesem Workflow durchzuführen, um Ihre Daten automatisch zu kennzeichnen. Das Notizbuch bring_your_own_model_for_sagemaker_labeling_workflows_with_active_learning.ipynb demonstriert dies mithilfe des integrierten Algorithmus. SageMaker BlazingText Dieses Notizbuch bietet einen Stapel, mit dem Sie diesen Workflow ausführen können. AWS CloudFormation AWS Step Functions Sie finden das Notizbuch und die unterstützenden Dateien in diesem GitHub Repository
Sie finden dieses Notizbuch auch im SageMaker Examples Repository. Unter Beispielnotizbücher verwenden erfahren Sie, wie Sie ein SageMaker Amazon-Beispielnotizbuch finden.
