Für ähnliche Funktionen wie Amazon Timestream für sollten Sie Amazon Timestream for LiveAnalytics InfluxDB in Betracht ziehen. Es bietet eine vereinfachte Datenaufnahme und Antwortzeiten im einstelligen Millisekundenbereich für Analysen in Echtzeit. Erfahren Sie hier mehr.
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Architektur
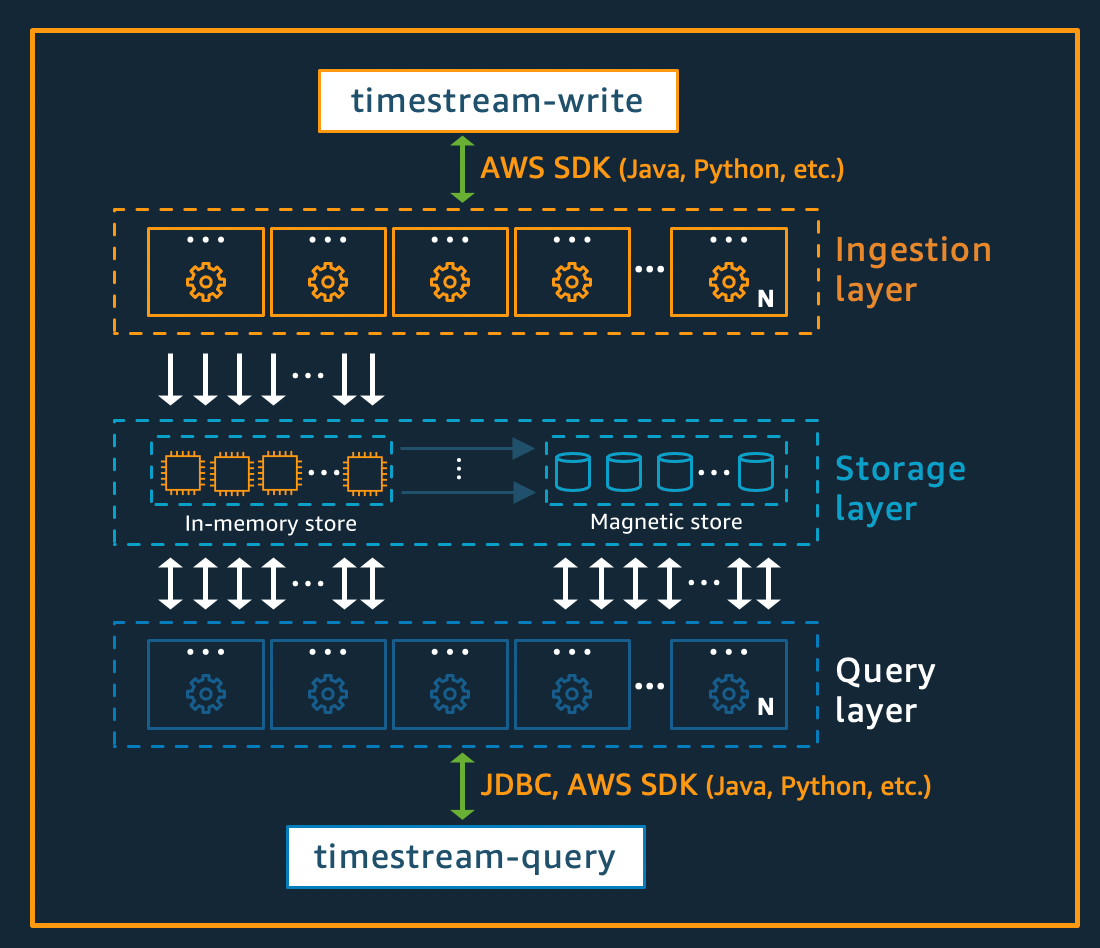
Amazon Timestream for Live Analytics wurde von Grund auf für die Erfassung, Speicherung und Verarbeitung von Zeitreihendaten in großem Umfang konzipiert. Die serverlose Architektur unterstützt vollständig entkoppelte Datenaufnahme-, Speicher- und Abfrageverarbeitungssysteme, die unabhängig voneinander skaliert werden können. Dieses Design vereinfacht jedes Subsystem und macht es einfacher, unerschütterliche Zuverlässigkeit zu erreichen, Skalierungsengpässe zu beseitigen und die Wahrscheinlichkeit korrelierter Systemausfälle zu verringern. Jeder dieser Faktoren wird mit der Skalierung des Systems immer wichtiger.
Schreiben Sie Architektur
Beim Schreiben von Zeitreihendaten leitet Amazon Timestream for Live Analytics Schreibvorgänge für eine Tabelle oder Partition an eine fehlertolerante Speicherinstanz weiter, die Datenschreibvorgänge mit hohem Durchsatz verarbeitet. Der Speicherspeicher wiederum sorgt für Stabilität in einem separaten Speichersystem, das die Daten in drei Availability Zones repliziert (). AZs Die Replikation basiert auf einem Quorum, sodass der Verlust von Knoten oder einer gesamten AZ die Schreibverfügbarkeit nicht beeinträchtigt. Fast in Echtzeit werden andere In-Memory-Speicherknoten mit den Daten synchronisiert, um Abfragen zu bearbeiten. Die Reader-Replikatknoten erstrecken sich AZs ebenfalls über mehrere Knoten, um eine hohe Leseverfügbarkeit zu gewährleisten.
Timestream for Live Analytics unterstützt das direkte Schreiben von Daten in den Magnetspeicher für Anwendungen, die spät eintreffende Daten mit geringerem Durchsatz generieren. Bei spät eintreffenden Daten handelt es sich um Daten, deren Zeitstempel vor der aktuellen Uhrzeit liegt. Ähnlich wie bei Schreibvorgängen mit hohem Durchsatz im Speicherspeicher werden die in den Magnetspeicher geschriebenen Daten dreifach repliziert, AZs und die Replikation erfolgt quorumbasiert.
Unabhängig davon, ob Daten in den Speicher oder in den Magnetspeicher geschrieben werden, indexiert und partitioniert Timestream for Live Analytics Daten automatisch, bevor sie in den Speicher geschrieben werden. Eine einzelne Timestream for Live Analytics-Tabelle kann Hunderte, Tausende oder sogar Millionen von Partitionen enthalten. Einzelne Partitionen kommunizieren nicht direkt miteinander und teilen keine Daten (Shared-Nothing-Architektur). Stattdessen wird die Partitionierung einer Tabelle über einen hochverfügbaren Dienst zur Partitionsverfolgung und -indizierung nachverfolgt. Dies bietet eine weitere Trennung von Problemen, die speziell darauf ausgelegt sind, die Auswirkungen von Systemausfällen zu minimieren und die Wahrscheinlichkeit korrelierter Ausfälle erheblich zu verringern.
Speicherarchitektur
Wenn Daten in Timestream for Live Analytics gespeichert werden, werden die Daten anhand von Kontextattributen, die zusammen mit den Daten geschrieben werden, sowohl in zeitlicher Reihenfolge als auch im Zeitverlauf organisiert. Für die massive Skalierung eines Zeitreihensystems ist es wichtig, über ein Partitionierungsschema zu verfügen, das neben der Zeit auch „Raum“ unterteilt. Das liegt daran, dass die meisten Zeitreihendaten zur oder um die aktuelle Uhrzeit geschrieben werden. Daher eignet sich die Partitionierung nach Zeit allein nicht gut zur Verteilung des Schreibverkehrs oder zur effektiven Bereinigung von Daten zur Abfragezeit. Dies ist wichtig für die Verarbeitung extrem großer Zeitreihen und hat es Timestream for Live Analytics ermöglicht, serverlos um Größenordnungen höher zu skalieren als die anderen führenden Systeme, die es heute gibt. Die resultierenden Partitionen werden als „Kacheln“ bezeichnet, weil sie Teilungen eines zweidimensionalen Raums darstellen (die so konzipiert sind, dass sie eine ähnliche Größe haben). Timestream for Live Analytics-Tabellen bestehen zunächst aus einer einzelnen Partition (Kachel) und werden dann je nach Durchsatz in die räumliche Dimension aufgeteilt. Wenn Kacheln eine bestimmte Größe erreichen, werden sie dann in der Zeitdimension aufgeteilt, um bei wachsender Datengröße eine bessere Lese-Parallelität zu erreichen.
Timestream for Live Analytics wurde entwickelt, um den Lebenszyklus von Zeitreihendaten automatisch zu verwalten. Timestream for Live Analytics bietet zwei Datenspeicher — einen In-Memory-Speicher und einen kostengünstigen Magnetspeicher. Es unterstützt auch die Konfiguration von Richtlinien auf Tabellenebene, um Daten automatisch zwischen Speichern zu übertragen. Eingehende Schreibvorgänge mit hohem Durchsatz landen im Speicherspeicher, wo die Daten für Schreibvorgänge optimiert sind. Das Gleiche gilt für Lesevorgänge, die etwa zur aktuellen Zeit ausgeführt werden, um Abfragen vom Typ Dashboard und Warnmeldungen zu starten. Wenn der Hauptzeitrahmen für Schreib-, Alarm- und Dashboard-Anforderungen abgelaufen ist, können die Daten automatisch vom Speicherspeicher zum Magnetspeicher fließen, um die Kosten zu optimieren. Timestream for Live Analytics ermöglicht zu diesem Zweck die Festlegung einer Datenaufbewahrungsrichtlinie für den Speicherspeicher. Datenschreibvorgänge für spät eintreffende Daten werden direkt in den Magnetspeicher geschrieben.
Sobald die Daten im Magnetspeicher verfügbar sind (aufgrund des Ablaufs der Aufbewahrungsfrist des Speicherspeichers oder aufgrund direkter Schreibvorgänge in den Magnetspeicher), werden sie in ein Format umorganisiert, das für das Lesen großer Datenmengen in hohem Maße optimiert ist. Der Magnetspeicher verfügt außerdem über eine Datenaufbewahrungsrichtlinie, die konfiguriert werden kann, wenn es einen bestimmten Zeitraum gibt, ab dem die Daten nicht mehr nützlich sind. Wenn die Daten den für die Aufbewahrungsrichtlinie für Magnetspeicher definierten Zeitraum überschreiten, werden sie automatisch entfernt. Daher erfolgt das Datenlebenszyklusmanagement bei Timestream for Live Analytics, abgesehen von einigen Konfigurationen, nahtlos hinter den Kulissen.
Architektur abfragen
Timestream for Live Analytics-Abfragen werden in einer SQL-Grammatik ausgedrückt, die Erweiterungen für zeitreihenspezifische Unterstützung (zeitreihenspezifische Datentypen und Funktionen) bietet, sodass Entwickler, die bereits mit SQL vertraut sind, die Lernkurve leicht erlernen können. Abfragen werden dann von einer adaptiven, verteilten Abfrage-Engine verarbeitet, die Metadaten aus dem Tile-Tracking- und Indexierungsservice verwendet, um zum Zeitpunkt der Ausgabe der Abfrage nahtlos auf Daten aus verschiedenen Datenspeichern zuzugreifen und diese zu kombinieren. Dies sorgt für ein Erlebnis, das bei den Kunden gut ankommt, da es viele der Rube-Goldberg-Komplexitäten in einer einfachen und vertrauten Datenbankabstraktion zusammenfasst.
Abfragen werden von einer eigenen Flotte von Mitarbeitern ausgeführt, wobei die Anzahl der Mitarbeiter, die für die Ausführung einer bestimmten Abfrage angeworben werden, von der Komplexität der Abfrage und der Datengröße abhängt. Die Leistung komplexer Abfragen über große Datenmengen wird durch massive Parallelität erreicht, und zwar sowohl bei der Abfragelaufzeitflotte als auch bei den Speicherflotten des Systems. Die Fähigkeit, riesige Datenmengen schnell und effizient zu analysieren, ist eine der größten Stärken von Timestream for Live Analytics. Eine einzelne Abfrage, die Terabyte oder sogar Petabyte an Daten umfasst, kann dazu führen, dass Tausende von Computern gleichzeitig daran arbeiten.
Zellulare Architektur
Um sicherzustellen, dass Timestream for Live Analytics eine praktisch unendliche Skalierbarkeit für Ihre Anwendungen bietet und gleichzeitig eine Verfügbarkeit von 99,99% gewährleistet, wurde das System auch unter Verwendung einer Mobilfunkarchitektur konzipiert. Anstatt das System als Ganzes zu skalieren, segmentiert Timestream for Live Analytics in mehrere kleinere Kopien von sich selbst, die als Zellen bezeichnet werden. Auf diese Weise können Zellen in vollem Umfang getestet werden, und es wird verhindert, dass ein Systemproblem in einer Zelle die Aktivität anderer Zellen in einer bestimmten Region beeinträchtigt. Timestream for Live Analytics ist zwar so konzipiert, dass es mehrere Zellen pro Region unterstützt, aber stellen Sie sich das folgende fiktive Szenario vor, in dem sich zwei Zellen in einer Region befinden.

In dem oben dargestellten Szenario werden die Datenaufnahme- und Abfrageanforderungen zunächst vom Erkennungsendpunkt für die Datenaufnahme bzw. Abfrage verarbeitet. Anschließend identifiziert der Erkennungsendpunkt die Zelle, die die Kundendaten enthält, und leitet die Anfrage an den entsprechenden Aufnahme- oder Abfrageendpunkt für diese Zelle weiter. Wenn Sie den verwenden SDKs, werden diese Endpunktverwaltungsaufgaben transparent für Sie erledigt.
Anmerkung
Wenn Sie VPC-Endpunkte mit Timestream for Live Analytics verwenden oder direkt auf REST-API-Operationen für Timestream for Live Analytics zugreifen, müssen Sie direkt mit den Mobilfunkendpunkten interagieren. Anleitungen dazu finden Sie unter VPC-Endpunkte für Anweisungen zum Einrichten von VPC-Endpunkten und unter Endpoint Discovery Pattern für Anweisungen zum direkten Aufrufen der REST-API-Operationen.
