Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
UNLOADKonzepte
Syntax
UNLOAD (SELECT statement) TO 's3://bucket-name/folder' WITH ( option = expression [, ...] )
wo option ist
{ partitioned_by = ARRAY[ col_name[,…] ] | format = [ '{ CSV | PARQUET }' ] | compression = [ '{ GZIP | NONE }' ] | encryption = [ '{ SSE_KMS | SSE_S3 }' ] | kms_key = '<string>' | field_delimiter ='<character>' | escaped_by = '<character>' | include_header = ['{true, false}'] | max_file_size = '<value>' | }
Parameter
- SELECTAussage
-
Die Abfrageanweisung, die verwendet wird, um Daten aus einem oder mehreren Timestreams für LiveAnalytics Tabellen auszuwählen und abzurufen.
(SELECT column 1, column 2, column 3 from database.table where measure_name = "ABC" and timestamp between ago (1d) and now() ) - TO-Klausel
-
TO 's3://bucket-name/folder'or
TO 's3://access-point-alias/folder'Die
TOKlausel in derUNLOADAnweisung gibt das Ziel für die Ausgabe der Abfrageergebnisse an. Sie müssen den vollständigen Pfad angeben, einschließlich entweder des Amazon S3-Bucket-Namens oder Amazon S3 access-point-alias mit dem Speicherort des Ordners auf Amazon S3, in den Timestream for die LiveAnalytics Ausgabedateiobjekte schreibt. Der S3-Bucket sollte demselben Konto gehören und sich in derselben Region befinden. Zusätzlich zum Abfrageergebnissatz LiveAnalytics schreibt Timestream for die Manifest- und Metadatendateien in den angegebenen Zielordner. - PARTITIONED_BY-Klausel
-
partitioned_by = ARRAY [col_name[,…] , (default: none)Die
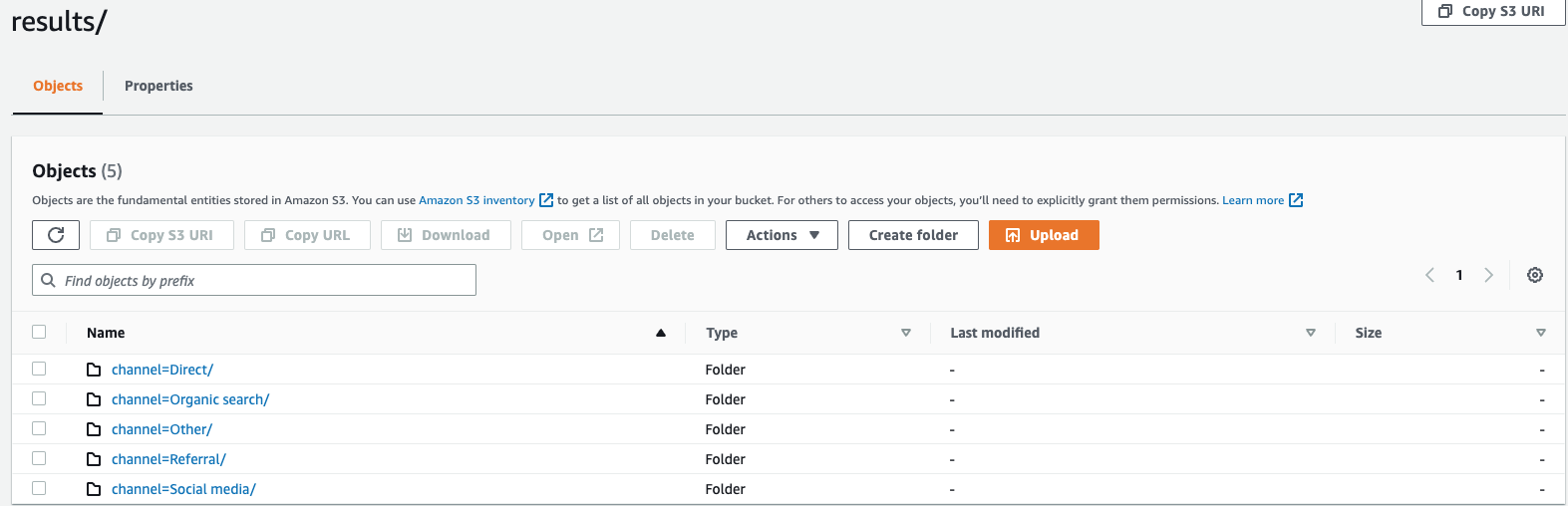
partitioned_byKlausel wird in Abfragen verwendet, um Daten auf granularer Ebene zu gruppieren und zu analysieren. Wenn Sie Ihre Abfrageergebnisse in den S3-Bucket exportieren, können Sie wählen, ob Sie die Daten auf der Grundlage einer oder mehrerer Spalten in der Auswahlabfrage partitionieren möchten. Bei der Partitionierung der Daten werden die exportierten Daten basierend auf der Partitionsspalte in Teilmengen unterteilt, und jede Teilmenge wird in einem separaten Ordner gespeichert. Innerhalb des Ergebnisordners, der Ihre exportierten Daten enthält, wird automatisch ein Unterordner erstelltfolder/results/partition column = partition value/. Beachten Sie jedoch, dass partitionierte Spalten nicht in der Ausgabedatei enthalten sind.partitioned_byist keine obligatorische Klausel in der Syntax. Wenn Sie die Daten ohne Partitionierung exportieren möchten, können Sie die Klausel in der Syntax ausschließen.Angenommen, Sie überwachen die Clickstream-Daten Ihrer Website und haben 5 Verkehrskanäle
direct, nämlich,Social MediaOrganic SearchOther, und.ReferralBeim Exportieren der Daten können Sie wählen, ob Sie die Daten mithilfe der SpalteChannelpartitionieren möchten. In Ihrem Datenordner befinden sich fünf Ordner mit jeweils ihrem jeweiligen Kanalnamen.s3://bucketname/results/channel=Social Media/.In diesem Ordner finden Sie beispielsweise die Daten aller Kunden, die über denSocial MediaKanal auf Ihre Website gelangt sind.s3://bucketname/resultsIn ähnlicher Weise werden Sie andere Ordner für die verbleibenden Kanäle haben.Exportierte Daten, partitioniert nach Kanalspalten
- FORMAT
-
format = [ '{ CSV | PARQUET }' , default: CSVDie Schlüsselwörter zur Angabe des Formats der Abfrageergebnisse, die in Ihren S3-Bucket geschrieben werden. Sie können die Daten entweder als kommagetrennten Wert (CSV) mit einem Komma (,) als Standardtrennzeichen oder im Apache Parquet-Format, einem effizienten offenen spaltenbasierten Speicherformat für Analysen, exportieren.
- COMPRESSION
-
compression = [ '{ GZIP | NONE }' ], default: GZIPSie können die exportierten Daten mithilfe des Komprimierungsalgorithmus komprimieren GZIP oder sie dekomprimieren lassen, indem Sie die Option angeben.
NONE - ENCRYPTION
-
encryption = [ '{ SSE_KMS | SSE_S3 }' ], default: SSE_S3Die Ausgabedateien auf Amazon S3 werden mit der von Ihnen ausgewählten Verschlüsselungsoption verschlüsselt. Zusätzlich zu Ihren Daten werden auch die Manifest- und Metadatendateien auf der Grundlage der von Ihnen ausgewählten Verschlüsselungsoption verschlüsselt. Wir unterstützen derzeit die SSE _S3- und SSE KMS _-Verschlüsselung. SSE_S3 ist eine serverseitige Verschlüsselung, bei der Amazon S3 die Daten mit der 256-Bit-Verschlüsselung des Advanced Encryption Standard () verschlüsselt. AES SSE_ KMS ist eine serverseitige Verschlüsselung zur Verschlüsselung von Daten mit vom Kunden verwalteten Schlüsseln.
- KMS_KEY
-
kms_key = '<string>'KMSDer Schlüssel ist ein vom Kunden definierter Schlüssel zur Verschlüsselung exportierter Abfrageergebnisse. KMSDer Schlüssel wird sicher vom AWS Key Management Service (AWS KMS) verwaltet und zum Verschlüsseln von Datendateien auf Amazon S3 verwendet.
- FIELD_DELIMITER
-
field_delimiter ='<character>' , default: (,)Beim Exportieren der Daten im CSV Format gibt dieses Feld ein einzelnes ASCII Zeichen an, das zur Trennung von Feldern in der Ausgabedatei verwendet wird, z. B. ein senkrechter Strich (|), ein Komma (,) oder ein Tabulatorzeichen (/t). Das Standardtrennzeichen für CSV Dateien ist ein Komma. Wenn ein Wert in Ihren Daten das gewählte Trennzeichen enthält, wird das Trennzeichen mit einem Anführungszeichen in Anführungszeichen gesetzt. Wenn der Wert in Ihren Daten beispielsweise Folgendes enthält
Time,stream, wird dieser Wert wie in den exportierten Daten"Time,stream"in Anführungszeichen gesetzt. Das von Timestream für verwendete Anführungszeichen LiveAnalytics sind doppelte Anführungszeichen („).Vermeiden Sie es, das Wagenrücklaufzeichen (ASCII13
0D, Hexadezimalzahl, Text '\ r') oder das Zeilenumbruchzeichen (ASCII10, Hexadezimalzahl 0A, Text '\n') als 'anzugeben,FIELD_DELIMITERwenn Sie Header in die aufnehmen möchtenCSV, da dies viele Parser daran hindert, die Header in der resultierenden Ausgabe korrekt zu analysieren. CSV - ESCAPED_VON
-
escaped_by = '<character>', default: (\)Beim Exportieren der Daten im CSV Format gibt dieses Feld das Zeichen an, das in der in den S3-Bucket geschriebenen Datendatei als Escape-Zeichen behandelt werden soll. Escaping findet in den folgenden Szenarien statt:
-
Wenn der Wert selbst das Anführungszeichen („) enthält, wird er mit einem Escape-Zeichen maskiert. Wenn der Wert beispielsweise lautet
Time"stream, wobei (\) das konfigurierte Escape-Zeichen ist, dann wird er als maskiertTime\"stream. -
Wenn der Wert das konfigurierte Escape-Zeichen enthält, wird es maskiert. Wenn der Wert beispielsweise ist
Time\stream, wird er als maskiertTime\\stream.
Anmerkung
Wenn die exportierte Ausgabe komplexe Datentypen wie Arrays, Zeilen oder Zeitreihen enthält, wird sie als Zeichenfolge serialisiert. JSON Im Folgenden sehen Sie ein Beispiel.
Datentyp Tatsächlicher Wert Wie der Wert im CSV Format [serialisierte JSON Zeichenfolge] maskiert wird Array
[ 23,24,25 ]"[23,24,25]"Zeile
( x=23.0, y=hello )"{\"x\":23.0,\"y\":\"hello\"}"Zeitreihen
[ ( time=1970-01-01 00:00:00.000000010, value=100.0 ),( time=1970-01-01 00:00:00.000000012, value=120.0 ) ]"[{\"time\":\"1970-01-01 00:00:00.000000010Z\",\"value\":100.0},{\"time\":\"1970-01-01 00:00:00.000000012Z\",\"value\":120.0}]" -
- INCLUDE_HEADER
-
include_header = 'true' , default: 'false'Wenn Sie die Daten im CSV Format exportieren, können Sie in diesem Feld Spaltennamen als erste Zeile der exportierten CSV Datendateien angeben.
Die akzeptierten Werte sind „wahr“ und „falsch“ und der Standardwert ist „falsch“. Optionen zur Texttransformation wie
escaped_byundfield_delimitergelten auch für Überschriften.Anmerkung
Beim Einbeziehen von Kopfzeilen ist es wichtig, dass Sie kein Wagenrücklaufzeichen (ASCII13, Hex 0D, Text '\ r') oder ein Zeilenumbruchzeichen (ASCII10, Hex 0A, Text '\n') als 'auswählen
FIELD_DELIMITER, da dies viele Parser daran hindert, die Header in der resultierenden Ausgabe korrekt zu analysieren. CSV - MAX_FILE_SIZE
-
max_file_size = 'X[MB|GB]' , default: '78GB'Dieses Feld gibt die maximale Größe der Dateien an, die die
UNLOADAnweisung in Amazon S3 erstellt. DieUNLOADAnweisung kann mehrere Dateien erstellen, aber die maximale Größe jeder in Amazon S3 geschriebenen Datei entspricht ungefähr der in diesem Feld angegebenen Größe.Der Wert des Felds muss zwischen 16 MB und einschließlich 78 GB liegen. Sie können ihn als Ganzzahl wie
12GBoder in Dezimalzahlen wie0.5GBoder angeben.24.7MBDer Standardwert ist 78 GB.Die tatsächliche Dateigröße wird beim Schreiben der Datei geschätzt, sodass die tatsächliche Maximalgröße möglicherweise nicht genau der von Ihnen angegebenen Zahl entspricht.
Was wird in meinen S3-Bucket geschrieben?
Für jede erfolgreich ausgeführte UNLOAD Abfrage LiveAnalytics schreibt Timestream for Ihre Abfrageergebnisse, die Metadatendatei und die Manifestdatei in den S3-Bucket. Wenn Sie die Daten partitioniert haben, befinden sich alle Partitionsordner im Ergebnisordner. Die Manifestdatei enthält eine Liste der Dateien, die mit dem UNLOAD Befehl geschrieben wurden. Die Metadatendatei enthält Informationen, die die Merkmale, Eigenschaften und Attribute der geschriebenen Daten beschreiben.
Wie lautet der Name der exportierten Datei?
Der Name der exportierten Datei enthält zwei Komponenten, die erste Komponente ist die QueryID und die zweite Komponente ist eine eindeutige Kennung.
CSVDateien
S3://bucket_name/results/<queryid>_<UUID>.csv S3://bucket_name/results/<partitioncolumn>=<partitionvalue>/<queryid>_<UUID>.csv
Komprimierte CSV Datei
S3://bucket_name/results/<partitioncolumn>=<partitionvalue>/<queryid>_<UUID>.gz
Parquet-Datei
S3://bucket_name/results/<partitioncolumn>=<partitionvalue>/<queryid>_<UUID>.parquet
Metadaten und Manifestdateien
S3://bucket_name/<queryid>_<UUID>_manifest.json S3://bucket_name/<queryid>_<UUID>_metadata.json
Da die Daten im CSV Format auf Dateiebene gespeichert werden, hat die Datei beim Komprimieren der Daten beim Exportieren nach S3 die Erweiterung „.gz“. Die Daten in Parquet werden jedoch auf Spaltenebene komprimiert. Selbst wenn Sie die Daten beim Exportieren komprimieren, hat die Datei immer noch die Erweiterung.parquet.
Welche Informationen enthält jede Datei?
Manifestdatei
Die Manifestdatei enthält Informationen zur Liste der Dateien, die bei der UNLOAD Ausführung exportiert werden. Die Manifestdatei ist im bereitgestellten S3-Bucket mit einem Dateinamen verfügbar:s3://<bucket_name>/<queryid>_<UUID>_manifest.json. Die Manifestdatei enthält die URL der Dateien im Ergebnisordner, die Anzahl der Datensätze und die Größe der jeweiligen Dateien sowie die Abfrage-Metadaten (d. h. die Gesamtzahl der Byte und der Gesamtzahl der Zeilen, die für die Abfrage nach S3 exportiert wurden).
{ "result_files": [ { "url":"s3://my_timestream_unloads/ec2_metrics/AEDAGANLHLBH4OLISD3CVOZZRWPX5GV2XCXRBKCVD554N6GWPWWXBP7LSG74V2Q_1448466917_szCL4YgVYzGXj2lS.gz", "file_metadata": { "content_length_in_bytes": 32295, "row_count": 10 } }, { "url":"s3://my_timestream_unloads/ec2_metrics/AEDAGANLHLBH4OLISD3CVOZZRWPX5GV2XCXRBKCVD554N6GWPWWXBP7LSG74V2Q_1448466917_szCL4YgVYzGXj2lS.gz", "file_metadata": { "content_length_in_bytes": 62295, "row_count": 20 } }, ], "query_metadata": { "content_length_in_bytes": 94590, "total_row_count": 30, "result_format": "CSV", "result_version": "Amazon Timestream version 1.0.0" }, "author": { "name": "Amazon Timestream", "manifest_file_version": "1.0" } }
Metadaten
Die Metadatendatei enthält zusätzliche Informationen über den Datensatz, z. B. Spaltenname, Spaltentyp und Schema. <queryid>Die Metadatendatei ist im bereitgestellten S3-Bucket mit dem folgenden Dateinamen verfügbar: S3: //bucket_name/ _< >_metadata.json UUID
Es folgt ein Beispiel für eine Metadatendatei.
{ "ColumnInfo": [ { "Name": "hostname", "Type": { "ScalarType": "VARCHAR" } }, { "Name": "region", "Type": { "ScalarType": "VARCHAR" } }, { "Name": "measure_name", "Type": { "ScalarType": "VARCHAR" } }, { "Name": "cpu_utilization", "Type": { "TimeSeriesMeasureValueColumnInfo": { "Type": { "ScalarType": "DOUBLE" } } } } ], "Author": { "Name": "Amazon Timestream", "MetadataFileVersion": "1.0" } }
Die in der Metadatendatei gemeinsam genutzten Spalteninformationen haben dieselbe Struktur wie die in der API Abfrageantwort für SELECT Abfragen ColumnInfo gesendeten Informationen.
Ergebnisse
Der Ergebnisordner enthält Ihre exportierten Daten entweder im Apache Parquet- oder im Apache CSV Parquet-Format.
Beispiel
Wenn Sie eine UNLOAD Anfrage wie unten über Query einreichenAPI,
UNLOAD(SELECT user_id, ip_address, event, session_id, measure_name, time, query, quantity, product_id, channel FROM sample_clickstream.sample_shopping WHERE time BETWEEN ago(2d) AND now()) TO 's3://my_timestream_unloads/withoutpartition/' WITH ( format='CSV', compression='GZIP')
UNLOADDie Abfrageantwort wird 1 Zeile x 3 Spalten haben. Diese 3 Spalten sind:
-
Zeilen des Typs BIGINT — gibt die Anzahl der exportierten Zeilen an
-
metadataFile vom Typ VARCHAR — das ist das S3 URI der exportierten Metadatendatei
-
manifestFile vom Typ VARCHAR — das ist der S3 URI der exportierten Manifest-Datei
Sie erhalten die folgende Antwort von QueryAPI:
{ "Rows": [ { "Data": [ { "ScalarValue": "20" # No of rows in output across all files }, { "ScalarValue": "s3://my_timestream_unloads/withoutpartition/AEDAAANGH3D7FYHOBQGQQMEAISCJ45B42OWWJMOT4N6RRJICZUA7R25VYVOHJIY_<UUID>_metadata.json" #Metadata file }, { "ScalarValue": "s3://my_timestream_unloads/withoutpartition/AEDAAANGH3D7FYHOBQGQQMEAISCJ45B42OWWJMOT4N6RRJICZUA7R25VYVOHJIY_<UUID>_manifest.json" #Manifest file } ] } ], "ColumnInfo": [ { "Name": "rows", "Type": { "ScalarType": "BIGINT" } }, { "Name": "metadataFile", "Type": { "ScalarType": "VARCHAR" } }, { "Name": "manifestFile", "Type": { "ScalarType": "VARCHAR" } } ], "QueryId": "AEDAAANGH3D7FYHOBQGQQMEAISCJ45B42OWWJMOT4N6RRJICZUA7R25VYVOHJIY", "QueryStatus": { "ProgressPercentage": 100.0, "CumulativeBytesScanned": 1000, "CumulativeBytesMetered": 10000000 } }
Datentypen
Die UNLOAD Anweisung unterstützt alle Datentypen der Abfragesprache von Timestream for LiveAnalytics, die unter beschrieben sind, Unterstützte Datentypen außer time undunknown.
