Für ähnliche Funktionen wie Amazon Timestream für sollten Sie Amazon Timestream for LiveAnalytics InfluxDB in Betracht ziehen. Es bietet eine vereinfachte Datenaufnahme und Antwortzeiten im einstelligen Millisekundenbereich für Analysen in Echtzeit. Erfahren Sie hier mehr.
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Optimieren des Datenzugriffs in Amazon Timestream
Sie können die Datenzugriffsmuster in Amazon Timestream mithilfe des Timestream-Partitionierungsschemas oder der Datenorganisationstechniken optimieren.
Timestream-Partitionierungsschema
Amazon Timestream verwendet ein hoch skalierbares Partitionierungsschema, bei dem jede Timestream-Tabelle Hunderte, Tausende oder sogar Millionen unabhängiger Partitionen haben kann. Ein hochverfügbarer Dienst zur Partitionsverfolgung und Indizierung verwaltet die Partitionierung, minimiert die Auswirkungen von Ausfällen und macht das System widerstandsfähiger.
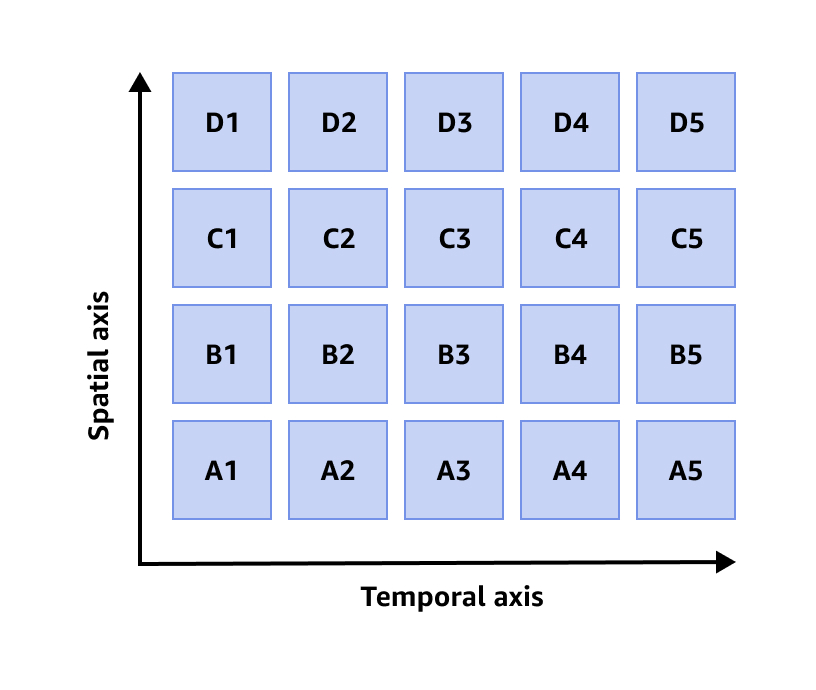
Datenorganisation
Timestream speichert jeden Datenpunkt, den es aufnimmt, in einer einzigen Partition. Wenn Sie Daten in eine Timestream-Tabelle aufnehmen, erstellt Timestream automatisch Partitionen auf der Grundlage der Zeitstempel, des Partitionsschlüssels und anderer Kontextattribute in den Daten. Neben der zeitlichen Partitionierung der Daten (zeitliche Partitionierung) partitioniert Timestream die Daten auch auf der Grundlage des ausgewählten Partitionierungsschlüssels und anderer Dimensionen (räumliche Partitionierung). Dieser Ansatz ist darauf ausgelegt, den Schreibverkehr zu verteilen und eine effektive Bereinigung von Daten für Abfragen zu ermöglichen.
Die Funktion für Abfrageerkenntnisse bietet wertvolle Einblicke in die Effizienz der Bereinigung von Abfragen, einschließlich der räumlichen Abdeckung von Abfragen und der zeitlichen Abdeckung von Abfragen.
QuerySpatialCoverage
Die QuerySpatialCoverageMetrik bietet Einblicke in die räumliche Abdeckung der ausgeführten Abfrage und in die Tabelle mit der ineffizientesten räumlichen Bereinigung. Diese Informationen können Ihnen helfen, Bereiche zu identifizieren, in denen die Partitionierungsstrategie verbessert werden kann, um die räumliche Kürzung zu verbessern. Der Wert für die QuerySpatialCoverage Metrik liegt zwischen 0 und 1. Je niedriger der Wert der Metrik ist, desto optimaler ist die Bereinigung der Abfrage auf der räumlichen Achse. Ein Wert von 0,1 gibt beispielsweise an, dass die Abfrage 10% der räumlichen Achse scannt. Ein Wert von 1 gibt an, dass die Abfrage 100% der räumlichen Achse scannt.
Beispiel Verwenden von Abfrageerkenntnissen zur Analyse der räumlichen Abdeckung einer Abfrage
Angenommen, Sie haben eine Timestream-Datenbank, in der Wetterdaten gespeichert sind. Gehen Sie davon aus, dass die Temperatur jede Stunde von Wetterstationen in verschiedenen Bundesstaaten der Vereinigte Staaten aufgezeichnet wird. Stellen Sie sich vor, Sie wählen State den benutzerdefinierten Partitionsschlüssel (CDPK), um die Daten nach Status zu partitionieren.
Angenommen, Sie führen eine Abfrage aus, um die Durchschnittstemperatur aller Wetterstationen in Kalifornien zwischen 14 Uhr und 16 Uhr an einem bestimmten Tag abzurufen. Das folgende Beispiel zeigt die Abfrage für dieses Szenario.
SELECT AVG(temperature) FROM "weather_data"."hourly_weather" WHERE time >= '2024-10-01 14:00:00' AND time < '2024-10-01 16:00:00' AND state = 'CA';
Mithilfe der Funktion Query Insights können Sie die räumliche Abdeckung der Abfrage analysieren. Stellen Sie sich vor, dass die QuerySpatialCoverage Metrik einen Wert von 0,02 zurückgibt. Das bedeutet, dass die Abfrage nur 2% der räumlichen Achse gescannt hat, was effizient ist. In diesem Fall war die Abfrage in der Lage, den räumlichen Bereich effektiv zu kürzen, indem nur Daten aus Kalifornien abgerufen und Daten aus anderen Bundesstaaten ignoriert wurden.
Im Gegenteil, wenn die QuerySpatialCoverage Metrik einen Wert von 0,8 zurückgibt, würde dies bedeuten, dass die Abfrage 80% der räumlichen Achse gescannt hat, was weniger effizient ist. Dies könnte darauf hindeuten, dass die Partitionierungsstrategie verfeinert werden muss, um die räumliche Bereinigung zu verbessern. Sie können den Partitionsschlüssel beispielsweise als Stadt oder Region statt als Bundesland auswählen. Durch die Analyse der QuerySpatialCoverage Metrik können Sie Möglichkeiten zur Optimierung Ihrer Partitionierungsstrategie und zur Verbesserung der Leistung Ihrer Abfragen identifizieren.
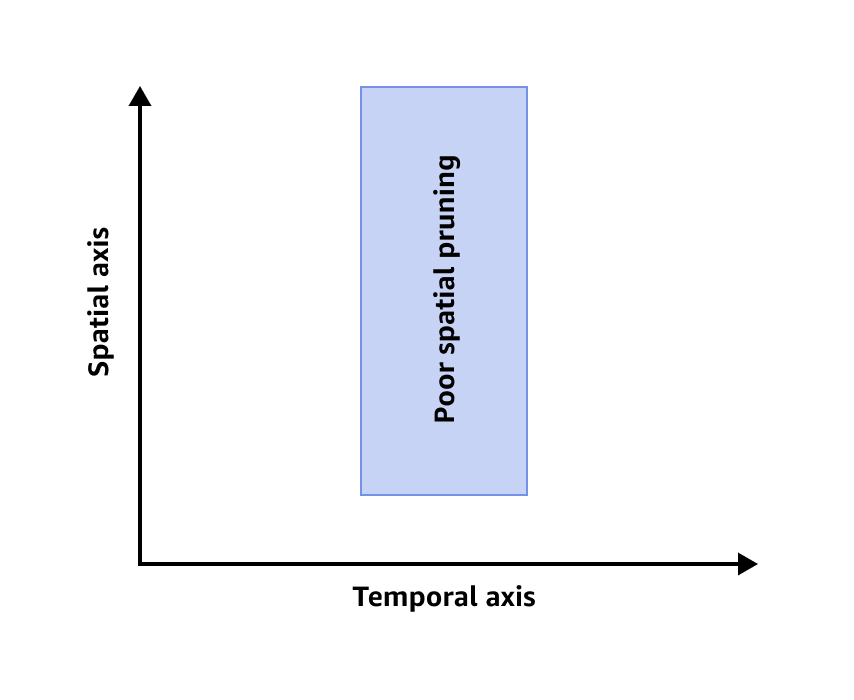
Die folgende Abbildung zeigt eine schlechte räumliche Bereinigung.
Um die Effizienz beim räumlichen Beschneiden zu verbessern, können Sie eine oder beide der folgenden Aktionen ausführen:
-
Fügen Sie
measure_nameden Standard-Partitionierungsschlüssel hinzu, oder verwenden Sie die CDPK-Prädikate in Ihrer Abfrage. -
Wenn Sie die im vorherigen Punkt genannten Attribute bereits hinzugefügt haben, entfernen Sie Funktionen rund um diese Attribute oder Klauseln, z. B.
LIKE
QueryTemporalCoverage
Die QueryTemporalCoverage Metrik bietet Einblicke in den Zeitbereich, der von der ausgeführten Abfrage gescannt wurde, einschließlich der Tabelle mit dem größten gescannten Zeitraum. Der Wert für die QueryTemporalCoverage Metrik ist der Zeitbereich, der in Nanosekunden dargestellt wird. Je niedriger der Wert dieser Metrik ist, desto optimaler ist die Abfragebereinigung im Zeitbereich. Beispielsweise ist eine Abfrage, die Daten der letzten Minuten scannt, leistungsfähiger als eine Abfrage, die den gesamten Zeitraum der Tabelle scannt.
Beispiel
Angenommen, Sie haben eine Timestream-Datenbank, in der IoT-Sensordaten gespeichert werden, wobei jede Minute Messungen von Geräten in einer Produktionsstätte durchgeführt werden. Gehen Sie davon aus, dass Sie Ihre Daten nach partitioniert haben. device_ID
Angenommen, Sie führen eine Abfrage aus, um den durchschnittlichen Sensorwert für ein bestimmtes Gerät in den letzten 30 Minuten abzurufen. Das folgende Beispiel zeigt die Abfrage für dieses Szenario.
SELECT AVG(sensor_reading) FROM "sensor_data"."factory_1" WHERE device_id = 'DEV_123' AND time >= NOW() - INTERVAL 30 MINUTE and time < NOW();
Mithilfe der Funktion für Abfrageerkenntnisse können Sie den von der Abfrage gescannten Zeitbereich analysieren. Stellen Sie sich vor, die QueryTemporalCoverage Metrik gibt einen Wert von 1800000000000 Nanosekunden (30 Minuten) zurück. Das bedeutet, dass die Abfrage nur die Daten der letzten 30 Minuten gescannt hat, was ein relativ enger Zeitbereich ist. Dies ist ein gutes Zeichen, da es darauf hinweist, dass die Abfrage die zeitliche Partitionierung effektiv bereinigen konnte und nur die angeforderten Daten abgerufen hat.
Im Gegenteil, wenn die QueryTemporalCoverage Metrik einen Wert von 1 Jahr in Nanosekunden zurückgibt, bedeutet dies, dass die Abfrage einen Zeitraum von einem Jahr in der Tabelle gescannt hat, was weniger effizient ist. Dies könnte darauf hindeuten, dass die Abfrage nicht für die zeitliche Bereinigung optimiert ist, und Sie könnten sie verbessern, indem Sie Zeitfilter hinzufügen.
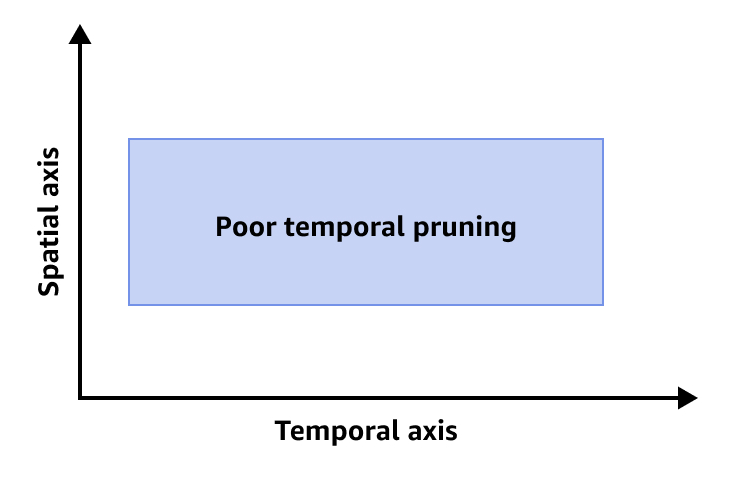
Die folgende Abbildung zeigt ein schlechtes zeitliches Beschneiden.
Um den zeitlichen Schnitt zu verbessern, empfehlen wir Ihnen, einen oder alle der folgenden Schritte durchzuführen:
-
Fügen Sie der Abfrage die fehlenden Zeitprädikate hinzu und stellen Sie sicher, dass die Zeitprädikate das gewünschte Zeitfenster bereinigen.
-
Entfernen Sie Funktionen wie etwa
MAX()Zeitprädikate. -
Fügen Sie allen Unterabfragen Zeitprädikate hinzu. Dies ist wichtig, wenn Ihre Unterabfragen große Tabellen verknüpfen oder komplexe Operationen ausführen.
