Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Schwärzen von PII in Ihrem Batch-Job
Wenn Sie während eines Batch-Transkriptionsvorgangs personenbezogene Daten (PII) aus einem Transkript redigieren, wird jede identifizierte Instanz von PII durch den Haupttext Ihres [PII] Transkripts Amazon Transcribe ersetzt. In dem Teil der Transkriptionsausgabe können Sie sich auch die Art der personenbezogenen Daten ansehen, die geschwärzt wurden. word-for-word Ein Beispiel für die Ausgabe finden Sie unter Beispiel für eine geschwärzte Ausgabe (Batch).
Die Schwärzung mit Batch-Transkriptionen ist in US-Englisch (en-US) und US-Spanisch () verfügbar. es-US Die Schwärzung ist nicht mit der Sprachidentifikationkompatibel.
Sowohl geschwärzte als auch unredigierte Transkripte werden im selben Ausgabe-Bucket gespeichert. Amazon S3 Amazon Transcribe speichert sie in einem von Ihnen angegebenen Bucket oder in dem vom Service verwalteten Amazon S3 Standard-Bucket.
| PII-Typ | Beschreibung |
|---|---|
ADDRESS |
Eine physische Adresse, z. B. 100 Main Street, Anytown, USA oder Suite #12, Gebäude 123. Eine Adresse kann eine Straße, ein Gebäude, einen Ort, eine Stadt, ein Bundesland, ein Land, eine Grafschaft, eine Postleitzahl, einen Bezirk, ein Stadtviertel und mehr enthalten. |
ALL |
Schwärzen oder identifizieren Sie alle in dieser Tabelle aufgeführten PII-Typen. |
BANK_ACCOUNT_NUMBER |
Eine US-Bankkontonummer. Diese sind in der Regel zwischen 10 und 12 Ziffern lang, aber Amazon Transcribe erkennt auch Bankkontonummern, bei denen nur die letzten 4 Ziffern vorhanden sind. |
BANK_ROUTING |
Eine US-Bankleitzahl. Diese sind in der Regel 9 Ziffern lang, aber Amazon Transcribe erkennt auch Routing-Nummern, bei denen nur die letzten 4 Ziffern vorhanden sind. |
CREDIT_DEBIT_CVV |
Ein dreistelliger Kartenbestätigungscode (CVV), der auf Kredit- und Debitkarten von VISA und Discover vorhanden ist. MasterCard Bei American Express-Kredit- oder Debitkarten handelt es sich um einen 4-stelligen Zahlencode. |
CREDIT_DEBIT_EXPIRY |
Das Ablaufdatum einer Kredit- oder Debitkarte. Diese Zahl ist in der Regel 4-stellig und wird als Monat/Jahr oder MM/JJJJ formatiert. Amazon Transcribe Kann beispielsweise Ablaufdaten wie den 21. Januar, den 1. Januar 2021 und den 1. Januar 2021 erkennen. |
CREDIT_DEBIT_NUMBER |
Die Nummer einer Kredit- oder Debitkarte. Diese Zahlen können zwischen 13 und 16 Ziffern lang sein, erkennen aber Amazon Transcribe auch Kredit- oder Debitkartennummern, wenn nur die letzten 4 Ziffern vorhanden sind. |
EMAIL |
Eine E-Mail-Adresse, z. B. efua.owusu@email.com. |
NAME |
Der Name einer Person. Dieser Entitätstyp umfasst keine Titel wie Herr, Frau, Fräulein oder Dr.. Er wendet diesen Entitätstyp Amazon Transcribe nicht auf Namen an, die Teil von Organisationen oder Adressen sind. Amazon Transcribe Erkennt beispielsweise die John Doe Organization als Organisation und Jane Doe Street als Adresse. |
PHONE |
Eine Telefonnummer. Dieser Entitätstyp umfasst auch Fax- und Pager-Nummern. |
PIN |
Eine 4-stellige persönliche Identifikationsnummer (PIN), mit der jemand Zugang zu seinen Kontodaten erhält. |
SSN |
Eine Sozialversicherungsnummer (SSN) ist eine 9-stellige Nummer, die an US-Bürger, Personen mit ständigem Wohnsitz und Personen mit vorübergehender Erwerbstätigkeit vergeben wird. Amazon Transcribe erkennt auch Sozialversicherungsnummern, wenn nur die letzten 4 Ziffern vorhanden sind. |
Sie können einen Batch-Transkriptionsauftrag mit dem AWS SDK AWS Management Console AWS CLI, oder starten.
-
Melden Sie sich an der AWS Management Console
an. -
Wählen Sie im Navigationsbereich Transkriptionsaufträge und dann Auftrag erstellen (oben rechts). Daraufhin wird die Seite Auftragsdetails angeben geöffnet.
-
Nachdem Sie die gewünschten Felder auf der Seite Auftragsdetails angeben ausgefüllt haben, wählen Sie Weiter, um zur Seite Auftrag konfigurieren – optional zu gelangen. Hier finden Sie den Bereich zum Entfernen von Inhalten mit dem Schalter für die Schwärzung von PII .
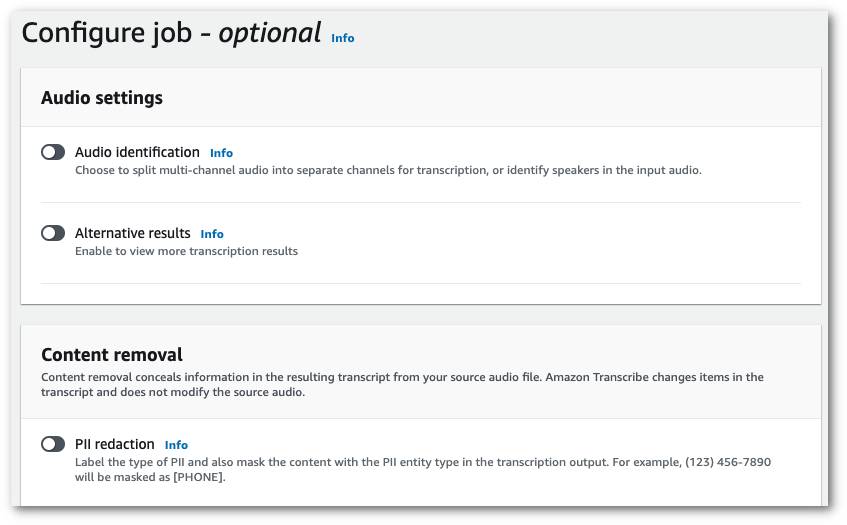
-
Sobald Sie die Schwärzung von PII ausgewählt haben, haben Sie die Möglichkeit, alle PII-Typen auszuwählen, die Sie schwärzen möchten. Sie können auch festlegen, dass ein ungeschwärztes Transkript angezeigt wird, wenn Sie Ungeschwärztes Transkript in das Auftragsausgabefeld einschließen auswählen.
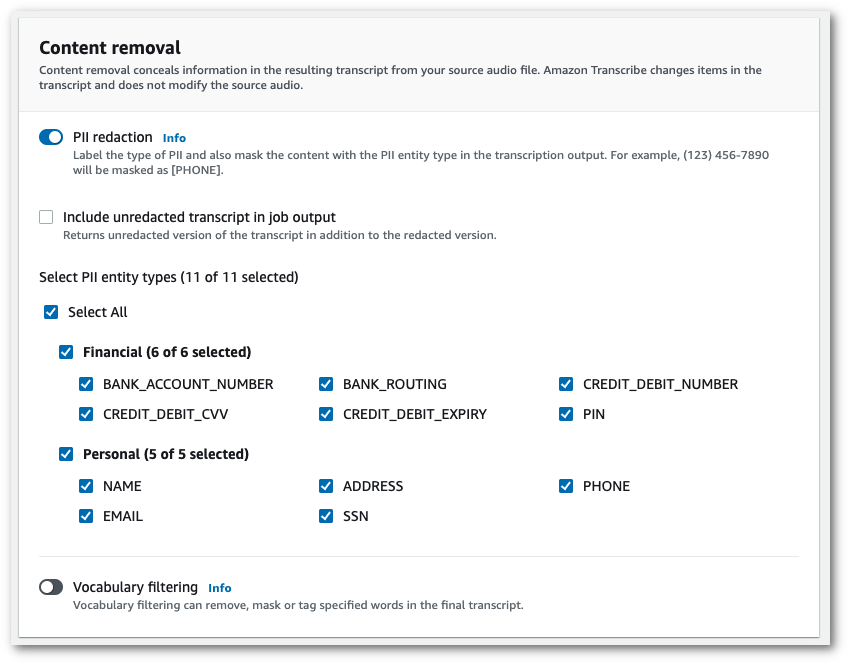
-
Wählen Sie Auftrag erstellen, um Ihren Transkriptionsauftrag auszuführen.
In diesem Beispiel werden der Befehl und der start-transcription-jobcontent-redaction Weitere Informationen finden Sie unter StartTranscriptionJob und ContentRedaction.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://DOC-EXAMPLE-BUCKET/my-input-files/my-media-file.flac\ --output-bucket-nameDOC-EXAMPLE-BUCKET\ --output-keymy-output-files/ \ --language-codeen-US\ --content-redaction RedactionType=PII,RedactionOutput=redacted,PiiEntityTypes=NAME,ADDRESS,BANK_ACCOUNT_NUMBER
Hier ist ein weiteres Beispiel, in dem die start-transcription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://filepath/my-first-redaction-job.json
Die Datei my-first-redaction-job.json enthält den folgenden Anfragetext.
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://DOC-EXAMPLE-BUCKET/my-input-files/my-media-file.flac" }, "OutputBucketName": "DOC-EXAMPLE-BUCKET", "OutputKey": "my-output-files/", "LanguageCode": "en-US", "ContentRedaction": { "RedactionOutput":"redacted", "RedactionType":"PII", "PiiEntityTypes": [ "NAME", "ADDRESS", "BANK_ACCOUNT_NUMBER" ] } }
In diesem Beispiel wird der verwendet AWS SDK for Python (Boto3) , um den Inhalt mithilfe des ContentRedaction Arguments für die Methode start_transcription_jobStartTranscriptionJob und ContentRedaction.
Weitere Beispiele für die Verwendung der AWS SDKs, einschließlich funktionsspezifischer, szenarienspezifischer und serviceübergreifender Beispiele, finden Sie im Kapitel. Codebeispiele für Amazon Transcribe mit AWS SDKs
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') job_name = "my-first-transcription-job" job_uri = "s3://DOC-EXAMPLE-BUCKET/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'DOC-EXAMPLE-BUCKET', OutputKey = 'my-output-files/', LanguageCode = 'en-US', ContentRedaction = { 'RedactionOutput':'redacted', 'RedactionType':'PII', 'PiiEntityTypes': [ 'NAME','ADDRESS','BANK_ACCOUNT_NUMBER' ] } ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
Anmerkung
Die Bearbeitung personenbezogener Daten für Batch-Jobs wird nur in folgenden Ländern unterstützt AWS-Regionen: Asien-Pazifik (Hongkong), Asien-Pazifik (Mumbai), Asien-Pazifik (Seoul), Asien-Pazifik (Singapur), Asien-Pazifik (Sydney), Asien-Pazifik GovCloud (Tokio), (US-West), Kanada (Zentral), EU (Frankfurt), EU (Irland), EU (London), EU (Paris), Naher Osten (Bahrain), Südamerika (Sao Paulo), USA Ost (Nord-Virginia), USA Ost (Ohio), USA West (Oregon) und USA West (Nordkalifornien).
