Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
REL10-BP01 Bereitstellen des Workloads an mehreren Standorten
Verteilen Sie die Workload-Daten und -Ressourcen über mehrere Availability Zones oder ggf. über mehrere AWS-Regionen.
Ein grundlegendes Prinzip für das Servicedesign in AWS ist die Vermeidung von Single Points of Failure, einschließlich der zugrunde liegenden physischen Infrastruktur. AWS bietet Cloud-Computing-Ressourcen und -Services weltweit an mehreren geographischen Standorten, den sogenannten Regionen. Jede Region ist physisch und logisch unabhängig und besteht aus drei oder mehr Availability Zones (AZs). Availability Zones liegen geographisch nahe beieinander, sind jedoch physisch voneinander getrennt und isoliert. Wenn Sie Ihre Workloads auf Availability Zones und Regionen verteilen, minimieren Sie das Risiko von Bedrohungen wie Bränden, Überschwemmungen, wetterbedingten Katastrophen, Erdbeben und menschlichem Versagen.
Entwickeln Sie eine Standortstrategie, um eine hohe Verfügbarkeit zu gewährleisten, die für Ihre Workloads geeignet ist.
Gewünschtes Ergebnis: Produktionsworkloads werden auf mehrere Availability Zones (AZs) oder Regionen verteilt, um Fehlertoleranz und Hochverfügbarkeit zu erreichen.
Typische Anti-Muster:
-
Ihr Produktionsworkload ist nur in einer einzelnen Availability Zone vorhanden.
-
Sie implementieren eine Architektur mit mehreren Regionen, wenn eine Multi-AZ-Architektur die geschäftlichen Anforderungen erfüllen würde.
-
Ihre Bereitstellungen oder Daten werden desynchronisiert, was zu Konfigurationsabweichungen oder unzureichend replizierten Daten führt.
-
Sie berücksichtigen nicht die Abhängigkeiten zwischen Anwendungskomponenten, wenn sich die Anforderungen an Ausfallsicherheit und mehrere Standorte zwischen diesen Komponenten unterscheiden.
Vorteile der Nutzung dieser bewährten Methode:
-
Ihre Workloads sind widerstandsfähiger gegen Vorfälle wie Strom- oder Umgebungssteuerungsausfälle, Naturkatastrophen, Upstream-Serviceausfälle oder Netzwerkprobleme, die sich auf eine AZ oder eine ganze Region auswirken.
-
Sie können auf einen größeren Bestand an Amazon-EC2-Instances zugreifen und die Wahrscheinlichkeit von InsufficientCapacityExceptions (ICE) verringern, wenn Sie bestimmte EC2-Instance-Typen starten.
Risikostufe bei fehlender Befolgung dieser bewährten Methode: Hoch
Implementierungsleitfaden
Stellen Sie alle Produktionsworkloads in mindestens zwei Availability Zones (AZs) in einer Region bereit und führen Sie diese dort aus.
Verwenden mehrerer Availability Zones
Availability Zones sind Standorte für das Hosting von Ressourcen, die physisch voneinander getrennt sind, um korrelierte Ausfälle aufgrund von Risiken wie Bränden, Überschwemmungen und Tornados zu vermeiden. Jede Availability Zone verfügt über eine unabhängige physische Infrastruktur, einschließlich Stromversorgungsanschlüssen, Notstromquellen, mechanischen Services und Netzwerkkonnektivität. Dadurch bleiben Fehler in einer dieser Komponenten nur auf die betroffene Availability Zone beschränkt. Wenn beispielsweise aufgrund eines AZ-weiten Vorfalls EC2-Instances in der betroffenen Availability Zone nicht verfügbar sind, bleiben Ihre Instances in einer anderen Availability Zone weiterhin verfügbar.
Obwohl die Availability Zones in derselben AWS-Region physisch voneinander getrennt sind, sind sie einander nah genug, um Netzwerke mit hohem Durchsatz und niedriger Latenz (einstellige Millisekundenbeträge) bereitzustellen. Sie können Daten für die meisten Workloads synchron zwischen Availability Zones replizieren, ohne den Benutzerkomfort wesentlich zu beeinträchtigen. So können Sie Availability Zones in einer Aktiv/Aktiv- oder Aktiv/Standby-Konfiguration nutzen.
Die gesamte mit Ihren Workloads verbundene Computingleistung sollte auf mehrere Availability Zones verteilt werden. Dazu gehören Amazon-EC2-Instances
Sie sollten auch Daten für Ihre Workloads replizieren und sie in mehreren Availability Zones verfügbar machen. Einige AWS-verwaltete Datenservices wie Amazon S3
Wenn Sie selbstverwalteten Speicher wie Amazon Elastic Block Store (EBS)
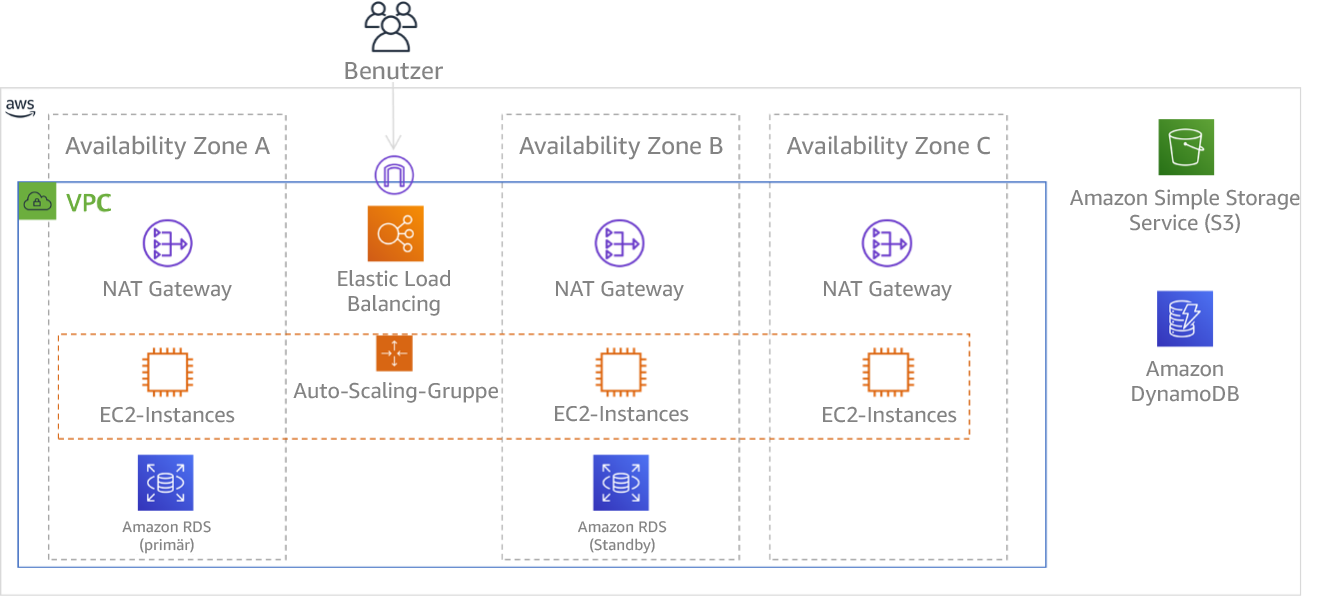
Abbildung 9: Mehrstufige Architektur, die in drei Availability Zones bereitgestellt wird. Amazon S3 und Amazon DynamoDB nutzen immer automatisch mehrere AZs. Auch der ELB wird in allen drei Zonen bereitgestellt.
Verwenden von mehreren AWS-Regionen
Wenn Sie über Workloads verfügen, die extreme Widerstandsfähigkeit erfordern (z. B. kritische Infrastrukturen, gesundheitsbezogene Anwendungen oder Services mit strengen kundenspezifischen oder gesetzlich vorgeschriebenen Verfügbarkeitsanforderungen), benötigen Sie möglicherweise zusätzliche Verfügbarkeit, die über das hinausgeht, was eine einzelne AWS-Region bieten kann. In diesem Fall sollten Sie Ihre Workloads auf mindestens zwei AWS-Regionen verteilen und dort ausführen (vorausgesetzt, dass Ihre Anforderungen an die Datenresidenz dies zulassen).
AWS-Regionen befinden sich in verschiedenen geographischen Regionen der Welt und auf mehreren Kontinenten. AWS-Regionen verfügen über eine noch stärkere physische Trennung und Isolierung als Availability Zones allein. AWS-Services, mit wenigen Ausnahmen, nutzen dieses Konzept, um völlig unabhängig zwischen verschiedenen Regionen zu operieren (auch bekannt als Regionalservices). Ein Ausfall eines Services in einer AWS-Region soll den Services in einer anderen Region nicht beeinträchtigen.
Wenn Sie Ihre Workloads in mehreren Regionen betreiben, sollten Sie zusätzliche Anforderungen berücksichtigen. Da Ressourcen in verschiedenen Regionen voneinander getrennt und unabhängig voneinander sind, müssen Sie die Komponenten Ihrer Workloads in jeder Region duplizieren. Dazu gehören neben Rechen- und Datenservices auch grundlegende Infrastrukturen wie VPCs.
HINWEIS: Wenn Sie ein multiregionales Design in Betracht ziehen, stellen Sie sicher, dass Ihre Workloads in einer einzigen Region ausgeführt werden können. Wenn Sie Abhängigkeiten zwischen Regionen erstellen, in denen eine Komponente in einer Region auf Services oder Komponenten in einer anderen Region angewiesen ist, könnt dies das Ausfallrisiko erhöhen und die Zuverlässigkeit erheblich beeinträchtigen.
Um multiregionale Bereitstellungen zu vereinfachen und die Konsistenz aufrechtzuerhalten, kann AWS CloudFormation StackSets Ihre gesamte AWS-Infrastruktur über mehrere Regionen hinweg replizieren. AWS CloudFormation
Sie müssen Ihre Daten auch in jeder der von Ihnen ausgewählten Regionen replizieren. Viele AWS-verwaltete Datenservices bieten multiregionale Replikationsfunktionen, wie z. B. Amazon S3, Amazon DynamoDB, Amazon RDS, Amazon RDS, Amazon Aurora Amazon Aurora, Amazon Redshift, Amazon Elastiache und Amazon EFS. Globale Amazon DynamoDB-Tabellen
AWS bietet außerdem die Möglichkeit, den Anforderungsdatenverkehr mit großer Flexibilität an Ihre regionalen Bereitstellungen weiterzuleiten. Beispielsweise können Sie Ihre DNS-Datensätze mithilfe von Amazon Route 53
Auch wenn Sie sich dafür entscheiden, aus Gründen der Hochverfügbarkeit nicht in mehreren Regionen zu operieren, sollten Sie mehrere Regionen als Teil Ihrer Notfallwiederherstellungsstrategie (DR) in Betracht ziehen. Wenn möglich, replizieren Sie die Infrastrukturkomponenten und Daten Ihrer Workloads in einer Warm-Standby- oder Pilot-Light-Konfiguration in einer sekundären Region. Dabei replizieren Sie die Basisinfrastruktur aus der primären Region wie VPCs, Auto-Scaling-Gruppen, Container-Orchestratoren und andere Komponenten, konfigurieren aber die Komponenten variabler Größe in der Standby-Region (wie die Anzahl der EC2-Instances und Datenbankreplikate) so, dass sie eine minimal funktionsfähige Größe haben. Sie sorgen auch für eine kontinuierliche Datenreplikation von der primären Region zur Standby-Region. Wenn ein Vorfall eintritt, können Sie die Ressourcen in der Standby-Region skalieren oder vergrößern und sie dann zur primären Region heraufstufen.
Implementierungsschritte
-
Ermitteln Sie gemeinsam mit geschäftlichen Stakeholdern und Datenresidenzexperten die AWS-Regionen, die zum Hosten Ihrer Ressourcen und Daten verwendet werden können.
-
Bewerten Sie Ihre Workloads in Zusammenarbeit mit geschäftlichen und technischen Stakeholdern, um festzustellen, ob die Anforderungen an die Ausfallsicherheit durch einen Multi-AZ-Ansatz (einzelneAWS-Region) erfüllt werden können, oder ob ein multiregionaler Ansatz erforderlich ist (wenn mehrere Regionen zulässig sind). Die Verwendung mehrerer Regionen kann zu einer höheren Verfügbarkeit führen, jedoch auch zusätzliche Komplexität und Kosten mit sich bringen. Berücksichtigen Sie bei Ihrer Bewertung die folgenden Faktoren:
-
Geschäftsziele und Kundenanforderungen: Welche Ausfallzeiten sind zulässig, wenn in einer Availability Zone oder einer Region ein Vorfall eintritt, der sich auf Workloads auswirkt? Bewerten Sie Ihre Ziele für den Wiederherstellungspunkt wie in REL13-BP01 Definieren von Wiederherstellungszielen bei Ausfällen und Datenverlusten beschrieben.
-
Anforderungen an die Notfallwiederherstellung (DR): Gegen welche Art von potenziellen Notfällen möchten Sie sich versichern? Ziehen Sie die Möglichkeit eines Datenverlusts oder einer langfristigen Nichtverfügbarkeit in unterschiedlichen Ausprägungen in Betracht, von einer einzelnen Availability Zone bis hin zu einer ganzen Region. Wenn Sie Daten und Ressourcen über Availability Zones hinweg replizieren und in einer einzelnen Availability Zone ein länger dauernder Ausfall auftritt, können Sie den Service in einer anderen Availability Zone wiederherstellen. Wenn Sie Daten und Ressourcen regionsübergreifend replizieren, können Sie den Service in einer anderen Region wiederherstellen.
-
-
Stellen Sie Ihre Computingressourcen in mehreren Availability Zones bereit.
-
Erstellen Sie in Ihrer VPC mehrere Subnetze in verschiedenen Availability Zones. Konfigurieren Sie jedes Subnetz so, dass es groß genug ist, um die Ressourcen aufzunehmen, die zur Bewältigung des Workloads benötigt werden, auch bei einem Vorfall. Weitere Informationen finden Sie unter REL02-BP03 Berücksichtigen von Erweiterung und Verfügbarkeit bei der Zuweisung von IP-Adressen für Subnetze.
-
Wenn Sie Amazon-EC2-Instances verwenden, verwenden Sie EC2 Auto Scaling
, um Ihre Instances zu verwalten. Geben Sie die Subnetze an, die Sie im vorherigen Schritt ausgewählt haben, als Sie Ihre Auto-Scaling-Gruppen erstellt haben. -
Wenn Sie AWS Fargate Compute für Amazon ECS oder Amazon EKS verwenden, wählen Sie die Subnetze aus, die Sie im ersten Schritt ausgewählt haben, wenn Sie einen ECS-Service erstellen, eine ECS-Aufgabe starten oder ein Fargate-Profil für EKS erstellen.
-
Wenn Sie AWS Lambda-Funktionen verwenden, die in Ihrer VPC ausgeführt werden müssen, wählen Sie die Subnetze aus, die Sie im ersten Schritt bei der Erstellung der Lambda-Funktion ausgewählt haben. AWS Lambda verwaltet die Verfügbarkeit für alle Funktionen, die keine VPC-Konfiguration haben, automatisch für Sie.
-
Platzieren Sie Traffic Directors wie Load Balancer vor Ihren Computingressourcen. Wenn zonenübergreifendes Load Balancing aktiviert ist, erkennen AWSAp plication Load Balancer und Network Load Balancer, wenn Ziele wie EC2-Instances und Container aufgrund einer Beeinträchtigung der Availability Zone nicht erreichbar sind, und leiten den Datenverkehr zu Zielen in intakten Availability Zones um. Wenn Sie das zonenübergreifende Load Balancing deaktivieren, verwenden Sie Amazon Application Recovery Controller (ARC), um die Zonenverschiebungsfunktion bereitzustellen. Wenn Sie einen Load Balancer eines Drittanbieters verwenden oder Ihre eigenen Load Balancer implementiert haben, konfigurieren Sie diese mit mehreren Front-Ends in verschiedenen Availability Zones.
-
-
Replizieren Sie die Daten Ihrer Workloads in mehrere Availability Zones.
-
Wenn Sie einen AWS-verwalteten Datenservice wie Amazon RDS, Amazon ElastiCache oder Amazon FSx verwenden, lesen Sie dessen Benutzerhandbuch, um mehr über seine Datenreplikations- und Ausfallsicherheitsfunktionen zu erfahren. Aktivieren Sie bei Bedarf AZ-übergreifende Replikation und Failover.
-
Wenn Sie AWS-verwaltete Speicherservices wie Amazon S3, Amazon EFS und Amazon FSx verwenden, vermeiden Sie die Verwendung von Single-AZ- oder One-Zone-Konfigurationen für Daten, die eine hohe Dauerhaftigkeit erfordern. Verwenden Sie für diese Services eine Multi-AZ-Konfiguration. Prüfen Sie im Benutzerhandbuch des jeweiligen Services, ob die Multi-AZ-Replikation standardmäßig aktiviert ist, oder ob Sie sie aktivieren müssen.
-
Wenn Sie eine selbstverwaltete Datenbank, eine Warteschlange oder einen anderen Speicherservice ausführen, organisieren Sie die Multi-AZ-Replikation gemäß den Anweisungen zu der Anwendung oder bewährten Methoden. Machen Sie sich mit den Failover-Verfahren für Ihre Anwendung vertraut.
-
-
Konfigurieren Sie Ihren DNS-Service so, dass er AZ-Beeinträchtigungen erkennt und den Datenverkehr in eine fehlerfreie Availability Zone umleitet. Amazon Route 53 kann dies automatisch tun, wenn es in Kombination mit Elastic Load Balancers verwendet wird. Route 53 kann auch mit Failover-Datensätzen konfiguriert werden, bei denen mithilfe von Integritätsprüfungen nur Anfragen mit fehlerfreien IP-Adressen beantwortet werden. Geben Sie für alle DNS-Datensätze, die für das Failover verwendet werden, einen kleinen TTL-Wert (Time to Live) an (z. B. 60 Sekunden oder weniger), um zu verhindern, dass das Zwischenspeichern von Einträgen die Wiederherstellung behindert (Route 53-Aliaseinträge stellen die entsprechenden TTLs für Sie bereit).
Zusätzliche Schritte bei Verwendung mehrerer AWS-Regionen
-
Replizieren Sie den gesamten Betriebssystem- (OS) und Anwendungscode, der von Ihren Workloads verwendet wird, in den ausgewählten Regionen. Replizieren Sie bei Bedarf Amazon Machine Images (AMIs), die von Ihren EC2-Instances verwendet werden, mithilfe von Lösungen wie Amazon EC2 Image Builder. Replizieren Sie Container-Images, die in Registern gespeichert sind, mithilfe von Lösungen wie der regionsübergreifenden Replikation in Amazon ECR. Aktivieren Sie die regionale Replikation für alle Amazon-S3-Buckets, die zum Speichern von Anwendungsressourcen verwendet werden.
-
Stellen Sie Ihre Computingressourcen und Konfigurationsmetadaten (z. B. als im AWS Systems Manager Parameter Store gespeicherte Parameter) in mehreren Regionen bereit. Verwenden Sie dieselben Verfahren, die in den vorherigen Schritten beschrieben wurden, replizieren Sie jedoch die Konfiguration für jede Region, die Sie für Ihre Workloads verwenden. Verwenden Sie Infrastructure-as-Code-Lösungen wie AWS CloudFormation, um beispielsweise die Konfigurationen in allen Regionen einheitlich zu reproduzieren. Wenn Sie eine sekundäre Region in einer Pilot-Light-Konfiguration für die Notfallwiederherstellung verwenden, können Sie die Anzahl Ihrer Computingressourcen auf einen Mindestwert reduzieren, um Kosten zu sparen, was die Zeit bis zur Wiederherstellung entsprechend verlängert.
-
Replizieren Sie Ihre Daten aus Ihrer primären Region in Ihre sekundären Regionen.
-
Globale Amazon-DynamoDB-Tabellen stellen globale Replikate Ihrer Daten bereit, in die aus jeder unterstützten Region geschrieben werden kann. Bei anderen AWS-verwalteten Datenservices wie Amazon RDS, Amazon Aurora und Amazon Elasticache legen Sie eine primäre (Lese-/Schreib-) Region und Replikatregionen (schreibgeschützt) fest. Einzelheiten zur regionalen Replikation finden Sie in den Benutzer- und Entwicklerhandbüchern der jeweiligen Services.
-
Wenn Sie eine selbstverwaltete Datenbank verwenden, richten Sie die Replikation in mehreren Regionen gemäß den Anweisungen zur Anwendung oder zu den bewährten Methoden ein. Machen Sie sich mit den Failover-Verfahren für Ihre Anwendung vertraut.
-
Wenn Ihre Workloads AWS EventBridge verwenden, müssen Sie möglicherweise ausgewählte Ereignisse aus Ihrer primären Region an Ihre sekundären Regionen weiterleiten. Geben Sie dazu Ereignisbusse in Ihren sekundären Regionen als Ziele für übereinstimmende Ereignisse in Ihrer Hauptregion an.
-
-
Überlegen Sie, ob und in welchem Umfang Sie in allen Regionen identische Verschlüsselungsschlüssel verwenden möchten. Ein typischer Ansatz, der Sicherheit und Benutzerfreundlichkeit in Einklang bringt, ist die Verwendung von regionsspezifischen Schlüsseln für für die Region lokale Daten und Authentifizierung und die Verwendung von Schlüsseln mit globalem Geltungsbereich für die Verschlüsselung von Daten, die zwischen verschiedenen Regionen repliziert werden. AWS Key Management Service (KMS)
unterstützt Schlüssel für mehrere Regionen, um Schlüssel, die zwischen Regionen gemeinsam genutzt werden, sicher zu verteilen und zu schützen. -
Ziehen Sie AWS Global Accelerator in Betracht, um die Verfügbarkeit Ihrer Anwendung zu verbessern, indem Sie den Datenverkehr in Regionen mit fehlerfreien Endpunkten umleiten.
Ressourcen
Zugehörige bewährte Methoden:
Zugehörige Dokumente:
-
Amazon EC2 Auto Scaling: Beispiel: Aufteilen von Instances über mehrere Availability Zones
-
Wie Amazon ECS Aufgaben auf Container-Instances platziert (einschließlich Fargate)
-
Amazon Elasticache for Redis OSS: Replikation über AWS-Regionen hinweg mit globalen Datenspeichern
-
Amazon Application Recovery Controller (ARC) – Entwicklerhandbuch
-
Senden und Empfangen von Amazon-EventBridge-Ereignissen zwischen AWS-Regionen
-
Blogserie „Erstellen einer regionsübergreifenden Anwendung mit AWS-Services“
-
Architektur für die Notfallwiederherstellung in AWS, Teil III: Pilot Light und Warm Standby
Zugehörige Videos:
