Búsqueda de datos anteriores de un clúster de base de datos de Aurora
Con Edición compatible con Amazon Aurora MySQL puede realizar búsquedas de datos anteriores en un clúster de base de datos en un momento específico, sin restaurar datos desde un backup.
importante
Las versiones 2, 3 y 8.4 de Aurora MySQL admiten la función de búsqueda de datos anteriores.
Contenido
Consideraciones de actualización para clústeres habilitados para backtrack
Configuración de la búsqueda de datos anteriores en un clúster de base de datos de Aurora MySQL
Búsqueda de datos anteriores para un clúster de base de datos de Aurora MySQL
Monitorización de la búsqueda de datos anteriores para un clúster de base de datos de Aurora MySQL
Suscripción a un evento de búsqueda de datos anteriores con la consola
Deshabilitación de la búsqueda de datos anteriores para un clúster de base de datos de Aurora MySQL
Información general de búsquedas de datos anteriores
La búsqueda de datos anteriores "rebobina" el clúster de base de datos al momento que especifique. La búsqueda de datos anteriores no es un sustituto del backup del clúster de base de datos para que pueda restaurarlo a un momento determinado. No obstante, la búsqueda de datos anteriores presenta las siguientes ventajas respecto al backup y restauración tradicional:
Puede deshacer errores con facilidad. Si lleva a cabo una acción destructiva por error, por ejemplo DELETE sin una cláusula WHERE, puede realizar una búsqueda de datos anteriores del clúster de base de datos a un momento anterior a la acción destructiva con una interrupción de servicio mínima.
Puede realizar una búsqueda de datos anteriores en un clúster de base de datos rápidamente. La restauración de un clúster de base de datos a un momento determinado lanza un nuevo clúster de base de datos y lo restaura a partir de datos de backup o de una instantánea de clúster de base de datos, lo que puede tardar horas. La búsqueda de datos anteriores de un clúster de base de datos no requiere un nuevo clúster de base de datos y rebobina el clúster de base de datos en cuestión de minutos.
Puede explorar cambios de datos anteriores. Puede realizar búsqueda de datos anteriores de un clúster de base de datos repetidamente adelante y atrás en el tiempo para ayudar a determinar cuándo se produjo un cambio de datos particular. Por ejemplo, puede realizar una búsqueda de datos anteriores de un clúster de base de datos de hace tres horas y, a continuación, realizar la búsqueda de datos anteriores hacia adelante en el tiempo una hora. En este caso, el tiempo de búsqueda de datos anteriores es dos horas antes de la hora original.
nota
Para obtener más información acerca la restauración de un clúster de base de datos a un momento determinado, consulte Información general de copias de seguridad y restauración de un clúster de base de datos Aurora.
Ventana de búsqueda de datos anteriores
Con la búsqueda de datos anteriores, hay una ventana de búsqueda de datos anteriores de destino y una ventana de búsqueda de datos anteriores real:
-
La ventana de búsqueda de datos anteriores de destino es la cantidad de tiempo que desea poder realizar búsqueda de datos anteriores en su clúster de base de datos. Cuando habilita la búsqueda de datos anteriores, especifica una ventana de búsqueda de datos anteriores de destino. Por ejemplo, podría especificar una ventana de búsqueda de datos anteriores de 24 horas si desea poder realizar la búsqueda de datos anteriores del clúster de base de datos un día.
-
La ventana de búsqueda de datos anteriores real es la cantidad de tiempo real en la que puede realizar búsqueda de datos anteriores en su clúster de base de datos, que puede ser inferior a la de la ventana de búsqueda de datos anteriores de destino. La ventana de búsqueda de datos anteriores real se basa en su carga de trabajo y en el almacenamiento disponible para información de almacenamiento sobre cambios de base de datos, denominados registros de cambio.
A medida que actualiza su clúster de base de datos de Aurora con la búsqueda de datos anteriores habilitada, genera registros de cambios. Aurora mantiene los registros de cambios del periodo de búsqueda de datos anteriores de destino y paga una tarifa por hora para almacenarlos. Tanto la ventana de búsqueda de datos anteriores de destino como la carga de trabajo de su clúster de base de datos determinan el número de registros de cambio que puede almacenar. La carga de trabajo es el número de cambios que realiza en su clúster de base de datos en un período de tiempo dado. Si la carga de trabajo es pesada, almacena más registros de cambio en su ventana de búsqueda de datos anteriores de la que tendría si la carga de trabajo fuera ligera.
Puede entender la ventana de búsqueda de datos anteriores de destino como el objetivo para la cantidad de tiempo máxima que desea poder realizar la búsqueda de datos anteriores en su clúster de base de datos. En la mayoría de los casos, puede realizar una búsqueda de datos anteriores del período de tiempo máximo que haya especificado. No obstante, en algunos casos, el clúster de base de datos no puede almacenar suficientes registros de cambio para realizar la búsqueda de datos anteriores durante el período de tiempo máximo y la ventana de búsqueda de datos anteriores real es inferior a la de destino. Normalmente, la ventana de búsqueda de datos anteriores real es más pequeña que el destino cuando se tiene una carga de trabajo extremadamente pesada en el clúster de base de datos. Cuando la ventana de búsqueda de datos anteriores real es inferior al destino, le enviamos una notificación.
Cuando la búsqueda de datos anteriores está habilitada para un clúster de base de datos y elimina una tabla almacenada en el clúster de base de datos, Aurora mantiene dicha tabla en los registros de cambio de búsqueda de datos anteriores. Lo hace para que pueda volver a un momento anterior a la eliminación de la tabla. Si no tiene espacio suficiente en su ventana de búsqueda de datos anteriores para almacenar la tabla, la tabla podría acabar por eliminarse de los registros de cambios de búsqueda de datos anteriores.
Tiempo de búsqueda de datos anteriores
Aurora siempre realiza la búsqueda de datos anteriores en un momento que sea coherente para el clúster de base de datos. Al hacerlo así, se elimina la posibilidad de transacciones sin confirmar cuando se ha completado la búsqueda de datos anteriores. Cuando se especifica una hora para una búsqueda de datos anteriores, Aurora elige automáticamente la hora coherente más próxima posible. Este enfoque significa que la búsqueda de datos anteriores completada podría no concordar exactamente con la hora que especifique, pero puede determinar la hora exacta de una búsqueda de datos anteriores con el comando describe-db-cluster-backtracks de la CLI de AWS. Para obtener más información, consulte Recuperar búsqueda de datos anteriores existentes.
Limitaciones de la búsqueda de datos anteriores
Las limitaciones siguientes son aplicables a la búsqueda de datos anteriores:
-
La búsqueda de datos anteriores solo está disponible para clústeres de base de datos que se crearon con la característica de búsqueda de datos anteriores habilitada. Tampoco puede modificar un clúster de base de datos para habilitar la característica de búsqueda de datos anteriores. Puede habilitar la característica de búsqueda de datos anteriores cuando cree un clúster de base de datos nuevo o restaure una instantánea de un clúster de base de datos.
-
El límite para una ventana de búsqueda de datos anteriores es de 72 horas.
-
La búsqueda de datos anteriores afecta a todo el clúster de base de datos. Por ejemplo, puede realizar la búsqueda de datos anteriores selectivamente en una única tabla o una única actualización de datos.
-
No puede crear réplicas de lectura entre regiones desde un clúster habilitado para búsqueda de datos anteriores, pero sí puede habilitar la replicación de registros binarios (binlog) en el clúster. Además, si intenta realizar una búsqueda de datos anteriores en un clúster de base de datos para el que está habilitado el registro binario, suele producirse un error, a menos que haya elegido forzar la búsqueda de datos anteriores. Cualquier intento de forzar una búsqueda de datos anteriores interrumpirá las réplicas de lectura descendentes e interferirá con otras operaciones, como las implementaciones azul/verde.
-
No puede realizar una búsqueda de datos anteriores de un clon de base de datos a una hora anterior a la que se creó dicho clon de base de datos. Sin embargo, puede utilizar la base de datos original para realizar una búsqueda de datos anteriores a un momento anterior a la creación del clon. Para obtener más información acerca de la clonación de la base de datos, consulte Clonación de un volumen de clúster de base de datos de Amazon Aurora.
-
La búsqueda de datos anteriores provoca una breve interrupción de la instancia de base de datos. Debe detener o pausar las aplicaciones antes de iniciar una operación de búsqueda de datos anteriores para asegurarse de que no haya ninguna solicitud nueva de lectura o escritura. Durante la operación de búsqueda de datos anteriores, Aurora pone en pausa la base de datos, cierra las conexiones abiertas y borra las lecturas y escrituras sin confirmar. A continuación, espera a que se complete la operación de búsqueda de datos anteriores.
-
No puede restaurar una instantánea entre regiones de un clúster habilitado para una búsqueda de datos anteriores en una región de AWS que no admita una búsqueda de datos anteriores.
-
Si realiza una actualización local para un clúster habilitado para la función de búsqueda de datos anteriores desde la versión 2 a la versión 3, o desde la versión 3 a la versión 8.4, de Aurora MySQL, no podrá realizar ninguna búsqueda de datos anteriores a un punto en el tiempo anterior a la actualización.
Disponibilidad en regiones y versiones
Backtrack no está disponible para Aurora PostgreSQL.
A continuación se presentan los motores compatibles y la disponibilidad de Backtrack con Aurora MySQL.
| Región | Aurora MySQL versión 8.4 | Aurora MySQL versión 3 | Aurora MySQL versión 2 |
|---|---|---|---|
| Este de EE. UU. (Norte de Virginia) | Todas las versiones | Todas las versiones | Todas las versiones |
| Este de EE. UU. (Ohio) | Todas las versiones | Todas las versiones | Todas las versiones |
| Oeste de EE. UU. (Norte de California) | Todas las versiones | Todas las versiones | Todas las versiones |
| Oeste de EE. UU. (Oregón) | Todas las versiones | Todas las versiones | Todas las versiones |
| África (Ciudad del Cabo) | – | – | – |
| Asia-Pacífico (Hong Kong) | – | – | – |
| Asia-Pacífico (Yakarta) | – | – | – |
| Asia-Pacífico (Malasia) | – | – | – |
| Asia-Pacífico (Melbourne) | – | – | – |
| Asia-Pacífico (Mumbai) | Todas las versiones | Todas las versiones | Todas las versiones |
| Asia-Pacífico (Nueva Zelanda) | – | – | – |
| Asia-Pacífico (Osaka) | Todas las versiones | Todas las versiones | Versión 2.07.3 y posterior |
| Asia-Pacífico (Seúl) | Todas las versiones | Todas las versiones | Todas las versiones |
| Asia-Pacífico (Singapur) | Todas las versiones | Todas las versiones | Todas las versiones |
| Asia-Pacífico (Sídney) | Todas las versiones | Todas las versiones | Todas las versiones |
| Asia-Pacífico (Taipéi) | – | – | – |
| Asia-Pacífico (Tailandia) | – | – | – |
| Asia-Pacífico (Tokio) | Todas las versiones | Todas las versiones | Todas las versiones |
| Canadá (centro) | Todas las versiones | Todas las versiones | Todas las versiones |
| Oeste de Canadá (Calgary) | – | – | – |
| China (Pekín) | – | – | – |
| China (Ningxia) | – | – | – |
| Europa (Fráncfort) | Todas las versiones | Todas las versiones | Todas las versiones |
| Europa (Irlanda) | Todas las versiones | Todas las versiones | Todas las versiones |
| Europa (Londres) | Todas las versiones | Todas las versiones | Todas las versiones |
| Europa (Milán) | – | – | – |
| Europa (París) | Todas las versiones | Todas las versiones | Todas las versiones |
| Europa (España) | – | – | – |
| Europa (Estocolmo) | – | – | – |
| Europa (Zúrich) | – | – | – |
| Israel (Tel Aviv) | – | – | – |
| México (centro) | – | – | – |
| Medio Oriente (Baréin) | – | – | – |
| Medio Oriente (EAU) | – | – | – |
| América del Sur (São Paulo) | – | – | – |
| AWS GovCloud (Este de EE. UU.) | – | – | – |
| AWS GovCloud (Oeste de EE. UU.) | – | – | – |
Consideraciones de actualización para clústeres habilitados para backtrack
Puede actualizar un clúster de base de datos que tenga habilitada la función de búsqueda de datos anteriores desde la versión 2 a la versión 3, o desde la versión 3 a la versión 8.4, de Aurora MySQL, ya que todas las versiones secundarias de la versión 3 y la versión 8.4 de Aurora MySQL son compatibles con la función de búsqueda de datos anteriores.
Suscripción a un evento de búsqueda de datos anteriores con la consola
El siguiente procedimiento describe cómo suscribirse a un evento de búsqueda de datos anteriores utilizando la consola. El evento le envía una notificación de correo electrónico o texto cuando su ventana de búsqueda de datos anteriores real es inferior a su ventana de búsqueda de datos anteriores de destino.
Para ver información de búsqueda de datos anteriores mediante la consola
Inicie sesión en la Consola de administración de AWS y abra la consola de Amazon RDS en https://console.aws.amazon.com/rds/
. -
Elija Event subscriptions (Suscripciones de evento).
-
Seleccione Create event subscription (Crear suscripción de evento).
-
En el cuadro Name (Nombre), escriba un nombre para la suscripción de evento y asegúrese de que se haya seleccionado Yes (Sí) en Enabled (Habilitado).
-
En la sección Target (Destino), elija New email topic (Nuevo tema de correo electrónico).
-
Para Topic name (Nombre de tema), escriba un nombre para el tema y para With these recipients (Con estos destinatarios), introduzca las direcciones de correo electrónico o los números de teléfono para recibir las notificaciones.
-
En la sección Source (Origen), elija Instances (Instancias) para Source type (Tipo de origen).
-
Para Instances to include (Instancias que incluir), elija Select specific instances (Seleccionar instancias específicas) y elija su instancia de base de datos.
-
Para Event categories to include (Categorías de evento que incluir), elija Select specific event categories (Seleccionar categorías de evento específicas) y elija backtrack (búsqueda de datos anteriores).
La página debería tener un aspecto similar a la página siguiente.
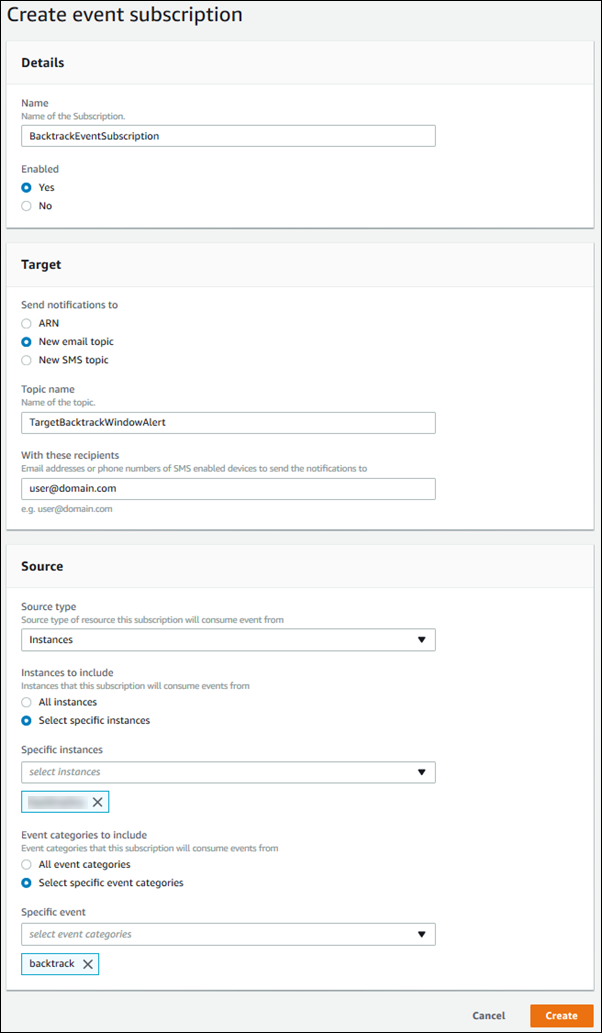
-
Seleccione Crear.
Recuperar búsqueda de datos anteriores existentes
Puede recuperar información de búsquedas de datos anteriores existentes para un clúster de base de datos. Esta información incluye el identificador único de la búsqueda de datos anteriores, la fecha y la hora para realizar la búsqueda de datos anteriores de inicio y final, la fecha y la hora a la que se solicitó la búsqueda de datos anteriores y el estado actual de la búsqueda de datos anteriores.
nota
Actualmente no se pueden recuperar las búsquedas de datos anteriores existentes utilizando la consola.
El siguiente procedimiento describe cómo recuperar las búsquedas de datos anteriores existentes para un clúster de base de datos utilizando la AWS CLI.
Para recuperar búsquedas de datos anteriores existentes utilizando la AWS CLI
-
Llame al comando describe-db-cluster-backtracks de la CLI de AWS y suministre los siguientes valores:
-
--db-cluster-identifier: el nombre del clúster de base de datos.
El ejemplo siguiente recuperar búsquedas de datos anteriores existentes para
sample-cluster.Para Linux, macOS o Unix:
aws rds describe-db-cluster-backtracks \ --db-cluster-identifier sample-clusterPara Windows:
aws rds describe-db-cluster-backtracks ^ --db-cluster-identifier sample-cluster -
Para recuperar información sobre las búsquedas de datos anteriores para un clúster de base de datos utilizando la API de Amazon RDS, utilice la operación DescribeDBClusterBacktracks. Esta acción devuelve la información acerca de las búsquedas de datos anteriores para el clúster de base de datos especificado en el valor DBClusterIdentifier.
