Cómo funciona Aurora Serverless v1
importante
AWS ha anunciado la fecha de fin de la vida útil de Aurora Serverless v1 que será el 31 de marzo de 2025. Recomendamos encarecidamente actualizar todos los clústeres de bases de datos de Aurora Serverless v1 a Aurora Serverless v2 antes de dicha fecha. Esta actualización puede implicar un cambio en el número de versión principal del motor de base de datos. Por lo tanto, es importante planificar, probar e implementar esta transición antes de la fecha de fin de la vida útil. A partir del 8 de enero de 2025, los clientes ya no podrán crear nuevos clústeres o instancias de Aurora Serverless v1 con la AWS Management Console o la CLI. Para obtener información sobre el proceso de migración, consulte Actualización de un clúster de Aurora Serverless v1 a Aurora Serverless v2.
Aurora Serverless v2 escala de forma más rápida y detallada. Aurora Serverless v2 también es más compatible con otras características de Aurora, como las instancias de base de datos de lector. Puede obtener más información sobre Aurora Serverless v2 en Uso de Aurora Serverless v2.
A continuación, le enseñaremos cómo funciona Aurora Serverless v1.
Aurora Serverless v1 architecture
La siguiente imagen es una visión general de la arquitectura de Aurora Serverless v1.
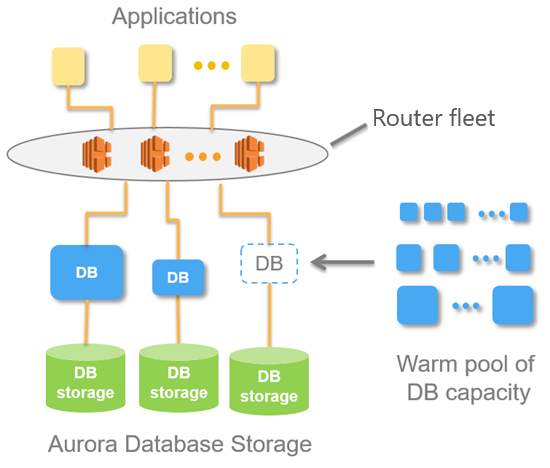
En lugar de aprovisionar y administrar los servidores de base de datos, se especifican unidades de capacidad de Aurora (ACU). Cada ACU es una combinación de aproximadamente 2 gigabytes (GB) de memoria, la CPU correspondiente y las redes. El almacenamiento de base de datos escala automáticamente de 10 gibibytes (GiB) a 128 tebibytes (TiB), al igual que el almacenamiento en un clúster de bases de datos de Aurora estándar.
Puede especificar las ACU mínima y máxima. La unidad de capacidad de Aurora mínima es la ACU más baja a la que puede escalarse el clúster de bases de datos al reducir la capacidad. La unidad de capacidad de Aurora máxima es la ACU más baja a la que puede escalarse el clúster de bases de datos al aumentar la capacidad. En función de la configuración, Aurora Serverless v1 crea de manera automática reglas de escalado para los límites de uso de la CPU, las conexiones y la memoria disponible.
Aurora Serverless v1 administra el grupo activo de recursos de una Región de AWS para minimizar el tiempo de escalado. Cuando Aurora Serverless v1 agrega nuevos recursos al clúster de bases de datos de Aurora, utiliza la flota de enrutadores para cambiar las conexiones de clientes activas a los nuevos recursos. En cualquier momento dado, solo se le cobrarán las ACU que se estén utilizando activamente en su clúster de base de datos de Aurora.
Escalado automático para Aurora Serverless v1
La capacidad asignada a su clúster de bases de datos de Aurora Serverless v1 se amplía y reduce sin problemas en función de la carga generada por la aplicación cliente. Aquí, la carga es la utilización de la CPU y el número de conexiones. Cuando la capacidad está limitada por cualquiera de ellos, Aurora Serverless v1 aumenta. Aurora Serverless v1 también se amplía cuando detecta problemas de rendimiento que se pueden resolver de esta manera.
Puede ver los eventos de escalado para su clúster de Aurora Serverless v1 en la AWS Management Console. Durante el escalado automático, Aurora Serverless v1 restablece la métrica de EngineUptime. El valor de la métrica de restablecimiento no significa que el escalado perfecto haya tenido problemas ni que Aurora Serverless v1 haya eliminado conexiones. Es simplemente el punto de partida para el tiempo de actividad en la nueva capacidad. Para obtener más información sobre las métricas, consulte Supervisión de métricas en un clúster de Amazon Aurora.
Cuando el clúster de base de datos de Aurora Serverless v1 no tiene conexiones activas, puede reducir la capacidad a cero (0 ACU). Para obtener más información, consulte Pausar y reanudar Aurora Serverless v1.
Cuando necesita realizar una operación de escalado, Aurora Serverless v1 primero intenta identificar un punto de escalado, un momento en el que no se estén procesando consultas. Aurora Serverless v1 podría no encontrar un punto de escalado por las siguientes razones:
-
Consultas de larga duración
-
Transacciones en curso
-
Tablas temporales o bloqueos de tabla
Para aumentar la tasa de éxito del clúster de bases de datos de Aurora Serverless v1 al encontrar un punto de escalado, le recomendamos que evite las consultas y transacciones de larga duración. Para obtener más información sobre las operaciones que bloquean el escalado y cómo evitarlas, consulte Best practices for working with Aurora Serverless v1
De forma predeterminada, Aurora Serverless v1 intenta encontrar un punto de escalado durante 5 minutos (300 segundos). Puede especificar un período de tiempo de espera distinto al crear o modificar el clúster. El tiempo de espera puede ser de 60 segundos a 10 minutos (600 segundos). Si Aurora Serverless v1 no puede encontrar ningún punto de escalado en el período especificado, el tiempo de espera de la operación de escalado automático se agotará.
De forma predeterminada, si el escalado automático no encuentra un punto de escalado antes de agotar el tiempo de espera, Aurora Serverless v1 mantiene el clúster en la capacidad actual. Puede cambiar este comportamiento predeterminado al crear o modificar el clúster de bases de datos de Aurora Serverless v1 al seleccionar la opción Force capacity change (Forzar el cambio de capacidad). Para obtener más información, consulte Acción de tiempo de espera para cambios de capacidad.
Acción de tiempo de espera para cambios de capacidad
Si se agota el tiempo de espera del escalado automático y no se encuentra ningún punto de escalado, Aurora mantendrá la capacidad actual de forma predeterminada. Puede elegir que Aurora fuerce el cambio al seleccionar la opción Force the capacity change (Forzar cambio de capacidad). Esta opción está disponible en la sección Autoscaling timeout and action (Acción y tiempo de espera de escalado automático) de la página Create database (Crear base de datos) cuando se crea el clúster.
De manera predeterminada, la opción Force the capacity change (Forzar cambio de capacidad) no está seleccionada. Deje esta opción desactivada para que la capacidad del clúster de base de datos de Aurora Serverless v1 permanezca sin cambios si la operación de escalado agota el tiempo de espera sin encontrar un punto de escalado.
Al elegir esta opción, el clúster de base de datos de Aurora Serverless v1 aplica el cambio de capacidad, incluso sin un punto de escalado. Antes de seleccionar esta opción, tenga en cuenta las consecuencias:
-
Cualquier transacción en proceso se interrumpe y aparece el siguiente mensaje de error.
Aurora MySQL versión 2:
ERROR 1105 (HY000): La última transacción se ha interrumpido debido a la escalación sin interrupciones. Vuelva a intentarlo.Podrá volver a enviar la transacción tan pronto como el clúster de bases de datos de Aurora Serverless v1 esté disponible.
-
Se eliminan las conexiones a las tablas y bloqueos temporales.
Recomendamos que elija la opción Force the capacity change (Forzar cambio de capacidad) solo si su aplicación puede recuperarse de conexiones caídas o transacciones incompletas.
Las opciones que elige en la AWS Management Console cuando crea un clúster de base de datos de Aurora Serverless v1 se almacenan en el objeto ScalingConfigurationInfo y en las propiedades SecondsBeforeTimeout y TimeoutAction. El valor de la propiedad TimeoutAction se establece en uno de los siguientes valores al crear el clúster:
-
RollbackCapacityChange: este valor se establece cuando se elige la opción Roll back the capacity change (Revertir el cambio de capacidad). Este es el comportamiento predeterminado. -
ForceApplyCapacityChange: este valor se establece cuando se elige la opción Force the capacity change (Forzar el cambio de capacidad).
Puede obtener el valor de esta propiedad en un clúster de bases de datos de Aurora Serverless v1 existente mediante el comando de la AWS CLI describe-db-clusters, como se muestra a continuación.
Para Linux, macOS o Unix:
aws rds describe-db-clusters --regionregion\ --db-cluster-identifieryour-cluster-name\ --query '*[].{ScalingConfigurationInfo:ScalingConfigurationInfo}'
Para Windows:
aws rds describe-db-clusters --regionregion^ --db-cluster-identifieryour-cluster-name^ --query "*[].{ScalingConfigurationInfo:ScalingConfigurationInfo}"
A modo de ejemplo, a continuación se muestra la consulta y la respuesta para un clúster de bases de datos de Aurora Serverless v1 denominado west-coast-sles en la región de EE. UU Oeste (N. California).
$aws rds describe-db-clusters --region us-west-1 --db-cluster-identifier west-coast-sles --query '*[].{ScalingConfigurationInfo:ScalingConfigurationInfo}' [ { "ScalingConfigurationInfo": { "MinCapacity": 1, "MaxCapacity": 64, "AutoPause": false, "SecondsBeforeTimeout": 300, "SecondsUntilAutoPause": 300, "TimeoutAction": "RollbackCapacityChange" } } ]
Como muestra la respuesta, este clúster de bases de datos de Aurora Serverless v1 utiliza la configuración predeterminada.
Para obtener más información, consulte Creación de un clúster de bases de datos de Aurora Serverless v1. Después de crear su Aurora Serverless v1, puede modificar la acción de tiempo de espera y otros ajustes de capacidad en cualquier momento. Para saber cómo hacerlo, consulte Modificación de un clúster de bases de datos de Aurora Serverless v1.
Pausar y reanudar Aurora Serverless v1
Puede optar por pausar el clúster de bases de datos de Aurora Serverless v1 después de transcurrido un tiempo determinado sin actividad. Usted especifica el periodo sin actividad que deberá transcurrir antes de poner en pausa el clúster de bases de datos. Al seleccionar esta opción, el tiempo de inactividad predeterminado es de cinco minutos, pero puede cambiar este valor. Se trata de una configuración opcional.
Cuando el clúster de bases de datos está en pausa, no se produce ningún tipo de actividad de computación ni de memoria y solamente se le cobra el almacenamiento. Si se solicitan conexiones a la base de datos mientras un clúster de bases de datos de Aurora Serverless v1 está en pausa, este clúster se reanuda automáticamente y atiende las solicitudes de conexión.
Cuando el clúster de bases de datos reanuda la actividad, tiene la misma capacidad que tenía cuando Aurora detuvo el clúster. El número de ACU depende de cuánto aumentó o redujo Aurora la escala del clúster antes de ponerlo en pausa.
nota
Si un clúster de bases de datos está en pausa durante más de siete días, puede hacerse una copia de seguridad de él mediante una instantánea. En este caso, Aurora restaura el clúster de bases de datos desde la instantánea cuando hay una solicitud para conectarse al mismo.
Determinación del número máximo de conexiones de base de datos para Aurora Serverless v1
Los siguientes ejemplos corresponden a un clúster de base de datos de Aurora Serverless v1 que es compatible con MySQL 5.7. Puede utilizar un cliente MySQL o el editor de consultas, si ha configurado el acceso a él. Para obtener más información, consulte Ejecución de consultas en el editor de consultas.
Para encontrar el número máximo de conexiones de base de datos
-
Busque el rango de capacidad de su cluster de base de datos de Aurora Serverless v1 mediante la AWS CLI.
aws rds describe-db-clusters \ --db-cluster-identifier my-serverless-57-cluster \ --query 'DBClusters[*].ScalingConfigurationInfo|[0]'El resultado muestra que su rango de capacidad es de 1 a 4 ACU.
{ "MinCapacity": 1, "AutoPause": true, "MaxCapacity": 4, "TimeoutAction": "RollbackCapacityChange", "SecondsUntilAutoPause": 3600 } -
Ejecute la siguiente consulta SQL para encontrar el número máximo de conexiones.
select @@max_connections;El resultado mostrado es para la capacidad mínima del clúster, 1 ACU.
@@max_connections 90 -
Escale el clúster de 8 a 32 ACU.
Para obtener más información sobre el escalado, consulte Modificación de un clúster de bases de datos de Aurora Serverless v1.
-
Confirme el rango de capacidad.
{ "MinCapacity": 8, "AutoPause": true, "MaxCapacity": 32, "TimeoutAction": "RollbackCapacityChange", "SecondsUntilAutoPause": 3600 } -
Busque el número máximo de conexiones.
select @@max_connections;El resultado mostrado corresponde a la capacidad mínima del clúster, 8 ACU.
@@max_connections 1000 -
Escale el clúster al máximo posible, 256 a 256 ACU.
-
Confirme el rango de capacidad.
{ "MinCapacity": 256, "AutoPause": true, "MaxCapacity": 256, "TimeoutAction": "RollbackCapacityChange", "SecondsUntilAutoPause": 3600 } -
Busque el número máximo de conexiones.
select @@max_connections;El resultado mostrado corresponde a 256 ACU.
@@max_connections 6000nota
El valor de
max_connectionsno se escala linealmente con el número de ACU. -
Vuelva a escalar el clúster a 1 a 4 ACU.
{ "MinCapacity": 1, "AutoPause": true, "MaxCapacity": 4, "TimeoutAction": "RollbackCapacityChange", "SecondsUntilAutoPause": 3600 }Esta vez, el valor de
max_connectionscorresponde a 4 ACU.@@max_connections 270 -
Vuelva a reducir verticalmente el clúster a 2 ACU.
@@max_connections 180Si ha configurado el clúster para que se detenga después de un tiempo de inactividad, se reduce verticalmente a 0 ACU. Sin embargo,
max_connectionsno cae por debajo del valor de 1 ACU.@@max_connections 90
Grupos de parámetros de Aurora Serverless v1
Cuando crea el clúster de bases de datos de Aurora Serverless v1, elige un motor de base de datos de Aurora y un grupo de parámetros de clúster de bases de datos asociado. A diferencia de los clústeres de base de datos aprovisionados de Aurora, un clúster de bases de datos de Aurora Serverless v1 tiene una única instancia de base de datos de lectura y escritura configurada con un grupo de parámetros de clúster de bases de datos— no tiene un grupo de parámetros de base de datos aparte. Durante el escalado automático, Aurora Serverless v1 necesita poder cambiar los parámetros para que el clúster funcione mejor para el aumento o la disminución de la capacidad. Por lo tanto, con un clúster de base de datos de Aurora Serverless v1, es posible que no se apliquen algunos de los cambios que puede realizar en los parámetros de un tipo de motor de base de datos determinado.
Por ejemplo, un clúster de bases de datos de Aurora Serverless v1 basado en –Aurora PostgreSQL no puede usar apg_plan_mgmt.capture_plan_baselines ni otros parámetros que podrían utilizarse en clústeres de base de datos de Aurora PostgreSQL para la administración del plan de consultas.
Puede obtener una lista de valores predeterminados de los grupos de parámetros predeterminados para los diferentes motores de base de datos de Aurora mediante el comando describe-engine-default-cluster-parameters de la CLI y consultando la Región de AWS. Estos son los valores que puede utilizar para la opción --db-parameter-group-family.
|
Aurora MySQL versión 2 |
|
|
Aurora PostgreSQL versión 11 |
|
|
Aurora PostgreSQL versión 13 |
|
Recomendamos que configure la AWS CLI con su ID de clave de acceso de AWS y la clave de acceso secreta de AWS y que establezca su Región de AWS antes de usar los comandos de la AWS CLI. Si proporciona la región a la configuración de la CLI, se evita ingresar al parámetro --region cuando ejecuta comandos. Para obtener más información sobre cómo configurar la AWS CLI, consulte Conceptos básicos de la configuración en la Guía del usuario de AWS Command Line Interface.
En el ejemplo siguiente, se obtiene una lista de parámetros del grupo de clústeres de base de datos predeterminado para la versión 2 de Aurora MySQL.
Para Linux, macOS o Unix:
aws rds describe-engine-default-cluster-parameters \ --db-parameter-group-family aurora-mysql5.7 --query \ 'EngineDefaults.Parameters[*].{ParameterName:ParameterName,SupportedEngineModes:SupportedEngineModes} | [?contains(SupportedEngineModes, `serverless`) == `true`] | [*].{param:ParameterName}' \ --output text
Para Windows:
aws rds describe-engine-default-cluster-parameters ^ --db-parameter-group-family aurora-mysql5.7 --query ^ "EngineDefaults.Parameters[*].{ParameterName:ParameterName,SupportedEngineModes:SupportedEngineModes} | [?contains(SupportedEngineModes, 'serverless') == `true`] | [*].{param:ParameterName}" ^ --output text
Modificar los valores de parámetros para Aurora Serverless v1
Como se explica en Grupos de parámetros para Amazon Aurora, no puede cambiar directamente los valores de un grupo de parámetros predeterminado, independientemente de su tipo (grupo de parámetros de clúster de bases de datos, grupo de parámetros de base de datos). En su lugar, se crea un grupo de parámetros personalizado basado en el grupo de parámetros de clúster de bases de datos predeterminado para su motor de base de datos de Aurora y se cambia la configuración según sea necesario en ese grupo de parámetros. Por ejemplo, es posible que desee cambiar algunos de los ajustes de su clúster de bases de datos de Aurora Serverless v1 para registrar consultas o cargar registros específicos del motor de base de datos a Amazon CloudWatch.
Para crear un grupo de parámetros de clúster de bases de datos personalizado
-
Inicie sesión en AWS Management Console y abra la consola de Amazon RDS en https://console.aws.amazon.com/rds/
. -
Elija Parameter groups (Grupos de parámetros).
-
Elija Create parameter group (Crear grupo de parámetros) para abrir el panel “Parameter group details (Detalles del grupo de parámetros)”.
-
Elija el grupo de clúster de bases de datos predeterminado adecuado para el motor de base de datos que desea utilizar para su clúster de bases de datos de Aurora Serverless v1. Asegúrese de elegir las siguientes opciones:
-
En Parameter group family (Familia de grupos de parámetros), elija la familia adecuada para el motor de base de datos elegido. Asegúrese de que su selección tenga el prefijo
aurora-en el nombre. -
En Type (Tipo), elija DB Cluster Parameter Group (Grupo de parámetros de clúster de bases de datos).
-
En Group name (Nombre de grupo) y Description (Descripción), escriba nombres significativos para usted u otras personas que puedan necesitar trabajar con el clúster de bases de datos de Aurora Serverless v1 y sus parámetros.
-
Seleccione Create (Crear).
-
El grupo de parámetros de clúster de base de datos personalizado se añade a la lista de grupos de parámetros disponibles en su Región de AWS. Puede utilizar su grupo de parámetros de clúster de base de datos personalizado al crear nuevos clústeres de base de datos de Aurora Serverless v1. También puede modificar un clúster de base de datos de Aurora Serverless v1 existente para utilizar su grupo de parámetros de clúster de base de datos personalizado. Cuando su clúster de base de datos de Aurora Serverless v1 comienza a utilizar el grupo de parámetros de clúster de base de datos personalizado, puede cambiar los valores de los parámetros dinámicos mediante la AWS Management Console o la AWS CLI.
También puede utilizar la consola para ver una comparación paralela de los valores del grupo de parámetros de clúster de base de datos personalizado y el grupo de parámetros de clúster de base de datos predeterminado, como se muestra en la siguiente captura de pantalla.
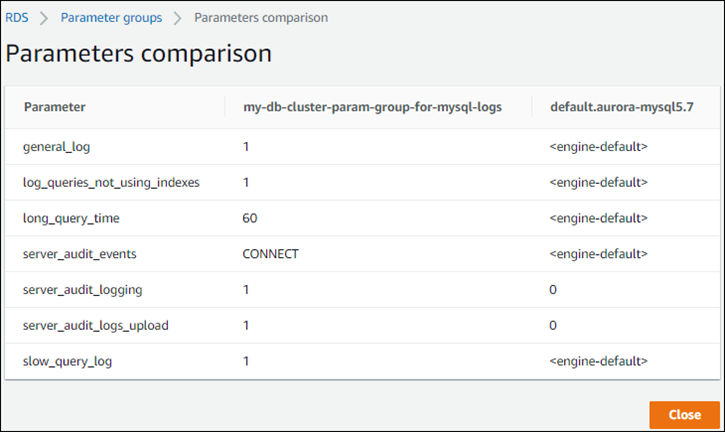
Cuando cambia los valores de los parámetros en un clúster de bases de datos activo, Aurora Serverless v1 inicia un escalado perfecto para aplicar los cambios de parámetro. Si el clúster de base de datos de Aurora Serverless v1 está en un estado en pausa, se reanuda y comienza a escalarse para que pueda realizar el cambio. La operación de escalado para un cambio de grupo de parámetros siempre fuerza el cambio de capacidad , así que tenga en cuenta que la modificación de los parámetros podría causar caídas en la conexión si no se puede encontrar un punto de escalado durante el periodo de escalado.
Registros en Aurora Serverless v1
De forma predeterminada, los registros de errores están habilitados para Aurora Serverless v1 y se cargan automáticamente a Amazon CloudWatch. También puede hacer que su clúster de base de datos de Aurora Serverless v1 cargue los registros específicos del motor de base de datos de Aurora en CloudWatch Para ello, habilite los parámetros de configuración en el grupo de parámetros del clúster de base de datos personalizado. Su clúster de base de datos de Aurora Serverless v1 carga todos los registros disponibles en Amazon CloudWatch. En este punto, Amazon CloudWatch le permite analizar los datos de registro, crear alarmas y ver métricas.
Para Aurora MySQL, la siguiente tabla muestra los registros que puede habilitar. Cuando se habilitan, se cargan automáticamente desde su clúster de base de datos de Aurora Serverless v1 a Amazon CloudWatch.
| Registro de Aurora MySQL | Descripción |
|---|---|
|
|
Crea el registro general. Se establece en 1 para activarlo. El valor predeterminado es desactivado (0). |
|
|
Registra todas las consultas en el registro de consultas lentas que no utilizan un índice. El valor predeterminado es desactivado (0). Se establece en 1 para activar este registro. |
|
|
Evita que las consultas de ejecución rápida se registren en el registro de consultas lentas. Se puede establecer en un número flotante entre 0 y 3,1536,000. El valor predeterminado es 0 (no activo). |
|
|
La lista de eventos que se deben capturar en los registros. Los valores admitidos son |
|
|
Se establece en 1 para activar el registro de auditoría del servidor. Si activa esta opción, puede especificar los eventos de auditoría que se enviarán a CloudWatch enumerándolos en el parámetro de |
|
|
Crea un registro de consulta lento. Se establece en 1 para activar el registro de consultas lentas. El valor predeterminado es desactivado (0). |
Para obtener más información, consulte Uso de auditorías avanzadas con un clúster de base de datos de Amazon Aurora MySQL.
Para Aurora PostgreSQL, la siguiente tabla muestra los registros que puede habilitar. Cuando se habilitan, se cargan automáticamente desde su clúster de base de datos de Aurora Serverless v1 a Amazon CloudWatch junto con los registros de errores regulares.
| Registro de Aurora PostgreSQL | Descripción |
|---|---|
|
|
Activado de forma predeterminada y no se puede cambiar. Registra los detalles de todas las conexiones de cliente nuevas. |
|
|
Activado de forma predeterminada y no se puede cambiar. Registra todas las desconexiones de cliente. |
|
|
Desactivado de forma predeterminada y no se puede cambiar. Los nombres de host no se registran. |
|
|
El valor predeterminado es 0 (desactivado). Se establece en 1 para registrar las esperas de bloqueo. |
|
|
La duración mínima (en milisegundos) para que una instrucción se ejecute antes de que se registre. |
|
|
Define los niveles de los mensajes que se registran. Los valores admitidos son Para registrar los datos de rendimiento en el registro de |
|
|
Registra el uso de archivos temporales que superan los kilobytes especificados (kB). |
|
|
Controla las instrucciones SQL específicas que se registran. Los valores admitidos son |
Después de activar los registros para Aurora MySQL o Aurora PostgreSQL para su clúster de base de datos de Aurora Serverless v1, puede ver los registros en CloudWatch.
Visualización registros de Aurora Serverless v1 con Amazon CloudWatch
Aurora Serverless v1 carga automáticamente ("publica") en Amazon CloudWatch todos los registros habilitados en el grupo de parámetros de clúster de bases de datos personalizado. No es necesario elegir o especificar los tipos de registro. La carga de registros se inicia tan pronto como se habilita el parámetro de configuración del registro. Si posteriormente deshabilita el parámetro de registro, las cargas futuras se detienen. Sin embargo, todos los registros que ya se hayan publicado en CloudWatch permanecerán hasta que los elimine.
Para obtener más información acerca de cómo usar CloudWatch con registros de Aurora MySQL, consulte Monitoreo de eventos de registro en Amazon CloudWatch.
Para obtener más información sobre CloudWatch y Aurora PostgreSQL, consulte Publicación de registros de Aurora PostgreSQL en Amazon CloudWatch Logs.
Para ver los registros del clúster de bases de datos de Aurora Serverless v1
Abra la consola de CloudWatch en https://console.aws.amazon.com/cloudwatch/
. -
Elija su Región de AWS.
-
Elija Log groups (Grupos de registros).
-
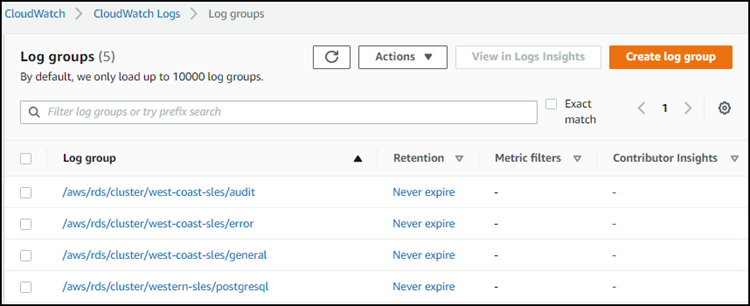
Seleccione el registro del clúster de bases de datos de Aurora Serverless v1 de la lista. Para los registros de errores, el patrón de nomenclatura es el siguiente.
/aws/rds/cluster/cluster-name/error
Por ejemplo, en la siguiente captura de pantalla encontrará descripciones de registros publicados para un clúster de base de datos de Aurora Serverless v1 de Aurora PostgreSQL llamado western-sles. También puede encontrar varias descripciones del clúster de base de datos de Aurora Serverless v1 de Aurora MySQL, west-coast-sles. Elija el registro que le interesa para empezar a explorar su contenido.
Aurora Serverless v1 y mantenimiento
El mantenimiento del clúster de base de datos de Aurora Serverless v1, como la aplicación de las últimas características, correcciones y actualizaciones de seguridad, se realiza automáticamente. Aurora Serverless v1 tiene un periodo de mantenimiento que puede consultar en la AWS Management Console, en Mantenimiento y copias de seguridad, para su clúster de base de datos de Aurora Serverless v1. Puede encontrar la fecha y la hora en que se puede realizar el mantenimiento y si hay algún mantenimiento pendiente para su clúster de bases de datos de Aurora Serverless v1, como se muestra en la siguiente figura.
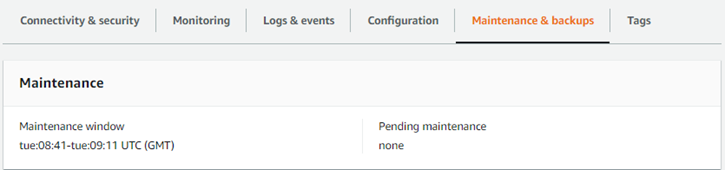
Puede configurar el periodo de mantenimiento al crear el clúster de base de datos de Aurora Serverless v1 y modificarlo posteriormente. Para obtener más información, consulte Ajuste de la ventana de mantenimiento preferida para un clúster de base de datos.
Los periodos de mantenimiento se utilizan para las actualizaciones programadas de las versiones principales. Las actualizaciones de versiones secundarias y las revisiones se aplican inmediatamente durante el escalado. El escalado se realiza de acuerdo con la configuración establecida para TimeoutAction:
-
ForceApplyCapacityChange: el cambio se aplica inmediatamente. -
RollbackCapacityChange: Aurora actualiza el clúster de manera forzada 3 días después del primer intento de aplicación de la revisión.
Al igual que con cualquier cambio forzado sin un punto de escalado apropiado, esto podría interrumpir la carga de trabajo.
Cuando es posible, Aurora Serverless v1 realiza el mantenimiento de una manera no disruptiva. Cuando se requiere mantenimiento, el clúster de bases de datos de Aurora Serverless v1 escala su capacidad para gestionar las operaciones necesarias. Antes de escalar, Aurora Serverless v1 busca un punto de escalado. Lo hace durante un máximo de tres días, si es necesario.
Al final de cada día que Aurora Serverless v1 no puede encontrar un punto de escalado, crea un evento de clúster. Este evento lo notifica sobre el mantenimiento pendiente y la necesidad de escalar para realizar el mantenimiento. La notificación incluye la fecha en la que Aurora Serverless v1 puede forzar al clúster de base de datos para que se escale.
Para obtener más información, consulte Acción de tiempo de espera para cambios de capacidad.
Aurora Serverless v1 y conmutación por error
Si la instancia de base de datos de un clúster de base de datos de Aurora Serverless v1 deja de estar disponible o se produce un error en la zona de disponibilidad (AZ) en la que se encuentra, Aurora vuelve a crear la instancia de base de datos en una AZ diferente. Sin embargo, el clúster de Aurora Serverless v1 no es un clúster Multi-AZ. Esto se debe a que consta de una única instancia de base de datos en una sola AZ. Por tanto, el mecanismo de conmutación por error tarda más que en un clúster de Aurora con instancias aprovisionadas o de Aurora Serverless v2. El tiempo de conmutación por error de Aurora Serverless v1 está sin definir, ya que depende de la demanda y de la disponibilidad de capacidad de otras zonas de disponibilidad de la Región de AWS específica.
Debido a que Aurora separa la capacidad de computación y el almacenamiento, el volumen de almacenamiento para el clúster se distribuye por varias AZ. Sus datos permanecen disponibles si alguna interrupción afecta la instancia de base de datos o la AZ asociada.
Aurora Serverless v1 e instantáneas
El volumen de un clúster de Aurora Serverless v1 siempre está cifrado. Puede elegir la clave de cifrado, pero no puede desactivar el cifrado. Para copiar o compartir una instantánea de un clúster de Aurora Serverless v1, cifre la instantánea mediante su propia AWS KMS key. Para obtener más información, consulte Copia de una instantánea de clúster de base de datos. Para obtener más información sobre el cifrado y Amazon Aurora, consulte Cifrar un clúster de bases de datos de Amazon Aurora
