Uso de machine learning de Amazon Aurora con Aurora PostgreSQL
Al utilizar el machine learning de Amazon Aurora con su clúster de base de datos de Aurora PostgreSQL, puede utilizar Amazon Comprehend, IA de Amazon SageMaker o Amazon Bedrock, según sus necesidades. Cada uno de estos servicios admite casos de uso de machine learning específicos.
El machine learning de Aurora se admite en determinadas Regiones de AWS y solo para versiones de Aurora PostgreSQL. Antes de intentar configurar el machine learning de Aurora, compruebe la disponibilidad para su versión de Aurora PostgreSQL y su región. Para obtener más información, consulte Machine learning de Aurora con Aurora PostgreSQL.
Temas
Requisitos para usar machine learning de Aurora con Aurora PostgreSQL
Funciones y limitaciones compatibles del machine learning de Aurora con Aurora PostgreSQL
Uso de Amazon Bedrock con el clúster de base de datos de Aurora PostgreSQL
Uso de Amazon Comprehend con el clúster de base de datos de Aurora PostgreSQL
Uso de IA de SageMaker con el clúster de base de datos de Aurora PostgreSQL
Exportación de datos a Amazon S3 para el entrenamiento de modelos de IA de SageMaker (avanzado)
Requisitos para usar machine learning de Aurora con Aurora PostgreSQL
AWSLos servicios de machine learning de son servicios administrados que se configuran y ejecutan en sus propios entornos de producción. El machine learning de Aurora admite la integración con Amazon Comprehend, IA de SageMaker y Amazon Bedrock. Antes de intentar configurar el clúster de base de datos de Aurora PostgreSQL para usar el machine learning de Aurora, asegúrese de comprender los siguientes requisitos y requisitos previos.
Los servicios Amazon Comprehend, IA de SageMaker y Amazon Bedrock deben ejecutarse en la misma Región de AWS que el clúster de base de datos de Aurora PostgreSQL. No puede usar los servicios de Amazon Comprehend, IA de SageMaker o Amazon Bedrock desde un clúster de base de datos de Aurora PostgreSQL en una región diferente.
Si su clúster de base de datos de Aurora PostgreSQL se encuentra en una nube pública virtual (VPC) diferente basada en el servicio Amazon VPC que los servicios Amazon Comprehend e IA de SageMaker, el grupo de seguridad de la VPC debe permitir las conexiones salientes al servicio de machine learning de Aurora de destino. Para obtener más información, consulte Habilitación de la comunicación de red desde Amazon Aurora a otros servicios de AWS.
Para IA de SageMaker, los componentes de machine learning que desee usar para las inferencias deben estar configurados y listos para usarse. Durante el proceso de configuración del clúster de base de datos Aurora PostgreSQL, debe tener disponible el nombre de recurso de Amazon (ARN) del punto de conexión de IA de SageMaker. Es probable que los científicos de datos de su equipo sean los más capacitados para trabajar con IA de SageMaker para preparar los modelos y gestionar otras tareas similares. Para empezar a utilizar IA de Amazon SageMaker, consulte Get Started with Amazon SageMaker AI. Para obtener más información sobre inferencias y puntos de conexión, consulte Inferencia en tiempo real.
-
Para Amazon Bedrock, debe tener disponible el ID de modelo de los modelos de Bedrock que desee utilizar para las inferencias durante el proceso de configuración del clúster de base de datos de Aurora PostgreSQL. Es probable que los científicos de datos de su equipo sean los más capacitados para trabajar con Bedrock y decidir qué modelos utilizar, ajustarlos si es necesario y gestionar otras tareas similares. Para empezar a usar Amazon Bedrock, consulte Cómo configurar Bedrock.
-
Los usuarios de Amazon Bedrock deben solicitar acceso a los modelos para que estén disponibles para su uso. Si desea agregar modelos adicionales para la generación de texto, chat e imágenes, debe solicitar el acceso a los modelos de Amazon Bedrock. Para obtener más información, consulte Acceso a modelos.
Funciones y limitaciones compatibles del machine learning de Aurora con Aurora PostgreSQL
El machine learning de Aurora admite los puntos de conexión de IA de SageMaker que puedan leer y escribir el formato de valores separados por comas (CSV), a través de un valor ContentType de text/csv. Los algoritmos incorporados de IA de SageMaker que actualmente aceptan este formato son los siguientes.
Linear Learner
Random Cut Forest
XGBoost
Para obtener más información sobre estos algoritmos, consulte Choose an Algorithm en la Guía para desarrolladores de IA de Amazon SageMaker.
Al usar Amazon Bedrock con el machine learning de Aurora, se aplican las siguientes limitaciones:
-
Las funciones definidas por el usuario (UDF) proporcionan una forma nativa de interactuar con Amazon Bedrock. Las UDF no tienen requisitos específicos de solicitud o respuesta, por lo que pueden utilizar cualquier modelo.
-
Puede utilizar las UDF para crear cualquier flujo de trabajo que desee. Por ejemplo, puede combinar primitivas básicas, como
pg_cron, para ejecutar una consulta, obtener datos, generar inferencias y escribir en tablas para servir las consultas directamente. -
Las UDF no admiten llamadas por lotes o paralelas.
-
La extensión de Aurora Machine Learning no admite interfaces vectoriales. Como parte de la extensión, hay una función disponible para generar las incrustaciones de la respuesta del modelo en el formato
float8[]para almacenar esas incrustaciones en Aurora. Para obtener más información sobre el uso defloat8[], consulte Uso de Amazon Bedrock con el clúster de base de datos de Aurora PostgreSQL.
Configuración del clúster de base de datos Aurora PostgreSQL para utilizar el machine learning de Aurora
Para que el machine learning de Aurora funcione con su clúster de base de datos de Aurora PostgreSQL, debe crear un rol de AWS Identity and Access Management (IAM) para cada uno de los servicios que desee utilizar. El rol de IAM permite que el clúster de base de datos de Aurora PostgreSQL utilice el servicio de machine learning de Aurora en nombre del clúster. También debe instalar la extensión de machine learning de Aurora. En los siguientes temas, puede encontrar los procedimientos de configuración para cada uno de estos servicios de machine learning de Aurora.
Temas
Configuración de Aurora PostgreSQL para usar Amazon Bedrock
En el procedimiento siguiente, primero debe crear la política y el rol de IAM que otorgan a Aurora PostgreSQL el permiso para usar Amazon Bedrock en nombre del clúster. A continuación, adjunte la política a un rol de IAM que el clúster de base de datos Aurora PostgreSQL utilice para trabajar con Amazon Bedrock. Por motivos de simplicidad, este procedimiento utiliza la AWS Management Console para completar todas las tareas.
Para configurar el clúster de base de datos de Aurora PostgreSQL para utilizar Amazon Bedrock
Inicie sesión en AWS Management Console y abra la consola IAM en https://console.aws.amazon.com/iam/
. Abra la consola de IAM en https://console.aws.amazon.com/iam/
. Elija Políticas (en Administración de acceso) en el menú de la consola de AWS Identity and Access Management (IAM).
Elija Crear política. En la página del editor visual, elija Servicio y, a continuación, escriba Bedrock en el campo de selección de servicio. Expanda el nivel de acceso de lectura. Elija InvokeModel en la configuración de lectura de Amazon Bedrock.
Elija el modelo fundacional o aprovisionado al que desee conceder el acceso de lectura a través de la política.
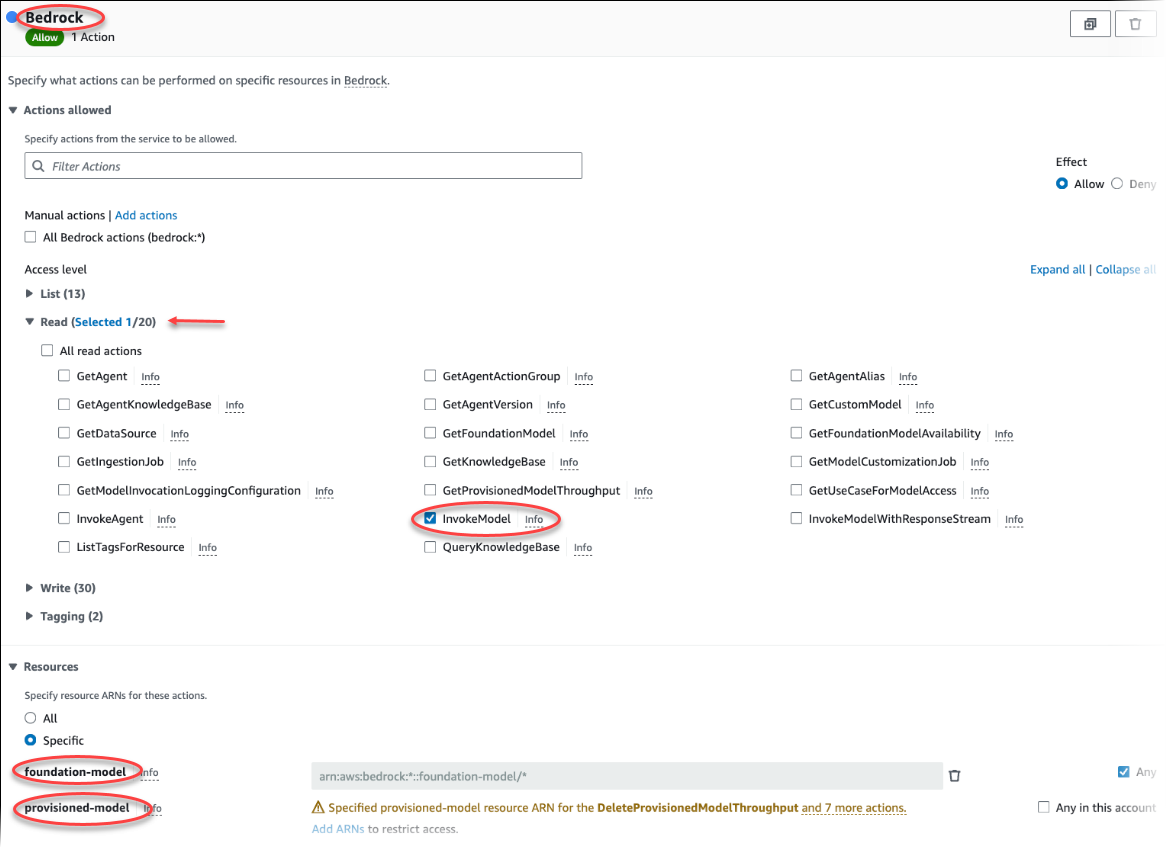
Elija Siguiente: Etiquetas y defina las etiquetas que desee (esto es opcional). Elija Siguiente: Revisar. Introduzca un nombre para la política y una descripción, como se muestra en la imagen.
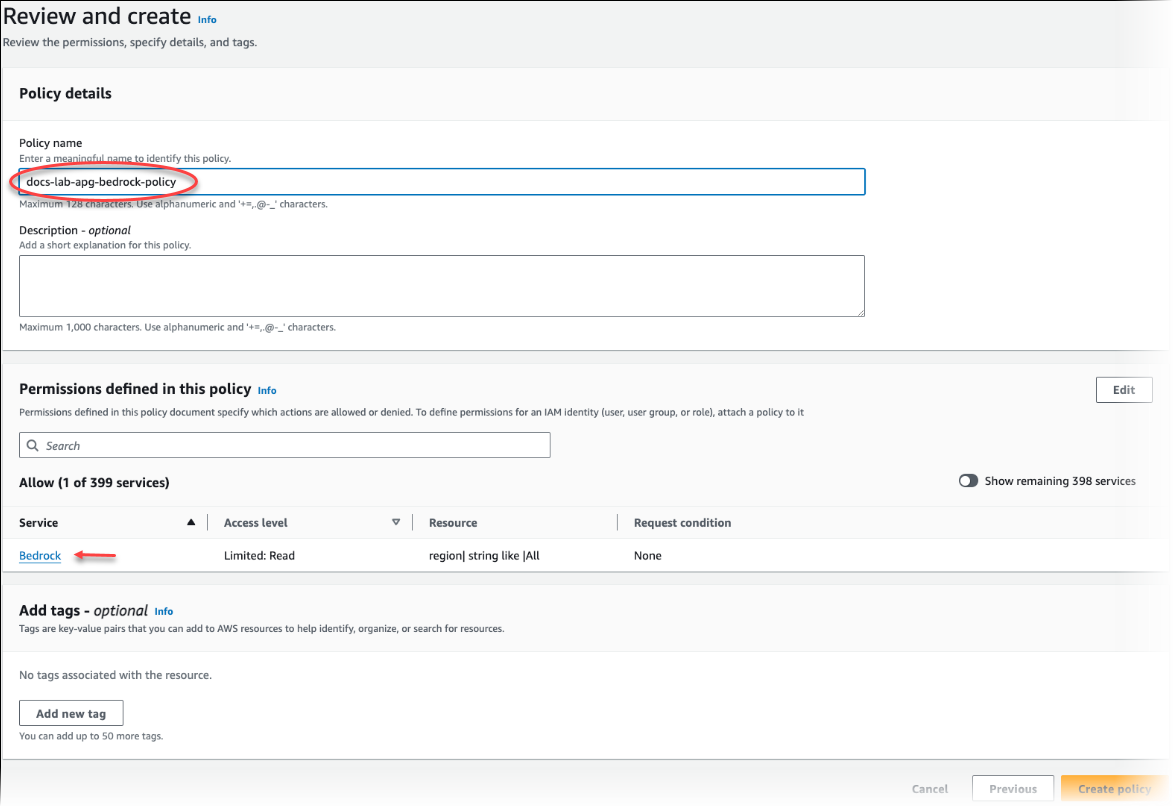
Elija Crear política. La consola muestra una alerta cuando se guarda la política. Puede encontrarla en la lista de políticas.
Elija Roles (en Administración de acceso) en el menú de la consola de IAM.
Elija Creación de rol.
En la página Seleccionar entidad de confianza, elija el mosaico de servicio de AWS y, a continuación, elija RDS para abrir el selector.
Elija RDS: Añadir rol a la base de datos.
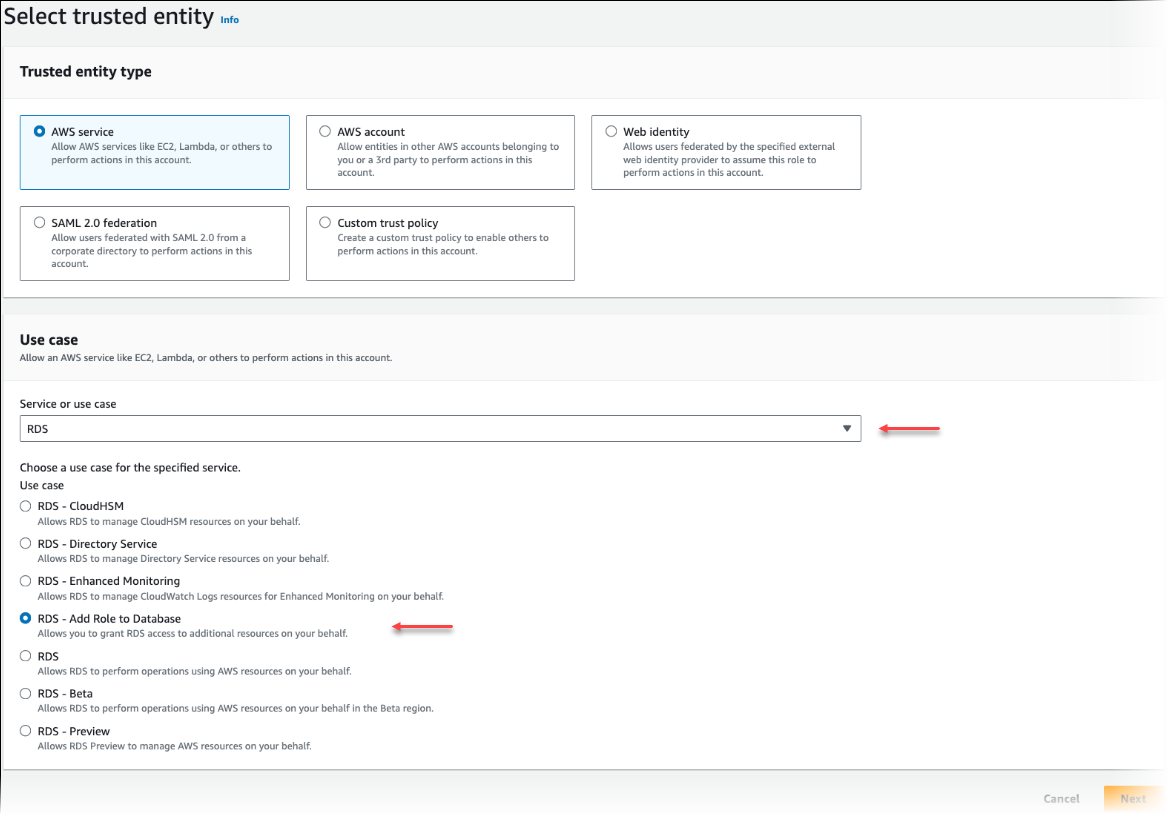
Elija Siguiente. En la página Añadir permisos, busque la política que creó en el paso anterior y la elija de entre las de la lista. Elija Siguiente.
Siguiente: Revisar. Introduzca un nombre y la descripción del rol de IAM.
Abra la consola de Amazon RDS en https://console.aws.amazon.com/rds/
. Vaya hasta la Región de AWS donde se encuentra el clúster de base de datos de Aurora PostgreSQL.
-
En el panel de navegación, elija Bases de datos y, a continuación, elija el clúster de base de datos Aurora PostgreSQL que desea utilizar con Bedrock.
-
En la pestaña Conectividad y seguridad y desplácese hasta la sección Administrar roles de IAM de la página. En el selector Añadir roles de IAM a este clúster, elija el rol que creó en los pasos anteriores. En el selector Característica, elija Bedrock y, a continuación, seleccione Añadir rol.
El rol (con su política) está asociado al clúster de base de datos de Aurora PostgreSQL. Cuando el proceso se completa, el rol aparece en la lista de roles de IAM actuales para este clúster, como se muestra a continuación.
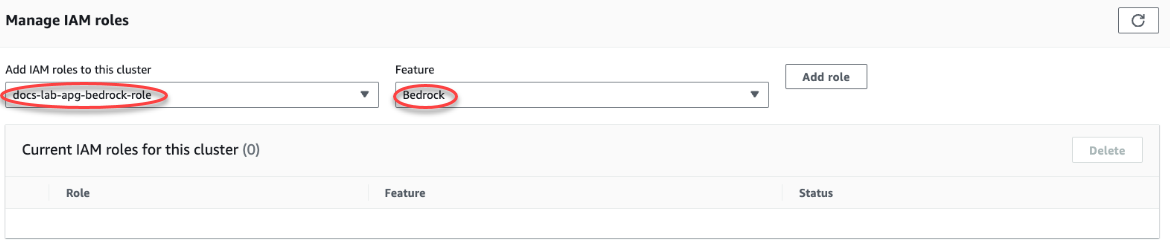
La configuración de IAM para Amazon Bedrock está completa. Siga configurando Aurora PostgreSQL para que funcione con el machine learning de Aurora. Para ello, instale la extensión tal y como se detalla en Instalación de la extensión de machine learning de Aurora
Configuración de Aurora PostgreSQL para usar Amazon Comprehend
En el procedimiento siguiente, primero debe crear la política y el rol de IAM que otorgan a Aurora PostgreSQL el permiso para usar Amazon Comprehend en nombre del clúster. A continuación, adjunte la política a un rol de IAM que el clúster de base de datos de Aurora PostgreSQL utiliza para trabajar con Amazon Comprehend. Por motivos de simplicidad, este procedimiento utiliza la AWS Management Console para completar todas las tareas.
Para configurar el clúster de base de datos de Aurora PostgreSQL para utilizar Amazon Comprehend
Inicie sesión en AWS Management Console y abra la consola IAM en https://console.aws.amazon.com/iam/
. Abra la consola de IAM en https://console.aws.amazon.com/iam/
. Elija Policies (Políticas) (en Administración de acceso) en el menú de la consola de AWS Identity and Access Management (IAM).
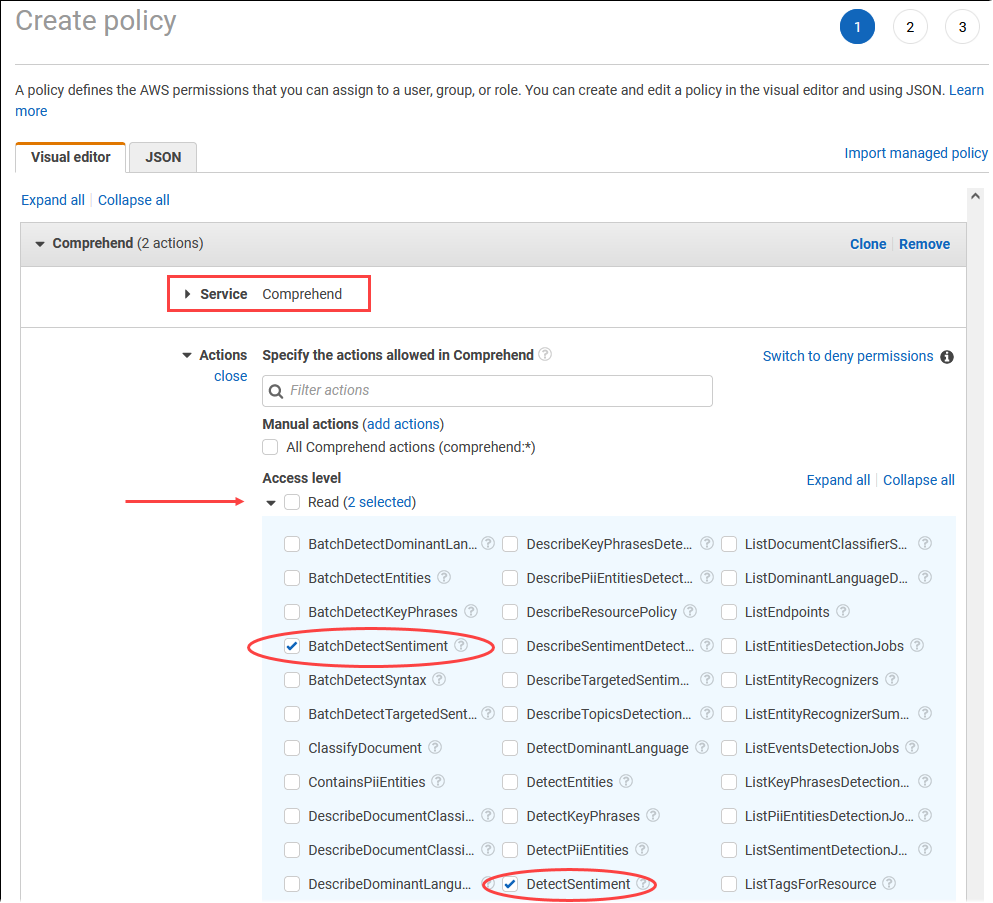
Elija Crear política. En la página del editor visual, elija Service (Servicio) y, a continuación, escriba Comprehend en el campo de selección de servicio. Expanda el nivel de acceso de lectura. Elija BatchDetectSentiment y DetectSentiment en la configuración de lectura de Amazon Comprehend
Elija Next: Tags (Siguiente: Etiquetas )y defina las etiquetas que desee (esto es opcional). Elija Siguiente: Revisar. Introduzca un nombre para la política y una descripción, como se muestra en la imagen.
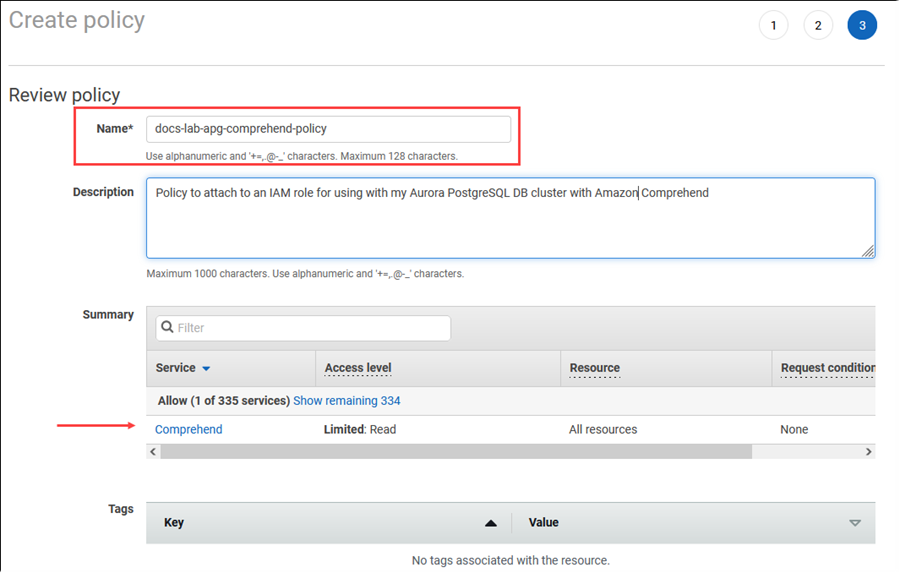
Elija Create Policy (Crear política). La consola muestra una alerta cuando se guarda la política. Puede encontrarla en la lista de políticas.
Elija Roles (en Administración de acceso) en el menú de la consola de IAM.
Elija Creación de rol.
En la página Seleccionar entidad de confianza, elija el mosaico de servicio de AWS y, a continuación, elija RDS para abrir el selector.
Elija RDS – Add Role to Database (RDS: Añadir rol a la base de datos).
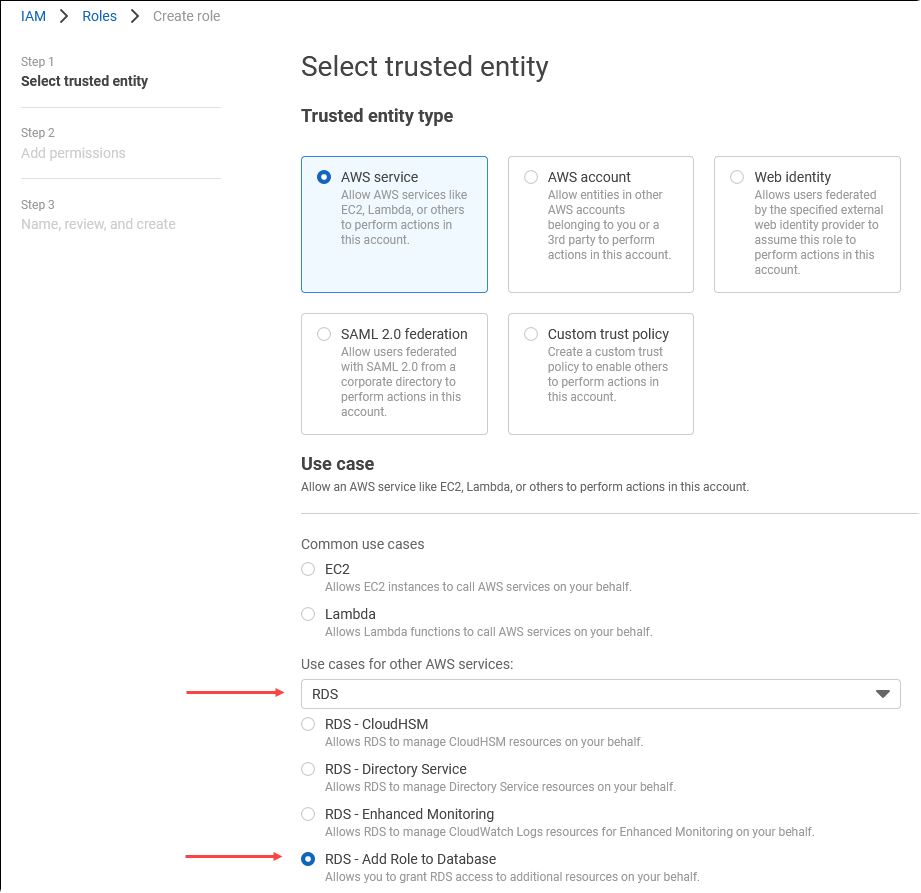
Elija Siguiente. En la página Añadir permisos, busque la política que creó en el paso anterior y la elija de entre las de la lista. Elija Siguiente.
Siguiente: Revisar. Introduzca un nombre y la descripción del rol de IAM.
Abra la consola de Amazon RDS en https://console.aws.amazon.com/rds/
. Vaya hasta la Región de AWS donde se encuentra el clúster de base de datos de Aurora PostgreSQL.
-
En el panel de navegación, elija Databases (Bases de datos) y, a continuación, elija el clúster de base de datos Aurora PostgreSQL que desea utilizar con Amazon Comprehend.
-
En la pestaña Connectivity & Security (Conectividad y seguridad) y desplácese hasta la sección Manage IAM roles (Administrar roles de IAM) de la página. En el selector Añadir roles de IAM a este clúster, elija el rol que creó en los pasos anteriores. En el selector Característica, elija Comprehend y, a continuación, seleccione Agregar rol.
El rol (con su política) está asociado al clúster de base de datos de Aurora PostgreSQL. Cuando el proceso se completa, el rol aparece en la lista de roles de IAM actuales para este clúster, como se muestra a continuación.
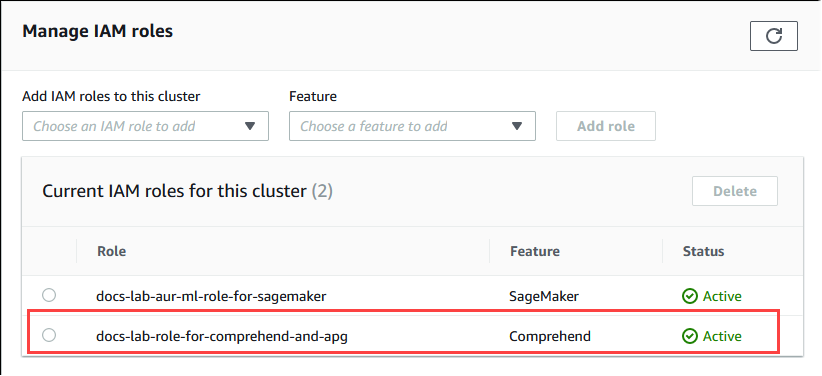
La configuración de IAM para Amazon Comprehend está completa. Siga configurando Aurora PostgreSQL para que funcione con el machine learning de Aurora. Para ello, instale la extensión tal y como se detalla en Instalación de la extensión de machine learning de Aurora
Configuración de Aurora PostgreSQL para usar IA de Amazon SageMaker
Antes de poder crear la política y el rol de IAM para su clúster de base de datos de Aurora PostgreSQL, debe tener la configuración del modelo de IA de SageMaker y su punto de conexión disponible.
Configuración del clúster de base de datos Aurora PostgreSQL para que utilice IA de SageMaker
Inicie sesión en AWS Management Console y abra la consola IAM en https://console.aws.amazon.com/iam/
. Elija Policies (Políticas) (en Administración de acceso) en el menú de la consola de AWS Identity and Access Management (IAM) y, a continuación, elija Create policy (Crear política). En el editor visual, elija SageMaker para el servicio. Para Actions (Acciones), abra el selector de lectura (en el nivel de acceso) y elija InvokeEndpoint. Al hacer esto, aparece un icono de advertencia.
Abra el selector de recursos y elija el enlace Agregar ARN para restringir el acceso en la sección Especificar el ARN del recurso de punto de conexión para la acción InvokeEndpoint.
Introduzca la Región de AWS de los recursos de IA de SageMaker y el nombre de su punto de conexión. Su cuenta de AWS ya está precargada.
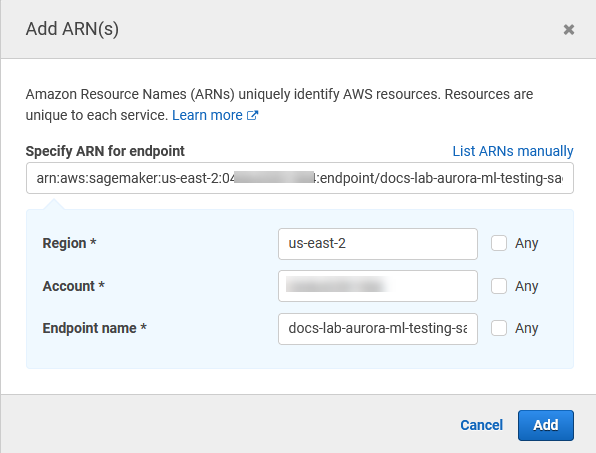
Seleccione Añadir para guardar. Elija Siguiente: Etiquetas y Siguiente: Revisar para ir a la última página del proceso de creación de políticas.
Escriba un nombre y una descripción para esta política y, a continuación, elija Crear política. La política se crea y se añade a la lista de políticas. Verá una alerta en la consola cuando esto ocurre.
En la consola de IAM, seleccione Roles.
Elija Create role (Crear rol).
En la página Seleccionar entidad de confianza, elija el mosaico de servicio de AWS y, a continuación, elija RDS para abrir el selector.
Elija RDS: Añadir rol a la base de datos.
Elija Siguiente. En la página Añadir permisos, busque la política que creó en el paso anterior y la elija de entre las de la lista. Elija Siguiente.
Siguiente: Revisar. Introduzca un nombre y la descripción del rol de IAM.
Abra la consola de Amazon RDS en https://console.aws.amazon.com/rds/
. Vaya hasta la Región de AWS donde se encuentra el clúster de base de datos de Aurora PostgreSQL.
-
En el panel de navegación, elija Bases de datos y, a continuación, elija el clúster de base de datos Aurora PostgreSQL que desea utilizar con IA de SageMaker.
-
En la pestaña Conectividad y seguridad y desplácese hasta la sección Administrar roles de IAM de la página. En el selector Añadir roles de IAM a este clúster, elija el rol que creó en los pasos anteriores. En el selector de Característica, elija IA de SageMaker y después seleccione Añadir rol.
El rol (con su política) está asociado al clúster de base de datos de Aurora PostgreSQL. Cuando el proceso se completa, el rol aparece en la lista de roles de IAM actuales para esta lísta de clúster.
La configuración de IAM para IA de SageMaker está completa. Siga configurando Aurora PostgreSQL para que funcione con el machine learning de Aurora. Para ello, instale la extensión tal y como se detalla en Instalación de la extensión de machine learning de Aurora
Configuración de Aurora PostgreSQL para usar Amazon S3 para IA de SageMaker (avanzado)
Para utilizar IA de SageMaker con sus propios modelos en lugar de utilizar los componentes prediseñados que ofrece IA de SageMaker, debe configurar un bucket de Amazon Simple Storage Service (Amazon S3) para que lo utilice el clúster de base de datos Aurora PostgreSQL. Se trata de un tema avanzado y no está completamente documentado en esta Guía del usuario de Amazon Aurora. El proceso general es el mismo que para integrar el soporte para IA de SageMaker, de la siguiente manera.
Cree el rol y la política de IAM para Amazon S3.
Agregue el rol de IAM y la importación o exportación de Amazon S3 como una característica en la pestaña Conectividad y seguridad de su clúster de base de datos de Aurora PostgreSQL.
Añada el ARN del rol a su grupo de parámetros de clúster de base de datos personalizado para su clúster de base de datos de Aurora.
Para obtener información de uso básica, consulte Exportación de datos a Amazon S3 para el entrenamiento de modelos de IA de SageMaker (avanzado).
Instalación de la extensión de machine learning de Aurora
Las extensiones aws_ml 1.0 de machine learning de Aurora proporcionan dos funciones que puede usar para invocar los servicios Amazon Comprehend e IA de SageMaker, y aws_ml 2.0 proporciona dos funciones adicionales que puede usar para invocar los servicios de Amazon Bedrock. La instalación de estas extensiones en el clúster de base de datos de Aurora PostgreSQL también crea una función administrativa para la característica.
nota
El uso de estas funciones depende de que la configuración de IAM para el servicio de machine learning de Aurora (Amazon Comprehend, IA de SageMaker, Amazon Bedrock) esté completa, tal como se detalla en Configuración del clúster de base de datos Aurora PostgreSQL para utilizar el machine learning de Aurora.
aws_comprehend.detect_sentiment: utilice esta función para aplicar el análisis de opinión al texto almacenado en la base de datos de su clúster de base de datos de Aurora PostgreSQL.
aws_sagemaker.invoke_endpoint: esta función se utiliza en el código SQL para comunicarse con el punto de conexión de IA de SageMaker desde el clúster.
aws_bedrock.invoke_model: esta función se utiliza en el código SQL para comunicarse con los modelos de Bedrock del clúster. La respuesta de esta función tendrá el formato TEXT, por lo que si un modelo responde en el formato de un cuerpo JSON, el resultado de esta función se retransmitirá en formato de cadena al usuario final.
aws_bedrock.invoke_model_get_embeddings: esta función se utiliza en el código SQL para invocar los modelos Bedrock, que devuelven incrustaciones de salida dentro de una respuesta JSON. Esto se puede aprovechar cuando desee extraer las incrustaciones directamente asociadas a la json-key para optimizar la respuesta con cualquier flujo de trabajo autoadministrado.
Para instalar la extensión de machine learning de Aurora en su clúster de bases de datos de Aurora PostgreSQL
Use
psqlpara conectarse a la instancia de escritor de su clúster de base de datos de Aurora PostgreSQL. Conecte a la base de datos específica en la que desee instalar la extensiónaws_ml.psql --host=cluster-instance-1.111122223333.aws-region.rds.amazonaws.com --port=5432 --username=postgres --password --dbname=labdb
labdb=>CREATE EXTENSION IF NOT EXISTS aws_ml CASCADE;NOTICE: installing required extension "aws_commons" CREATE EXTENSIONlabdb=>
La instalación de las extensiones aws_ml también crea el rol administrativo aws_ml y tres esquemas nuevos, tal como se indica a continuación.
aws_comprehend: esquema del servicio de Amazon Comprehend y origen de la funcióndetect_sentiment(aws_comprehend.detect_sentiment).aws_sagemaker: esquema del servicio de IA de SageMaker y origen de la funcióninvoke_endpoint(aws_sagemaker.invoke_endpoint).aws_bedrock: esquema del servicio de Amazon Bedrock y origen de las funcionesinvoke_model(aws_bedrock.invoke_model)yinvoke_model_get_embeddings(aws_bedrock.invoke_model_get_embeddings).
Al rol rds_superuser se le concede el rol administrativo aws_ml y se crea el OWNER de estos tres esquemas de machine learning de Aurora. Para permitir que otros usuarios de bases de datos accedan a las funciones de machine learning de Aurora, el rds_superuser tiene que conceder privilegios EXECUTE en las funciones de machine learning de Aurora. De forma predeterminada, los privilegios EXECUTE se revocan de PUBLIC en las funciones de los dos esquemas de machine learning de Aurora.
En una configuración de base de datos multiusuario, puede evitar que los inquilinos accedan a las funciones de machine learning de Aurora utilizando REVOKE USAGE en esquema de machine learning de Aurora específico que desee proteger.
Uso de Amazon Bedrock con el clúster de base de datos de Aurora PostgreSQL
Para Aurora PostgreSQL, el machine learning de Aurora proporciona la siguiente función de Amazon Bedrock para trabajar con los datos de texto. Esta función solo está disponible después de instalar la extensión aws_ml 2.0 y completar todos los procedimientos de configuración. Para obtener más información, consulte Configuración del clúster de base de datos Aurora PostgreSQL para utilizar el machine learning de Aurora.
- aws_bedrock.invoke_model
-
Esta función toma texto formateado en JSON como entrada y lo procesa para diversos modelos alojados en Amazon Bedrock y recupera la respuesta de texto JSON del modelo. Esta respuesta puede contener texto, imagen o incrustaciones. A continuación se presenta un resumen de la documentación de la función.
aws_bedrock.invoke_model( IN model_id varchar, IN content_type text, IN accept_type text, IN model_input text, OUT model_output varchar)
Las entradas y salidas de esta función son las siguientes.
-
model_id: identificador del modelo. content_type: el tipo de solicitud al modelo de Bedrock.accept_type: el tipo de respuesta que cabe esperar del modelo de Bedrock. Por lo general, application/JSON para la mayoría de los modelos.model_input: peticiones; un conjunto específico de entradas al modelo en el formato especificado por content_type. Para obtener más información sobre el formato o la estructura de las solicitudes que acepta el modelo, consulte Parámetros de inferencia para modelos fundacionales.model_output: la salida del modelo de Bedrock como texto.
El siguiente ejemplo muestra cómo invocar un modelo de Anthropic Claude 2 para Bedrock mediante invoke_model.
ejemplo Ejemplo: Una consulta sencilla con las funciones de Amazon Bedrock
SELECT aws_bedrock.invoke_model ( model_id := 'anthropic.claude-v2', content_type:= 'application/json', accept_type := 'application/json', model_input := '{"prompt": "\n\nHuman: You are a helpful assistant that answers questions directly and only using the information provided in the context below.\nDescribe the answer in detail.\n\nContext: %s \n\nQuestion: %s \n\nAssistant:","max_tokens_to_sample":4096,"temperature":0.5,"top_k":250,"top_p":0.5,"stop_sequences":[]}' );
- aws_bedrock.invoke_model_get_embeddings
-
La salida del modelo puede apuntar a incrustaciones vectoriales en algunos casos. Dado que la respuesta varía según el modelo, se puede utilizar otra función, invoke_model_get_embeddings, que funciona exactamente igual que invoke_model, pero genera las incrustaciones especificando la json-key adecuada.
aws_bedrock.invoke_model_get_embeddings( IN model_id varchar, IN content_type text, IN json_key text, IN model_input text, OUT model_output float8[])
Las entradas y salidas de esta función son las siguientes.
-
model_id: identificador del modelo. content_type: el tipo de solicitud al modelo de Bedrock. Aquí, el accept_type se establece en el valor predeterminadoapplication/json.model_input: peticiones; un conjunto específico de entradas al modelo en el formato especificado por content_type. Para obtener más información sobre el formato o la estructura de las solicitudes que acepta el modelo, consulte Parámetros de inferencia para modelos fundacionales.json_key: referencia al campo del que se va a extraer la incrustación. Esto puede variar si cambia el modelo de incrustación.-
model_output: la salida del modelo de Bedrock como una matriz de incrustaciones con decimales de 16 bits.
El siguiente ejemplo muestra cómo generar una incrustación utilizando el modelo Titan Embeddings G1: modelo de incrustación de texto para la frase “vistas de monitorización de PostgreSQL I/O”.
ejemplo Ejemplo: Una consulta sencilla con las funciones de Amazon Bedrock
SELECT aws_bedrock.invoke_model_get_embeddings( model_id := 'amazon.titan-embed-text-v1', content_type := 'application/json', json_key := 'embedding', model_input := '{ "inputText": "PostgreSQL I/O monitoring views"}') AS embedding;
Uso de Amazon Comprehend con el clúster de base de datos de Aurora PostgreSQL
Para Aurora PostgreSQL, el machine learning de Aurora proporciona la siguiente función de Amazon Comprehend para trabajar con los datos de texto. Esta función solo está disponible después de instalar la extensión aws_ml y completar todos los procedimientos de configuración. Para obtener más información, consulte Configuración del clúster de base de datos Aurora PostgreSQL para utilizar el machine learning de Aurora.
- aws_comprehend.detect_sentiment
-
Esta función toma el texto como entrada y evalúa si el texto tiene una postura emocional positiva, negativa, neutra o mixta. Genera este sentimiento junto con un nivel de confianza para su evaluación. A continuación se presenta un resumen de la documentación de la función.
aws_comprehend.detect_sentiment( IN input_text varchar, IN language_code varchar, IN max_rows_per_batch int, OUT sentiment varchar, OUT confidence real)
Las entradas y salidas de esta función son las siguientes.
-
input_text: el texto para evaluar y asignar el sentimiento (negativo, positivo, neutro, mixto). language_code: el idioma delinput_textidentificado mediante el identificador ISO 639-1 de 2 letras con subetiqueta regional (según sea necesario) o el código de tres letras ISO 639-2, según proceda. Por ejemplo,enes el código del inglés,zhes el código del chino simplificado. Para obtener más información, consulte los idiomas admitidos en la Guía para desarrolladores de Amazon Comprehend.max_rows_per_batch: el número máximo de filas por lote para el procesamiento por lotes. Para obtener más información, consulte Descripción del modo por lotes y las funciones de machine learning de Aurora.sentiment: el sentimiento del texto de entrada, identificado como POSITIVE, NEGATIVE, NEUTRAL o MIXED.confidence: el grado de confianza en la precisión delsentimentespecificado. Los valores están comprendidos entre 0,0 y 1,0.
A continuación, puede encontrar ejemplos de cómo utilizar esta función.
ejemplo Ejemplo: una consulta sencilla con las funciones de Amazon Comprehend
A continuación, se muestra un ejemplo de una consulta sencilla que invoca esta función para evaluar la satisfacción del cliente con su equipo de soporte. Supongamos que tiene una tabla de base de datos (support) que almacena los comentarios de los clientes después de cada solicitud de ayuda. En este ejemplo de consulta se aplica la función aws_comprehend.detect_sentiment al texto de la columna feedback de la tabla y muestra el sentimiento y el nivel de confianza de ese sentimiento. Esta consulta también muestra los resultados en orden descendente.
SELECT feedback, s.sentiment,s.confidence FROM support,aws_comprehend.detect_sentiment(feedback, 'en') s ORDER BY s.confidence DESC;feedback | sentiment | confidence ----------------------------------------------------------+-----------+------------ Thank you for the excellent customer support! | POSITIVE | 0.999771 The latest version of this product stinks! | NEGATIVE | 0.999184 Your support team is just awesome! I am blown away. | POSITIVE | 0.997774 Your product is too complex, but your support is great. | MIXED | 0.957958 Your support tech helped me in fifteen minutes. | POSITIVE | 0.949491 My problem was never resolved! | NEGATIVE | 0.920644 When will the new version of this product be released? | NEUTRAL | 0.902706 I cannot stand that chatbot. | NEGATIVE | 0.895219 Your support tech talked down to me. | NEGATIVE | 0.868598 It took me way too long to get a real person. | NEGATIVE | 0.481805 (10 rows)
Para evitar que la detección de sentimientos se cobre más de una vez por cada fila de la tabla, puede materializar los resultados. Haga esto en las filas de interés. Por ejemplo, se están actualizando las notas del médico para que solo las que estén en francés (fr) usen la función de detección de sentimiento.
UPDATE clinician_notes SET sentiment = (aws_comprehend.detect_sentiment (french_notes, 'fr')).sentiment, confidence = (aws_comprehend.detect_sentiment (french_notes, 'fr')).confidence WHERE clinician_notes.french_notes IS NOT NULL AND LENGTH(TRIM(clinician_notes.french_notes)) > 0 AND clinician_notes.sentiment IS NULL;
Para obtener más información sobre cómo optimizar las llamadas a las funciones, consulte Consideraciones sobre el rendimiento para utilizar el machine learning de Aurora con Aurora PostgreSQL.
Uso de IA de SageMaker con el clúster de base de datos de Aurora PostgreSQL
Tras configurar el entorno de IA de SageMaker e integrarlo con Aurora PostgreSQL, tal como se describe en Configuración de Aurora PostgreSQL para usar IA de Amazon SageMaker, puede invocar operaciones mediante la función aws_sagemaker.invoke_endpoint. La función aws_sagemaker.invoke_endpoint solo se conecta a un punto de conexión de modelo en la misma Región de AWS. Si la instancia de la base de datos tiene réplicas en varias Regiones de AWS, asegúrese de configurar e implementar cada modelo de IA de SageMaker en cada Región de AWS.
Las llamadas a aws_sagemaker.invoke_endpoint se autentican mediante el rol de IAM que configuró para asociar su clúster de base de datos de Aurora PostgreSQL al servicio de IA de SageMaker y al punto de conexión que proporcionó durante el proceso de configuración. El ámbito de los puntos de conexión del modelo de IA de SageMaker se aplica a una cuenta individual y no son públicos. La URL endpoint_name no contiene el ID de la cuenta. IA de SageMaker determina el ID de cuenta a partir del token de autenticación proporcionado por el rol de IAM de SageMaker de la instancia de base de datos.
- aws_sagemaker.invoke_endpoint
Esta función toma el punto de conexión de IA de SageMaker como entrada y el número de filas que se deben procesar como un lote. También toma como entrada los distintos parámetros esperados por el punto de conexión del modelo de IA de SageMaker. La documentación de referencia de esta función es la siguiente.
aws_sagemaker.invoke_endpoint( IN endpoint_name varchar, IN max_rows_per_batch int, VARIADIC model_input "any", OUT model_output varchar )
Las entradas y salidas de esta función son las siguientes.
endpoint_name: una URL de punto de conexión independiente de la Región de AWS.max_rows_per_batch: el número máximo de filas por lote para el procesamiento por lotes. Para obtener más información, consulte Descripción del modo por lotes y las funciones de machine learning de Aurora.model_input: uno o más parámetros de entrada para el modelo. Estos pueden ser cualquier tipo de datos que el modelo de IA de SageMaker necesite. PostgreSQL le permite especificar hasta 100 parámetros de entrada para una función. Los tipos de datos de matriz deben ser unidimensionales, pero pueden contener tantos elementos como se esperan en el modelo de IA de SageMaker. El número de entradas de un modelo de IA de SageMaker solo está limitado por el límite de tamaño de los mensajes de IA de SageMaker, que es de 6 MB.model_output: la salida del modelo de IA de SageMaker como texto.
Creación de una función definida por el usuario para invocar un modelo de IA de SageMaker
Cree una función definida por el usuario independiente para llamar a aws_sagemaker.invoke_endpoint para cada uno de sus modelos de IA de SageMaker. Cada función definida por el usuario almacenada representa el punto de conexión de IA de SageMaker que aloja el modelo. La función aws_sagemaker.invoke_endpoint se ejecuta dentro de la función definida por el usuario. Las funciones definidas por el usuario proporcionan muchas ventajas:
-
Puede dar a su modelo de IA de SageMaker su propio nombre en lugar de solo llamar a
aws_sagemaker.invoke_endpointpara todos sus modelos de IA de SageMaker. -
Puede especificar la dirección URL del punto de conexión del modelo en un solo lugar en el código de la aplicación SQL.
-
Puede controlar los privilegios de
EXECUTEde cada función de machine learning de Aurora de forma independiente. -
Puede declarar los tipos de entrada y salida del modelo mediante tipos de SQL. SQL aplica el número y el tipo de argumentos pasados al modelo de IA de SageMaker y realiza la conversión de tipos si es necesario. El uso de tipos de SQL también traducirá
SQL NULLal valor predeterminado adecuado esperado por su modelo de IA de SageMaker. -
Puede reducir el tamaño máximo del lote si desea devolver las primeras filas un poco más rápido.
Para especificar una función definida por el usuario, utilice la instrucción de lenguaje de definición de datos SQL (DDL) CREATE FUNCTION. Al definir la función, puede especificar lo siguiente:
-
Los parámetros de entrada para el modelo.
-
El punto de conexión de IA de SageMaker específico que se va a invocar.
-
El tipo de devolución.
La función definida por el usuario devuelve la inferencia calculada por el punto de conexión de IA de SageMaker después de ejecutar el modelo en los parámetros de entrada. En el siguiente ejemplo se crea una función definida por el usuario para un modelo de IA de SageMaker con dos parámetros de entrada.
CREATE FUNCTION classify_event (IN arg1 INT, IN arg2 DATE, OUT category INT)
AS $$
SELECT aws_sagemaker.invoke_endpoint (
'sagemaker_model_endpoint_name', NULL,
arg1, arg2 -- model inputs are separate arguments
)::INT -- cast the output to INT
$$ LANGUAGE SQL PARALLEL SAFE COST 5000;Tenga en cuenta lo siguiente:
-
La entrada de la función
aws_sagemaker.invoke_endpointpuede ser uno o más parámetros de cualquier tipo de datos. -
En este ejemplo se utiliza un tipo de salida INT. Si convierte la salida de un tipo
varchara otro tipo, entonces debe convertirse a un tipo escalar integrado de PostgreSQL comoINTEGER,REAL,FLOAToNUMERIC. Para obtener más información acerca de estos tipos, consulte Data Typesen la documentación de PostgreSQL. -
Especifique
PARALLEL SAFEpara habilitar el procesamiento de consultas paralelas. Para obtener más información, consulte Mejora de los tiempos de respuesta con el procesamiento de consultas en paralelo. -
Especifique
COST 5000para estimar el costo de ejecución de la función. Utilice un número positivo que indique el costo de ejecución estimado para la función, en unidades decpu_operator_cost.
Transmisión de una matriz como entrada de un modelo de IA de SageMaker
La función aws_sagemaker.invoke_endpoint puede tener hasta 100 parámetros de entrada, que es el límite para las funciones de PostgreSQL. Si el modelo de IA de SageMaker precisa más de 100 parámetros del mismo tipo, transfiera los parámetros del modelo como una matriz.
En el siguiente ejemplo se define una función definida por el usuario que transfiere una matriz como entrada al modelo de regresión de IA de SageMaker. La salida se convierte en un valor REAL.
CREATE FUNCTION regression_model (params REAL[], OUT estimate REAL) AS $$ SELECT aws_sagemaker.invoke_endpoint ( 'sagemaker_model_endpoint_name', NULL, params )::REAL $$ LANGUAGE SQL PARALLEL SAFE COST 5000;
Especificación del tamaño del lote al invocar un modelo de IA de SageMaker
En el ejemplo siguiente, se crea una función definida por el usuario para un modelo de IA de SageMaker que establece el valor predeterminado del tamaño del lote en NULL. La función también le permite proporcionar un tamaño de lote diferente cuando lo invoque.
CREATE FUNCTION classify_event (
IN event_type INT, IN event_day DATE, IN amount REAL, -- model inputs
max_rows_per_batch INT DEFAULT NULL, -- optional batch size limit
OUT category INT) -- model output
AS $$
SELECT aws_sagemaker.invoke_endpoint (
'sagemaker_model_endpoint_name', max_rows_per_batch,
event_type, event_day, COALESCE(amount, 0.0)
)::INT -- casts output to type INT
$$ LANGUAGE SQL PARALLEL SAFE COST 5000;Tenga en cuenta lo siguiente:
-
Utilice el parámetro
max_rows_per_batchopcional para proporcionar el control del número de filas para una invocación de la función en modo de lote. Si utiliza un valor NULL, el optimizador de consultas elige automáticamente el tamaño máximo del lote. Para obtener más información, consulte Descripción del modo por lotes y las funciones de machine learning de Aurora. -
De forma predeterminada, transferir NULL como un valor de parámetro se traduce en una cadena vacía antes de transferirlo a IA de SageMaker. En este ejemplo, las entradas tienen diferentes tipos.
-
Si tiene una entrada que no sea de texto o una entrada de texto que necesita de forma predeterminada un valor distinto de una cadena vacía, utilice la instrucción
COALESCE. Se utilizaCOALESCEpara traducir NULL al valor de reemplazo nulo deseado en la llamada aaws_sagemaker.invoke_endpoint. Para el parámetroamountde este ejemplo, un valor NULL se convierte en 0.0.
Invocación de un modelo de IA de SageMaker que tenga varias salidas
En el ejemplo siguiente, se crea una función definida por el usuario para un modelo de IA de SageMaker que devuelva varias salidas. Su función necesita convertir la salida de la función aws_sagemaker.invoke_endpoint a un tipo de datos correspondiente. Por ejemplo, podría usar el tipo de punto de PostgreSQL integrado para pares (x, y) o un tipo compuesto definido por el usuario.
Esta función definida por el usuario devuelve valores de un modelo que devuelve varias salidas mediante el uso de un tipo compuesto para las salidas.
CREATE TYPE company_forecasts AS ( six_month_estimated_return real, one_year_bankruptcy_probability float); CREATE FUNCTION analyze_company ( IN free_cash_flow NUMERIC(18, 6), IN debt NUMERIC(18,6), IN max_rows_per_batch INT DEFAULT NULL, OUT prediction company_forecasts) AS $$ SELECT (aws_sagemaker.invoke_endpoint('endpt_name', max_rows_per_batch,free_cash_flow, debt))::company_forecasts; $$ LANGUAGE SQL PARALLEL SAFE COST 5000;
Para el tipo compuesto, utilice los campos en el mismo orden que aparecen en la salida del modelo y convierta la salida de aws_sagemaker.invoke_endpoint al tipo compuesto. El intermediario puede extraer los campos individuales ya sea por nombre o con la notación ".*" de PostgreSQL.
Exportación de datos a Amazon S3 para el entrenamiento de modelos de IA de SageMaker (avanzado)
Le recomendamos que se familiarice con el machine learning de Aurora e IA de SageMaker utilizando los algoritmos y ejemplos proporcionados, en lugar de intentar entrenar sus propios modelos. Para obtener más información, consulte Get Started with Amazon SageMaker AI.
Para entrenar modelos de IA de SageMaker, exporte los datos a un bucket de Amazon S3. IA de SageMaker utiliza el bucket de Amazon S3 para entrenar el modelo antes de implementarlo. Puede consultar datos de un clúster de base de datos de Aurora PostgreSQL y guardarlos directamente en archivos almacenados en un bucket de Amazon S3. A continuación, IA de SageMaker consume los datos del bucket de Amazon S3 para el entrenamiento. Para obtener más información sobre el entrenamiento de modelos de IA de SageMaker, consulte Train a model with Amazon SageMaker AI.
nota
Al crear un bucket de Amazon S3 para el entrenamiento del modelo de IA de SageMaker o la puntuación por lotes, utilice sagemaker en el nombre del bucket de Amazon S3. Para obtener más información, consulte Especificar un bucket de S3 para cargar conjuntos de datos de entrenamiento y almacenar datos de salida en la Guía para desarrolladores de IA de Amazon SageMaker.
Para obtener más información acerca de la exportación de datos, consulte Exportación de datos de una Aurora PostgreSQL de base de datos de clústerde Amazon S3.
Consideraciones sobre el rendimiento para utilizar el machine learning de Aurora con Aurora PostgreSQL
Los servicios de Amazon Comprehend e IA de SageMaker realizan la mayor parte del trabajo cuando se invocan mediante una función de machine learning de Aurora. Esto significa que puede escalar esos recursos según sea necesario, de forma independiente. Para su clúster de base de datos Aurora PostgreSQL, puede hacer que sus llamadas a funciones sean lo más eficientes posible. A continuación, encontrará algunas consideraciones de rendimiento que debe tener en cuenta al trabajar con el machine learning de Aurora PostgreSQL.
Temas
Descripción del modo por lotes y las funciones de machine learning de Aurora
Normalmente, PostgreSQL ejecuta funciones una fila a la vez. El machine learning de Aurora puede reducir esta sobrecarga combinando las llamadas al servicio externo de machine learning de Aurora para muchas filas en lotes con un enfoque llamado ejecución en modo por lotes. En el modo por lotes, el machine learning de Aurora recibe las respuestas de un lote de filas de entrada y, a continuación, devuelve las respuestas a la consulta en ejecución una fila a la vez. Esta optimización mejora el rendimiento de las consultas de Aurora sin limitar el optimizador de consultas de PostgreSQL.
Aurora utiliza automáticamente el modo por lotes si se hace referencia a la función desde la lista SELECT, una cláusula WHERE o una cláusula HAVING. Tenga en cuenta que las expresiones CASE simples de nivel superior son elegibles para la ejecución en el modo por lotes. Las expresiones CASE buscadas de nivel superior también son elegibles para la ejecución en el modo por lotes siempre que la primera cláusula WHEN sea un predicado simple con una llamada a la función en el modo por lotes.
Su función definida por el usuario debe ser una función LANGUAGE SQL y debe especificar PARALLEL SAFE y COST 5000.
Migración de funciones de la instrucción SELECT a la cláusula FROM
Normalmente, Aurora migra automáticamente una función aws_ml que es elegible para la ejecución en el modo por lotes a la cláusula FROM.
La migración de funciones elegibles para el modo por lotes a la cláusula FROM se puede examinar manualmente en el nivel de consulta. Para ello, utilice instrucciones EXPLAIN (y ANALYZE y VERBOSE) y busque la información "Procesamiento por lotes" debajo de cada modo por lotes Function Scan. También puede usar EXPLAIN (con VERBOSE) sin ejecutar la consulta. A continuación, observe si las llamadas a la función aparecen como un Function
Scan bajo una unión de bucle anidado que no se especificó en la instrucción original.
En el siguiente ejemplo, la el operador de unión de bucle anidado en el plan muestra que Aurora migró la función anomaly_score. Esta función se migró de la lista SELECT a la cláusula FROM, donde es elegible para la ejecución en el modo por lotes.
EXPLAIN (VERBOSE, COSTS false)
SELECT anomaly_score(ts.R.description) from ts.R;
QUERY PLAN
-------------------------------------------------------------
Nested Loop
Output: anomaly_score((r.description)::text)
-> Seq Scan on ts.r
Output: r.id, r.description, r.score
-> Function Scan on public.anomaly_score
Output: anomaly_score.anomaly_score
Function Call: anomaly_score((r.description)::text)Para deshabilitar la ejecución en el modo por lotes, establezca el parámetro apg_enable_function_migration en false. Esto impide la migración de funciones de aws_ml de SELECT a la cláusula FROM. El siguiente ejemplo muestra cómo.
SET apg_enable_function_migration = false;El parámetro apg_enable_function_migration es un parámetro Grand Unified Configuration (GUC) reconocido por la extensión apg_plan_mgmt de Aurora PostgreSQL para la administración de planes de consulta. Para deshabilitar la migración de funciones en una sesión, utilice la administración de planes de consulta para guardar el plan resultante como un plan approved. En tiempo de ejecución, la administración de planes de consulta aplica el plan approved con su configuración apg_enable_function_migration. Esta aplicación se produce independientemente de la configuración del parámetro GUC apg_enable_function_migration. Para obtener más información, consulte Administración de planes de ejecución de consultas para Aurora PostgreSQL.
Uso del parámetro max_rows_per_batch
Tanto la función aws_comprehend.detect_sentiment como aws_sagemaker.invoke_endpoint tienen un parámetro max_rows_per_batch. Este parámetro especifica el número de filas que se pueden enviar al servicio de machine learning de Aurora. Cuanto mayor sea el conjunto de datos procesado por su función, mayor será el tamaño del lote.
Las funciones del modo por lotes mejoran la eficiencia gracias a la creación de lotes de filas que distribuyen el costo de las llamadas a las funciones del machine learning de Aurora en un gran número de filas. Sin embargo, si una instrucción SELECT termina de forma prematura debido a una cláusula LIMIT, entonces el lote se puede construir en más filas de las que utiliza la consulta. Esta estrategia puede dar lugar a cargos adicionales en su cuenta de AWS. Para obtener los beneficios de la ejecución en el modo por lotes pero evitar la creación de lotes demasiado grandes, utilice un valor más pequeño para el parámetro max_rows_per_batch en las llamadas a funciones.
Si realiza un EXPLAIN (VERBOSE, ANALYZE) de una consulta que utiliza la ejecución en el modo por lotes, verá un operador FunctionScan que está por debajo de una unión de bucle anidado. El número de bucles comunicados por EXPLAIN es igual al número de veces que se ha obtenido una fila del operador FunctionScan. Si una instrucción utiliza una cláusula LIMIT, el número de recuperaciones es coherente. Para optimizar el tamaño del lote, establezca el parámetro max_rows_per_batch en este valor. Sin embargo, si se hace referencia a la función del modo por lotes en un predicado en la cláusula WHERE o la cláusula HAVING, entonces probablemente no pueda saber el número de recuperaciones por adelantado. En este caso, utilice los bucles como guía y experimente con max_rows_per_batch para encontrar un ajuste que optimice el rendimiento.
Verificación de la ejecución en el modo por lotes
Para ver si una función se ejecuta en modo por lotes, utilice EXPLAIN ANALYZE. Si se utilizó la ejecución en el modo por lotes, el plan de consulta incluirá la información en una sección "Procesamiento por lotes".
EXPLAIN ANALYZE SELECT user-defined-function();
Batch Processing: num batches=1 avg/min/max batch size=3333.000/3333.000/3333.000
avg/min/max batch call time=146.273/146.273/146.273En este ejemplo, había 1 lote que contenía 3333 filas, que tardó 146 273 ms en procesarse. La sección "Procesamiento por lotes" muestra lo siguiente:
-
Cuántos lotes había para esta operación de escaneo de funciones
-
El tamaño promedio, mínimo y máximo del lote
-
El tiempo de ejecución por lotes promedio, mínimo y máximo
Normalmente, el lote final es más pequeño que el resto, lo que a menudo resulta en un tamaño mínimo de lote mucho más pequeño que el promedio.
Para devolver las primeras filas más rápidamente, establezca el parámetro max_rows_per_batch en un valor más pequeño.
Para reducir el número de llamadas del modo por lotes al servicio de ML cuando se utiliza un LIMIT en la función definida por el usuario, establezca el parámetro max_rows_per_batch en un valor menor.
Mejora de los tiempos de respuesta con el procesamiento de consultas en paralelo
Para obtener resultados lo más rápido posible de un gran número de filas, puede combinar el procesamiento de consultas en paralelo con el procesamiento en modo por lotes. Puede utilizar el procesamiento de consultas en paralelo para instrucciones SELECT, CREATE TABLE AS SELECT y CREATE
MATERIALIZED VIEW.
nota
PostgreSQL aún no admite consultas en paralelo para instrucciones de lenguaje de manipulación de datos (DML).
El procesamiento de consultas en paralelo se produce tanto dentro de la base de datos como dentro del servicio de ML. El número de núcleos de la clase de instancia de la base de datos limita el grado de paralelismo que se puede utilizar cuando se ejecuta una consulta. El servidor de la base de datos puede construir un plan de ejecución de consultas en paralelo que divide la tarea entre un conjunto de subprocesos de trabajo paralelos. A continuación, cada uno de estos subprocesos de trabajo puede crear solicitudes por lotes que contengan decenas de miles de filas (o tantas como permita cada servicio).
Las solicitudes por lotes de todos los trabajadores paralelos se envían al punto de conexión de IA de SageMaker. El grado de paralelismo que puede admitir el punto de conexión está limitado por el número y el tipo de instancias que lo admiten. Para obtener un paralelismo de K grados, se necesita una clase de instancia de base de datos que tenga al menos K núcleos. También debe configurar el punto de conexión de IA de SageMaker para que su modelo tenga K instancias iniciales de una clase de instancia de rendimiento suficientemente alto.
Para usar el procesamiento de consultas en paralelo, puede establecer el parámetro de almacenamiento parallel_workers de la tabla que contiene los datos que planea transferir. Se establece parallel_workers en una función de modo por lotes como aws_comprehend.detect_sentiment. Si el optimizador elige un plan de consultas en paralelo, se puede llamar a los servicios de ML de AWS tanto en lote como en paralelo.
Puede utilizar los siguientes parámetros con la función aws_comprehend.detect_sentiment para obtener un plan con paralelismo de cuatro vías. Si cambia uno de los dos parámetros siguientes, debe reiniciar la instancia de la base de datos para que los cambios surtan efecto
-- SET max_worker_processes to 8; -- default value is 8
-- SET max_parallel_workers to 8; -- not greater than max_worker_processes
SET max_parallel_workers_per_gather to 4; -- not greater than max_parallel_workers
-- You can set the parallel_workers storage parameter on the table that the data
-- for the Aurora machine learning function is coming from in order to manually override the degree of
-- parallelism that would otherwise be chosen by the query optimizer
--
ALTER TABLE yourTable SET (parallel_workers = 4);
-- Example query to exploit both batch-mode execution and parallel query
EXPLAIN (verbose, analyze, buffers, hashes)
SELECT aws_comprehend.detect_sentiment(description, 'en')).*
FROM yourTable
WHERE id < 100;Para obtener más información sobre el control de consultas en paralelo, consulte Planes paralelos
Uso de vistas materializadas y columnas materializadas
Cuando invoca un servicio de AWS como IA de SageMaker o Amazon Comprehend desde su base de datos, se cobrará a su cuenta de acuerdo con la política de precios de dicho servicio. Para minimizar los cargos a su cuenta, puede materializar el resultado de las llamadas al servicio de AWS en una columna materializada para que no se llame al servicio de AWS más de una vez por fila de entrada. Si lo desea, puede agregar una columna de marca de tiempo materializedAt para registrar la hora a la que se materializaron las columnas.
La latencia de una instrucción INSERT de una sola fila ordinaria suele ser mucho menor que la latencia de llamar a una función de modo por lotes. Por lo tanto, es posible que no pueda cumplir los requisitos de latencia de su aplicación si invoca la función de modo por lotes para cada fila única INSERT que realiza la aplicación. Para materializar el resultado de llamar a un servicio de AWS en una columna materializada, las aplicaciones de alto rendimiento generalmente tienen que rellenar las columnas materializadas. Para ello, emiten periódicamente una instrucción UPDATE que opera en un gran lote de filas al mismo tiempo.
UPDATE toma un bloqueo de nivel de fila que puede afectar a una aplicación en ejecución. Por lo tanto, es posible que tenga que utilizar SELECT ... FOR UPDATE SKIP LOCKED o MATERIALIZED
VIEW.
Las consultas analíticas que operan en un gran número de filas en tiempo real pueden combinar la materialización en modo por lotes con el procesamiento en tiempo real. Para ello, estas consultas ensamblan un UNION ALL de los resultados prematerializados con una consulta sobre las filas que aún no tienen resultados materializados. En algunos casos, UNION ALL es necesario en varios lugares, o una aplicación de terceros genera la consulta. Si es así, puede crear un VIEW para encapsular la operación UNION ALL para que este detalle no esté expuesto al resto de la aplicación SQL.
Puede utilizar una vista materializada para materializar los resultados de una instrucción SELECT arbitraria en una instantánea en el tiempo. También puede utilizarse para actualizar la vista materializada en cualquier momento en el futuro. Actualmente, PostgreSQL no admite la actualización incremental, por lo que cada vez que se actualiza la vista materializada, la vista materializada se vuelve a calcular por completo.
Puede actualizar vistas materializadas con la opción CONCURRENTLY, que actualiza el contenido de la vista materializada sin tener un bloqueo exclusivo. Al hacer esto, una aplicación SQL puede leer desde la vista materializada mientras se actualiza.
Monitorización del machine learning de Aurora
Puede supervisar las funciones aws_ml estableciendo el parámetro track_functions de su grupo de parámetros de clúster de base de datos personalizado en all. De forma predeterminada, este parámetro está configurado en pl, lo que significa que solo se rastrean las funciones del lenguaje de procedimientos. Al cambiarlo a all, también se hace un seguimiento de las funciones aws_ml. Para obtener más información, consulte Run-time Statistics
Para obtener información acerca de la supervisión del rendimiento de las operaciones de IA de SageMaker llamadas desde las funciones del machine learning de Aurora, consulte Monitor Amazon SageMaker AI en la Guía para desarrolladores de IA de Amazon SageMaker.
Si track_functions está configurado en all, puede consultar la vista pg_stat_user_functions para obtener estadísticas sobre las funciones que define y utiliza para invocar los servicios de machine learning de Aurora. Para cada función, la vista incluye el número de calls, total_time y self_time.
Para ver las estadísticas de aws_sagemaker.invoke_endpoint y las funciones aws_comprehend.detect_sentiment, puede filtrar los resultados por nombre de esquema mediante la siguiente consulta.
SELECT * FROM pg_stat_user_functions WHERE schemaname LIKE 'aws_%';
Para borrar las estadísticas, haga lo siguiente.
SELECT pg_stat_reset();
Puede obtener los nombres de las funciones de SQL que llaman a la función aws_sagemaker.invoke_endpoint consultando el catálogo del sistema pg_proc de PostgreSQL. Este catálogo almacena información sobre funciones, procedimientos y mucho más. Para obtener más información consulte pg_procproname) cuyo origen (prosrc) incluye el texto invoke_endpoint.
SELECT proname FROM pg_proc WHERE prosrc LIKE '%invoke_endpoint%';
