Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Trabajos de matrices
Un trabajo de matriz es un trabajo que comparte parámetros comunes, como la definición de trabajo, las vCPU y la memoria. Se ejecuta como un conjunto de trabajos básicos relacionados, pero independientes, que se pueden distribuir en varios hosts y pueden ejecutarse de forma simultánea. Los trabajos de matrices son la manera más eficiente de ejecutar trabajos que ocurren todos en paralelo, como simulaciones Monte Carlo, barridos paramétricos o grandes trabajos de representación.
AWS Batch Los trabajos de matriz se envían igual que los trabajos normales. Sin embargo, es necesario especificar un tamaño de matriz (entre 2 y 10 000) para definir la cantidad de trabajos secundarios que deberían ejecutarse en la matriz. Si envía un trabajo con un tamaño de matriz de 1 000, se ejecuta un solo trabajo que genera 1 000 trabajos secundarios. El trabajo de matriz es una referencia o un puntero para administrar todos los trabajos secundarios. Esto permite enviar grandes cargas de trabajo con una sola consulta. El tiempo de espera especificado en el parámetro attemptDurationSeconds se aplica a cada trabajo secundario. El trabajo de matriz principal no tiene tiempo de espera.
Al enviar un trabajo de matriz, el trabajo de matriz principal recibe un ID de AWS Batch trabajo normal. Cada trabajo secundario tiene el mismo ID base. Cada trabajo secundario tiene el mismo ID de base, pero su índice de matriz se añade al final del ID principal, por ejemplo, example_job_ID:0
El trabajo de matriz principal puede introducir un estado SUBMITTED, PENDING, FAILED o SUCCEEDED. El trabajo de matriz principal se actualiza a PENDING cuando se actualiza cualquier trabajo secundario a RUNNABLE. Para obtener más información acerca de estas dependencias, consulte Dependencias de trabajos.
Durante el tiempo de ejecución, la variable de entorno AWS_BATCH_JOB_ARRAY_INDEX se establece en el número de índice del trabajo de matriz correspondiente del contenedor. Al primer índice de trabajo de matriz se le asigna el número 0, y los trabajos secundarios posteriores se numeran en orden ascendente (por ejemplo, 1, 2, 3, etc.). Puede utilizar este valor de índice para controlar la forma en la que se diferencian los elementos secundarios del trabajo de matriz. Para obtener más información, consulte Uso del índice de trabajo de matriz para controlar la diferenciación de trabajos.
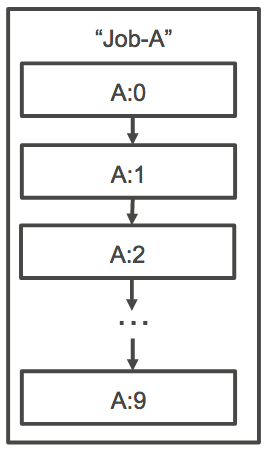
En las dependencias de trabajo de matriz, puede especificar un tipo para la dependencia, como, por ejemplo, SEQUENTIAL o N_TO_N. Puede especificar una dependencia de tipo SEQUENTIAL (sin especificar un ID de trabajo) para que cada trabajo de matriz secundario se complete de forma secuencial, comenzando a partir del índice 0. Por ejemplo, si envía un trabajo de matriz con un tamaño de matriz de 100, y especifica una dependencia de tipo SEQUENTIAL, se generan 100 trabajos secundarios de forma secuencial, cada uno de los cuales debe completarse correctamente para que comience el siguiente. En la ilustración siguiente se muestra Job A, un trabajo de matriz con un tamaño de matriz de 10. Cada trabajo del índice secundario de Job A depende del trabajo secundario anterior. El trabajo no A:1 puede empezar hasta que A:0 finalice.
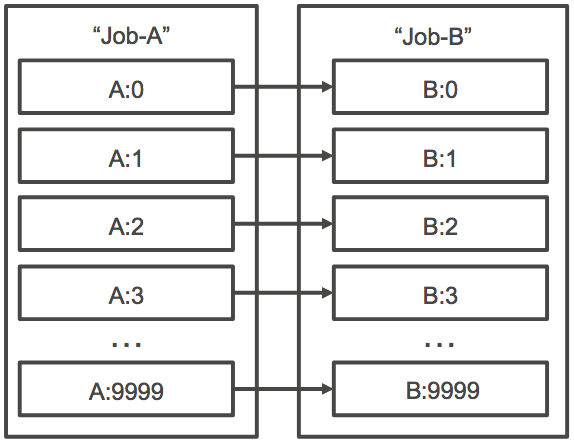
También puede especificar una dependencia de tipo N_TO_N con un ID de trabajo para los trabajos de matriz. De esta forma, cada índice secundario de este trabajo debe esperar a que se complete el índice secundario correspondiente de cada dependencia antes de comenzar. En la ilustración siguiente se muestran Job A y Job B, dos trabajos de matrices con un tamaño de matriz de 10 000. Cada trabajo del índice secundario del Trabajo B depende del índice correspondiente del Trabajo A. El trabajo no B:1 puede empezar hasta que A:1 finalice el trabajo.
Si cancela o termina un trabajo de matriz principal, todos los trabajos secundarios se cancelan o terminan con él. Puede cancelar o terminar trabajos secundarios por separado (con lo que adoptarán el estado FAILED) sin afectar al resto de trabajos secundarios. Sin embargo, si un trabajo de matriz secundario produce un error (durante su ejecución o por una cancelación/terminación manual), el trabajo principal también producirá un error. En este escenario, el trabajo principal cambia a FAILED cuando se completan todos los trabajos secundarios.
Para obtener más información sobre la búsqueda y el filtrado de trabajos de matriz, consulteBuscar para trabajos en una cola de trabajos.
Temas
