Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Solución de problemas de Amazon DataZone
Si te encuentras con problemas de acceso denegado o dificultades similares al trabajar con Amazon, DataZone consulta los temas de esta sección.
Solución de problemas de permisos de AWS Lake Formation para Amazon DataZone
Esta sección contiene instrucciones para solucionar problemas que podría encontrarse en Configurar los permisos de Lake Formation para Amazon DataZone.
| Mensaje de error en el portal de datos | Resolución |
|---|---|
|
Unable to assume the Data Access Role. |
Este error aparece cuando Amazon DataZone no puede asumir AmazonDataZoneGlueDataAccessRoleque utilizaste para habilitarlo DefaultDataLakeBlueprinten tu cuenta. Para solucionar el problema, ve a la consola de AWS IAM de la cuenta en la que se encuentra tu activo de datos y asegúrate de que AmazonDataZoneGlueDataAccessRoletiene la relación de confianza adecuada con el director de DataZone servicio de Amazon. Para obtener más información, consulte AmazonDataZoneGlueAccess- <region>- <domainId> |
|
The Data Access Role does not have the necessary permissions to read the metadata of the asset you are trying to subscribe. |
Este error se muestra cuando Amazon asume DataZone correctamente el AmazonDataZoneGlueDataAccessRolerol, pero el rol no tiene los permisos necesarios. Para solucionar el problema, vaya a la consola de AWS IAM de la cuenta en la que se encuentra su activo de datos y asegúrese de que el rol lo tenga AmazonDataZoneGlueManageAccessRolePolicyasociado. Para obtener más información, consulte AmazonDataZoneGlueAccess- <region>- <domainId>. |
|
El activo es un enlace a un recurso. Amazon DataZone no admite suscripciones a enlaces de recursos. |
Este error se muestra cuando el recurso que estás intentando publicar en Amazon DataZone es un enlace de recursos a una tabla de AWS Glue. |
|
AWS Lake Formation no administra el activo. |
Este error indica que los permisos de AWS Lake Formation no se aplican al activo que desea publicar. Esto sucede en los siguientes casos:
|
|
Data Access role does not have necessary Lake Formation permissions to grant access to this asset. |
Este error indica que el elemento AmazonDataZoneGlueDataAccessRoleque estás utilizando para habilitar el DefaultDataLakeBlueprintcontenido en tu cuenta no tiene los permisos necesarios para DataZone que Amazon gestione los permisos del activo publicado. Puede resolver el problema añadiendo al AmazonDataZoneGlueDataAccessRolecomo administrador de AWS Lake Formation o concediendo los siguientes permisos al activo que desee publicar. AmazonDataZoneGlueDataAccessRole
|
Solución de problemas de vinculación de activos DataZone de Amazon Linage con conjuntos de datos ascendentes
Esta sección contiene instrucciones de solución de problemas que puedan surgir con el DataZone linaje de Amazon. En algunos de los eventos de ejecución de linaje abierto AWS Glue y relacionados con Amazon Redshift, es posible que vea que el linaje de activos no está vinculado a un conjunto de datos ascendente. En este tema se explican los escenarios y algunos enfoques destinados a mitigar los problemas. Para obtener más información acerca del linaje, consulte Linaje de datos en Amazon DataZone.
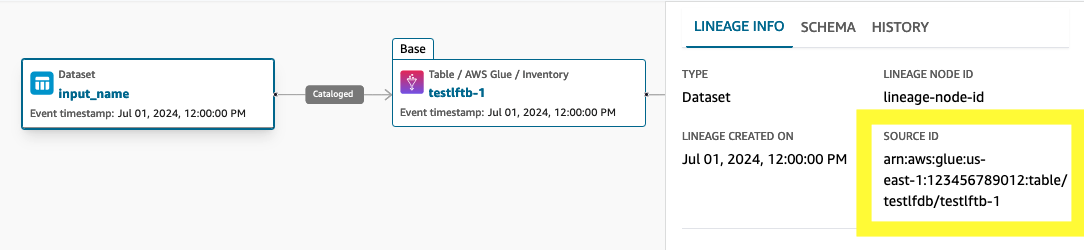
SourceIdentifier en el nodo de linaje
El atributo sourceIdentifier de un nodo de linaje representa los eventos que ocurren en un conjunto de datos. Para obtener más información, consulte los Key attributes in lineage nodes.
El nodo de linaje representa todos los eventos que ocurren en el conjunto de datos o trabajo correspondiente. El nodo de linaje contiene un atributo SourceIdentifier que contiene el identificador del conjunto de datos/trabajo correspondiente. Como admitimos eventos de linaje abierto, el valor sourceIdentifier se rellena de forma predeterminada como la combinación de espacio de nombres y nombre para un conjunto de datos, una tarea y una ejecución de tareas.
En el caso de AWS recursos como AWS Glue Amazon Redshift, estas sourceIdentifier serían la tabla AWS Glue ARN y la tabla Redshift a ARNs partir de las cuales DataZone Amazon construirá el evento de ejecución y otros detalles, como se indica a continuación:
nota
En AWS, el ARN contiene información como el AccountID, la región, la base de datos y la tabla de cada recurso.
OpenLineage El evento de estos conjuntos de datos contiene el nombre de la base de datos y la tabla.
La región se captura en la faceta propiedades del entorno de una ejecución. Si no está presente, el sistema utiliza la región de las credenciales del intermediario.
AccountId se toma de las credenciales de la persona que llama.
SourceIdentifier sobre los activos que contiene DataZone
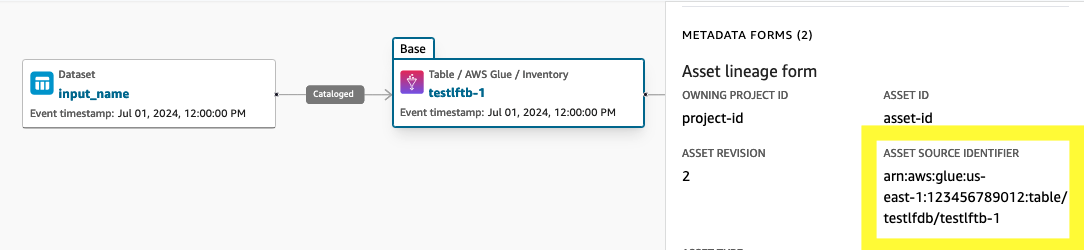
AssetCommonDetailForm tiene un atributo llamado “SourceIdentifier” que representa el identificador del conjunto de datos que representa el activo. Para que los nodos del linaje de activos se vinculen a un conjunto de datos ascendente, el atributo debe rellenarse con el valor que coincida con el sourceIdentifier del nodo del conjunto de datos. Si los activos se importan por fuente de datos, el flujo de trabajo se rellena automáticamente sourceIdentifier como la tabla AWS Glue ARN/ ARN de la tabla Redshift, mientras que la persona que llama debe rellenar ese valor para otros activos (incluidos los activos personalizados) creados mediante la CreateAsset API.
¿Cómo DataZone construye Amazon el SourceIdentifier a partir del OpenLineage evento?
Para AWS Glue los activos de Redshift, sourceIdentifier se construye a partir de Glue y Redshift. ARNs Así es como lo DataZone construye Amazon:
AWS Glue ARN
El objetivo es construir un OpenLineage evento en el que el nodo de linaje de sourceIdentifier salida sea:
arn:aws:glue:us-east-1:123456789012:table/testlfdb/testlftb-1
Para determinar si una ejecución utiliza datos de AWS Glue, busca la presencia de determinadas palabras clave en la environment-properties faceta. En concreto, si alguno de estos campos designados está presente, el sistema presupone que RunEvent se origina en AWS Glue.
GLUE_VERSION
GLUE_COMMAND_CRITERIA
GLUE_PYTHON_VERSION
"run": { "runId":"4e3da9e8-6228-4679-b0a2-fa916119fthr", "facets":{ "environment-properties":{ "_producer":"https://github.com/OpenLineage/OpenLineage/tree/1.9.1/integration/spark", "_schemaURL":"https://openlineage.io/spec/2-0-2/OpenLineage.json#/$defs/RunFacet", "environment-properties":{ "GLUE_VERSION":"3.0", "GLUE_COMMAND_CRITERIA":"glueetl", "GLUE_PYTHON_VERSION":"3" } } }
Para una AWS Glue ejecución, puede usar el nombre de la symlinks faceta para obtener la base de datos y el nombre de la tabla, que se pueden usar para construir el ARN.
Debe asegurarse de que el nombre es databaseName.tableName:
"symlinks": { "_producer":"https://github.com/OpenLineage/OpenLineage/tree/1.9.1/integration/spark", "_schemaURL":"https://openlineage.io/spec/facets/1-0-0/SymlinksDatasetFacet.json#/$defs/SymlinksDatasetFacet", "identifiers":[ { "namespace":"s3://object-path", "name":"testlfdb.testlftb-1", "type":"TABLE" } ] }
Ejemplo de evento COMPLETO:
{ "eventTime":"2024-07-01T12:00:00.000000Z", "producer":"https://github.com/OpenLineage/OpenLineage/tree/1.9.1/integration/glue", "schemaURL":"https://openlineage.io/spec/2-0-2/OpenLineage.json#/$defs/RunEvent", "eventType":"COMPLETE", "run": { "runId":"4e3da9e8-6228-4679-b0a2-fa916119fthr", "facets":{ "environment-properties":{ "_producer":"https://github.com/OpenLineage/OpenLineage/tree/1.9.1/integration/spark", "_schemaURL":"https://openlineage.io/spec/2-0-2/OpenLineage.json#/$defs/RunFacet", "environment-properties":{ "GLUE_VERSION":"3.0", "GLUE_COMMAND_CRITERIA":"glueetl", "GLUE_PYTHON_VERSION":"3" } } } }, "job":{ "namespace":"namespace", "name":"job_name", "facets":{ "jobType":{ "_producer":"https://github.com/OpenLineage/OpenLineage/tree/1.9.1/integration/glue", "_schemaURL":"https://openlineage.io/spec/facets/2-0-2/JobTypeJobFacet.json#/$defs/JobTypeJobFacet", "processingType":"BATCH", "integration":"glue", "jobType":"JOB" } } }, "inputs":[ { "namespace":"namespace", "name":"input_name" } ], "outputs":[ { "namespace":"namespace.output", "name":"output_name", "facets":{ "symlinks":{ "_producer":"https://github.com/OpenLineage/OpenLineage/tree/1.9.1/integration/spark", "_schemaURL":"https://openlineage.io/spec/facets/1-0-0/SymlinksDatasetFacet.json#/$defs/SymlinksDatasetFacet", "identifiers":[ { "namespace":"s3://object-path", "name":"testlfdb.testlftb-1", "type":"TABLE" } ] } } } ] }
Según el evento OpenLineage enviado, el sourceIdentifier del nodo del linaje de salida será:
arn:aws:glue:us-east-1:123456789012:table/testlfdb/testlftb-1
El nodo del linaje de salida se conectará al nodo del linaje de un activo donde el sourceIdentifier del activo está:
arn:aws:glue:us-east-1:123456789012:table/testlfdb/testlftb-1
Amazon Redshift ARN
El objetivo es construir un OpenLineage evento en el que el nodo de linaje de salida sea: sourceIdentifier
arn:aws:redshift:us-east-1:123456789012:table/workgroup-20240715/tpcds_data/public/dws_tpcds_7
El sistema determina si una entrada o una salida se almacena en Redshift en función del espacio de nombres. En concreto, si el espacio de nombres comienza por redshift:// o contiene las cadenas redshift-serverless.amazonaws.com o redshift.amazonaws.com, es un recurso de Redshift.
"outputs": [ { "namespace":"redshift://workgroup-20240715.123456789012.us-east-1.redshift.amazonaws.com:5439", "name":"tpcds_data.public.dws_tpcds_7" } ]
Tenga en cuenta que el espacio de nombres debe tener el siguiente formato:
provider://{cluster_identifier}.{region_name}:{port}
Para redshift-serverless:
"outputs": [ { "namespace":"redshift://workgroup-20240715.123456789012.us-east-1.redshift-serverless.amazonaws.com:5439", "name":"tpcds_data.public.dws_tpcds_7" } ]
Resultados en el siguiente sourceIdentifier
arn:aws:redshift-serverless:us-east-1:123456789012:table/workgroup-20240715/tpcds_data/public/dws_tpcds_7
Según el OpenLineage evento enviado, el nodo de linaje que se asignará sourceIdentifier a un nodo de linaje descendente (es decir, una salida del evento) es:
arn:aws:redshift-serverless:us-e:us-east-1:123456789012:table/workgroup-20240715/tpcds_data/public/dws_tpcds_7
Esta es la asignación que le ayuda a visualizar el linaje de un activo en el catálogo.
Enfoque alternativo
Cuando no se cumplen ninguna de las condiciones anteriores, el sistema utiliza el espacio de nombres/nombre para construir el sourceIdentifier:
"inputs": [ { "namespace":"arn:aws:redshift:us-east-1:123456789012:table", "name":"workgroup-20240715/tpcds_data/public/dws_tpcds_7" } ], "outputs": [ { "namespace":"arn:aws:glue:us-east-1:123456789012:table", "name":"testlfdb/testlftb-1" } ]
Solución de problemas por falta de flujo ascendente para el nodo del linaje de activos
Si no ve el flujo ascendente del nodo de linaje del activo, puede hacer lo siguiente para solucionar el problema por el que no está vinculado al conjunto de datos:
Invoque
GetAssetmientras proporciona lasdomainIdyassetId:aws datazone get-asset --domain-identifier <domain-id> --identifier <asset-id>La respuesta aparece como se muestra a continuación:
{ ..... "formsOutput": [ ..... { "content": "{\"sourceIdentifier\":\"arn:aws:glue:eu-west-1:123456789012:table/testlfdb/testlftb-1\"}", "formName": "AssetCommonDetailsForm", "typeName": "amazon.datazone.AssetCommonDetailsFormType", "typeRevision": "6" }, ..... ], "id": "<asset-id>", .... }Invoque
GetLineageNodepara obtener elsourceIdentifierdel nodo de linaje del conjunto de datos. Como no hay forma de obtener directamente el nodo de linaje para el nodo del conjunto de datos correspondiente, puede empezar conGetLineageNodeen la ejecución de tarea:aws datazone get-lineage-node --domain-identifier <domain-id> --identifier <job_namespace>.<job_name>/<run_id> if you are using the getting started scripts, job name and run ID are printed in the console and namespace is "default". Otherwise you can get these values from run event content.La respuesta del ejemplo tiene este aspecto:
{ ..... "downstreamNodes": [ { "eventTimestamp": "2024-07-24T18:08:55+08:00", "id": "afymge5k4v0euf" } ], "formsOutput": [ <some forms corresponding to run and job> ], "id": "<system generated node-id for run>", "sourceIdentifier": "default.redshift.create/2f41298b-1ee7-3302-a14b-09addffa7580", "typeName": "amazon.datazone.JobRunLineageNodeType", .... "upstreamNodes": [ { "eventTimestamp": "2024-07-24T18:08:55+08:00", "id": "6wf2z27c8hghev" }, { "eventTimestamp": "2024-07-24T18:08:55+08:00", "id": "4tjbcsnre6banb" } ] }GetLineageNodeVuelva a invocarlo pasando el identificador del downstream/upstream nodo (que cree que debería estar vinculado al nodo del activo), ya que corresponde al conjunto de datos:Ejemplo de comando que utiliza la respuesta del ejemplo anterior:
aws datazone get-lineage-node --domain-identifier <domain-id> --identifier afymge5k4v0eufEsto devuelve los detalles del nodo de linaje correspondientes al conjunto de datos: afymge5k4v0euf
{ ..... "domainId": "dzd_cklzc5s2jcr7on", "downstreamNodes": [], "eventTimestamp": "2024-07-24T18:08:55+08:00", "formsOutput": [ ..... ], "id": "afymge5k4v0euf", "sourceIdentifier": "arn:aws:redshift:us-east-1:123456789012:table/workgroup-20240715/tpcds_data/public/dws_tpcds_7", "typeName": "amazon.datazone.DatasetLineageNodeType", "typeRevision": "1", .... "upstreamNodes": [ ... ] }Compare el
sourceIdentifierde este nodo de conjunto de datos y la respuesta deGetAsset. Si no están vinculados, no coincidirán y, por lo tanto, no estarán visibles en la interfaz de usuario del linaje.
Escenarios y mitigaciones que no coinciden
Los siguientes son los escenarios más conocidos en los que no coincidirán y las posibles formas de mitigarlo:
Causa raíz: las tablas están presentes en una cuenta diferente a la de la cuenta de DataZone dominio de Amazon.
Mitigación: puede invocar la operación PostLineageEvent desde una cuenta asociada. Como el accountId para construir el ARN se selecciona de las credenciales del intermediario, puede asumir el rol desde la cuenta que contiene las tablas al ejecutar el script de introducción o al invocar PostLineageEvent. Hacerlo ayudará a construir ARNs correctamente los nodos de activos y a vincularlos con ellos.
Causa principal: el ARN de Redshift table/views contiene Redshift/Redshift-Serverless en función del espacio de nombres y los atributos de nombre de la información del conjunto de datos correspondiente en el evento de ejecución. OpenLineage
Mitigación: como no existe una forma determinada de saber si el nombre proporcionado pertenece a un clúster o a un grupo de trabajo, utilizamos la siguiente heurística:
Si el nombre correspondiente al conjunto de datos contiene
redshift-serverless.amazonaws.com, utilizamos redshift-serverless como parte del ARN. De lo contrario, el valor predeterminado es redshift.Lo anterior significa que los alias en los nombres de los grupos de trabajo no funcionarán.
Causa principal: los conjuntos de datos ascendentes no están enlazados correctamente para los activos personalizados.
Mitigación: asegúrese de rellenar el sourceIdentifier en el activo invocando un CreateAsset/CreateAssetRevision que coincida con el sourceIdentifier del nodo del conjunto de datos (que sería <namespace>/<name> para nodos personalizados).
